
30 Jun 2025
I just published Making Sense of RAG: Vector DBs & Embeddings Explained medium.com/road-to-full-stac…
#RAG #RAGmodels #LLM #vectordatabase #embeddings #vectorembeddings
1
2
28

27 Jan 2025
#192 Can RAG models Overcome Hallucinations?
#AI #MachineLearning #RAGModels #LLMs #AIResearch #DataScience #ArtificialIntelligence #HallucinationsInAI #Guardrails #AIInnovation #DataScienceDemystifiedDailyDose
linkedin.com/pulse/192-can-r…
5
8
56

LLM red teaming by @promptfoo
promptfoo.dev/docs/red-team/
#LLMs #AIInSecurity #AdversarialAttacks #RAGModels #LLMSecurity #JailbreakDefense #LLMSafety #AdversarialDefense #SecureSoftwareEngineering #AIForSecurity #VulnerabilityDetection #SoftwareSecurity #AIInDevelopment #VulnerabilityFix #BugDetection #APISecurity #CodeVulnerability #LLMDatasets #DataSecurity #LLMFineTuning #DataProtection #AdversarialResilience
31
365
AI-Driven Security Research: Weekly Highlights 🔍
This week’s research covers advancements in malware detection, abuse prevention, adversarial attacks, and privacy-preserving AI. Below is a summary of key studies and findings, curated by Brandon Dixon.
BERT and Bi-LSTM improve cyber abuse detection accuracy: arxiv.org/pdf/2501.05443v1.p…
MalParse achieves 77% accuracy in Android malware categorization: arxiv.org/pdf/2501.04848v1.p…
FlipedRAG reveals vulnerabilities in RAG models with 50% opinion manipulation success: arxiv.org/pdf/2501.02968v1.p…
RAG-WM embeds watermark texts in RAG systems for 100% IP verification success: arxiv.org/pdf/2501.05249v1.p…
SpaLLM-Guard achieves near-perfect SMS spam detection with LLMs: arxiv.org/pdf/2501.04985v1.p…
Layer-AdvPatcher efficiently mitigates jailbreak attacks on LLMs: arxiv.org/pdf/2501.02629v1.p…
AI improves defect prediction and vulnerability detection in secure software engineering: arxiv.org/pdf/2501.05165v1.p…
LLM4CVE enhances iterative automated software vulnerability repair: arxiv.org/pdf/2501.03446v1.p…
CommitShield excels in tracking vulnerability fixes in version control systems: arxiv.org/pdf/2501.03626v1.p…
DFUZZ uses LLMs for effective bug detection in deep learning libraries: arxiv.org/pdf/2501.04312v1.p…
CGP-Tuning improves code vulnerability detection with graph-text interactions: arxiv.org/pdf/2501.04510v1.p…
Stack v2 dataset evaluation reveals security vulnerabilities in LLM pre-training: arxiv.org/pdf/2501.02628v1.p…
PromptGuard moderates NSFW content in text-to-image models efficiently: arxiv.org/pdf/2501.03544v1.p…
GuardedTuning balances privacy and utility in fine-tuning LLMs: arxiv.org/pdf/2501.04323v2.p…
PAWN excels in robust AI-generated text detection under adversarial conditions: arxiv.org/pdf/2501.03940v1.p…
Language models enhance GNSS interference characterization accuracy: arxiv.org/pdf/2501.05079v1.p…
HP-BERT effectively monitors Hinduphobia on social media during crises: arxiv.org/pdf/2501.05482v1.p…
#CyberAbuseDetection #HateSpeechAI #LLMs #AndroidMalware #MalwareDetection #AIInSecurity #OpinionManipulation #AdversarialAttacks #RAGModels #WatermarkingAI #IPProtection #RAGSystems #SpamDetection #SMSFraud #LLMSecurity #JailbreakDefense #LLMSafety #AdversarialDefense #SecureSoftwareEngineering #AIForSecurity #VulnerabilityDetection #VulnerabilityRepair #SoftwareSecurity #AIInDevelopment #VersionControl #VulnerabilityFix #CommitShield #BugDetection #DeepLearningLibraries #APISecurity #CodeVulnerability #GraphTextAI #CyberResilience #LLMDatasets #PreTrainingRisks #DataSecurity #ContentModeration #NSFWDetection #TextToImageAI #PrivacyPreservation #LLMFineTuning #DataProtection #TextDetection #AIContent #AdversarialResilience #GNSSInterference #GenAISecurity @arxiv #arxiv

6
1
29
3,798

16 Jun 2024
Automated Evaluation Method for Assessing Hallucination in RAG Models.
See here - techchilli.com/artificial-in…
#AI #RAGModels #AutomatedEvaluation #HallucinationDetection #ItemResponseTheory #AIAssessment #TechInnovation #ScalableSolutions #AccurateMetrics #ArtificialIntelligence

1
57

28 Feb 2024
🚀 Beyond The Hype 🚀
💫 We had an amazing event last Monday at the Publicis Sapient office about Real-World AI applications 🤖
🗣️ Just wanted to say thank you to our two amazing speakers @KelkarRenuka and Nishi Ajmera!!
🌟 And a massive thank you to the Publicis Sapient team for hosting us Isha Upadhyay, Christenica Malonzo, Vinci Rufus. Looking forward to doing more events together!
#AI #RAGModels #Flutter #londontech

1
6
317
22 Feb 2024
🔥 Last Chance to Register 🔥
💡Are you curious about how AI is being leveraged beyond the headlines?
🧠Learn from AI success stories and leave inspired to implement AI solutions
🗓️ Feb 26th (Next Monday)
🎟️ Register now: gdg.community.dev/events/det…
🎙️ Two amazing talks:
💫 Enhancing Similarity Search with RAG Models - Nishi Ajmera, Lead Engineer at Publicis Sapient
🚀 Supercharging Flutter Apps with AI: Leveraging Firebase Extensions for Intelligent Solutions -
@KelkarRenuka, #Flutter GDE | Founder@TechPowerGirls
#AI #RAGModels #Flutter #Mobile

2
5
238
20 Feb 2024
🤖 Enhancing Similarity Search with RAG Models 🤖
Join Nishi Ajmera, Lead Engineer at Publicis Sapient, for a deep dive into cutting-edge search technology!
💫 We will explore how RAG models leverage vast databases to enrich search results with contextually relevant information.
🗓️ Feb 26th
⏰ 18:00
🎟️ Register now: gdg.community.dev/events/det…
#AI #GDGLondon #RAGmodels

3
6
388
19 Feb 2024
🤖 Beyond the Hype: Real-World AI Applications 🤖
💡Are you curious about how AI is being leveraged beyond the headlines?
🧠Learn from AI success stories and leave inspired to implement AI solutions
🗓️ Feb 26th (Next Monday)
🎟️ Register now: gdg.community.dev/events/det…
🎙️ Two amazing talks:
💫 Enhancing Similarity Search with RAG Models - Nishi Ajmera, Lead Engineer at Publicis Sapient
🚀 Supercharging Flutter Apps with AI: Leveraging Firebase Extensions for Intelligent Solutions - @KelkarRenuka , #Flutter GDE | Founder@TechPowerGirls
#AI #RAGModels #Flutter #Mobile

3
464

9 Jun 2023
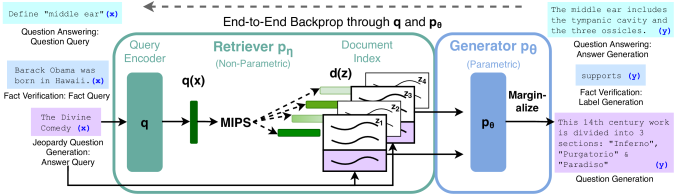
📣 "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks" paper, offers a new approach to improve language models' accuracy and understanding! 🧠🚀
🔎 They explore the realm of natural language generation, presenting a fine-tuning strategy for models called "RAG" that leverages both pre-trained parameters and non-parametric memory for language synthesis. 💡🗨️
❗ While existing models can store vast amounts of factual information, their ability to access and adapt this knowledge is limited, hindering their performance in knowledge-heavy tasks.
🎯 The solution provided by the authors is the development of RAG models, which incorporate pre-trained sequence-to-sequence models as the parametric memory component, while using dense vector indexing of Wikipedia, fetched with a pre-trained neural retriever, as the non-parametric memory component. This type of hybrid system allows for rapid modification and expansion of information and enables the examination and assessment of accessible knowledge, providing a way to overcome the challenges previously mentioned. While the research primarily focused on open-domain extractive question answering, the models "REALM" and "ORQA", which combine masked language models with a variational retriever, have shown promising results. Therefore, the authors employed a mix of parametric and non-parametric memory to enhance sequence-to-sequence (seq2seq) models, a fundamental tool in NLP. 🌐📚
⚡ This innovative method of augmentation provides language generation models with an external, updateable memory, combining a pre-trained neural retriever and a sequence-to-sequence transformer, creating a more effective model for language tasks. 🤖🎁
📊 In tests, these RAG models surpassed traditional techniques, delivering state-of-the-art performances on "TriviaQA," "open Natural Questions," "WebQuestions," and "CuratedTrec". Moreover, in "MS-MARCO" and "Jeopardy question" creation, their models provided more accurate, detailed, and diverse responses! 🏆🎉
🔬 The researchers found that RAG models generated more precise and detailed language, with the added bonus of keeping information current as society changes. Their findings also revealed a preference for RAG's outputs over the parametric-only "BART" model. 👥👍
🤔 But, like every coin has two sides, while RAG provides factual and controllable outputs, we must also remember that external sources like Wikipedia aren't perfect, and potential misuse for spreading false or offensive content remains a concern.
🌐 #AI #NLP #RAGModels #OpenAI #NaturalLanguageProcessing #AIResearch #AIAdvancements
You can read the full paper here: "arxiv.org/pdf/2005.11401.pdf"
1
1
194