
🧩 Patch Gradient Descent (PatchGD): Optimizing Locally, Impacting Globally
1. 🌍 Overview: PatchGD is an advanced deep learning optimization technique that enhances model performance on large, complex datasets by segmenting the data and optimizing within local regions.
2. 🛠️ Key Advantages:
- Local Pattern Capture: PatchGD outperforms traditional gradient descent by capturing local patterns in the data, allowing for finer model parameter adjustments and better global performance.
- Reduced Noise Impact: Local optimization helps reduce the influence of noisy data points, making the model more stable and reliable.
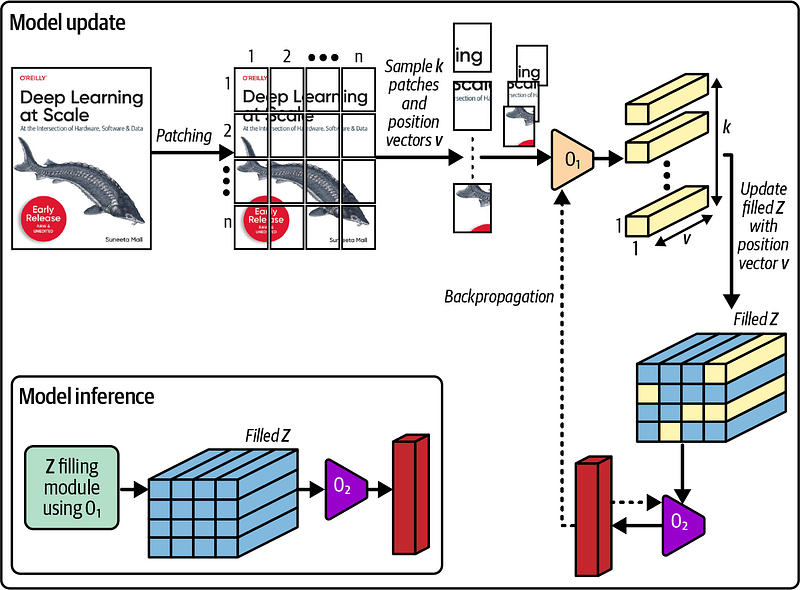
3. 📊 Implementation Steps:
- Data Segmentation: Divide the dataset into smaller patches.
- Local Gradient Calculation: Compute gradients within each patch.
- Parameter Update: Update model parameters, which can be done synchronously or asynchronously.
4. 💡 Applications:
- Image Processing: Enhances local feature optimization.
- Natural Language Processing: Improves language model accuracy.
- Time Series Analysis:Optimizes local patterns in sequential data.
5. 🚀 Efficiency: PatchGD is well-suited for large datasets and improves processing efficiency through parallel handling of small data batches.
6. 🧪 Experimental Results: Tests on synthetic datasets show PatchGD achieves low mean squared error and an R² value close to 1, indicating high accuracy and fast convergence.
7. 🔮 Future Impact: As data volume and complexity grow, local optimization techniques like PatchGD will play a crucial role in advancing deep learning, driving innovation in the field.
#AI #DeepLearning #PatchGD #Optimization #MachineLearning #DataScience #TechInnovation #BigData #LocalOptimization #ModelPerformance #ImageProcessing #NLP #TimeSeriesAnalysis #FutureTech
1
2
122