
Jun 10
We just published our second research paper, built on Glasp data.
When we started @_Glasp, the dream was simple: if we understand what each person highlights, we can personalize their entire reading experience.
This paper is us testing that dream rigorously. The answer surprised us.
Your reading history does say a lot about WHICH articles are yours. With a clean, leakage-free test, we could identify a person's documents among their co-readers' choices, even when the topics matched.
But WITHIN a document? Personalization stopped working. A model that knew your entire highlight history could not beat the shared, impersonal sense of what matters. Even frontier LLMs lost to a simple lead baseline at predicting highlights.
Our conclusion: personalization lives at the selection layer, not the salience layer. People differ in what they read. What stands out is mostly shared.
And honestly, my favorite part: we found a bias in our own evaluation that inflated our first result, audited it, and published the corrected number instead. That is the kind of research we want to do.
So maybe the future is not personalizing each reader harder. It is aggregating readers, turning shared salience into collective intelligence.
Co-authored with my co-founder @KeiWatanabe17.
#Glasp #Research #Personalization #ReadingTech

2
2
8
1,326

Jun 10
A brand that suggests infinite stories powered by AI. readverse.ai suits a startup developing an AI reading assistant, a literary analysis tool, or a personalized book recommendation engine. A rare .ai domain that speaks to readers and investors alike. Explore its potential. #AIDomains #DomainSeekAI #ReadingTech

1
14

27 Nov 2025
📖 Meet the Future of Reading & Note-Taking! ✨
Say hello to the JS Nova Penum eBook Reader — where innovation meets simplicity and productivity feels effortless. 💡
Specs:
✅ Long Battery Life — up to 2 weeks
🖊️ 1 Stylus Pen (Wacom EMR Support)
🎙️ Voice Transcription
💡 Adjustable Front Light (Warm/Cool)
⚡ Quad-Core Processor | 4GB RAM | 64GB Storage
🔗 USB-C | Wi-Fi | Bluetooth 5.0
📱 Powered by Android 11
💰 Ksh 45,000
📍 Hazina Trade Center
🌐 jsnovamegastore.com
Read smarter. Write smoother. Create anywhere. 💫
#JSNovaPenum #EbookReader #DigitalNotebook #SmartNotes #StudyTech #ReadingTech #CreativityTools #TechKenya #ProductivityDevice #ModernLearning #RutoWamabarabara #MainaAndKingangi The Arsenal #UnmaskTheUprising #RightToProtestNotRiot #TanzaniaAgainstViolence #Liverpool Arteta #DePIN #AEWDynamite #HOPE_ON_THE_STAGE_TOUR #AreYouSureSeason2 #이게맞아시즌2 #CherrishCHANYEOLDay #weareoneEXO #JAYB #RHOSLC




3
69

13 Nov 2025
In WeaveReads, you can create custom Lists — themed reading roadmaps for your goals. 📚 Want to read more sci-fi classics? Or study a subject? Build a list for that — it helps organize your reading journey around clear purposes. 1/2 #BuildInPublic #IndieDev #ReadingTech #AI
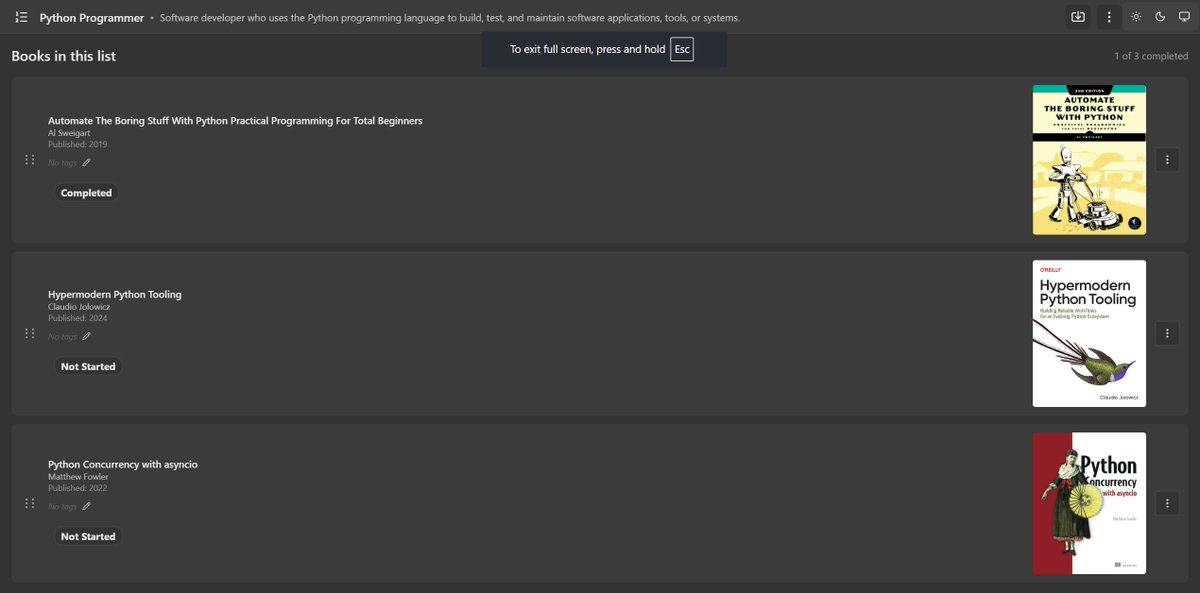
1
1
18

8 Nov 2025
Struggling to read? 😩 This pocket-sized genius scans & reads text aloud! 🤯 Perfect for students, dyslexia support, and anyone who wants to learn faster. 🚀 Check it out: unicun.com/product/primary-a… #readingtech #accessibility #learningtools

1
115

8 Oct 2025
Reading in bed just got easier 🛏️
We tested 5 Kindle page turners so you don't have to. One-handed reading, works through blankets, zero screen smudges.
The winner? 30m range silent clicks 🔇
Full breakdown: tabletsage.com/best-kindle-p…
#Kindle #ReadingTech #KindleAccessories
3
2
14

22 Feb 2025
How to Download Kindle Books from Amazon: A Step-by-Step Guide
“Check out the full article on my blog.”
cnnrise.blogspot.com/2025/02…
#KindleBooks #AmazonKindle #eBooks #DownloadGuide #KindleApp #ReadingTech #DigitalLibrary #BookLovers #TechTips #KindleStore

1
43

8 Jun 2024
📚✨ For Sale: SkimReads.com! ✨📚
Capture the essence of efficient reading with this premium domain. Perfect for news aggregators, summary services, and reading apps. A must-have for innovators in the reading and education space! 🚀
#ReadingTech #EduTech #Innovate

2
2
59

19 Apr 2023
🚨Attention🚨 OpenAI has just over a week to comply with European data protection laws or face hefty fines and bans. Educators & researchers worry about the impact of technology on student reading. Our report has got everyone talking. #dataprotection #AI #readingtech 🤯📰

2
34

7 Nov 2019
Had the pleasure of sharing @Flipgrid with @NPSchools Reading Specialists yesterday! This is the only time I will purposefully spread a fever...#FlipgridFever #edtech #TechCoach #education #collaboration #ThursdayMorning #ReadingTech @mroadruck @Lisa4Nash

1
1
8

9 Nov 2018
Had fun in Mrs Kensel’s class today teaching them how to use @flipgrid to share facts they learned from reading nonfiction text on EPIC! #readingtech



1

1 Sep 2018
🌟 New Feature!! 🌟 Focused Reading, the "Zen" of reading! - mailchi.mp/readmei/new-featu… #ebook #ereader #readingtech
2



22 Jul 2017
My apologies for the Canine Conversation that occurs half-way through! 🐶🐕📢🤦♂️#cep813 #theybarkedwhenIplayeditbacktoo #readingtech
22 Jul 2017

Formative Asmt using a CMS funkyinfourth.wordpress.com/…
1

8 Oct 2015
#ReadingTech will never replace the interactions between instructor and student. Tools will assist learners with... fb.me/4tNdgO8Ke
1
1