

The generative RecSys revolution mobiledevmemo.com/the-genera…
2
753

Spotify represents your entire music taste as a single token injected into an LLM.
Here is the stack their AI Foundation team just described in public:
- every track in a 100M catalog gets compressed into 6 tokens (Ariana Grande and Bruno Mars share the first two, because both are pop)
- your listening history becomes the prompt
- a user vector gets projected straight into the model's token space, so one frozen LLM personalizes for 750M people with no retraining
The model autocompletes the next song the same way it autocompletes the next word. Podcast next-episode picks already ship on it
20-min talk. bookmark before your recsys lead does
Every team still running generate-then-rank is now a generation behind
1
1
95

Jun 12
こうも再現性が取られていない手法だと大変だな。。(泣)
RecSys 2019 ベストペーパーを読んだメモ qiita.com/smochi/items/98dbd… #Qiita @smochi_pubより
89

Jun 12
Why I’m excited about @topk_io semantic_index as someone coming from recommender systems community
Whether you’re building search or recsys, the journey of results displayed to users always starts at the retrieval layer. And the hardest places to do retrieval are usually hard for the same reason: the catalog of items (documents) never sits still. New items pour in constantly, existing ones change, and anything more than a few hours old is pretty much dead weight. This is true for news feeds, or social platforms, or marketplaces. Freshness isn’t nice-to-have - it defines the product.
In general, any large-scale retrieval system requires three things:
- A way to ingest (and re-ingest) and index (and re-index) your whole dataset at scale
- A scalable way to serve your search or recommendation queries (high QPS, low latency)
- and, of course, high recall
You might be thinking: “but the current solutions already achieve all three” and you are right.
But in achieving this, they usually trade-off cost and freshness.
To get high quality, we can take the biggest embedding model we can serve (and accept either low write throughput or higher cost). Then, after the ingest is done, we build an index on top of this data, which means we need to wait for some amount of time until our data becomes available for querying. Alternatively, this means we are serving old data (e.g., not reflecting real-time updates in the posts).
@topk_io semantic_index is different because the compromise on freshness was never something we were willing to accept. Instead, by looking at the system as a whole, we realized there exists another way if we carefully co-design all the core components: the model, the inference engine, and the database.
Half of the issue, we realized, lies in the reliance on a large model producing dense embeddings and then running a simple cosine similarity search at query time. There’s been a lot of works recently showing how this leads to suboptimal quality and that even small models with a more expressive similarity function (late interaction) can match and often even exceed much bigger models in quality. But a somewhat understated consequence of this is a changed balance of cost in the system - by selecting a smaller model, you can more easily scale to higher write throughput, but at the same time your queries become more expensive. Not a free lunch, but it significantly helps alleviate the first freshness bottleneck: slow writes.
Naturally, this makes the second half of the problem - scalable querying *without indexing lag* - even more pressing, because with more expressive scoring function you make each query more expensive. Our solution here was a radically different form of representations (SMVE) - one where the vectors expose an index structure on their exterior, instead of us constructing an index post-hoc on dense vectors. Now, in semantic_index, a new entry is transformed on write to a form that clicks into an existing index. No rebuilds, no lag - you write and it’s there, ready to be retrieved efficiently.
I’m very excited about this release because with this design you get all three requirements of large-scale retrieval the freshness that makes your product engaging.
If freshness is a key requirement in your retrieval, you shouldn’t sleep on this one.
1
7
156


Jun 10
After intentionally following curiosity and trying to build something unlikely, all that to arrive at search and RecSys from first principles.
21

Premature optimization is still the root of all evil.
But the teams not experimenting with LLM-native retrieval and ranking right now are going to have some catching up to do.
What is your fave LLM x RecSys learning? 👀
41
→ History repeats itself. In 2016, "deep learning won't work in recsys" was the consensus.
Today, LLMs get the same skepticism. We are at the cusp of a new baseline.
1
49
A sneak peek into my notes from the "LLMs for Recommendation Systems" private event hosted by @Meta 📝
Engineers and researchers are all converging on the same architectural bet: move parts of retrieval/ranking toward LLM-native sequence modeling!
#RecSys #LLMRecSys

1
2
132

Recommendation latest research progress | 10. Dynamic Objective Selection with Safeguards and LLM Oversight for Financial Decision-Making
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

20
Recommendation latest research progress | 9. Efficient $(α,β)$-core Computation and On-the-fly Query at Billion Scale with GPUs
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

14
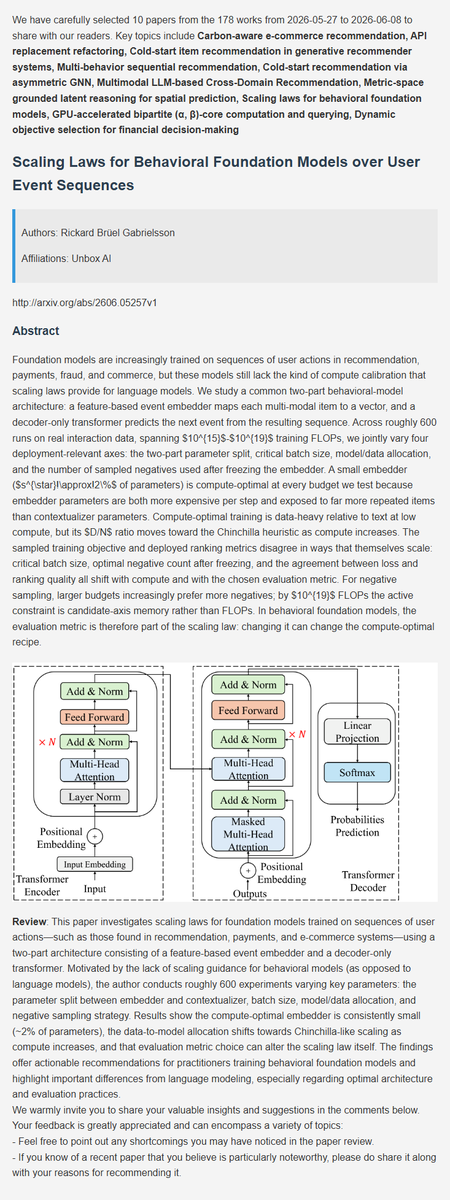
Recommendation latest research progress | 8. Scaling Laws for Behavioral Foundation Models over User Event Sequences
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys
12
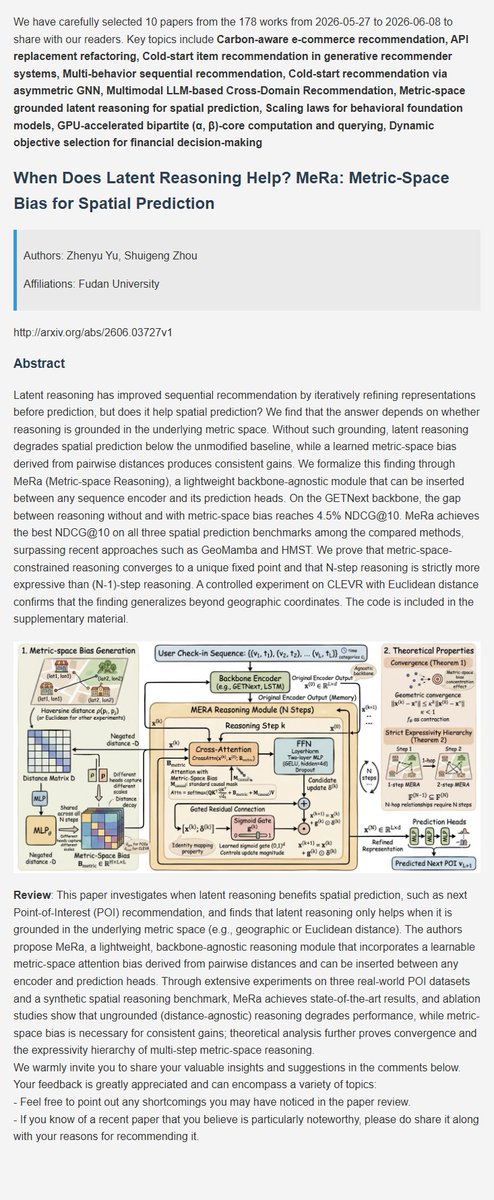
Recommendation latest research progress | 7. When Does Latent Reasoning Help? MeRa: Metric-Space Bias for Spatial Prediction
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys
23
Recommendation latest research progress | 6. Bridging Short Videos and Live Streams: Reasoning-Guided Multimodal LLMs for Cross-Domain Representation Learning
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

12
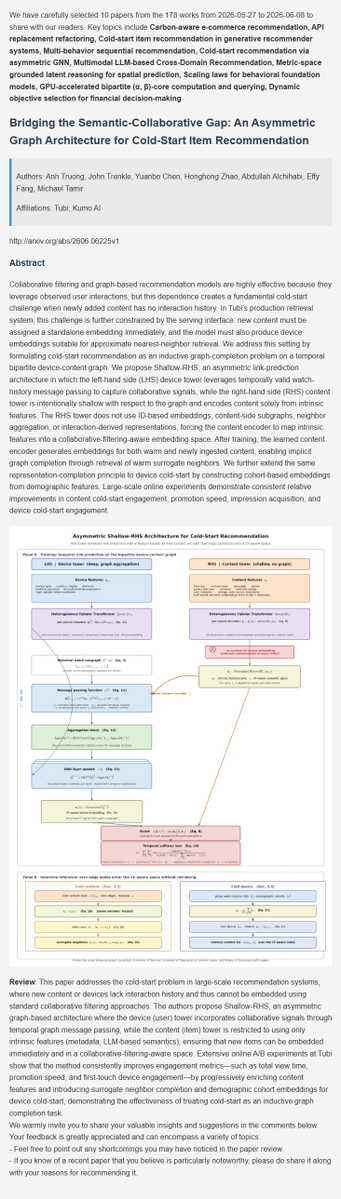
Recommendation latest research progress | 5. Bridging the Semantic-Collaborative Gap: An Asymmetric Graph Architecture for Cold-Start Item Recommendation
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys
10
Recommendation latest research progress | 4. PHKT:Personalized Dynamic Hypergraph-enhanced KAN-Transformer for Multi-behavior Sequential Recommendation
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

12
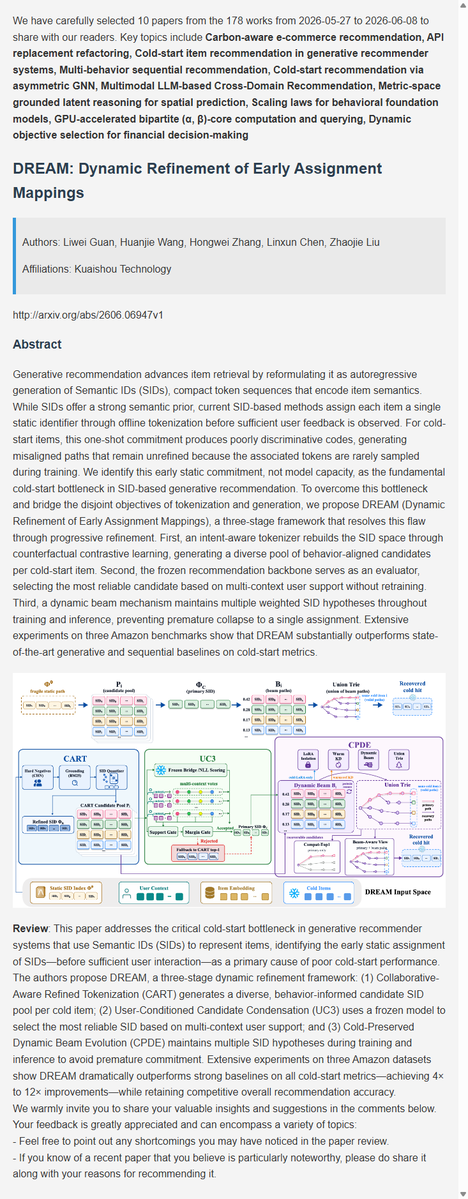
Recommendation latest research progress | 3. DREAM: Dynamic Refinement of Early Assignment Mappings
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys
16
Recommendation latest research progress | 2. From Custom Logic to APIs: Understanding and Recommending API Replacement Refactorings
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

9
Recommendation latest research progress | 1. Trading Engagement for Sustainability: Carbon-Aware Re-ranking for E-commerce Recommendations
#AI #DeepLearning #ArtificialInteligence #Datascience #Research #recsys

13