
Jun 10
DBCC FREEPROCCACHE is a sledgehammer. Use it carefully.
FREEPROCCACHE (no args): flushes the entire plan cache. Every query recompiles on next execution. In production under load, this creates a massive CPU spike.
FREEPROCCACHE with a plan handle: removes just one plan:
DECLARE @handle VARBINARY(64);
SELECT @handle = plan_handle
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
WHERE text LIKE '%your query%';
DBCC FREEPROCCACHE(@handle);
This forces a single bad plan to recompile without touching anything else.
The same precision applies to DBCC DROPCLEANBUFFERS — never run that on production.
#SQLServer #DBCC #PlanCache #Performance
3

30 Nov 2024
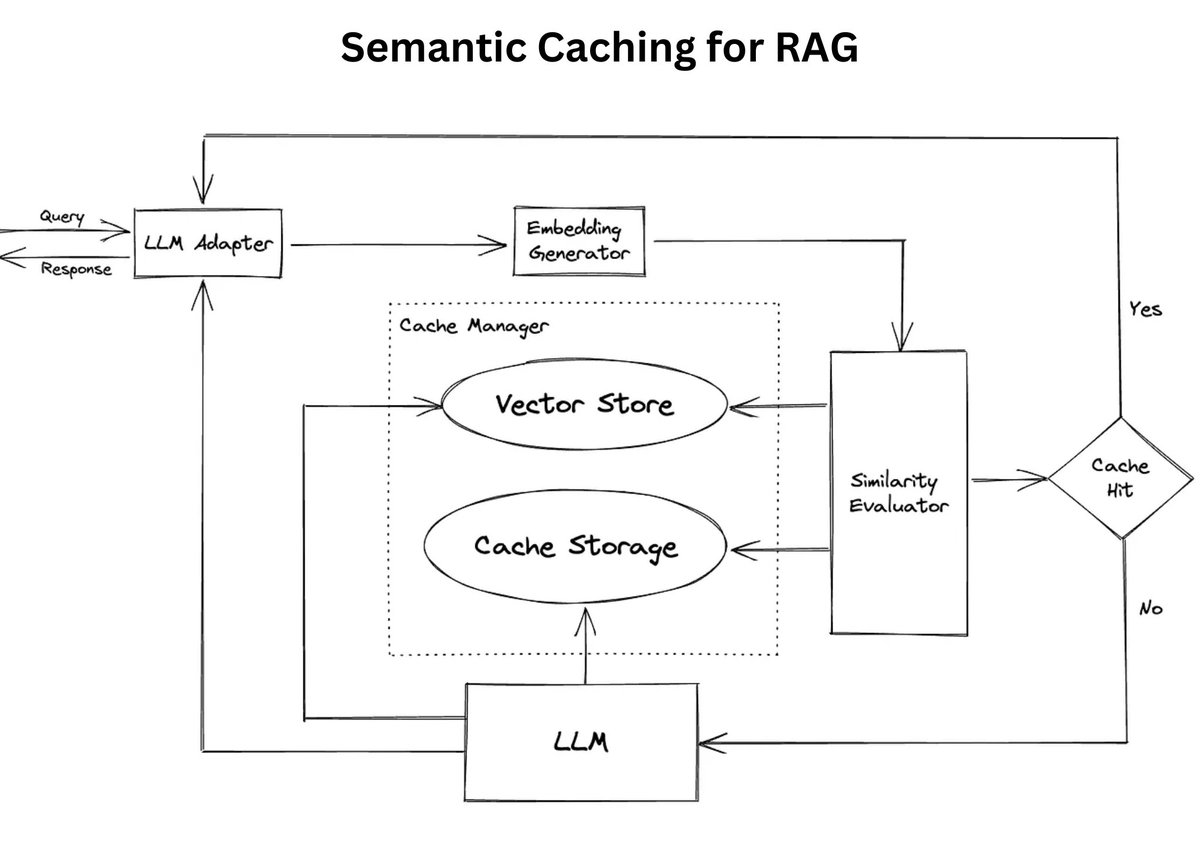
Supercharge your #RAG system with semantic caching!
Unlike traditional caching systems that rely on exact matches of keys or queries, semantic caching stores and retrieves information based on semantic similarity. This means that even if a new query isn’t exactly the same as a previously cached query, the system can still leverage cached results if they’re semantically similar enough.
Semantic caching involves storing the results of computations or queries along with their semantic representations (embeddings). When a new query is made, its embedding is compared against those in the cache to find semantically similar entries. If a match exceeds a predefined similarity threshold, the cached result is returned, eliminating the need for redundant computations.
Remember: Semantic caching isn’t just about making things faster — it’s about making AI systems more efficient, cost-effective, and scalable.
Know more about building semantic cache for your rag systems: medium.com/@elvingomez/build…
You can easily use SingleStore as the Semantic Cache Layer.
SingleStore is an ideal choice for the semantic cache layer due to its real-time, distributed architecture designed for ultra-fast queries. SingleStore database includes a built-in plancache, which further accelerates subsequent queries with the same plan, enhancing overall performance.
Sign up to SingleStore and use it for free: singlestore.com/cloud-trial/
Also, here are some advanced RAG techniques you should know: levelup.gitconnected.com/adv…
1
3
83

22 Dec 2021
Intro to Query Store by Deepthi Goguri (@dbanuggets) session is now available on YouTube!
buff.ly/3yOXYZI
#ladataplatform #microsoft #sqlserver #performance #querystore #executionplan #plancache

4
3

29 Mar 2021
PlanCacheならあとからでもみれるので、バッチジョブや長時間実行のクエリとかでパフォーマンスの初期分析で普段と違うエンジンが使われていないかなど確認するのに便利ですね。
2
22 Oct 2020
OCT 21, 2020 meeting info:
SQL Engine - Its working style by Deepthi Goguri (@dbanuggets)
Slide deck:
lnkd.in/gHmSc9T
Recording:
lnkd.in/gtuPH-w
#sqlserver #internals #microsoft #databases #acid #performancetuning #storageengine #cache #plancache

4
3

11 Feb 2020
While I would say that my (long ago) exposure to the plancache in oracle was not great, I don't agree with the general sentiment.
The amount of time we spend planning, and the amount of memory we need for our crappy per-backend plancache, is just not reasonable.
1
2