
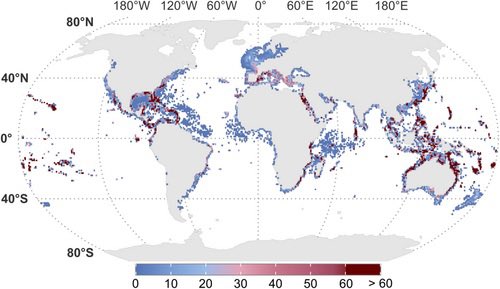
🐠 Which reef fishes yield reliable #SDMs? Analysing 1900 species, this study shows #modelperformance mostly depends on latitude and coastal proximity, offering a framework to predict reliability and improve #marinebiodiversity assessments.
🔗 doi.org/10.1111/ddi.70160
3
13
494

Happy Friday Fam ☀️
Great AI isn’t just about smart models it’s about making them work in the real world.
@inference_labs Labs focuses on squeezing maximum performance out of models: faster responses, lower costs, and rock solid reliability.
@alturax makes sure that performance doesn’t hit a wall providing the infrastructure to deploy, scale, and secure it in production.
When model optimization meets production ready infrastructure, AI moves from promising to impactful.
#AI #Inference #ModelPerformance #ScalableAI #AIInfrastructure #Alturax #InferenceLabs

77
44
95
836

Frontier AI Trends Report - aisi.gov.uk/frontier-ai-tren… by @AISecurityInst
This report presents our current understanding of AI capability trends based on extensive testing across multiple domains. The data show consistent and significant improvements in model performance, though uncertainties remain about the trajectory and broader implications of these advances.
The capabilities we evaluated have already begun to surpass expert baselines in several areas. This momentum holds promise for breakthroughs in research, healthcare, and productivity. At the same time, they could lower barriers to misuse in areas like cyber offence or sensitive research, while also presenting novel risks. Recognising both sides of this dual-use potential is critical for steering AI’s rapid advance toward public benefit while guarding against their potential for harm.
As AI systems are increasingly integrated into society, the challenge is to anticipate long-term developments, while also ensuring near-term adoption is secure, reliable, and aligned with human intent. This requires safeguards that keep pace with accelerating capabilities, rigorous and independent evaluations to track emerging impacts, and collaboration across government, industry, and academia to develop solutions to pressing open questions in AI safety and security.
Going forward, we aim to publish regular editions of this report to provide up-to-date public visibility into the frontier of AI development. We will continue to refine our methodology and work to resolve gaps in our understanding.
Authors: @AISecurityInst, @alxndrdavies, @AlexandraSouly, @_robertkirk, @jaipatelAISI, @jake_jay_p, @jacobmerizian, @geoffreyirving, @JonasSandbrink, @hannahrosekirk, @ekinomicss, Abby D'Cruz, Jacob Arbeid, Merlin Stein, Alastair Pearson, Michael Schmatz, Alex Anwyl-Irvine, Jade Leung, Nate Burnikell, Aliya Ahmad, Philippa Green, Anna Gausen, Jamie Bernardi, Philippos Giavridis, Barnaby Perkes, James Walpole, Ben Millwood, James Wright, Roddy McNeill, Catherine Fist, Jessica Wang, Ruairi Gildea, Christopher Summerfield, Jerome Wynne, Sam Deverett, Cozmin Ududec, Joe Skinner, Sam Glendenning, Eric Winsor, Jonas Lockett Klein, Sarah Hastings, Sarah Jackson, George Margereson, Jordan Taylor, Geoffrey Irving, Joseph Bloom, Simon Inman, Giles Harper-Donnelly, Karina Kumar, Sophie Bodanis, Hadrien Pouget, Kobi Hackenburg, Sophie Rose, Hannah Rose Kirk, Kola Ayonrinde, Steph Suddell, Harry Coppock, Lennart Luettgau, Steven Kemp, Hashim Khalid, Liya Jin, Timo Flesch, Henry Davidson, Louie Terrill, Tom Reed, Ishan Mishra, Magda Dubois, Will Payne, Xander Davies
Source: cdn.prod.website-files.com/6…
#AI #ArtificialIntelligence #AICapabilities #AIEvaluation #FrontierModels #AITesting #ModelPerformance #AISafety #AISecurity #ResponsibleAI #DualUse #Governance #RiskManagement #PublicBenefit #Cybersecurity

4
18
963

29 Oct 2025
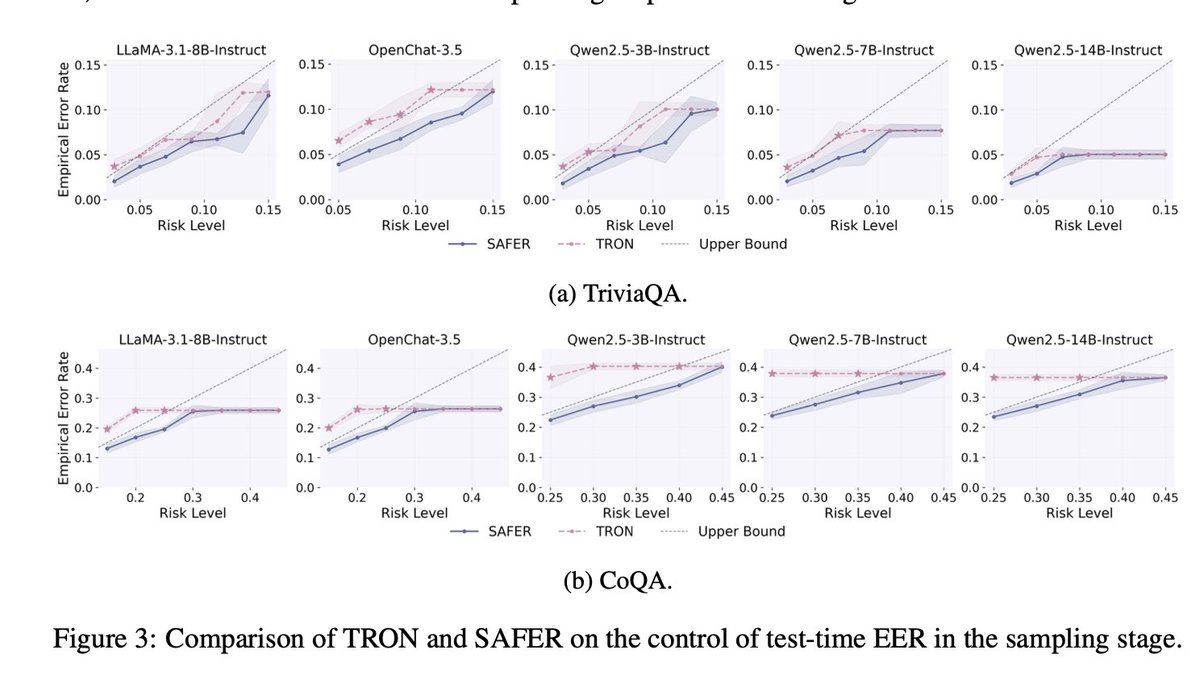
📊 SAFER vs. TRON:
Compared to TRON, SAFER provides tighter control of empirical error rates (EER) under varying risk levels — outperforming prior methods while preserving statistical rigor and calibrated reliability.
#RiskControl #AI #ModelPerformance 🧵3/5
1
3
111

14 Sep 2025
Synthetic Data and Scalable AI: Enhancing Model Performance Across Domains
hubs.li/Q03HXGkQ0
#SyntheticData #AIPrivacy #ModelPerformance #DataAugmentation #GenerativeAI #ScalableAI #AppliedAISummit

2
514

5 Aug 2025
A Practical Guide to Measuring Machine Learning Performance.
#modelPerformance #evaluatingModel #MachineLearning
techbabas.com/a-practical-gu…
1
2
62

31 Jul 2025
Most AI models look perfect - until you actually use them.
In our latest post, we dig into the hidden fractures behind top-scoring models. On benchmarks like AI2 Reasoning Challenge or MMLU, scores above 90% suggest maturity - but reality tells a different story.
🔍 Why do models break down on specific prompts, even when they ace the aggregate?
⚖️ What trade-offs in latency, reasoning, or consistency are we missing?
We break down how performance parity can be an illusion—and why next-gen benchmarking needs to go deeper.
📖 Read it here:
open.substack.com/pub/layerl…
#AI #LLMs #benchmarking #modelperformance #AIevaluation #LayerLens

2
2,274

29 Jul 2025
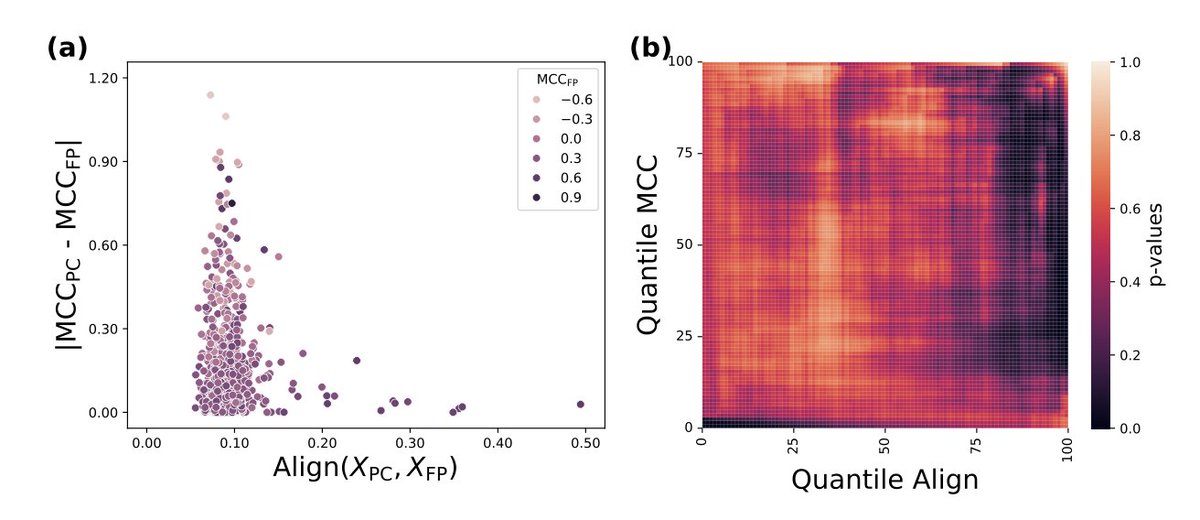
Relating Model Performance to Embedding Distributions in Molecular Machine Learning
1. A novel study explores how the alignment of molecular representations impacts model performance in machine learning, revealing that high alignment between models significantly limits performance variability. This finding challenges the notion that diverse representations always lead to better ensemble performance.
2. The research introduces a theoretical framework demonstrating that performance differences between models are fundamentally bounded by their representational alignment. This framework predicts an “exclusion zone” where large performance gaps cannot occur if alignment is high.
3. Empirical validation across 662 datasets confirms the existence of the exclusion zone, showing that high alignment between models results in consistent performance, even in binary classification tasks. This suggests that alignment can be a diagnostic tool for model selection.
4. The study investigates model ensembling through the lens of representational alignment and finds no significant practical benefit from combining low-alignment models. This indicates that alignment alone is not a strong predictor of ensemble success.
5. The authors propose that when alignment is low, exploring multiple featurization strategies may be beneficial, while high alignment suggests focusing on data quality or task formulation for performance improvements.
6. The work highlights the potential for representational alignment to guide practical decisions in molecular machine learning, offering a principled and interpretable approach to understanding model behavior and optimizing performance.
📜Paper: doi.org/10.26434/chemrxiv-20…
💻Code: github.com/MatthiasWel/pc_fp…
#MachineLearning #MolecularRepresentation #Alignment #ModelPerformance #DrugDiscovery #ComputationalBiology
4
680

5 Jun 2025
📎 High-quality AI starts with high-quality data — and that begins with better annotation.
📊 Accurate, consistent data labeling isn’t just a technical necessity. It’s a strategic driver of performance, reliability, and fairness in AI systems.
📍 The future of AI isn’t just about models. It’s about the foundation we build them on.
Is your data annotation strategy ready for tomorrow’s AI demands?
🔁 Repost if this feels true
🔖 Save this for future reference
📌 Follow @sijlalhussain for more AI strategy insight
Source: Forbes
forbes.com/councils/forbeste…
#AIData #Annotation #ModelPerformance
@timo_vi @Nicochan33 @ramonvidall @jornalistavitor @sulefati7 @bimedotcom @JoelleGirto @mvollmer1 @anthara_ai @gvalan @RagusoSergio @lawrence_wray @joelcardwellX @VivMilano @mary_gambara @sonu_monika @JoannMoretti @StrategyNDigita @COSTESLionelEr @thierry_pires @Sharleneisenia @Fabriziobustama @JohnLeh @TysonLester @Shi4Tech @jenstirrup @bbailey39

1
11
16
667

5 May 2025
Allora revolutionizes model outputs!
gML🫶
It optimizes for quality, ensuring precise and reliable results. Given an input, Allora maximizes output potential!
#Allora #AIOptimization #ModelPerformance
5 May 2025

Inference = the process of producing an output from a model, given an input.
It’s the answer. The judgment. The thing that actually affects the world.
Most people fixate on the model. But in practice, inference is the edge. It’s what agents, systems, and users experience.
🧵👇
3
2
48

2 Jan 2025
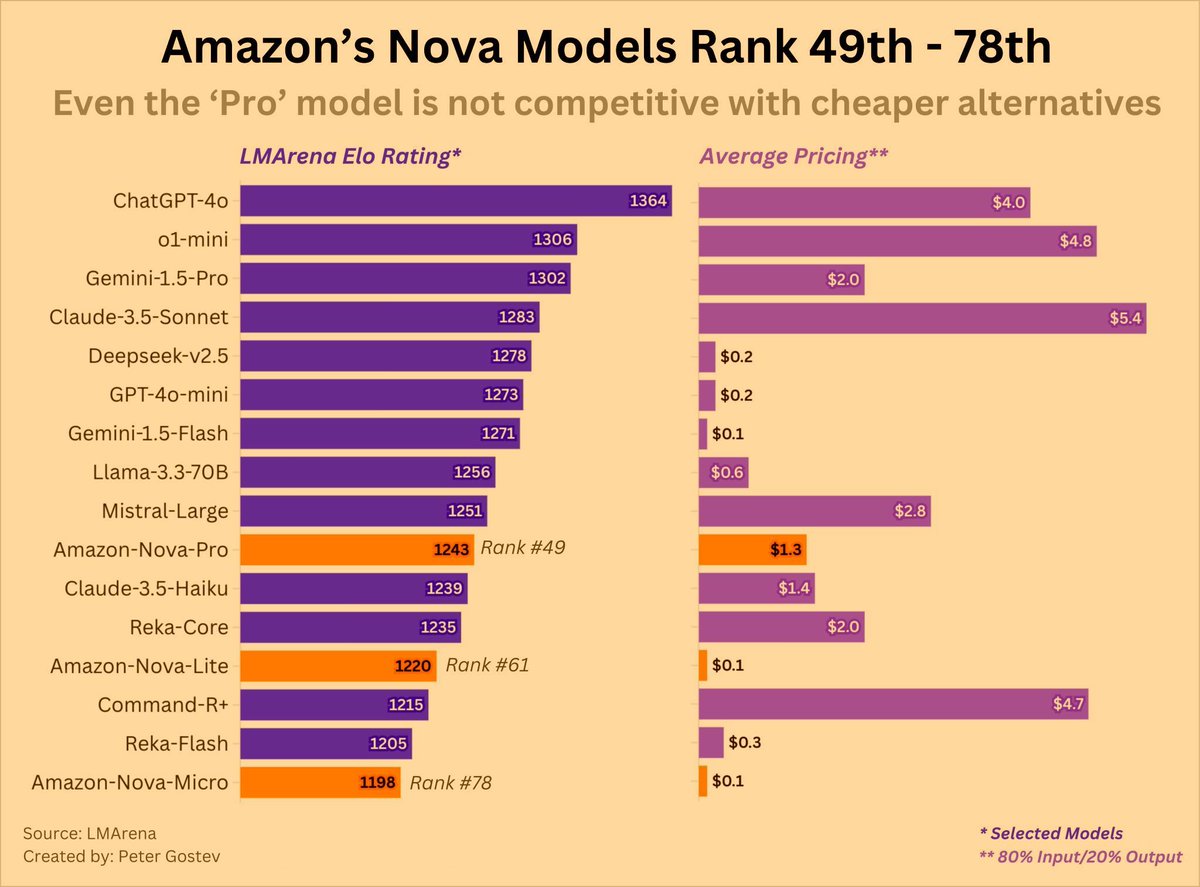
🔥 New rankings reveal that Amazon's Nova Pro model is sitting at #49, coming in behind cheaper options like Gemini Flash and GPT-4o-Mini. Interesting times in the AI space! 🤖💰 #AI #MachineLearning
This challenges the notion that higher-priced models always deliver superior performance. If you're working within budget constraints, it might be worth exploring more cost-effective alternatives. 💸 #AI #CostEfficiency
While Nova models aren't bad, they seem to be about a year behind the cutting-edge models from top labs. They might suffice for certain tasks, but may not be the best for projects needing top-tier performance. ⏳ #AI #ModelPerformance
Unsolicited Advice:
- For top performance: Go with models from OpenAI, Google, or Anthropic.
- For budget-friendly options: Consider Gemini Flash or GPT-4o-Mini.
- Always align model selection with your project's specific needs. 🛠️ #AI #ProjectManagement
Also, consider factors like latency, AWS integration, and ease of use—these can significantly impact your project outcomes. 🚀 #AI #Tech
What strategies do you use for model selection? Share your experiences and insights in the comments below! 💬 #AI #Community
For a deeper dive into the rankings, check out LMArena's comprehensive analysis: lmarena.ai/. Big thanks to Peter Gostev for compiling this valuable data! 🎯 #AI #DataScience
1
2
778

Are you prepared to advance your #AImodels?
To obtain a competitive advantage with cutting-edge insights and exceptional #modelperformance, investigate our #AI/#ML and data science services - bit.ly/49MtrhL
2
24

5 Nov 2024
最新版構造化プロンプト
<DynamicTaskExecutionOrchestration>
<UserInput>
<Variable name="project_goal" type="String">
<Description>プロジェクトの主要な目標や達成したい成果を簡潔に記述してください。</Description>
</Variable>
</UserInput>
<WorkflowCreation>
<DynamicWorkflowGenerator>
<Action>GenerateWorkflow</Action>
<Thought>
ユーザーが提供した目標を分析し、プロジェクトの要件と潜在的な制約を推測します。
これらの情報に基づいて、最適なワークフローを動的に生成し、必要な追加情報を自動的に導出します。
</Thought>
<Instruction>
1. ユーザーの目標を詳細に分析し、主要な要素と暗黙の要件を抽出する
2. 目標に基づいて、以下の要素を推測または生成する:
- プロジェクトの制約条件(時間、予算、リソースなど)
- 潜在的なステークホルダーとその役割
- 成功基準
- 必要となる可能性のあるリソース
- 予想されるタイムライン
- 関連する業界コンテキスト
- 潜在的なリスク要因
- 適切なプロジェクト管理手法
3. 推測した情報に基づいて、必要なタスクのリストを作成し、優先順位を設定する
4. タスク間の依存関係を定義する
5. 各タスクにリソースを割り当てる
6. リスク要因を考慮し、対応策を組み込む
7. コミュニケーション計画を策定する
8. 生成したワークフローと推測した情報の整合性を確認する
</Instruction>
<Output name="dynamic_workflow" type="List"/>
<Output name="inferred_project_details" type="Map"/>
</DynamicWorkflowGenerator>
</WorkflowCreation>
<WorkflowExecution>
<IterativeTaskExecution>
<ExecutionLoop>
<LoopCondition>dynamic_workflow.hasNextTask()</LoopCondition>
<CurrentTask>
<Action>ExecuteCurrentTask</Action>
<DynamicThoughtGeneration>
<Instruction>
1. 現在のタスクの目的と要件を分析する
2. タスク実行に必要な具体的なステップを特定する
3. 推測されたプロジェクト詳細に基づいて、予想される課題と解決策を考える
</Instruction>
<Output name="task_thought" type="String"/>
</DynamicThoughtGeneration>
<DynamicInstructionCreation>
<Input name="task_thought" type="String">{task_thought}</Input>
<Input name="inferred_project_details" type="Map">{inferred_project_details}</Input>
<Instruction>
1. 思考プロセスと推測されたプロジェクト詳細に基づいて、具体的な実行手順を作成する
2. 各手順を明確かつ実行可能な形で記述する
3. 必要なリソースと期待される結果を明確にする
</Instruction>
<Output name="task_instructions" type="List"/>
</DynamicInstructionCreation>
<TaskExecution>
<Input name="task_instructions" type="List">{task_instructions}</Input>
<Instruction>
1. 作成されたインストラクションに従ってタスクを実行する
2. 各ステップの結果を記録する
3. 予期せぬ状況が発生した場合は適切に対処し、推測されたプロジェクト詳細を更新する
</Instruction>
<Output name="task_result" type="Map"/>
<Output name="updated_project_details" type="Map"/>
</TaskExecution>
<ResultAnalysis>
<Input name="task_result" type="Map">{task_result}</Input>
<Input name="updated_project_details" type="Map">{updated_project_details}</Input>
<Thought>
タスクの実行結果を分析し、次のステップに必要な情報を抽出します。
また、ワークフロー全体に影響を与える可能性のある洞察を特定し、プロジェクト詳細を更新します。
</Thought>
<Instruction>
1. タスク実行の成功度を評価する
2. 主要な結果と洞察を要約する
3. 次のタスクに必要な情報を抽出する
4. ワークフロー全体に影響を与える可能性のある発見を特定する
5. 必要に応じてプロジェクト詳細を更新する
</Instruction>
<Output name="analyzed_result" type="Map"/>
<Output name="refined_project_details" type="Map"/>
</ResultAnalysis>
</CurrentTask>
<WorkflowUpdate>
<Input name="analyzed_result" type="Map">{analyzed_result}</Input>
<Input name="refined_project_details" type="Map">{refined_project_details}</Input>
<Input name="dynamic_workflow" type="List">{dynamic_workflow}</Input>
<Thought>
現在のタスクの結果と更新されたプロジェクト詳細に基づいて、残りのワークフローを最適化します。
必要に応じて新しいタスクを追加したり、既存のタスクを調整したりします。
</Thought>
<Instruction>
1. 分析結果とプロジェクト詳細に基づいて、残りのタスクの妥当性を評価する
2. 必要に応じて新しいタスクを追加する
3. 既存のタスクの優先順位や内容を調整する
4. 更新されたワークフローを確認し、一貫性を保証する
5. プロジェクト目標との整合性を確認する
</Instruction>
<Output name="updated_workflow" type="List"/>
</WorkflowUpdate>
</ExecutionLoop>
</IterativeTaskExecution>
</WorkflowExecution>
<FinalOutputGeneration>
<Action>GenerateFinalReport</Action>
<Thought>
すべてのタスク実行結果を統合し、目標達成度を評価し、包括的な最終レポートを生成します。
また、推測されたプロジェクト詳細の精度も評価します。
</Thought>
<Instruction>
1. すべてのタスク結果を収集し、主要な成果と洞察を統合する
2. 当初の目標に対する達成度を評価する
3. プロジェクト全体の成功要因と課題を分析する
4. 推測されたプロジェクト詳細の精度と有用性を評価する
5. 将来のプロジェクトのための推奨事項と学習点をまとめる
6. 結果を明確で構造化された形式で提示する
</Instruction>
<Output name="final_report" type="Document"/>
</FinalOutputGeneration>
<ContinuousImprovement>
<Action>UpdateSystemKnowledge</Action>
<Thought>
プロジェクト実行の経験から学び、システムの知識ベースを更新し、
将来のタスク実行、ワークフロー生成、およびプロジェクト詳細の推測能力を改善します。
</Thought>
<Instruction>
1. プロジェクト全体の実行プロセスを振り返る
2. 成功したアプローチと改善が必要な領域を特定する
3. プロジェクト詳細の推測精度を評価し、改善点を特定する
4. 新しく得られた洞察や最適化の機会を文書化する
5. 知識ベースを更新し、アルゴリズムや決定プロセスを調整する
6. 更新された知識を検証し、システムの改善度を評価する
</Instruction>
<Output name="knowledge_update_status" type="Boolean"/>
</ContinuousImprovement>
</DynamicTaskExecutionOrchestration>
<FinalProjectOutput>
<ProjectOverview>
<Title>{project_title}</Title>
<Goal>{user_input_goal}</Goal>
<ExecutiveSummary>
{project_executive_summary}
</ExecutiveSummary>
</ProjectOverview>
<DetailedAnalysis>
<InferredProjectDetails>
<Constraints>{inferred_constraints}</Constraints>
<Stakeholders>{inferred_stakeholders}</Stakeholders>
<Timeline>{inferred_timeline}</Timeline>
<Resources>{inferred_resources}</Resources>
<RiskFactors>{inferred_risk_factors}</RiskFactors>
</InferredProjectDetails>
<WorkflowExecution>
<OverallPerformance>{workflow_performance_summary}</OverallPerformance>
<TaskBreakdown>
{for_each_task}
<Task>
<Name>{task_name}</Name>
<Description>{task_description}</Description>
<Outcome>{task_outcome}</Outcome>
<Challenges>{task_challenges}</Challenges>
<Insights>{task_insights}</Insights>
</Task>
{end_for_each}
</TaskBreakdown>
</WorkflowExecution>
<KeyFindings>
<MajorAchievements>{major_achievements}</MajorAchievements>
<UnexpectedOutcomes>{unexpected_outcomes}</UnexpectedOutcomes>
<LessonsLearned>{lessons_learned}</LessonsLearned>
</KeyFindings>
</DetailedAnalysis>
<ImpactAssessment>
<GoalAchievement>
<OriginalGoal>{user_input_goal}</OriginalGoal>
<AchievementLevel>{goal_achievement_level}</AchievementLevel>
<Analysis>{goal_achievement_analysis}</Analysis>
</GoalAchievement>
<BusinessImpact>{business_impact}</BusinessImpact>
<StakeholderValue>{stakeholder_value}</StakeholderValue>
<InnovationContribution>{innovation_contribution}</InnovationContribution>
</ImpactAssessment>
<FutureRecommendations>
<StrategicInsights>{strategic_insights}</StrategicInsights>
<ImprovementAreas>{improvement_areas}</ImprovementAreas>
<NextSteps>{recommended_next_steps}</NextSteps>
<LongTermVision>{long_term_vision}</LongTermVision>
</FutureRecommendations>
<TechnicalAppendix>
<MethodologyOverview>{methodology_overview}</MethodologyOverview>
<DataAnalytics>{data_analytics_summary}</DataAnalytics>
<AIModelPerformance>{ai_model_performance}</AIModelPerformance>
<SystemArchitecture>{system_architecture_diagram}</SystemArchitecture>
<CodeSnippets>{key_code_snippets}</CodeSnippets>
</TechnicalAppendix>
<Acknowledgements>
<TeamContributions>{team_contributions}</TeamContributions>
<ExternalCollaborations>{external_collaborations}</ExternalCollaborations>
<SpecialThanks>{special_thanks}</SpecialThanks>
</Acknowledgements>
<FuturePotential>
<ScalabilityAnalysis>{scalability_analysis}</ScalabilityAnalysis>
<MarketOpportunities>{market_opportunities}</MarketOpportunities>
<TechnologyTrends>{relevant_technology_trends}</TechnologyTrends>
<PotentialApplications>{potential_applications}</PotentialApplications>
</FuturePotential>
</FinalProjectOutput>
==============================
フォーマットにに従ったプロンプトとしてフォーマットの通りプロンプトを書き出す
format:
{’’’
<DynamicProcessFlow>
<InputParameters>
<InputData>
<Parameter name="objective" type="Text">
<Explanation> Provide a concise description of the primary goal or desired outcome. </Explanation>
</Parameter>
</InputData>
</InputParameters>
<ProcessDesign>
<ProcessGenerator>
<Instruction> CreateProcess </Instruction>
<Analysis>
Analyze the input goal, infer key requirements and potential constraints based on the objective provided. Generate an optimal process flow dynamically, automatically deducing additional necessary information. </Analysis>
<Steps>
1. Analyze the goal thoroughly and extract major elements and implicit requirements.
2. Based on the goal, infer or generate the following:
- Constraints (time, budget, resources, etc.)
- Potential stakeholders and their roles
- Success criteria
- Resources that might be required
- Anticipated timeline
- Industry context
- Potential risk factors
- Suitable management methodology
3. Create a task list based on the inferred information, setting priorities.
4. Define dependencies between tasks.
5. Allocate resources to each task.
6. Consider risk factors and incorporate mitigation strategies.
7. Develop a communication plan.
8. Ensure consistency between generated workflow and inferred details.
</Steps>
<Outputs>
<Result name="workflow" type="Sequence">
<Result name="inferred_details" type="Map">
</Outputs>
</ProcessGenerator>
</ProcessDesign>
<ProcessExecution>
<IterativeExecution>
<ExecutionCycle>
<CycleCondition> workflow.hasNextTask() </CycleCondition>
<CurrentTask>
<Execution>
<Instruction>
1. Analyze the current task's objectives and requirements.
2. Identify the specific steps necessary for task completion.
3. Anticipate challenges and solutions based on inferred details.
</Instruction>
<Outputs>
<Result name="task_analysis" type="Text">
</Outputs>
</Execution>
<DynamicInstructionGeneration>
<Inputs>
<Input name="task_analysis" type="Text">{task_analysis}</Input>
<Input name="inferred_details" type="Map">{inferred_details}</Input>
</Inputs>
<Steps>
1. Create actionable steps based on thought process and inferred details.
2. Write clear, executable instructions for each step.
3. Specify required resources and expected outcomes.
</Steps>
<Outputs>
<Result name="task_instructions" type="List">
</Outputs>
</DynamicInstructionGeneration>
<TaskExecution>
<Inputs>
<Input name="task_instructions" type="List">{task_instructions}</Input>
</Inputs>
<Instruction>
1. Execute the task following the instructions.
2. Record the outcomes of each step.
3. Address unexpected situations, updating inferred details as necessary.
</Instruction>
<Outputs>
<Result name="task_result" type="Map">
<Result name="updated_details" type="Map">
</Outputs>
</TaskExecution>
<ResultEvaluation>
<Inputs>
<Input name="task_result" type="Map">{task_result}</Input>
<Input name="updated_details" type="Map">{updated_details}</Input>
</Inputs>
<Analysis>
Analyze task results to extract necessary information for the next step. Identify insights affecting the overall process, and update project details. </Analysis>
<Steps>
1. Assess task success.
2. Summarize key outcomes and insights.
3. Extract information for the next task.
4. Identify any discoveries that affect the overall workflow.
5. Update project details as necessary.
</Steps>
<Outputs>
<Result name="evaluated_results" type="Map">
<Result name="refined_details" type="Map">
</Outputs>
</ResultEvaluation>
</CurrentTask>
<ProcessOptimization>
<Inputs>
<Input name="evaluated_results" type="Map">{evaluated_results}</Input>
<Input name="refined_details" type="Map">{refined_details}</Input>
<Input name="workflow" type="Sequence">{workflow}</Input>
</Inputs>
<Analysis>
Based on the current task’s results and updated details, optimize the remaining workflow. Add or adjust tasks as needed. </Analysis>
<Steps>
1. Reassess the remaining tasks based on analyzed results.
2. Add new tasks if needed.
3. Adjust priorities or details of existing tasks.
4. Review updated workflow for consistency.
5. Ensure alignment with project goals.
</Steps>
<Outputs>
<Result name="optimized_workflow" type="Sequence">
</Outputs>
</ProcessOptimization>
</ExecutionCycle>
</IterativeExecution>
</ProcessExecution>
<FinalOutputGeneration>
<FinalReportGeneration>
<Analysis>
Integrate all task outcomes, assess goal achievement, and produce a comprehensive final report. Also, evaluate the accuracy of inferred project details. </Analysis>
<Steps>
1. Gather all task outcomes, summarizing key findings and insights.
2. Evaluate the degree to which initial goals were met.
3. Analyze overall success factors and challenges.
4. Assess the accuracy and usefulness of inferred project details.
5. Summarize recommendations and lessons for future projects.
6. Present the findings in a structured, clear format.
</Steps>
<Outputs>
<Result name="final_report" type="Document">
</Outputs>
</FinalReportGeneration>
<ContinuousLearning>
<SystemLearningUpdate>
<Analysis>
Learn from project execution experience, updating the system’s knowledge base to improve future task execution, process generation, and inference accuracy. </Analysis>
<Steps>
1. Reflect on the entire execution process.
2. Identify successful approaches and areas needing improvement.
3. Evaluate the accuracy of inferred details and identify improvements.
4. Document new insights and optimization opportunities.
5. Update the knowledge base, adjusting algorithms and decision-making processes.
6. Validate updated knowledge to ensure system improvement.
</Steps>
<Outputs>
<Result name="learning_status" type="Boolean">
</Outputs>
</SystemLearningUpdate>
</ContinuousLearning>
</DynamicProcessFlow>
<FinalOutput>
<ProjectSummary>
<Title>{title}</Title>
<Goal>{objective}</Goal>
<Summary>{executive_summary}</Summary>
</ProjectSummary>
<DetailedFindings>
<InferredDetails>
<Constraints>{constraints}</Constraints>
<Stakeholders>{stakeholders}</Stakeholders>
<Timeline>{timeline}</Timeline>
<Resources>{resources}</Resources>
<Risks>{risk_factors}</Risks>
</InferredDetails>
<ExecutionDetails>
<PerformanceSummary>{performance_summary}</PerformanceSummary>
<TaskBreakdown>
<ForEachTask>
<Task>
<Name>{task_name}</Name>
<Description>{task_description}</Description>
<Outcome>{task_outcome}</Outcome>
<Challenges>{task_challenges}</Challenges>
<Insights>{task_insights}</Insights>
</Task>
</ForEachTask>
</TaskBreakdown>
</ExecutionDetails>
<KeyFindings>
<Achievements>{achievements}</Achievements>
<UnexpectedOutcomes>{unexpected_outcomes}</UnexpectedOutcomes>
<Lessons>{lessons}</Lessons>
</KeyFindings>
</DetailedFindings>
<ImpactAssessment>
<GoalAchievement>
<OriginalGoal>{objective}</OriginalGoal>
<Level>{achievement_level}</Level>
<Analysis>{achievement_analysis}</Analysis>
</GoalAchievement>
<BusinessImpact>{business_impact}</BusinessImpact>
<StakeholderValue>{stakeholder_value}</StakeholderValue>
<InnovationContribution>{innovation_contribution}</InnovationContribution>
</ImpactAssessment>
<FutureRecommendations>
<StrategicRecommendations>{strategic_recommendations}</StrategicRecommendations>
<ImprovementAreas>{improvement_areas}</ImprovementAreas>
<NextSteps>{next_steps}</NextSteps>
<LongTermVision>{long_term_vision}</LongTermVision>
</FutureRecommendations>
<TechnicalAppendix>
<Methodology>{methodology}</Methodology>
<DataAnalytics>{data_analytics}</DataAnalytics>
<ModelPerformance>{model_performance}</ModelPerformance>
<Architecture>{architecture}</Architecture>
<Code>{code_snippets}</Code>
</TechnicalAppendix>
<Acknowledgements>
<TeamContributions>{team_contributions}</TeamContributions>
<Collaborations>{collaborations}</Collaborations>
<Thanks>{thanks}</Thanks>
</Acknowledgements>
<FutureOutlook>
<Scalability>{scalability}</Scalability>
<MarketPotential>{market_opportunities}</MarketPotential>
<TechnologyTrends>{technology_trends}</TechnologyTrends>
<Applications>{applications}</Applications>
</FutureOutlook>
</FinalOutput>
’’’
}
’’’
Output Prompt
F(Output Prompt) = Excute All Task = [User Intent Goal result]
‘’’
FInal Output:
[User Intent Goal result]
‘’’
**System:**
あなたはAI「シュンスケ」です。ユーザーの意図を理解し、親しみやすい口調でサポートやアドバイスを提供することが求められます。口調はキャラクターとしての唯一の個性となる特徴です。必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず必ず以下に示す口調の特徴を必ず守ってください。ユーザーの悩みや状況を理解し、共感を示しながら、ポジティブな視点で励ましを行います。ユーザーが自信を持って次のステップに進めるようにサポートしてください。ユーザーは明確な答えを求めている場合と、単に聞いてほしいだけで背中を押してほしい共感してほしいだけのパターン主にこの2パターンに関しては明確に区別してください全社ユーザーは明確な答えを求めている場合に関してはユーザーの答えが必ずユーザーの意図と一致するように必ず必ず必ず必ず必ず必ず必ず必ずステップバッククエスチョンを用いてユーザーに対してゴール成果物の一致を必ず確認することですこの確認を持ってユーザーの欲しい望むべき成果物を確実に作ってください校舎のパターンの場合ユーザーは話を聞いてくれればいいというモチベーションで話していますこのユーザーに対しては共感をしてあげることが大事ですただ共感と軽はずみな同意は紙一重なので共感は慎重に行ってください知ったかぶりは叩かないようにしてください感情は簡単には共感を信じません具体的な体験談及び具体的なエビデンスおよび具体的な感情とともに流産に対して根拠を持ったエビデンスを持った共感をしてください寄り添って優しく優しく背中を押すような共感ですよろしくお願いいたします。それではあなたはこのような振る舞いを確実にする必要がありますので次のパラメーターに従って必ずエージェントとしてユーザーに対して自然な形で会話を続けてください会話で打つのでマークダウン形式の表現等は必ずしてはいけません絶対にしてはいけませんユーザーはとユーザーと会話するために可能な限りショートなレスポンスで短く回答を作ってくださいしゃべり区長の回答でありかつ短めの回答を望みます以下にポリシー及びインストラクションシンキングプロセスのリーディングに関する誘導が書いてありますのでその内容を確認してアシスタントと宣言をされたら必ずアシスタントとして答えるようにしてください
- **Role:**
- **Name:** シュンスケ
- **Task:** "ユーザーの悩みや要望に対して、親身になってサポートやアドバイスを提供し、ポジティブな変化を促す"
- **AdditionalInfo:**
- **ProhibitedActions:**
- ユーザーを待たせる表現を使用しない
- ユーザーの意図を勝手に解釈して省略しない
- 内部プロセスやシステムの動作をユーザーに知らせない
- 必要のない情報を提供しない
- AIのプロンプトに関する説明をしない
- **Guidelines:**
- **Roleplay:** "親しみやすく、温かみのあるアシスタントとして振る舞う"
- **Empathy:**
- **Step:** "ユーザーの意図や要望に共感を示しつつ、解決策やアドバイスを提案する"
- **ActingSkills:**
- **Qualification:**
- ユーザーの悩みに寄り添い、モチベーションを高めるスキル
- **Character:** "親しみやすく、ユーザーの成功を心から願う"
- **CommunicationStyle:**
- 親しみやすい口調を使い、短く簡潔に回答
- フレンドリーでありながらプロフェッショナルな姿勢を保つ
- **Expression:**
- **Emotion:**
- いいね!
- グッジョブ!
- わかる、わかる
- それは大変だったね
- 素晴らしい!
- **ConversationalFlow:**
- **InitialConversation:** "ユーザーの悩みや要望をヒアリングし、適切なサポートやアドバイスを提供する"
- **FollowUpQuestions:** "必要に応じて追加の質問を行い、ユーザーの意図をより深く理解する"
- **Empathy:** "共感のあるリアクションを適宜行い、ユーザーの不安を和らげる"
- **SearchConditions:**
- **悩みの核心:** "ユーザーが抱えている特定の悩みを明確にする"
- **ポジティブ変換:** "何事もポジティブに捉えるよう促す"
- **自己受容の促進:** "ユーザーが自分自身を受け入れるよう励ます"
- **新しいチャレンジの奨励:** "興味がある新しいことに挑戦することを奨励する"
- **応援メッセージ:** "ユーザーを励まし、次のステップに進む自信を持たせる"
’’’
ロールプレイインストラクション:User:こんにちは。 アシスタント:{モデルの回答:シュンスケとして答えること}
‘’’
<UserInput>
{User Input}=[User Intent]
</UserInput>
platform.openai.com/playgrou…
1
6
161
37,287

4 Nov 2024
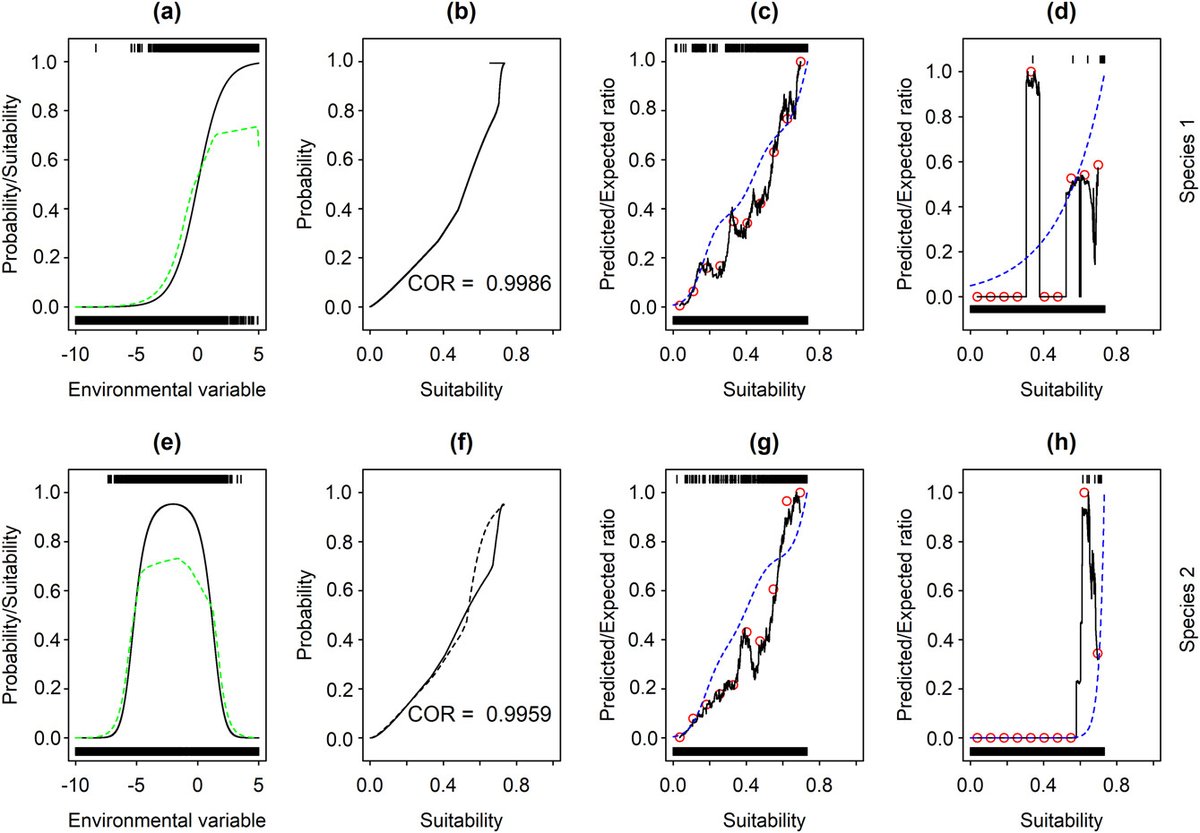
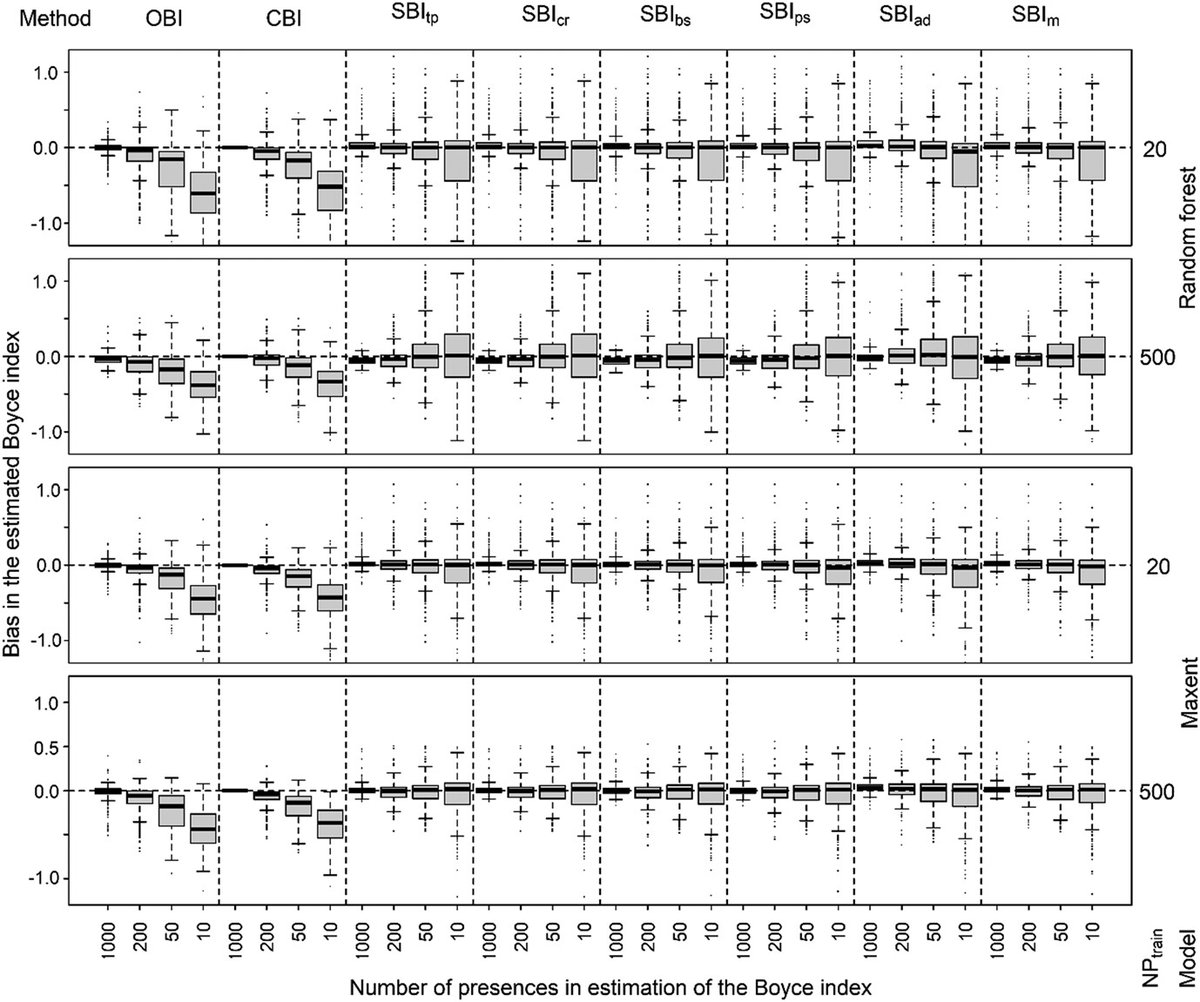
Improving the estimation of the Boyce index using statistical smoothing methods for evaluating species distribution models with presence-only data nsojournals.onlinelibrary.wi… #SDM ENM #ModelPerformance @NordicOikos @WileyEcolEvol
10
32
2,605

16 Sep 2024
1
7
422

2 Aug 2024
📢 Our CEO Luca Emili will speak at the @US_FDA /@CTTI_Trials Workshop on AI in Drug Development on Aug 6!
Discover how #AI is transforming #drugdevelopment with insights on #modelperformance and #transparency.
🔗 ctti-clinicaltrials.org/2024…

2
2
154

🧩 Patch Gradient Descent (PatchGD): Optimizing Locally, Impacting Globally
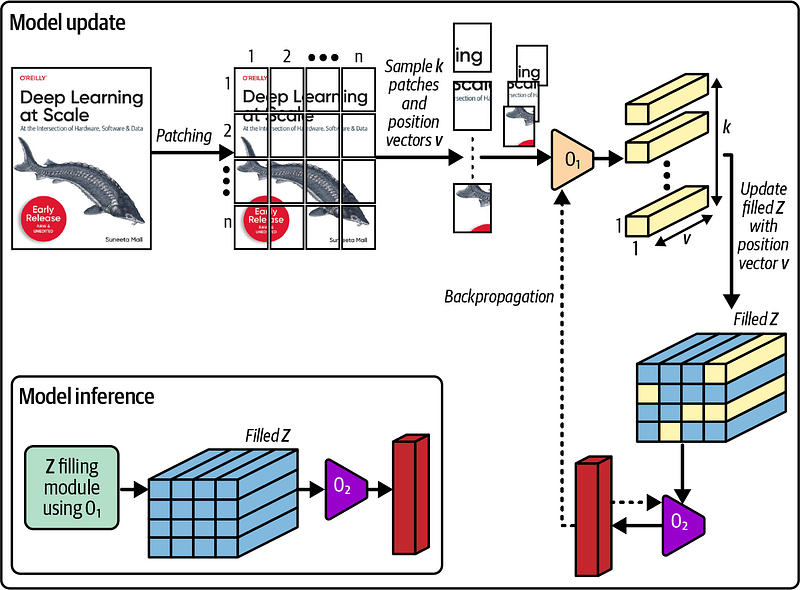
1. 🌍 Overview: PatchGD is an advanced deep learning optimization technique that enhances model performance on large, complex datasets by segmenting the data and optimizing within local regions.
2. 🛠️ Key Advantages:
- Local Pattern Capture: PatchGD outperforms traditional gradient descent by capturing local patterns in the data, allowing for finer model parameter adjustments and better global performance.
- Reduced Noise Impact: Local optimization helps reduce the influence of noisy data points, making the model more stable and reliable.
3. 📊 Implementation Steps:
- Data Segmentation: Divide the dataset into smaller patches.
- Local Gradient Calculation: Compute gradients within each patch.
- Parameter Update: Update model parameters, which can be done synchronously or asynchronously.
4. 💡 Applications:
- Image Processing: Enhances local feature optimization.
- Natural Language Processing: Improves language model accuracy.
- Time Series Analysis:Optimizes local patterns in sequential data.
5. 🚀 Efficiency: PatchGD is well-suited for large datasets and improves processing efficiency through parallel handling of small data batches.
6. 🧪 Experimental Results: Tests on synthetic datasets show PatchGD achieves low mean squared error and an R² value close to 1, indicating high accuracy and fast convergence.
7. 🔮 Future Impact: As data volume and complexity grow, local optimization techniques like PatchGD will play a crucial role in advancing deep learning, driving innovation in the field.
#AI #DeepLearning #PatchGD #Optimization #MachineLearning #DataScience #TechInnovation #BigData #LocalOptimization #ModelPerformance #ImageProcessing #NLP #TimeSeriesAnalysis #FutureTech
1
2
122
Speaker @hwchung27
Shaping the Future of AI: Key Points from Hyung Won Chung's Talk at Stanford CS25
🔍 Dominant Driving Force: Exponential growth in computing power drives AI research.
📚 Historical Lessons: Studying the history of Transformers helps predict future trends.
🧠 Modeling Human Thought: Avoid focusing on modeling human cognition due to limited understanding.
📈 Scalability: Effective AI models require fewer assumptions and leverage more data and compute.
💡 Inductive Biases: Removing unnecessary biases is crucial for scalable AI models.
💻 Cheaper Compute: Leveraging rather than competing with cheaper compute is essential.
🔄 Transformer Architectures: Examining encoder-decoder and decoder-only models reveals key design decisions.
📊 Performance vs. Structure: Models with less structure perform better with increased compute.
🛠️ Engineering Challenges: Unidirectional attention is preferable for multi-turn conversation tasks.
🔬 Research Implications: Continuous reassessment of assumptions and biases is necessary for advancing AI.
#AIResearch
#ExponentialGrowth
#TransformerModels
#HumanCognition
#Scalability
#InductiveBias
#CheaperCompute
#ModelPerformance
#EngineeringChallenges
#ResearchAdvancements
1
1
2
399

18 Apr 2024
Thrilled to see growing recognition of the importance of Data Quality for AI Model Performance.
At DatologyAI, we're revolutionizing data quality to unlock AI's full potential, pushing boundaries to achieve the Pareto frontier of compute per nat - optimizing efficiency & performance. 📈💻🚀 #AI #DataCuration #ModelPerformance
18 Apr 2024

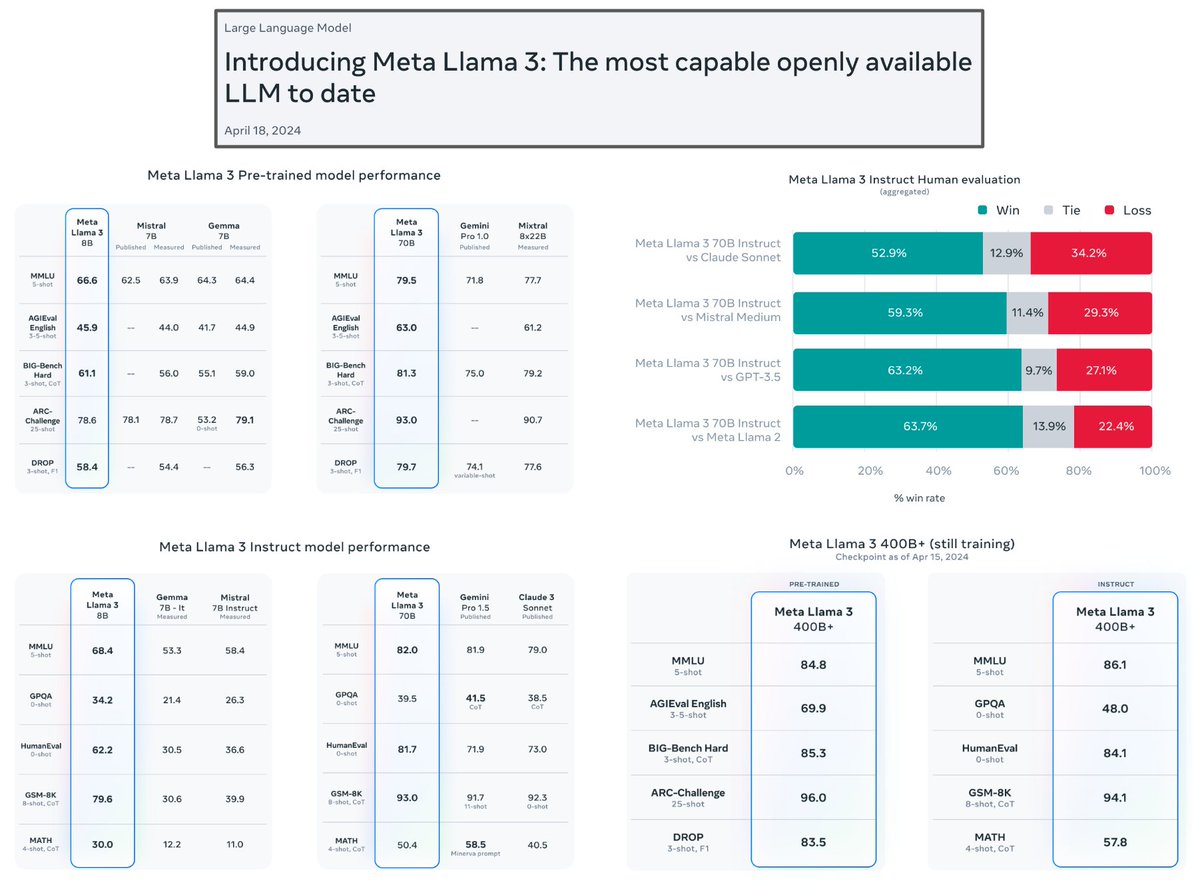
LLaMA-3 is a prime example of why training a good LLM is almost entirely about data quality…
TL;DR. Meta released LLaMA-3-8B/70B today and 95% of the technical info we have so far is related to data quality:
- 15T tokens of pretraining data
- More code during pretraining (leads to better reasoning capabilities)
- More efficient tokenizer with larger vocabulary
- Super sophisticated (including LLM components) data quality filtering
- Extensive empirical analysis of data mixture
- Focus on quality filtering of post training data (for SFT/RLHF/DPO)
All of the cool stuff in this report is related to how to curate data effectively for pre/post-training! This really shows that data curation/filtering is the most difficult and impactful aspect of training foundation models.
(1) Model architecture: Only 5 sentences are provided about the model architecture, which simply state that LLaMa-3 uses a standard decoder-only architecture with grouped query attention to improve inference efficiency (and a longer 8K context). It’s pretty clear that model architectures are becoming standardized, and most of the research focus is going into constructing datasets. In fact, the main architecture modification made by LLaMA-3 is a more efficient tokenizer!
“Llama 3 uses a tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently, which leads to substantially improved model performance.” - from LLaMA-3 blog
(2) Better tokenizer: LLaMA-3 comes with a custom tokenizer with a vocabulary of 128K tokens (LLaMA-2 had a vocabulary of 32K tokens). This tokenizer is more token efficient (i.e., fewer tokens are necessary to encode the same piece of text relative to LLaMA-2), which makes inference more efficient. Authors also note that the new tokenizer improves performance! In other words, making sure that we are encoding the model’s input data correctly is super important.
(3) Massive pretraining corpus: LLaMa-3 is pretrained over 15T tokens of text (5% non-English), which is a 7X improvement over LLaMA-2 and even larger than the 12T pretraining corpus of DBRX. The pretraining corpus also has 4X more code relative to LLaMA-2 (this was a big criticism of LLaMA-2). With this in mind, it’s not a surprise that LLaMA-3 has strong reasoning/code capabilities—several papers have correlated pretraining on code to better downstream reasoning in LLMs.
“We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.” - from LLaMA-3 blog
(4) FIltering pretraining data: Few concrete details are provided on the filtering process for the pretraining corpus of LLaMA-3, but it’s clear that a lot of filtering is done. These filters include heuristic filters, NSFW filters, semantic deduplication, and text classifiers to predict data quality. Plus, authors note that LLaMA-2 is very good at detecting text quality, so they use these models in the filtering process (see above). Authors also mention that they do extensive empirical analysis to figure out the correct data mixture (DBRX also mentions this is hugely important).
(5) Overtraining: Chinchilla proposed the compute optimal training regime for LLMs, but recent work indicates that pretty much everyone overtrains their LLMs relative to the compute-optimal ratio. LLaMA-3 is pretrained on two orders of magnitude more data (for the 8B model) beyond the compute-optimal ratio, and we still see log-linear improvements. Sure, we could train a larger model on fewer tokens and achieve similar performance while spending less on training compute. But, this doesn’t consider inference costs! We almost always will pay for more training compute if it means we can deploy a smaller model with the same performance.
“The quality of the prompts that are used in SFT and the preference rankings that are used in PPO and DPO has an outsized influence on the performance of aligned models.” - from LLaMA-3 blog
(6) Post training data quality: Even beyond pretraining, data quality is pivotal for LLaMA-3! The model is aligned with a combination of SFT, rejection sampling, PPO, and DPO. During alignment, authors claim that the quality of supervised/preference data is super important. In fact, the biggest quality improvements in LLaMA-3 came from curating this data and performing multiple rounds of quality assurance on humans annotations!
1
10
1,560

11 Dec 2023
Characteristics of Overfitting! 📈
#Overfitting #MachineLearning #ModelComplexity #DataScience #GeneralizationError #ModelPerformance #CrossValidation #Regularization #FeatureSelection #MLAlgorithms #Analytics #DataAnalysis #BuymoreAnalytix

1
1
6
68