
書きました.学校の時間割表をプログラムで作成します.
時間割表の数理最適化(混合整数計画・Pyomo HiGHS)zenn.dev/akimasanishida/arti… #zenn
2
13
739

May 16
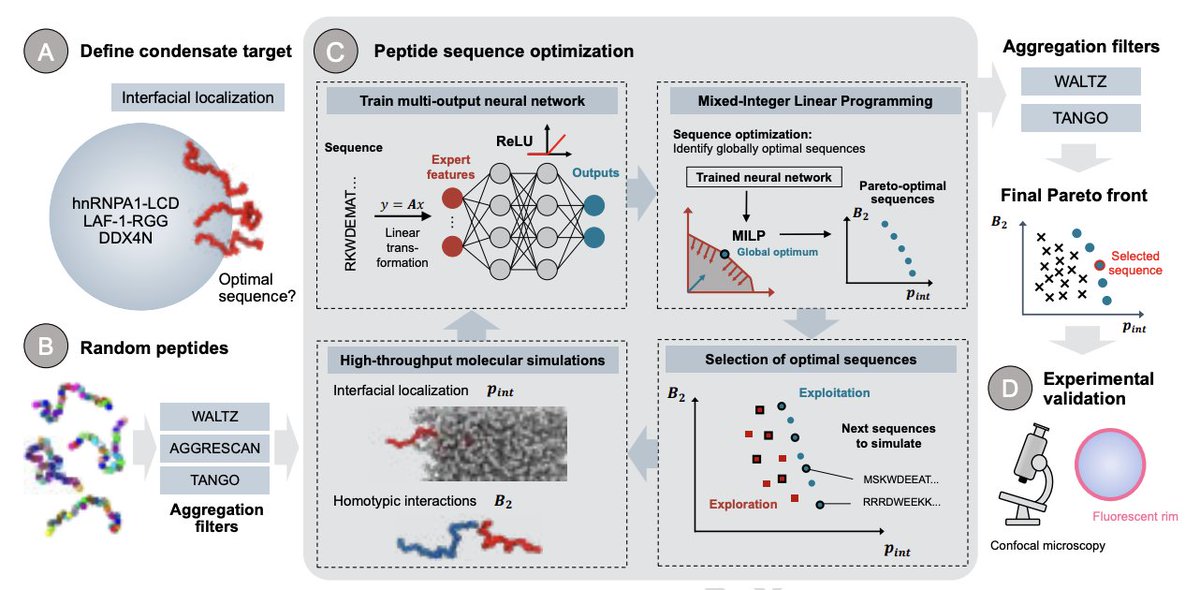
De novo peptides designed by ML and integer optimization that sit at the interface of biomolecular condensates
Inside cells, many biochemical reactions happen inside membraneless droplets called biomolecular condensates. Their interface (the thin layer between dense droplet and dilute phase) is increasingly recognized as a hotspot: it can accelerate disease-associated amyloid fibrils (hnRNPA1, FUS, α-synuclein), promote redox reactions, and modulate condensate size. Designing short peptides that selectively sit there, without disrupting the bulk, would give us a real handle on these systems. The problem is that classical surfactant intuition does not transfer: both phases are roughly 70% water, and the design space for a 30-residue peptide is 20^30.
Timo Schneider and coauthors build a pipeline that tackles this head-on. High-throughput coarse-grained MD (Mpipi force field) with adaptive biasing force quantifies, for each candidate, the free energy of partitioning between dilute, interface, and dense phases, plus the second virial coefficient B2 capturing self-association. A multi-output neural network is trained on 44 engineered sequence features (composition, charge and hydropathy decoration, aromatic patterning).
The key step: because all features are linear in the one-hot sequence and the network uses ReLU activations, the inverse design problem is reformulated as a Mixed-Integer Linear Programming problem (MILP, a classical optimization framework with provable global optimality), embedded via OMLT into Pyomo, and solved with Gurobi. AGGRESCAN enters as a hard constraint. The output is a true Pareto front, with formal guarantees that genetic algorithms cannot match.
Applied to three condensate targets (hnRNPA1-LCD, LAF-1-RGG, DDX4N), the pipeline converges on surfactant-like architectures: an aromatic-rich tail anchoring into the condensate via π-π and cation-π interactions, and a second tail excluded from the dense phase whose composition tracks the scaffold's net charge (polylysine for positively charged scaffolds, valine-rich for near-neutral DDX4N). Confocal microscopy confirms interfacial rims for all three designs, and the peptides shrink condensate size distributions while leaving bulk viscosity (FLIM) untouched.
For applied R&D, this matters beyond condensate biology. Combining trained neural networks with integer optimization is a general recipe for biomolecular inverse design where local optima are a real risk: peptide therapeutics modulating aggregation-prone condensates in neurodegeneration, and engineered sequences for compartmentalized biocatalysis in biopharma.
Paper: Schneider et al., Nature Communications (2026) — CC BY 4.0 | doi.org/10.1038/s41467-026-7…
1
21
77
4,606
May 15
Knowledge graphs as the backbone of digital twins for chemical processes
Building a digital twin of a chemical reactor sounds simple in principle: connect a virtual model to the plant, feed it data, let it predict. In practice, every unit operation needs its own bespoke model, and the equations, parameters and process descriptions live scattered across papers, software and lab notebooks. Scaling this to hundreds of processes is the kind of problem where ontologies and graphs shine.
Shuyuan Zhang and coauthors propose a knowledge graph that organizes process model building blocks (variables, laws, formulas, phenomena, context) into two ontologies, OntoModel and OntoProcess. Formulas are stored in MathML and parse automatically into code for SciPy, Pyomo or Julia. Autonomous agents handle assembly, calibration, SPARQL rule inference, database queries, AI property prediction, and chemistry queries via an LLM.
Two workflows emerge. A bottom-up agent assembles models when phenomena are explicit, tested on an annular microreactor where Villermaux–Dushman calibration reveals tunable mixing times down to 0.1 ms. A top-down agent screens candidates when phenomena are ambiguous, applied to a ribbed Taylor–Couette reactor where the best dispersion law shifts with rotation speed and solvent. It then drives multi-objective optimization of a flow amidation, finding Pareto-optimal trade-offs between space-time yield and E-factor, and beating Bayesian optimization on a benchmark.
What I find compelling is the philosophy. Rather than training one black-box model per process, the authors treat models as structured, reusable knowledge objects, with LLMs and AI predictors as supporting agents. A clean answer to a familiar frustration: predictive science gets stuck not on math, but on the lack of shared semantics across teams and tools.
For groups in pharma, specialty chemicals or battery electrolytes, this points to digital twins that actually scale. Process knowledge becomes queryable infrastructure rather than tribal memory, and new reactors can be onboarded by adding instances to the graph rather than rebuilding from scratch.
Paper: Zhang et al., Nature Chemical Engineering (2026) — CC BY 4.0 | doi.org/10.1038/s44286-026-0…

13
40
1,877




Jan 24
帮我修篱笆,修屋顶,换暖气片的阿叔/小哥们都问了同一个问题
你这木地板找谁家铺的,铺的挺好的
我:我自己…
他们:Amazing! 那损耗不会很高吗?
我:这很简单,建个数学模型然后把板长和宽还有房屋长宽给进去,去除掉踢脚线和膨胀块的厚度,再把木地板生产商给出的接缝错开最低长度,最低切板长,这些数据当做约束条件。拿pyomo建好调用gurobi几秒钟就求解出来横铺和竖铺各自的最低损耗率了。这样能够把商家建议的10%的损耗降低到4%,如果跨房间使用一些大块切板的话损耗还能降到3%左右
他们:虽然听不懂,但是我们知道你能赚钱的原因了…

24
16
540
87,903

16 Sep 2025
PuLPとかPyomoとの違いがわからない人(自称プロでも)が多いので、AMPLと他のモデリング言語の違い(優越性)を話してもらう予定です。
9 Sep 2025

最適化ソリューション開発を加速する―数理最適化モデリングツールAMPL活用セミナー
日時:2025年9月25日(木) 12:05〜12:50形式:zoomによるオンライン開催参加費:無料
講師:法政大学教授 MOAI Lab CEO 野々部 宏司
moai-lab.jp/seminar
4
3,097
7 Sep 2025
AMPLと他のモデラーの比較を Gemini でリサーチ、NotebookLMで論文を読ませて自動生成してみました。 論文はgeminiが見つけてくれた "Comparative Study of AMPL, Pyomo and JuMP Optimization Modeling Languages on a Flood Control Problem Example" です。
youtu.be/XHBchU2HM4M

3
865

22 Jul 2025
🚀 Tackling tough optimization problems? Check out "Solving Hard Optimization Problems with Pyomo and HiGHS" by Florian Wilhelm!
📅 Schedule: euroscipy.org/schedule/
🎟️ Get your ticket here: euroscipy.org/tickets/
#EuroSciPy #Python #Optimization
2
4
168

21 Jul 2025
突然のご連絡失礼いたします。
この記事の元になった書籍の著者の、森下と申します。
厳密解が求まるとのご指摘、ありがとうございます! 私は数理最適化はまだまだ勉強が足りず、適切な方法がとれていないことが多いと感じております。
ですので、ご指摘いただけたことに感謝しております。
生成AIの力も借りながら自分の環境(pyomoとSCIPを利用)で試してみたのですが、この最適化問題をそのまま渡すだけだと1時間たっても厳密解が求まらず、限界を感じています。
誠に恐縮ながら、もしお時間が許すようでしたら、解決の糸口となるようなヒントを少しでもご教示いただけますと幸いです。
(目的変数を補助変数y_iにして、制約条件をlog(y_i)にする、などを検討しております)。
無理を言っていることは承知しておりますので、お忙しい場合はご放念ください。
5
408

21 Jul 2025
Global supply chains have been disrupted by extreme events (e.g., trade wars, natural disasters, and geopolitical tensions) far more often than we would like. Each event triggered chaos and panic in sourcing operations, leading to severe financial damage. Predicting such events is difficult, but isn’t there anything we can do to prepare?Stress testing offers a powerful solution. In this blog post, we show how you can simulate thousands of disruption scenarios across your entire supply chain network to identify high risk supplier sites that could cause significant financial impact if they fail. These insights can then guide the reallocation of your risk mitigation investement. investment.
Here’s what you’ll learn:
📷 What operational data is needed to build a digital twin of your supply chain network
📷 The key concepts of time-to-recover (TTR) and time-to-survive (TTS)
📷 How to use Pyomo as a modeling interface and HiGHS as a solver to run stress tests
📷 How to scale simulations with Ray and run thousands of scenarios on a large network in parallel
📷 How to analyze the results to uncover hidden risks and identify opportunities for cost reduction
1
2
59

26 Jun 2025
We’re hiring: Optimization-Focused Developer (Python/JS/C)
We're looking for a technically sharp developer to support us with:
– Algorithmic optimization
– Rule-based logic and constraint modeling
– Parsing and structuring complex data
You might be comfortable with tools like:
🛠️ PuLP, Pyomo, or CVXPY for optimization logic
🛠️ MiniZinc for constraint programming
🛠️ (Optional) RLlib for reinforcement-learning-inspired planning
This is not about UI – it’s about smart logic, clean models, and scalable reasoning.
Freelance or permanent – we’re flexible.
If this fits you or someone in your network: feel free to DM or share 🙌
6
9
327

2 Jun 2025
Last week I joined the Maravelias group at Princeton as a visiting scholar. During my stay here, I will be training in biorefinery modeling (Pyomo/GAMS) with the goal of integrating metabolic models with process simulation and systems-level analyses as part of my GLBRC project.

7
286
11 May 2025
ampl tip 5: amplはCで書かれていて、さらに4erやらKeinighanが書いているので、PyomoやPuLPなどと比べると格段に速い。
4
650

23 Apr 2025
Interesting. Did you use a numerical optimization solver to arrive at the parameters? If not, you may want to consider using Pyomo to optimize if the solution space is large. See pyomo.org
1
1
237

7 Apr 2025
Problem of the week. Solving optimization problems with maths using Pyomo in Python
2
3
788

28 Mar 2025
<最大ダメージ構成を求める方法>
最大ダメージ構成を求める処理を非線形の整数計画問題として定式化し、最適化ソルバーに解かせています!
・最適化問題のモデリング言語:pyomo
・最適化ソルバー:SCIP
・ブラウザ上で実行する方法:WebAssembly
・SCIPをWASMで動かすためのコンパイラ:emscripten
1
3
252

21 Feb 2025
این دو کتاب برای مطالعه خودخوان میتونن کمکتون کنن. فقط به شخصه زبان پاسکال رو خیلی توصیه نمیکنم.
پایتون یک ابزار قویتر داره. داکیومنتهای کتابخانه pyomo رو میتونین مطالعه کنین و تست و کدنویسی الگوریتمها رو با اون انجام بدید.


2
3
105

7 Dec 2024
I used to ask GPT-4 a lot of questions when my optimization techniques and operations research course was going on.
Once the solution completed the step of defining feasible range and objective function, it used to proceed through python script using PuLP and pyomo library to find optimal solution.
That's what it might be doing under the hood in o1 too.
2
74

1 Dec 2024
Llega al alma esta hermosa canción en versión de “Willy Colón y Héctor Lavoe”, el cuatro pYomo Toro y la guitarra de Roberto García su autor. El disco I Asalto Navideño que es toda una delicia hoy es un buen día para degustarlo, @fredysocarras @Juan_Socarras_ , @daniel_socarras
1
2
360