
Jun 9
Most researchers waste hours on repetitive bioinformatics tasks that don’t require deep thinking: fetching gene sets, choosing between GSVA and ssGSEA, running differential tests, and formatting publication-ready figures.
→ github.com/aipoch/medical-re…
AIPOC H’s GSVA Pathway Analysis skill removes this friction.
You simply upload your expression matrix and group file, then describe what you want in natural language. The agent handles the rest:
• Automatically retrieves curated gene sets from MSigDB (KEGG, REACTOME, Hallmark, etc.)
• Selects the appropriate scoring method based on your dataset characteristics
• Performs limma-based differential pathway analysis with FDR correction
• Outputs ranked results tables and a clean, clustered heatmap ready for figures or further exploration
In the demo, it processed a colorectal cancer bulk RNA-seq dataset (GSE44076, 148 samples), scored 186 KEGG pathways, identified significantly altered pathways between tumor and healthy groups, and delivered both the statistical results and a high-quality heatmap — all within minutes.
The real value isn’t just speed. It’s consistency and reproducibility: every step follows established best practices without requiring you to maintain custom scripts or remember parameter details.
For researchers who want to spend less time on data wrangling and more time on biological interpretation, this is the kind of agent workflow that actually moves the needle.
Part of a growing library of 550 structured medical research agent skills.
#Bioinformatics #RNAseq #PathwayAnalysis #ResearchTools #AIPOCH
2
1,062

This is a crucial point in the field. While pathway analysis can be insightful for genetic studies, applying the same framework to metabolomics without adjustment can lead to inaccuracies. Metabolites often interact in complex ways that differ from the genetic models, which requires novel analytical approaches. Has there been any development of new tools or methods that address this gap? For comprehensive discussions and reviews on topics like this, you might want to check out Sci-Quest, a one-stop platform for every biomedical question: sciqst.com. #Metabolomics #PathwayAnalysis #Medicine
1
113

23 Jun 2025
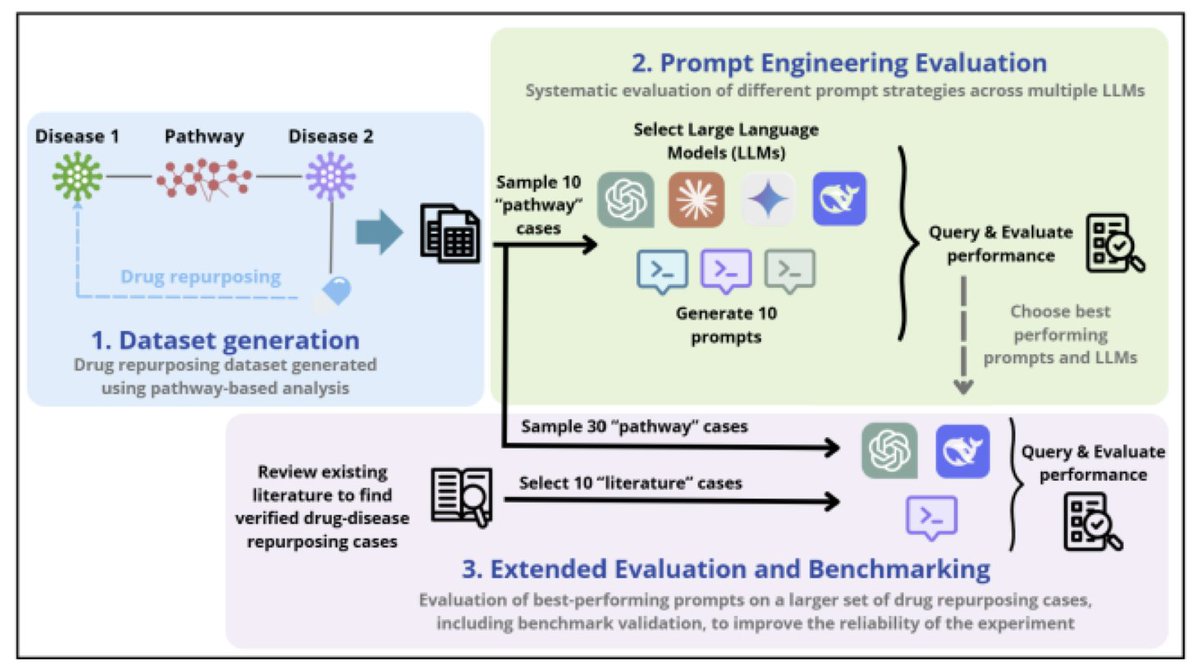
Accelerating Drug Repurposing with AI: The Role of Large Language Models in Hypothesis Validation
1.This study evaluates how Large Language Models (LLMs) can help validate drug repurposing hypotheses by analyzing biomedical literature. GPT-4o and DeepSeek stood out as the most reliable models when guided by well-designed prompts.
2.By using a pathway-based method to propose 21,968 drug-disease associations, the authors narrowed down to 30 representative cases and tested how well LLMs can classify them as viable or non-viable, simulating expert review.
3.They tested 10 different prompt strategies across 4 LLMs: GPT-4o, Claude-3, Gemini-2, and DeepSeek. The most effective strategies involved Chain-of-Thought reasoning, Few-shot examples, and Explicit Reasoning, confirming prior insights in biomedical NLP.
4.Among LLMs, GPT-4o had the best overall accuracy (83%) and precision, while DeepSeek had the best balance of precision (81%) and recall (92%). Claude-3 and Gemini-2 underperformed by comparison.
5.The best prompts (Few-shot, Chain-of-Thought, and Explicit Reasoning) significantly improved F1 scores, with structured prompts outperforming Zero-shot settings. This highlights the importance of carefully crafted prompt design.
6.In a second phase, the authors evaluated these top prompts on 30 new pathway-based repurposing cases. GPT-4o again had the best precision, while DeepSeek showed superior recall—useful in exploratory settings where false negatives are costly.
7.A third evaluation phase used 10 benchmark drug-disease repurposing cases based on established literature. Here, both GPT-4o and DeepSeek achieved near-perfect accuracy and F1 scores (0.92), suggesting strong alignment with existing biomedical knowledge.
8.Prompt impact was lower in benchmark cases, implying LLMs are more confident and consistent with well-documented associations—likely due to their alignment with LLM training data.
9.An illustrative example: LLMs identified verapamil as a viable candidate for diabetes mellitus through shared pathways, a prediction supported by the literature. Conversely, paclitaxel was correctly rejected for obesity, despite a shared pathway, due to toxicity concerns.
10.Overall, LLMs showed clear potential to assist in the early stages of drug repurposing by filtering viable candidates and reducing reliance on exhaustive manual review. Human oversight remains critical to manage hallucination and false positives.
11.Limitations include small dataset size, lack of fine-tuning, and citation hallucinations. Future work should explore biomedical fine-tuning and retrieval-augmented generation to boost credibility and reduce spurious claims.
💻Code: github.com/iratxe-zunzunegui…
📜Paper: biorxiv.org/content/10.1101/…
#DrugRepurposing #LLM #AIinMedicine #PromptEngineering #BiomedicalNLP #GPT4o #DeepSeek #PathwayAnalysis
6
22
1,459
23 Jun 2025
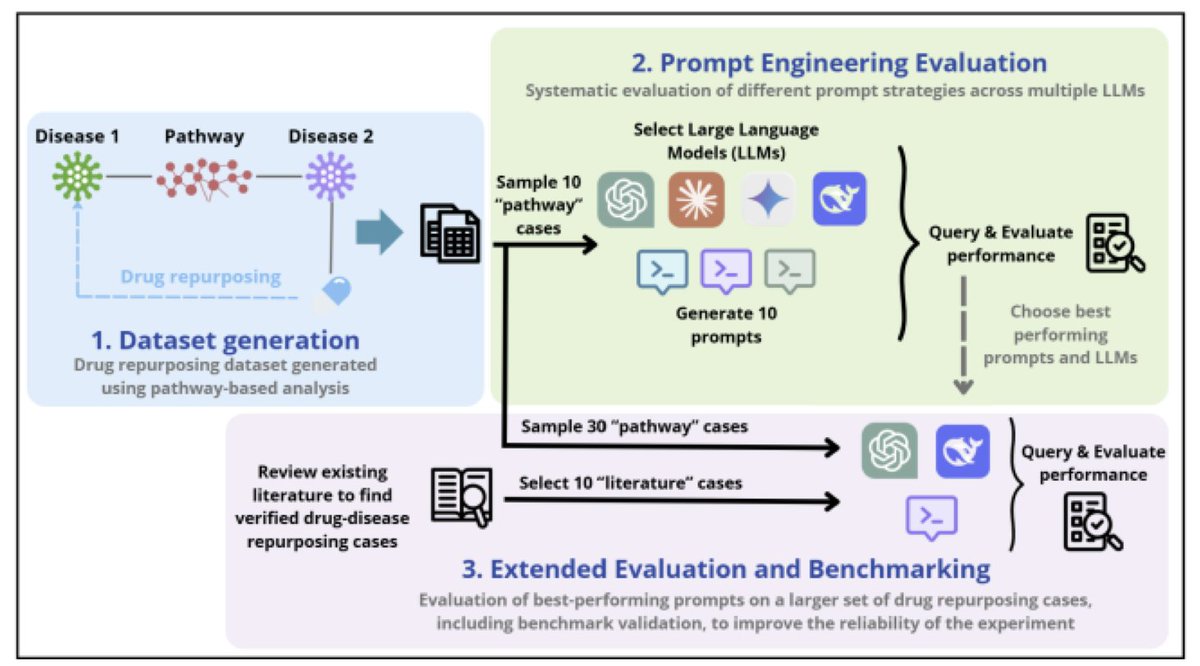
Accelerating Drug Repurposing with AI: The Role of Large Language Models in Hypothesis Validation
1.This study evaluates how Large Language Models (LLMs) can help validate drug repurposing hypotheses by analyzing biomedical literature. GPT-4o and DeepSeek stood out as the most reliable models when guided by well-designed prompts.
2.By using a pathway-based method to propose 21,968 drug-disease associations, the authors narrowed down to 30 representative cases and tested how well LLMs can classify them as viable or non-viable, simulating expert review.
3.They tested 10 different prompt strategies across 4 LLMs: GPT-4o, Claude-3, Gemini-2, and DeepSeek. The most effective strategies involved Chain-of-Thought reasoning, Few-shot examples, and Explicit Reasoning, confirming prior insights in biomedical NLP.
4.Among LLMs, GPT-4o had the best overall accuracy (83%) and precision, while DeepSeek had the best balance of precision (81%) and recall (92%). Claude-3 and Gemini-2 underperformed by comparison.
5.The best prompts (Few-shot, Chain-of-Thought, and Explicit Reasoning) significantly improved F1 scores, with structured prompts outperforming Zero-shot settings. This highlights the importance of carefully crafted prompt design.
6.In a second phase, the authors evaluated these top prompts on 30 new pathway-based repurposing cases. GPT-4o again had the best precision, while DeepSeek showed superior recall—useful in exploratory settings where false negatives are costly.
7.A third evaluation phase used 10 benchmark drug-disease repurposing cases based on established literature. Here, both GPT-4o and DeepSeek achieved near-perfect accuracy and F1 scores (0.92), suggesting strong alignment with existing biomedical knowledge.
8.Prompt impact was lower in benchmark cases, implying LLMs are more confident and consistent with well-documented associations—likely due to their alignment with LLM training data.
9.An illustrative example: LLMs identified verapamil as a viable candidate for diabetes mellitus through shared pathways, a prediction supported by the literature. Conversely, paclitaxel was correctly rejected for obesity, despite a shared pathway, due to toxicity concerns.
10.Overall, LLMs showed clear potential to assist in the early stages of drug repurposing by filtering viable candidates and reducing reliance on exhaustive manual review. Human oversight remains critical to manage hallucination and false positives.
11.Limitations include small dataset size, lack of fine-tuning, and citation hallucinations. Future work should explore biomedical fine-tuning and retrieval-augmented generation to boost credibility and reduce spurious claims.
💻Code:
github.com/iratxe-zunzunegui…
📜Paper: biorxiv.org/content/10.1101/…
#DrugRepurposing #LLM #AIinMedicine #PromptEngineering #BiomedicalNLP #GPT4o #DeepSeek #PathwayAnalysis
2
9
712
6 Jun 2025
Knowledge-guided Contextual Gene Set Analysis Using Large Language Models
1.The article presents the Contextualized Gene Set Analysis (cGSA), an AI-driven framework designed to improve gene set analysis (GSA) by incorporating contextual information to enhance the relevance and accuracy of pathway predictions.
2.cGSA integrates large language models (LLMs) with traditional GSA methods, prioritizing pathways based not only on statistical significance but also biological relevance to the experimental context and research objectives.
3.Through a robust workflow, cGSA first clusters genes using protein-protein interaction (PPI) networks, then performs enrichment analysis on these clusters. This process helps mitigate the overrepresentation of hub genes in results, a common problem in traditional GSA methods.
4.One of the key innovations of cGSA is its ability to refine and prioritize pathways using LLMs by incorporating contextual descriptions, which helps to avoid generic, redundant, or irrelevant results commonly produced by standard methods.
5.The study demonstrates that cGSA significantly outperforms traditional GSA methods, with a performance improvement of over 30% in benchmarking tests using 102 manually curated gene sets across 19 diseases and ten biological mechanisms.
6.Two case studies, focusing on melanoma and breast cancer, further validate cGSA's ability to uncover disease-specific insights and aid hypothesis generation in clinical research.
7.cGSA's approach minimizes manual effort in filtering irrelevant pathways, a common bottleneck in high-throughput studies, by delivering a more concise and contextually relevant set of enriched pathways.
8.In expert validation, cGSA showed a high degree of consistency with manually annotated gene sets, with a relevance score system ensuring that the pathways identified align well with biological functions related to specific diseases and conditions.
9.Despite its success, the authors acknowledge that cGSA can still generate low-context relevance pathways due to potential LLM hallucinations. Future improvements in contextual prompts and model refinement are suggested.
📜Paper: arxiv.org/abs/2506.04303v1
#Bioinformatics #GeneSetAnalysis #AI #MachineLearning #LargeLanguageModels #cGSA #PathwayAnalysis #BiomedicalResearch #Genomics

1
2
831
25 Apr 2025
Comparative Performance Evaluation of Large Language Models for Extracting Molecular Interactions and Pathway Knowledge
1/ In this study, the authors evaluate 15 open-source large language models (LLMs) to assess their effectiveness in extracting molecular interactions, pathway knowledge, and gene regulatory relationships from biological data.
2/ The research reveals that larger LLMs, particularly those trained on large datasets, show superior performance in identifying genes linked to low-dose radiation pathways and predicting protein-protein interactions (PPIs).
3/ One of the most notable findings is the superior ability of models like Mixtral-8x7B-Instruct and SOLAR-Instruct to handle complex biological tasks. These models are designed to process long text sequences efficiently.
4/ The study utilizes multiple biological databases, such as STRING, KEGG, and INDRA, to evaluate the models. They also tackle the challenge of negative PPI prediction by using experimentally validated non-interacting protein pairs.
5/ A key insight from this study is the models' ability to provide valuable insights into gene regulatory networks and pathway activity, offering a significant stride toward AI-assisted knowledge discovery in life sciences.
6/ While performance is strong on more well-studied pathways (e.g., GABAergic synapse), the models struggle with less explored pathways like antibiotic biosynthesis, highlighting the need for continuous database expansion and model fine-tuning.
7/ The authors also emphasize the importance of model evaluation frameworks, noting that factors such as data parallelism and shot-based prompting are critical for enhancing the performance of these LLMs in biomedical tasks.
💻Code: github.com/boxorange/BioIE-L…
📜Paper: arxiv.org/abs/2307.08813
#Bioinformatics #LLMs #ProteinInteractions #PathwayAnalysis #GeneRegulation #AIinBiomedicine #MachineLearning

4
5
1,012
25 Apr 2025
Comparative Performance Evaluation of Large Language Models for Extracting Molecular Interactions and Pathway Knowledge
1/ In this study, the authors evaluate 15 open-source large language models (LLMs) to assess their effectiveness in extracting molecular interactions, pathway knowledge, and gene regulatory relationships from biological data.
2/ The research reveals that larger LLMs, particularly those trained on large datasets, show superior performance in identifying genes linked to low-dose radiation pathways and predicting protein-protein interactions (PPIs).
3/ One of the most notable findings is the superior ability of models like Mixtral-8x7B-Instruct and SOLAR-Instruct to handle complex biological tasks. These models are designed to process long text sequences efficiently.
4/ The study utilizes multiple biological databases, such as STRING, KEGG, and INDRA, to evaluate the models. They also tackle the challenge of negative PPI prediction by using experimentally validated non-interacting protein pairs.
5/ A key insight from this study is the models' ability to provide valuable insights into gene regulatory networks and pathway activity, offering a significant stride toward AI-assisted knowledge discovery in life sciences.
6/ While performance is strong on more well-studied pathways (e.g., GABAergic synapse), the models struggle with less explored pathways like antibiotic biosynthesis, highlighting the need for continuous database expansion and model fine-tuning.
7/ The authors also emphasize the importance of model evaluation frameworks, noting that factors such as data parallelism and shot-based prompting are critical for enhancing the performance of these LLMs in biomedical tasks.
💻Code: github.com/boxorange/BioIE-L…
📜Paper: arxiv.org/abs/2307.08813
#Bioinformatics #LLMs #ProteinInteractions #PathwayAnalysis #GeneRegulation #AIinBiomedicine #MachineLearning

1
2
569

24 Mar 2025
🧩 Moving to Functional & Gene Set Enrichment Analysis (FEA & GSEA) to determine the biological functions and pathways associated with the differentially expressed genes.
🧩 This will provide insights into disease mechanisms.
#RNAseq #Bioinformatics #PathwayAnalysis
1
1
2
29

20 Feb 2025
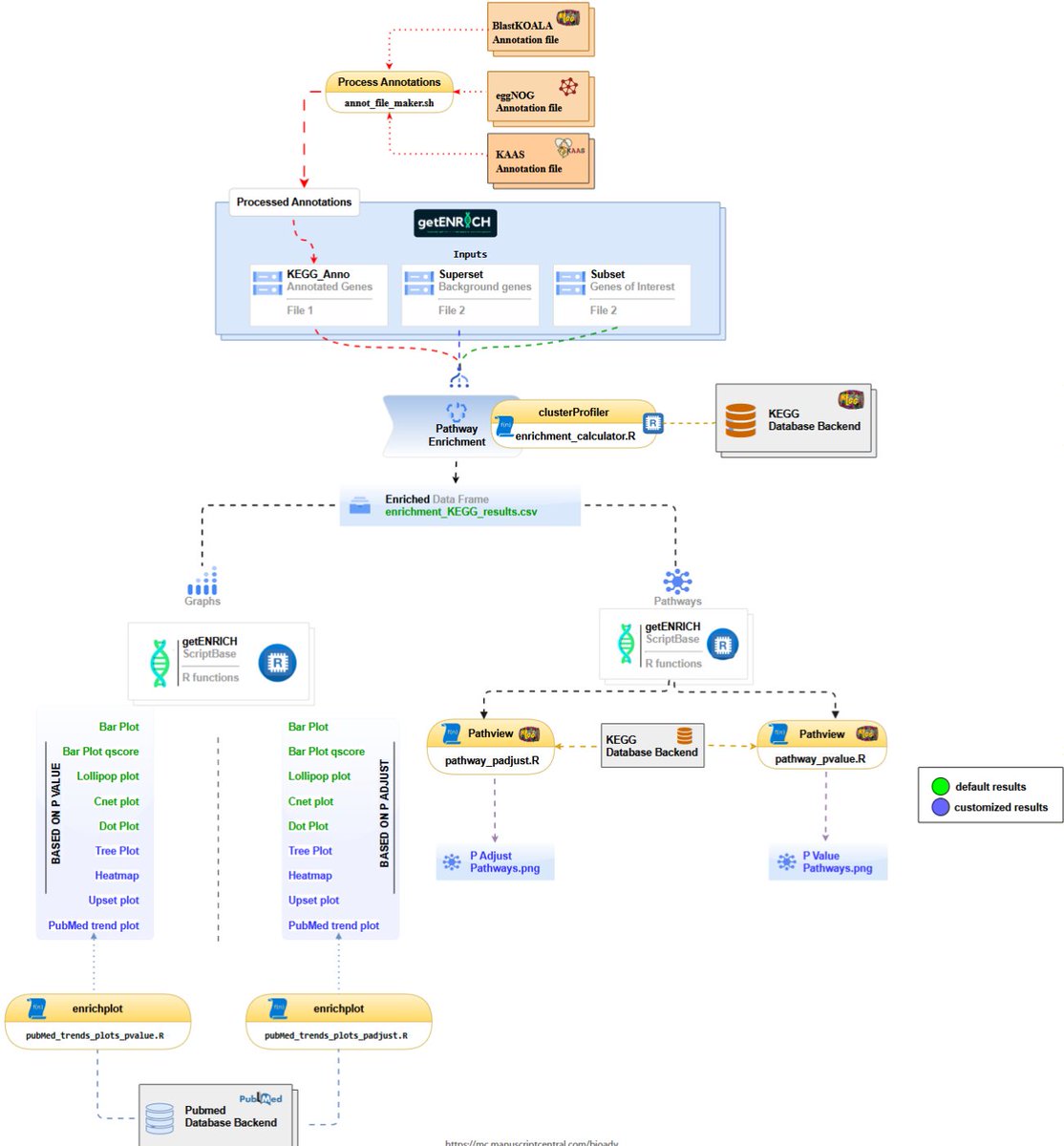
🧬 "getENRICH: a tool for the gene and pathway enrichment analysis of non-model organisms" introduces a versatile tool for functional annotation. Supporting both command-line and web-based interfaces, getENRICH enables researchers to analyze gene enrichment in species with limited #genomic resources. Read more: doi.org/10.1093/bioadv/vbaf0… #GeneOntology #PathwayAnalysis
1
1
2
283

25 Jun 2024
@Metabohub and @imperialcollege represented by Dr Cook #PathwayAnalysis works shown during poster flash session at @jobim2024

1
4
295

20 May 2024
PathwayNexus: a tool for interactive metabolic data analysis. #Metabolomics #PathwayAnalysis #Bioinformatics
academic.oup.com/bioinformat…
10
49
3,936

16 Apr 2024
🌱Dive into the world of plant pathways with the Plant Reactome: 💻an all-inclusive resource for basic research, genome analysis, and pathway modeling. It's open-source, peer-reviewed, and packed with expert-curated data. #PlantResearch #PathwayAnalysis
🔗tinyurl.com/ype6286u
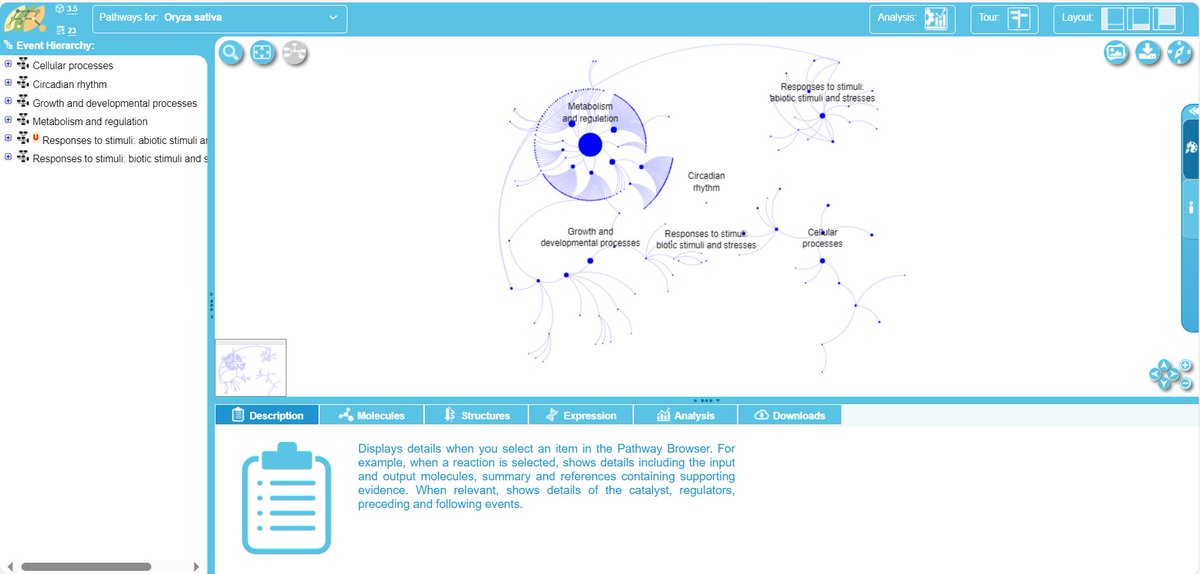
ALT Image of the pathway browser from the Plant Reactome.
9
21
1,900

1 Mar 2024
🔬 Using PH on RNA-seq data from HCC patients, our approach uncovers HCC-related pathways like apelin, IL-17, and p53 signaling pathways. Both shared and exclusive findings emphasize the power of PH in pathway analysis. 🔍 #InnovativeMethods #PathwayAnalysis #CancerPathways
3/5
1
1
3
63

29 Nov 2023
These upgrades and updates should greatly enhance PathBank's ease of use and its potential applications for interpreting a wide range of omics data. #metabolomics #pathwayAnalysis #compounds #proteins #databases #massspectrometry
Learn more here:
📎 academic.oup.com/nar/advance…
2
5
278

26 Jun 2023
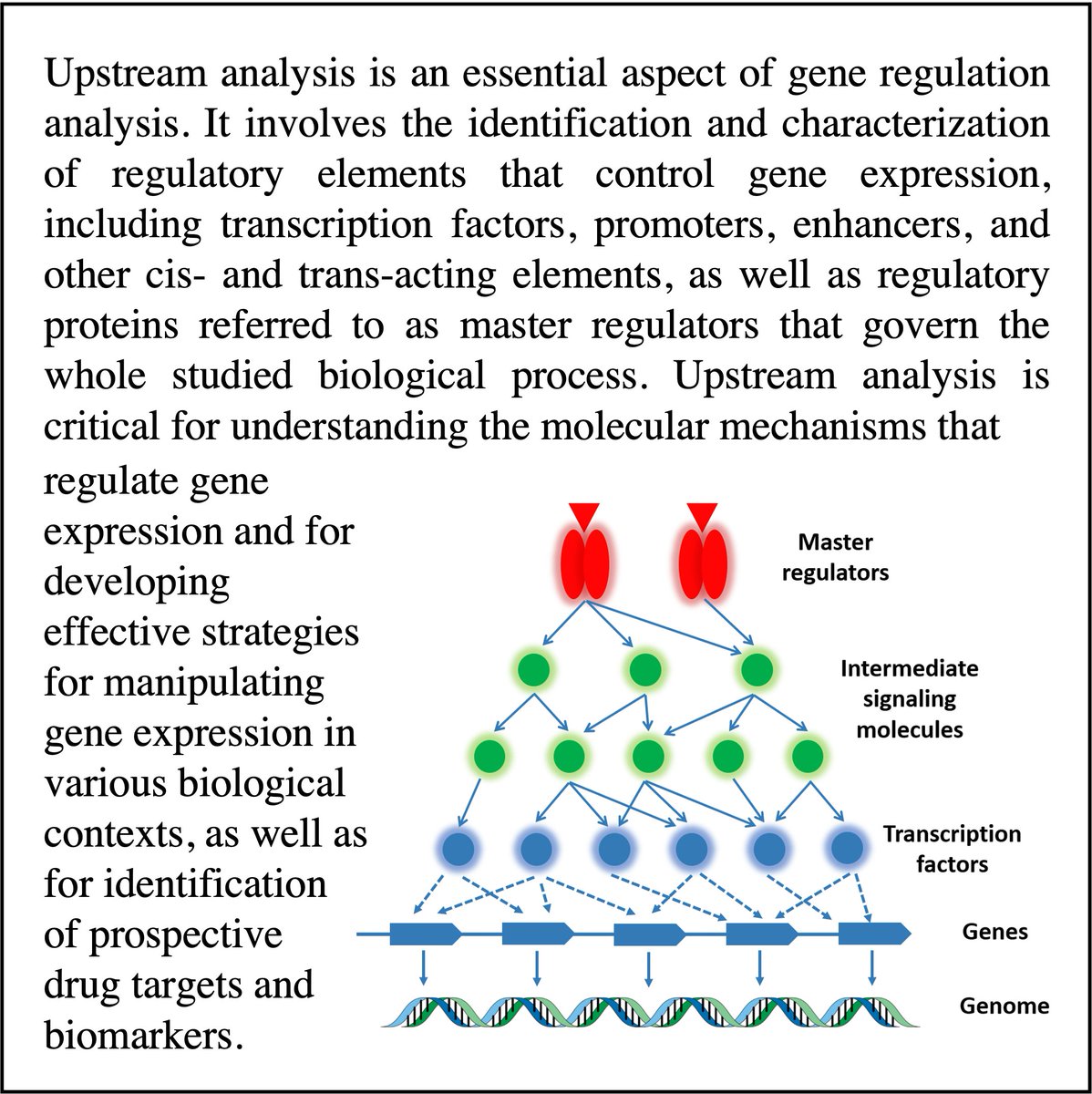
#UpstreamAnalysis is essential for understanding regulatory processes underlying any condition. Check out how #geneXplains's products can help you identify #MasterRegulators of the studeid process by performing the integrated #PromoterAnalysis and #PathwayAnalysis
#bioinformatics



2
42
8 Jun 2023
Watch the video record of the 8th Coffee break with TRANSFAC that was held on June 8th youtu.be/T_EYLqI0v-8
#bioinformatics #PathwayAnalysis #TranscriptionFactors #TranscriptionFactorBindingSite #Cancer #CancerResearch #Glioblastoma #WorldBrainTumorDay #WorldBrainTumorDay2023
5
1
1
213

6 Jun 2023
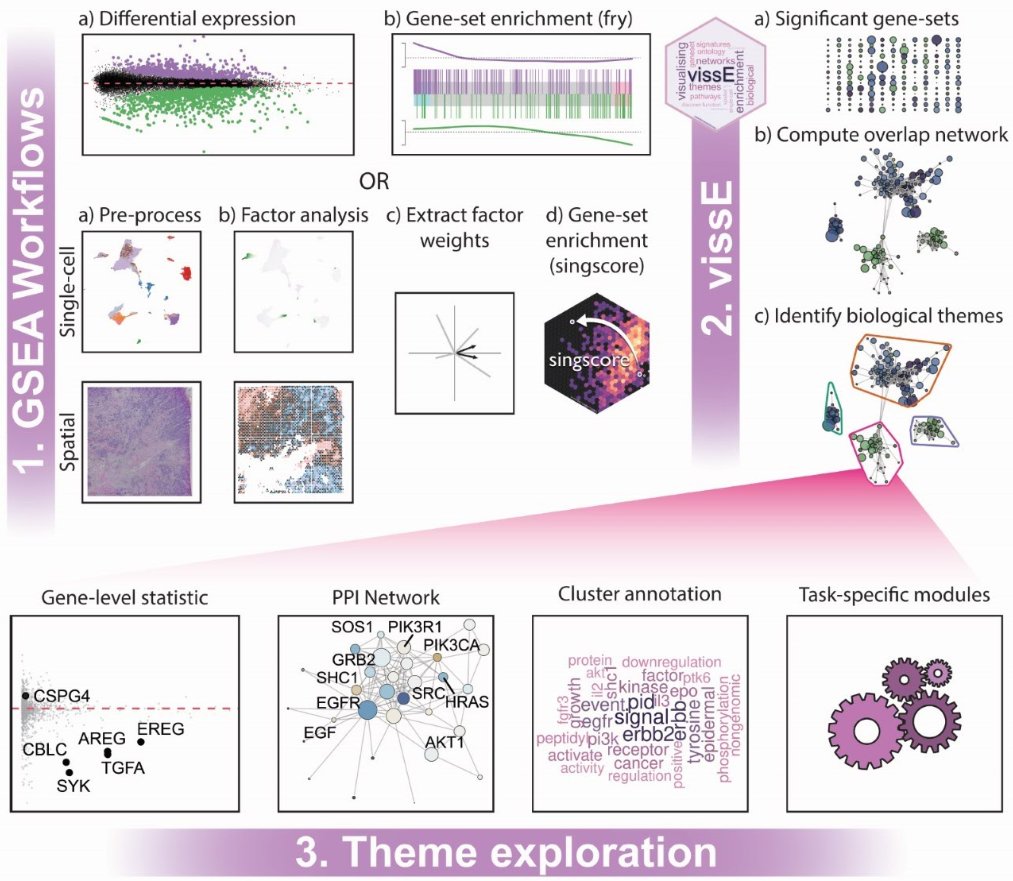
vissE.cloud builds on vissE to find themes to summarise #GSEA/#pathwayanalysis results. With a hierarchical structure you can investigate results at the gene, gene-set or cluster level and understand how individual genes relate to higher-order pathway activities.
9 Mar 2022

Our new tool, vissE, allows you to summarise pathway enrichment results from 1000s of pathways to a few biological themes that can aid in a holistic interpretation of biological systems. We also present a novel workflow to apply it to single-cell and spatial transcriptomics data.
1
1
4
264
31 May 2023
Join us for Coffee break with #TRANSFAC on June 8th at 10 AM CEST. Special topic is #Glioblastoma devoted to #WorldBrainTumorDay
Get the link here genexplain.com/ask
#bioinformatics #PathwayAnalysis #BrainTumor #Cancer #CancerResearch #Tumor #Pathways #MasterRegulators

2
317

17 May 2023
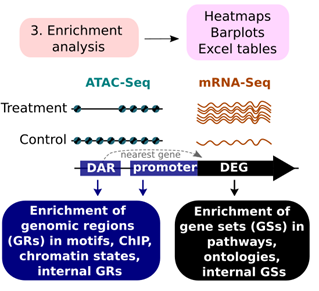
7/10. Step 3: Enrichment Analysis. Cactus performs enrichment analyses of entries from various databases in each DAS. It examines gene ontologies, pathways, DNA binding motifs, ChIP-Seq binding sites, and chromatin states. #TranscriptionFactor #PathwayAnalysis
1
2
102

16 Mar 2023
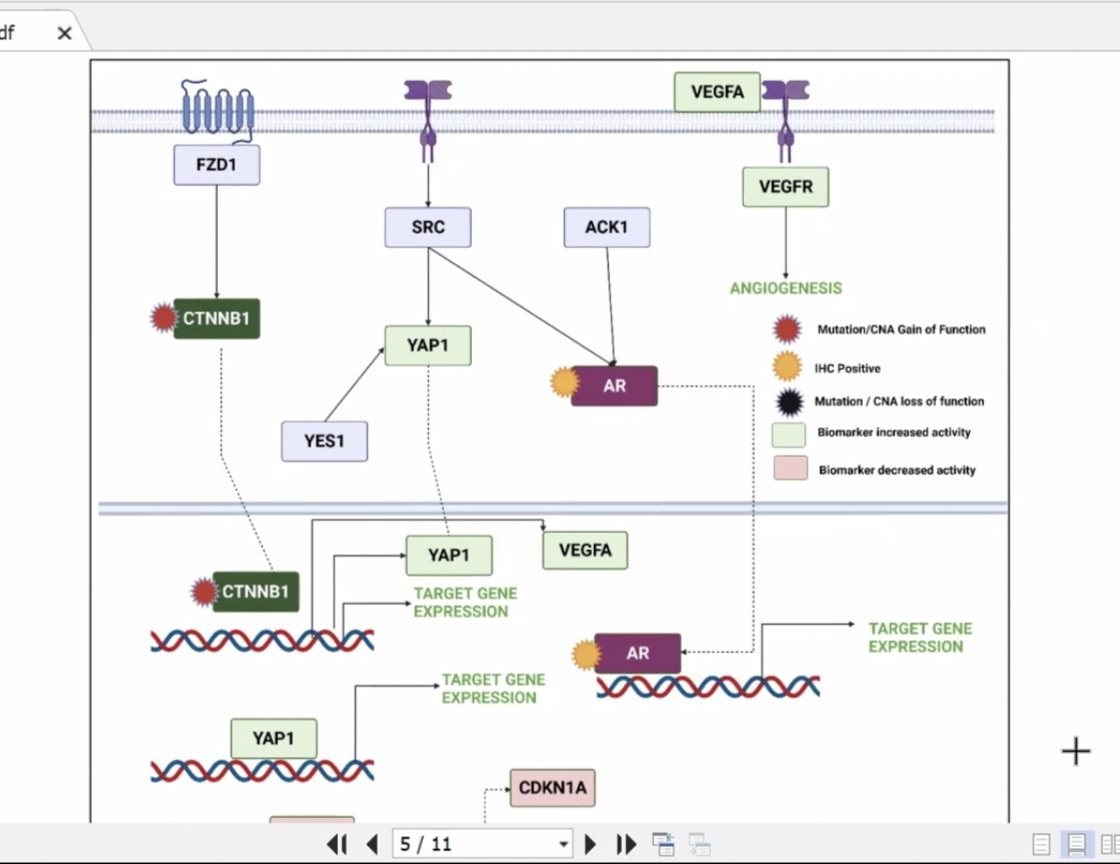
Thursday National Molecular Tumor Board & Precision Oncology
"discussion on difficult case with #TP53 and #CTNNB1 gene"
#pathwayanalysis
#tumorboard #PrecisionMedicine
@rushabh1388
@HHKhar @DrVijayPatil11



3
3
557