
17 Jul 2024
Love papers like RootFree (RF).
It's well-motivated, well-written, has decent ablations, and most importantly, is a simple yet elegant method.
The key idea of RFAdamW seems to be it moves away from the notion that "2nd-order statistics scale the per-parameter learning rate" and instead embraces their curvature information.
This way, they close the generalization gap between SGD and AdamW without compromising early convergence.
As the implementation is a one-line change, I've added RF and grafted RF to github.com/ClashLuke/schedul….
Grafted RF (following openreview.net/forum?id=FpKg…) allows the direct transfer of tuned SFAdamW hyperparameters to see immediate gains without retuning.
See below for an incomplete ranking on a toy problem:
x.com/LinYorker/status/18130…

16 Jul 2024

#ICML2024
Can We Remove the Square-Root in Adaptive Methods?
arxiv.org/abs/2402.03496
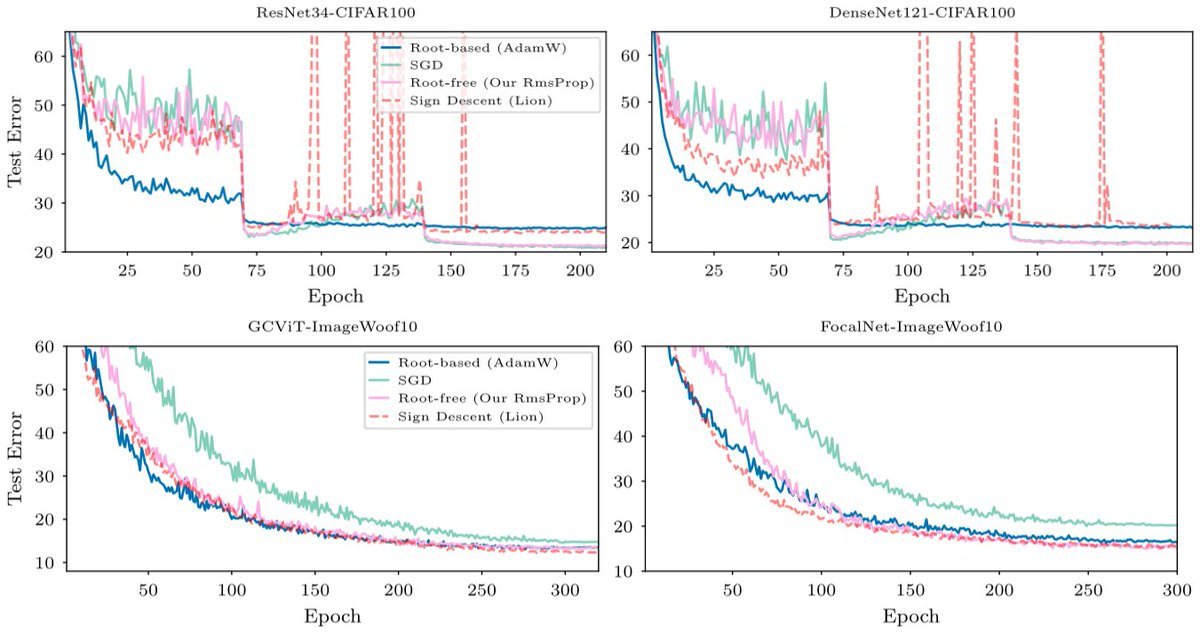
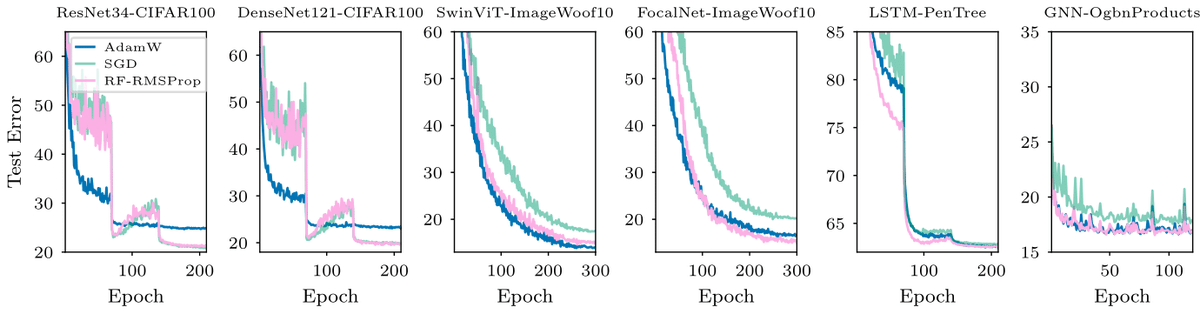
Root-free (RF) methods are better on CNNs and competitive on Transformers compared to root-based methods (AdamW)
Removing the root makes matrix methods faster: Root-free Shampoo in BFloat16 /1
2
8
34
3,183

14 Oct 2017
All done! #rootfree #thevillagerhairsalon katzilla_colors #pinkhairdontcare #paleaf instagram.com/p/BaPbe6WjE3f/

6 Apr 2016
@HHSLiverpool there's no better feeling that having your colour done #RootFree thank you ! ❤️ my colour xxx
1
1

19 Dec 2015
1
1


10 Apr 2015

1
1


1
1
2
