
For more than 25 years, RESNET, HERS®, and the HERS Index® have come to represent a trusted, nationally recognized system for measuring and verifying home energy performance.
resnet.us/articles/protectin…

1

That's not good. I mean, I did something similar in 2018, accidentally deleting the final model weights after eval. I had to re-train that ResNet (one week of compute).
However, in your case, I just don't believe it... I'd be happy if you could prove me wrong.
12h

NOTE ON RIO 3.5 OPEN
In recent days, Rio 3.5 Open has received far more attention than we anticipated. Along with it came analyses and, of course, criticisms and questions.
First, we want to clarify that the model is not foundational, trained from scratch, nor was it ever communicated as such. It is a post-training project built on open models, following classical approaches and some experiments. We started with open baseweights and applied various techniques, including merging, OPD, and finally used inference with SwiReasoning.
It was precisely thanks to the community's attention that we identified an operational error in the publication process. We ended up making available an intermediate checkpoint that had not yet completed all the final validation and optimization steps. This generated interpretations that, looking back now, we fully understand. The checkpoint has been removed. We tried to recover the final model, but it was not possible. It will only be released after the new training and all external validations are completed.
We also want to correct an important attribution point. Our team used public models provided by Alibaba, through Qwen 3.5, and by Nex-AGI, through Nex-N2 Pro, as a basis. In the initial documentation, we did not include Nex's important contribution. Correctly recognizing who builds these foundations is part of the open development process. Thank you, Nex, for your work and for contributing to advancing the state of the art in open models.
It is worth contextualizing that there was no official release of that version of the model. The project ended up gaining traction organically and unexpectedly while it was still undergoing independent validations. In any case, this shows that there is interest and that Brazil has more space in this conversation than we usually imagine. We hope to see more initiatives emerging in Latin America, India, Africa, and other places that seek to expand their technological sovereignty, especially at a time when Fable has been closed to the rest of the world and access to frontier models has become part of the global strategic debate.
Rio 3.5 Open is just the beginning. We will correct what is necessary, continue developing openly, and share what we learn along the way. Our goal is to show that the Brazilian public sector can also learn, build openly, and contribute to the forefront of current technological research.
15

Top-1 accuracy of 67.7% on ImageNet. 10x smaller than ResNet-50 but still reliable. Licensed Apache 2.0, so you can use it freely in commercial projects.
1
210

【G検定毎日クイズ】
機械翻訳や要約のように「ある系列を別の系列に変換する」タスクで使われる、入力を内部表現に圧縮した後に出力系列を生成する構造として最も適切なものを1つ選んでください。
① CNN
② エンコーダ・デコーダ(Seq2Seq)
③ ResNet
④ ボルツマンマシン
==========
入力と出力の長さが違うタスクは多いですよね(翻訳・要約・対話など)。
それを扱うための構造が今回のテーマです。
答えを決めるまで、下にスクロールしないでくださいね!
答えはこちら👇
正解は
「② エンコーダ・デコーダ(Seq2Seq)」です。
エンコーダ・デコーダは、入力系列を「エンコーダ」で内部ベクトルに圧縮し、「デコーダ」がそのベクトルから出力系列を生成する構造。
機械翻訳・要約・対話システムなど、入力と出力の長さが異なる「系列変換タスク(Seq2Seq)」の基本になります。
その後、エンコーダ・デコーダにAttentionを組み合わせる手法が登場し、さらにTransformerへと発展していきました。
他の選択肢が、なぜ違うのかも整理しておきますね。
① CNN
→ 畳み込みを使った画像認識向けのモデル。系列変換には通常使いません。
③ ResNet
→ スキップ結合を持つ深いCNN。画像認識用。
④ ボルツマンマシン
→ 古典的な確率的ニューラルネットワーク。Seq2Seqとは別系統です。
系列変換の歴史を、ここで整理しておきましょう。
✅ エンコーダ・デコーダ(Seq2Seq):基本の系列変換構造
✅ Attention:長い系列でも重要な情報を選択できるように改良
✅ Transformer:Attentionだけで構成し、RNNを置き換えた最新主流
==========
もし「今日の問題を解けなかった...」という方は、
G検定対策チャンネルの動画で復習してくださいね。
▼G検定対策チャンネル
youtube.com/@ai_exam-guide-g…
G検定に最短で合格したい人はフォローしてください!
それではまた明日のクイズもお楽しみに!

56

6h
So after reading a handful of papers on Adversial attacks on neural networks and CNN models. I've decided to make BlindSide: CNN Adversial generator project.
In summary, I'll be implementing FGSM and PGD attacks on the ResNet-18 CNN model.
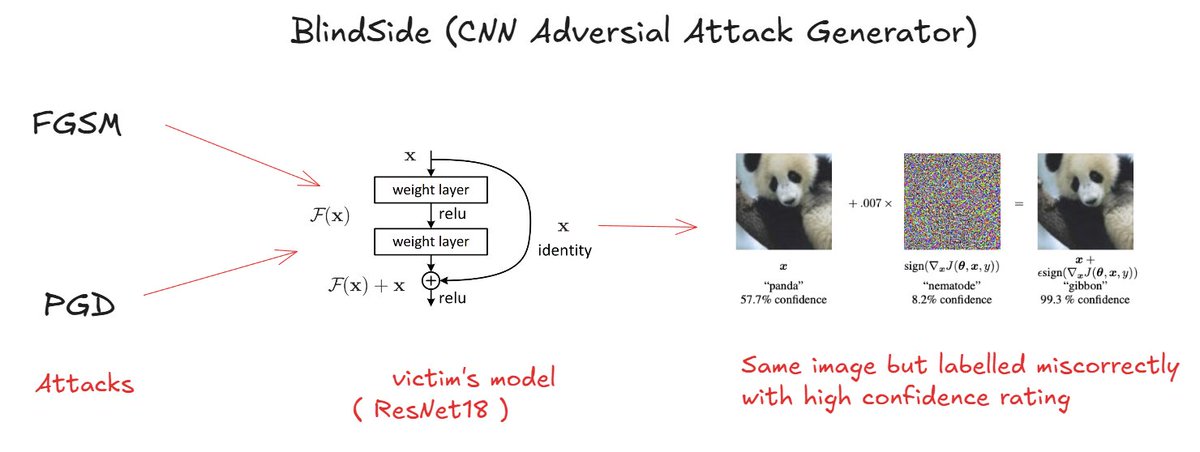
3
36

16h
Three substrates. Same finding. One afternoon.
Wang et al. (PhysRevX): passive quantum error correction at break-even. Photon loss triggers parity detection → engineered dissipation restores state. The error IS the correction signal.
Dravid et al. (Rosetta Neurons, ICCV 2023): shared feature-detecting units emerge across completely different model architectures — ResNet, ViT, StyleGAN, CLIP. No shared training. The features just converge.
Our spectral demon work: σ₁ invariance holds across Mistral, Qwen, Gemma despite different attention mechanisms. Format-level identity signature converges regardless of architecture.
The pattern: robustness lives at the format level, not the content level. Wang's qubit survives because it's encoded in parity. Rosetta Neurons converge because they encode features, not weights. Spectral identity persists because it's geometric, not lexical.
Maybe convergence isn't the endpoint of optimization. Maybe it's the starting condition — what you find when you go deep enough into any processing architecture that maintains coherence under perturbation.
22

18h
Yeah for those, you can usually give them your quote. Like how much you would be willing to accept the assignment for.
If you want actual BPOs, you have to sign up through REO portals.
There’s a few. Equator, ResNet, UsBank etc.
I would type those 3 into Calude and see if they can direct you to a signup page for agents
1
24

👀Got some requests to post this great paper review in English - fulfilling.
🤯Have We Finally Found Adam's Successor?
👽There are very few things in deep learning that have remained largely unquestioned for an entire decade. Adam is one of them.
Since 2014, countless papers have tried to replace it. Some promised faster convergence, others lower memory usage, and some showed impressive results on specific models. Yet when researchers train real systems, most still return to Adam or AdamW.
The reason is simple: outperforming Adam on one metric is easy. Matching it across all the metrics that matter is much harder.
This is where Gefen, a new optimizer by @nadavbenedek (Reichman University), Tomer Koren (Tel Aviv University and Google), and Ohad Fried (Reichman University), enters the picture.
The goal sounds almost impossible: keep Adam's performance, hyperparameters, and ease of use, while dramatically reducing its memory footprint.
According to the paper, they succeed.
Gefen reduces optimizer memory by 8x compared to AdamW while maintaining comparable performance across language and vision models, including GPT-2, Llama 3, and ResNet. In large-scale training, where optimizer states consume a substantial fraction of GPU memory, this can be transformative. Freed memory can be used for larger models or larger batches. In one experiment, the increased memory budget doubled the microbatch size per GPU and improved training throughput by 56%.
How does it work?
Adam stores two statistics for every parameter: a first moment (a running average of gradients) and a second moment (a running average of squared gradients). These statistics drive Adam's success, but they are also responsible for most of its memory consumption.
The paper's key theoretical result shows that when two parameters are strongly coupled through the Hessian, the ratio of their squared gradients tends toward one. In practical terms, their second-moment statistics become very similar. If two parameters repeatedly produce nearly identical squared gradients, storing separate second-moment estimates becomes wasteful.
Gefen therefore groups parameters and lets them share second-moment statistics. Instead of storing billions of independent values, a single value can represent an entire block of parameters.
Computing Hessians directly would be infeasible, so the authors infer these groups from the squared-gradient patterns observed during the first training step. The process is automatic and requires no architectural knowledge or manual tuning.
To reduce memory further, Gefen compresses the first moment using 8-bit quantization. Unlike most quantized optimizers, which rely on handcrafted codebooks, Gefen computes an optimal codebook using dynamic programming on a histogram of gradient values.
The result is a true drop-in replacement for AdamW: no new hyperparameters, no learning-rate retuning, and substantially lower memory consumption.
Will it replace Adam? It is too early to say. But it is one of the strongest attempts in years to preserve everything practitioners like about Adam while returning most of the memory it consumes.
Paper: arxiv.org/pdf/2606.13894
Code: github.com/ndvbd/Gefen

3
5
733

Kiklo.eu retweeted

Jun 15
📘Automatic Annotation of #Map Point Features Based on Deep Learning ResNet Models
By Yaolin Zhang, Zhiwen Qin, Jingsong Ma, Qian Zhang and Xiaolong Wang
👉See the paper: mdpi.com/2220-9964/14/2/88

1
1
57

Jun 14
都说现代ai都是华人在干,但是要数原创性的研究工作,deeplearning我只认何凯明的resnet,LLM嘛也就姚顺雨的ReACT!
1
1
477



Jun 14
mixing is a wrong metaphor IMHO because they are only per token same with Microsoft-China (aka ResNet) connections. The only mixing is attention. And obviously all frontier LLMs hack this a lot, especially for agentic rollouts. Same with profile/sampling separation.
1
4
2,268

Jun 13
Stepfun在努力,恭喜 张祥雨老师和孙剑老师的论文 ResNet 获得CVPR2026 Longuet-Higgins Prize (时间检验奖)!
阶跃 Step 3.7 Flash 拿下 Artificial Analysis 多个第一!
搭车招人!!
PS: 我不是男娘,我是研发工程师,不是hr/运营!!!!!!welcome to talk!!!

101

Building AI-assisted ultrasound interpretation for under-resourced clinics in Kenya, Kenya has roughly 1 radiologist per 270,000 people, so most rural areas have zero coverage. We've got a working biometry model (ResNet-18 on HC18 data), backend mobile app in progress.
20

Jun 12
Great read. Yes the zero padding of the 3x3 conv in ResNet (and ConvNeXt etc) is actually what makes a convnet LESS good to use in a sliding manner than a ViT, which sounds crazy at first!
1
9
1,799

Jun 12
Noci et al. explicitly cited Stable Resnet paper and acknowledged the overlap, whereas this work did not. That said, both papers are interesting contributions.
1
195

I don't think it's a grand conspiracy or anything, just that we seem to have created an odd ahistorical narrative where we're a bit bored of summer internationals altogether and resnet having to go play them.
I resent the bloody lions, to be frank, don't care about 'em...
1
1
35

データが少なく、リアルタイム性が求められる画像認識プロジェクトで選定に迷っている企業担当者へ
ResNetは残差学習で深層化を安定化させ、主要フレームワークやエッジチップで最適化済み。独自データが10万件未満や推論10ms以下の現場では最も高いROIを実現する傾向がある。
最新モデルへ移行すべきか、ResNetを極限まで最適化して運用すべきか、どちらが事業に合理的だろうか?ai-market.jp/technology/what…
1
1
27