

Real-time, Controllable AI Video Generation
Adobe's MotionStream project tackles two major problems in AI video: slow generation and the inability to make changes mid-process. Now, you can act like a "real-time director," adjusting the video as it's being created.
#AIVideo #MotionStream #AdobeResearch #AIGC #RealTimeGeneration
1
3
843

16 Oct 2025
The Convergence of “Understanding × Generation” in Long Video — Attention Sink ✨🎬🧠
We recently open-sourced two works related to long videos: long-video understanding StreamingVLM (github.com/mit-han-lab/strea…) and long-video generation LongLive (github.com/NVlabs/LongLive). Both papers validated the effectiveness of Attention Sink (originating from StreamingLLM - arxiv.org/pdf/2309.17453) through experiments and adopted it as a core component. As a co-author on both works, I’d like to briefly introduce how Attention Sink is used in long-video understanding and generation, and how this differs from its usage in LLMs. 🔗📄
1. Why are long videos hard? 🤔⏳
Long video is an “ultra-long context” scenario. Whether for StreamingVLM’s understanding or LongLive’s generation, we deal with millions of tokens. Full attention makes computation explode—training and inference costs become prohibitive, and real-time/interactive use is essentially impossible. We therefore need an approach that preserves quality while remaining efficient. ⚖️⚡
2. What is Attention Sink? 🧲🧩
Attention Sink was first proposed in the LLM setting by StreamingLLM: insert a set of “anchor” tokens (sink tokens) early in the attention sequence and increase their salience (e.g., larger key norms or special embeddings) so that tokens at any later position can reliably attend back to these global-memory anchors.
Combined with Window Attention, the model’s logits are less likely to collapse when prompts change, yielding more stable behavior; the extra overhead is nearly cost-free, because the number of sink tokens is fixed. 🧮✅
3. On the “understanding” side: How does StreamingVLM use it? 🧐🎥
Attention Sink Sliding Window. The sink serves as a global prior for long-video understanding, persistently retaining information that does not quickly become outdated (e.g., players in a sports broadcast), improving stability across shots. 📈
4. On the “generation” side: How does LongLive use it? 🎨⚙️
Attention Sink Window Attention KV-recache. The sink acts as a global prior in long-video generation, maintaining stylistic and narrative consistency during generation; KV-recache refreshes the cache at prompt switch points to ensure smooth transitions. 🔁🎞️
5. Same hammer, different nails 🔨🔩
• In long-video understanding, the sink functions like a retrieval prior, helping the model stay on the main storyline. 🧭
• In long-video generation, the sink acts like a visual metronome, keeping overall style from drifting. 🎼
6. How it differs from Attention Sink in StreamingLLM 🔍📚
In both long-video understanding and generation, the usage barrier is higher than in LLMs.
• On one hand, in LLMs it can be used inference-only without training; in StreamingVLM and LongLive, we need fine-tuning to adapt the model to this mechanism. 🛠️
• On the other hand, there are more sink tokens: for example, in LongLive we construct sink tokens in the first 3 frames, leading to more sinks than in StreamingLLM. 📦
One reason is that pure text models are trained on corpora with natural anchors like BOS, paragraph openings, and titles, so early-position signals are already strong in attention statistics. Video data lacks a stable “global-anchor paradigm” (frames are homogeneous streams and scenes vary widely), so injecting sinks at inference time can easily mismatch—hence the need for fine-tuning to “teach” the model how to use them. 🎯
#LongVideoGeneration #LongVideoUnderstanding #RealTimeGeneration #Multimodal
2
12
72
11,685

3 May 2024
Best prompt ever when you use @leonardoai #RealtimeGeneration
Gladiator.
#promptshare from @midisteadygo

11 Apr 2024

Ever heard of “Mahōtsukai no Tabi: Sora no Ōkami” ?😉
#PromptShare 🚨
1955 black and white film still, Harry Potter in the style of Akira Kurosawa with Fujifilm --ar 16:9 --s 50
@KibagamiYomi @LudovicCreator @youseememiami show me your 🪄Anyone can play and 🔁✌🏽

1
2
303






7 Feb 2024

ALT ""こんにちは、ガールフレンド、今日からアドバイスをお願いします。""
1
3
1,044





24 Jan 2024
[Feature Update: Real Time Text Generation]
A new feature has landed! Real Time Text generation creates new images as you type out your prompt. Get ready for some rapid-fire text to image interaction 🔥
💗Completely free, unlimited usage💗
try it here: pixai.art/generator/realtime…
#AIイラスト #AIart #AI画像生成 #realtimegeneration #AItools
3
6
28
3,789
27 Nov 2023
9
28
2,956
27 Nov 2023
9
17
81
18,023

24 Nov 2023
2
1,281

20 Nov 2023
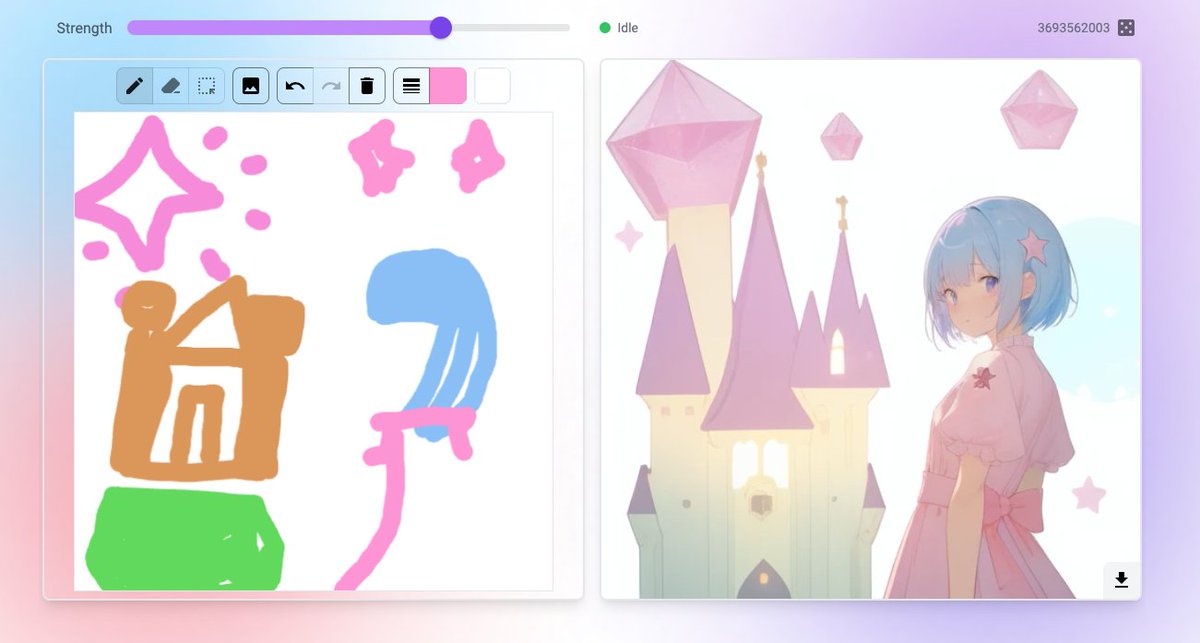
@krea_ai AI real-time generation tools are insane!!!!
Thanks to @edbyus for allowing us the opportunity to test this awesome tool.
#AI #realtimegeneration
1
2
86

20 Nov 2023
Need web design ideas? Say no more😄
Lemme draw a mockup quick ...
You can do it LIVE with @krea_ai 🔥🚀🔥
#kreaAI #realtimegeneration #AItools
1
4
532
20 Nov 2023
Infinite possibilities with @krea_ai Real-time Generation🔥🚀🤩
This is my first test with just a simple prompt @Lamborghini 🚗.
#kreaAI #realtimegeneration #lamborghini
3
375

3 Aug 2023
Devar, A Tech Company, Has Launched A Generative Ai Neural Network For Augmented Reality.
#GenerativeAR #MyWebAR #ARContentCreation #NeuralNetwork #CloudSolutions #WebAR #3DGraphics #AugmentedReality #iOS #Android #LowEndDevices #ImageRecognition #RealTimeGeneration @OpenAI

4
5
126

7 Jun 2023
“Patience they say is a … “; for we are still in court👌. So sorry, the era of waziri and his likes to become president is long gone😞. The president of this generation have to be someone that can set up a zoom meeting when his aids are not with him! #RealTimeGeneration👌
2
332

17 Mar 2017
81% of 13-17 year olds think teachers are doing a great job integrating #DigitalLearning - #RealtimeGeneration okt.to/Q21aQl

1
1

1