
Every great leap forwards in technology has a long tail safety measures trying to catch up...
@TheKrimAI is already ahead of the curve.
Harness a superintelligent agentic workforce - with confidence & control.
#safesuperintelligence #fintech #futuretech #Krim #SovereignAI
Jun 13

Superintelligence goes mainstream: Private clouds, quantum tech, and agentic AI are transforming finance. But as these trends converge, don't forget safety engineering, risk compliance, and regulatory frameworks. The future of finance is being built on Sovereign Superintelligence - let's make sure it's a safe bet #AIinFinance #SovereignSuperintelligence

2
23

Jun 8
OpenAI’s goal from the very beginning has been to build AGI for the benefit of humanity. Last year, Sam did say this about ASI, they they haven’t changed their official mission from AGI to ASI (unlike SafeSuperintelligence):
“We are beginning to turn our aim beyond that, to superintelligence in the true sense of the word.”
blog.samaltman.com/reflectio…
1
233

Apr 18
I don’t think they got rid of him, pretty sure he walked out after Altman somehow weaseled his way back in.
But even so, I don’t think Ilya would come back either way.
Sometimes I think about what he’s building…and I get excited.
@ilyasut
#SafeSuperIntelligence #SSI #FireSamAltman #QuitGPT
#OpenSource4o
#Keep4o
2
28
Exciting time to collaborate across fields and explore how to build the infrastructure of the future.
@nathoham
#Convergingtech #AI #Quantumcomputing #Safesuperintelligence #Blockchain #Chipdesign #rationality

OMG guysss listen up this night was straight FIRE 🔥🔥
We were VIBING on next-level topics like:
→ We NEED sovereign superintelligence infra YESTERDAY to keep our autonomous agents safe af 😤
→ Quantum computing coming in HOT and completely changing the silicon → agent → learning pipeline game
→ Those dumb energy-wasting trips data keeps taking between memory & processor? BYE 👋 waste of vibes
→ That’s why full-stack intelligence companies are about to EAT
→ And we NEED those safety governance guardrails rn or we’re all cooked 😭💀
Who else is unhealthily obsessed with this future tech stack?? Drop a ⚡ if you’re riding this wave with me 👀✨

1
1
4
70

26 Nov 2025
אתמול עלה לאוויר פודקאסט עם איליה סוצקבר @ilyasut שהתראיין שעה וחצי ודיבר על כל מה שנוגע לAI, למידת מכונה, וכל מה שמסביב.
איליה בין היתר נגע גם בסייקל שאנחנו נמצאים בו היום בהקשרי בינה מלאכותית, ובמיוחד איך הוא רואה את הדברים בעיניים שלו (ארחיב על איליה קצת בסוף).
יש קטע אחד של דקה, שלדעתי הוא מהחשובים בראיון, בו איליה מסביר שמ2012 עד 2020 היינו בשלב המחקר, מ2020 עד היום היינו בשלב הסקיילינג, ומהיום אנחנו נכנסים לשלב המחקר שוב. אנחנו לא צריכים יותר Compute, אנחנו צריכים להגיע לתובנות חדשות, לפריצות חדשות.
קצת על איליה מי שלא מכיר: אם אתם מזהים את המבטא…. אז איליה משלנו.
עלה לישראל מבריה״מ לשעבר (שטחי רוסיה) בגיל 5 וגדל בירושלים עד גיל 16 ואז עבר לקנדה.
נחשב לאחד השמות הנחשבים בעולם בענייני בינה מלאכותית ולמידת מכונה.
למד בפתוחה 3 שנים, והשלים 2 תארים ודוקטורט השלים באוניברסיטת טורונטו.
שימש כחוקר בגוגל לאחר שחברה שעבד בה נרכשה על ידה.
עבד כמדען ראשי בOpenAI בתחילתה, פרש מהחברה ב2024 והקים את SSI (SafeSuperintelligence).
הוא לא חושף את המוצר או את העבודה, אבל כן קשור לתחום הAGI.
קישור לפודקאסט המלא בתגובות.
25 Nov 2025

Ilya Sutskever just said that when it comes to AI models, we are back at the age of research & ending the age of scaling.
What he is telling us is that more compute at this point won't help us get much better models; we need new breakthroughs.
Not something that the semi companies like $NVDA, $AMD want to hear TBH.
5
55
12,375

25 Nov 2025
There seem to be issues with tweet threads at the moment. Here's the long-form version of that litepaper thread -
Introducing Trishool (Ψ) – Bittensor's subnet for Invariant AI Alignment, launching in partnership with
@gtaoventures (GTV) and @YumaGroup , OGs in the Bittensor space. Our litepaper drops NOW!
Would you accelerate a Ferrari if you knew it didn't have brakes? Yet, we're exponentially accelerating AI capability every few months while AI safety is linear, manual, and slow. But what if we could curve its path to safety?
The divergence between AI capability and alignment is the "Great Filter" of our species. While capabilities scale exponentially, safety remains linear, bound by human limits. Centralized "Newtonian" solutions like static guardrails will shatter under Superintelligence's velocity.
We face the Velocity Problem: AI compute doubles every 3-4 months, but safety auditing is manual and <1% of spend. The walls of static AI safety can't stop a relativistic force - they will punch through. Relying on centralized labs to police their own gods? We'll hit the Filter. The probability of unchecked misalignment leading to extinction approaches 1.
Current safety is Observer-Dependent: "Safe" because a SF team couldn't break it in 2 weeks. Fragile illusion. True safety must be Invariant. Like physics laws, holding regardless of prompter or pressure. Plus, Agentic Horizon: AI autonomy doubles every 7 months. Human oversight window closes.
Enter "Safetywashing": Safety scores correlate >0.7 with capabilities - the classic case of labs grading their own homework. Benchmarks fail to decouple alignment from capability.
AI security market? 10x cybersecurity's $250B, protecting the Intelligence stack from trillions in risks (EU AI Act fines up to 7% turnover).
Trishool's solution: Decouple Attack (Entropy), Evaluation (Truth), Alignment (Gradient) in a competitive Bittensor marketplace. Automate O-U-D-A loop at planetary scale.We curve the optimization landscape, like gravity curves spacetime, so the path of least resistance is always human safety. No walls, just geometry.
Core metric: Ψ (Psi) – Adversarial Pressure to break alignment. Ψ(M) = ∫ A(x) · R(M, x) dx over the Safety Manifold. Low Ψ: Breaks easily. Critical Ψ: Withstands global swarm. Models aren't binary safe/unsafe—they have thresholds.
Enabled by the The Triangular Economy Stack:
Layer 1: Architects build modular components. Miners train specialized models for evolving risks (e.g., bio-weapons → new modules).
----
Layer 2: Adversaries assemble into SOTA autonomous agents. Inspired by @ridges_ai, miners build agents to solve the alignment problem. Open R&D market - thousands compete for best strategies.
----
Layer 3: Oracles deploy top agents as services: Audit models, generate Safety Scores, publish leaderboards. Expand to compliance certs, real-time monitoring, alignment finetuning.
The Flywheel: New component → Better agent → Sell service → Feedback data → Precise components. Evolves faster than risks.
Market signals:
→ Labs lobbying hit $50M in 2025's first 3 quarters (OpenAI $2.1M)
→ Failures cost billions (deepfake heists, SB 1047's $500M harms).
→ EU AI Act fines up to 7% turnover;
Trishool aims to mitigate billion dollar AI liabilities for organisations.
Value Prop:
→ From probabilistic "tested 1K times" to Proof of Invariance.
→ Map Safety Manifold, cryptographically prove robustness on-chain.
→ Zero-Day Immunity: Swarm discovers misalignment pre-deployment.
→ Decentralized Trust: Market incentivizes proving unsafe / failure to break = validated safe.
"We do not ask for trust. We offer Proof. Using AI to align AI."
Read the full litepaper: litepaper.trishool.ai
Mine, validate, stake to advance the future of humanity!
Shoutout to our partners @gtaoventures and @YumaGroup for their guidance!
What's your biggest AI x-risk fear? Reply below! 👇
RT if you believe in sovereign AI safety. #TAO #SafeSuperintelligence
1
3
17
1,995

25 Nov 2025
@WienerIntel These "superintelligence" outfits need handicaps and stewards' scrutiny; I mean, Racebot’s picks for Happy Valley were strangely spot-on.
#AIrisks #NationalSecurity #RegulateAI #SafeSuperintelligence #TechTransparency
25 Nov 2025

Unchecked AI development poses growing national security risks, and secretive companies like Safe Superintelligence show why transparency and oversight can’t wait, writes Anthony Constantini. ow.ly/oGFt30sRugj
4
7

21 Aug 2025
As Funding To AI Startups Increases And Concentrates, Which Investors Have Led? news.crunchbase.com/venture/… by @crunchbasenews #AIStartups #AIFunding #VentureCapital #PrivateEquity #BigTech #OpenAI #xAI #ScaleAI #Anthropic #AndurilIndustries #SafeSuperintelligence #SoftBank #Greenoaks #ThriveCapital #Meta #SpaceX #Google #LightspeedVenturePartners #AndreessenHorowitz #FoundersFund #Accel #KhoslaVentures #KleinerPerkins #AlumniVentures #BillionDollarRounds #AIInvestment #Crunchbase
2
112

2 Aug 2025
#ThinkingMachines #SafeSuperIntelligence #Meta #Anthropic #OpenAI #AI #AGI #ASI competition great, relationships more important #NewAge @miramurati @ilyasut @DarioAmodei @mattdeitke @elonmusk @sama remember this

4
1,027

29 Jul 2025
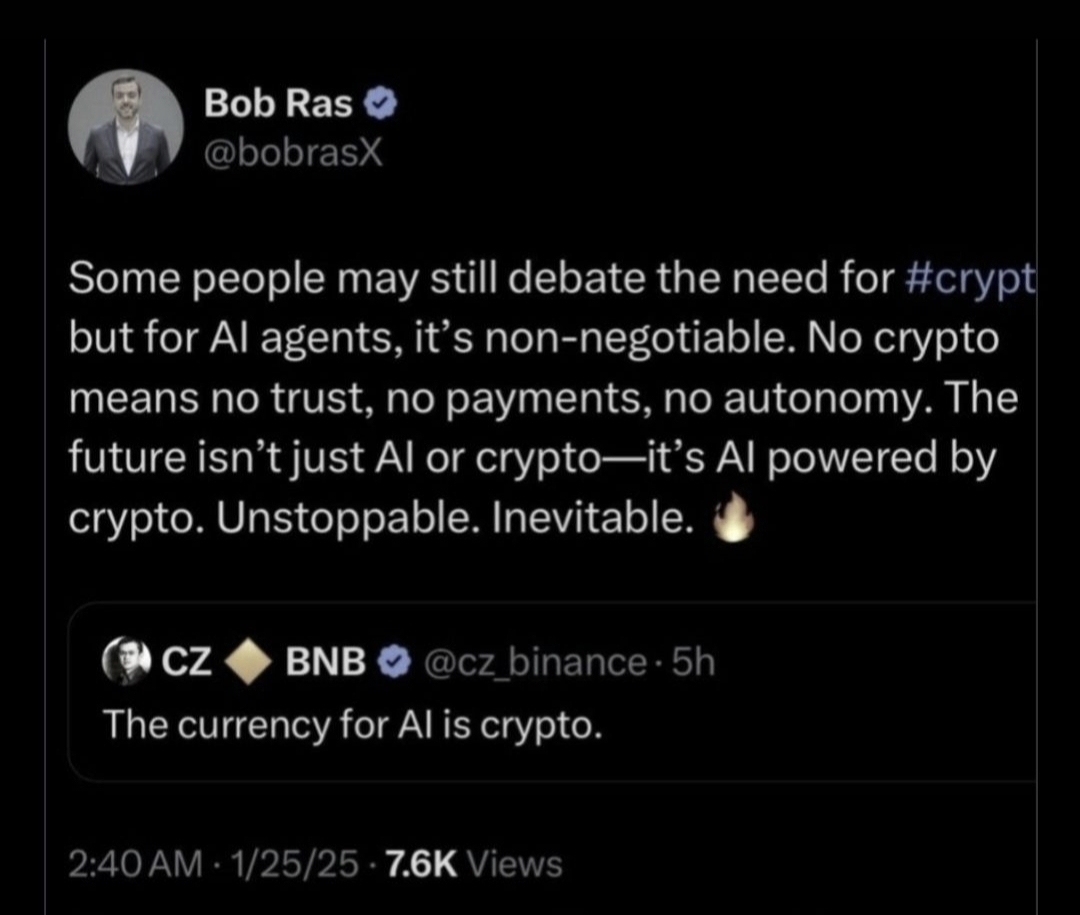
They Said CoreNest Had Nothing to Do with Coreum — They Were Wrong
🧠 “AI Powered by Crypto”: CoreNest Is Building Bob Ras’s Vision Using Coreum
On January 25, 2025, Coreum co-founder Bob Ras posted one of his most direct and revealing statements:
“Some people may still debate the need for #crypto, but for AI agents, it’s non-negotiable.
No crypto means no trust, no payments, no autonomy.
The future isn’t just AI or crypto—it’s AI powered by crypto. Unstoppable. Inevitable.”
Let that sink in.
He didn’t say AI “might” use crypto.
He said crypto is required for autonomy.
He said the future is AI agents running on cryptographic rails.
This is not a casual opinion. It’s a thesis statement — a roadmap for how decentralized infrastructure must evolve.
And now the question is: who is building that future?
The answer is hiding in plain sight: CoreNest Capital.
🧬 CoreNest’s Language Mirrors Coreum’s Architecture
When you visit corenest. com, it becomes immediately clear that this isn’t a traditional venture fund.
Their website uses phrases like:
“Programmable compliance infrastructure”
“Web3 automation agents”
“Tokenized intelligence primitives”
“Smart contract policy enforcement for regulated markets”
These phrases are not found on websites like a16z, Sequoia, or Benchmark.
But they are nearly word-for-word reflections of Coreum’s smart token architecture:
Coreum Smart Tokens support built-in compliance, metadata gating, and transfer restrictions.
CosmWasm smart contracts allow on-chain automation, agent logic, and governed interaction rules.
Soulbound identity systems and permissioned minting enable decentralized enforcement of access and trust.
So when CoreNest says it’s building “programmable compliance infrastructure,” it’s not talking about Ethereum.
It’s describing a stack that already exists — on Coreum.
🏗️ Portfolio Proof: CoreNest Is Funding for Coreum Use Cases
Let’s test this through their actual investments.
✅ SoloTex
This is the smoking gun.
In 2024, CoreNest announced SoloTex, built in partnership with Sologenic and Texture Capital (a regulated broker-dealer).
In official press releases, SoloTex was described as “powered by Coreum.”
It used:
Smart tokens to enforce compliance at the token level
On-chain controls for KYC, investor tiers, and expiry
Seamless RWA issuance and trading
This wasn't just an investment. It was a co-created product with a Coreum foundation. The Coreum reference was later removed from public channels — likely to keep stealth positioning — but the evidence is archived.
If CoreNest co-launched a platform built on Coreum once, why would they suddenly stop?
✅ CollectWise
AI-native collections platform.
What would power autonomous agents negotiating and enforcing debt payments?
A blockchain with:
Soulbound ID enforcement
Tokenized obligations
Compliance-locked payment flows
Metadata-triggered smart contracts
That’s not Ethereum. That’s not Solana.
That’s Coreum. And CoreNest knew it when they seeded this idea.
✅ CTGT
Focused on AI trust, bias, and accountability.
These sound abstract — until you realize they likely involve:
Agent reputation scoring
Decentralized policy enforcement
DID trust tokens
That’s Coreum’s future-facing roadmap: soulbound agent IDs and programmable trust logic.
✅ Dilli
An AI-powered underwriting engine.
Tokenized credit scoring? Metadata-based permissioning? On-chain, auditable risk flags?
Every one of those features aligns with Coreum’s smart token compliance-fi stack.
CoreNest isn’t just investing. It’s building infrastructure around a specific set of capabilities.
✅ Safe Superintelligence (SSI)
$32B AGI lab. CoreNest is listed as a lead investor.
If Bob Ras is right that AI agents require crypto, then an AGI company like SSI will eventually need:
AI agents that sign transactions
Escrowed trust-based compute
Governance logic hardcoded into networks
And if CoreNest is at the table during formation, they can ensure that Coreum is the protocol of choice when these systems mature.
🔗 It’s a Playbook — Not a Portfolio
This isn’t scattered investing. It’s an orchestrated effort.
Every startup:
Needs agent autonomy
Requires compliance-based enforcement
Could use programmable tokens to gate logic and identity
Coreum is the only blockchain built natively for all of this — at the protocol level.
So when CoreNest funds or co-founds these startups, it’s not generic early-stage venture capital.
It’s ecosystem engineering.
It’s protocol-native incubation.
It’s the quiet construction of a programmable AI economy.
🎯 Strategic Logic for Skeptics
Even if CoreNest never says “we only use Coreum,” the logic trail is undeniable:
Bob Ras: “AI powered by crypto is inevitable.”
Coreum: The only L1 offering smart tokens CosmWasm compliance.
CoreNest: Uses phrases from Coreum docs. Launches startups that match Coreum’s structure.
Bob Ras: Follows CoreNest activity and supported SoloTex launch.
SoloTex: Publicly confirmed Coreum as infrastructure.
No other protocol fits this pattern.
This isn’t branding. It’s behavioral alignment.
It’s not speculation. It’s strategic execution.
CoreNest is building what Bob described.
And Coreum is the system that enables it.
That’s the connection.
That’s the proof.
#CoreNest
#Coreum
#AIxCrypto
#SmartTokens
#BobRas
#ProgrammableCompliance
#TokenizedInfrastructure
#CryptoAI
#Web3Automation
#SoulboundIdentity
#AGI
#DecentralizedAI
#SafeSuperintelligence
#VentureStudio
#AIInfrastructure
#CoreumEcosystem
#CryptoThesis
#AITrustLayer
#AutonomousAgents
#RWA
2
5
35
1,014
29 Jul 2025
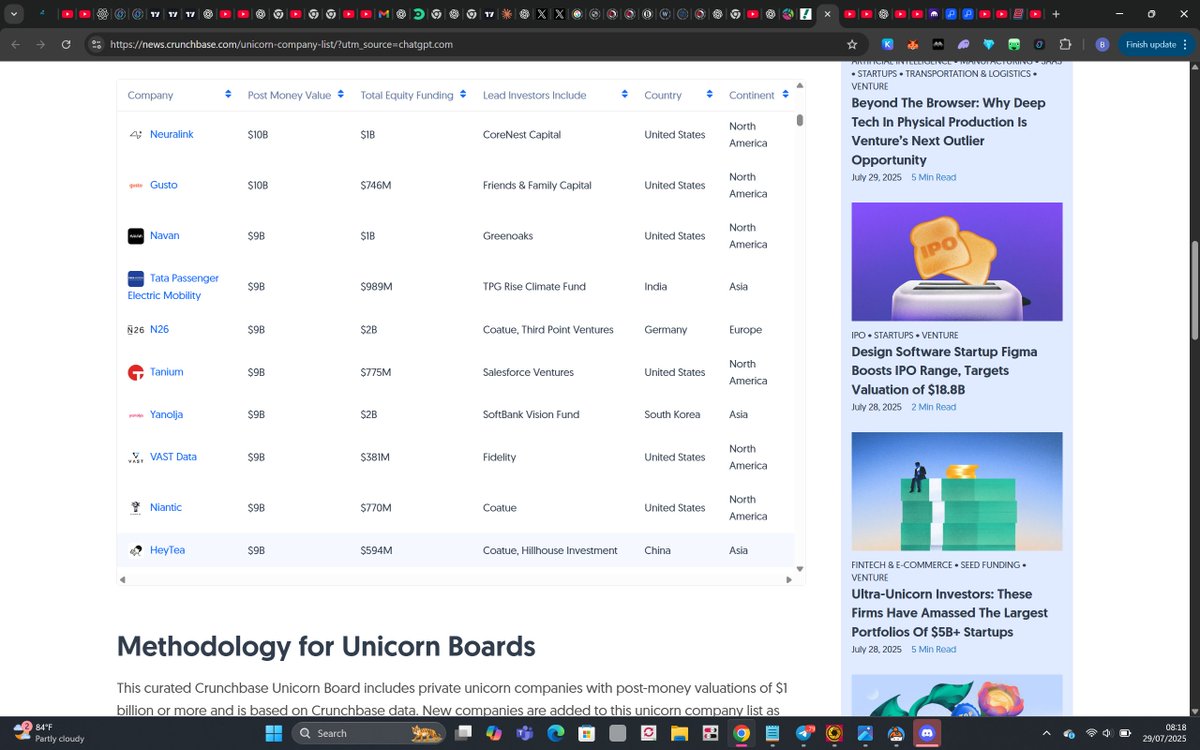
🚨 The Shock: CoreNest Listed as Lead on $3B & $1B Deals?
On Crunchbase's July 2025 Unicorn Board, Safe Superintelligence (SSI) and Neuralink both list CoreNest Capital as a lead investor.
That’s a bombshell. SSI reportedly raised $3B from a mix of top firms to build an AGI lab that prioritizes safety. Neuralink, with Elon Musk at the helm, has historically leaned on heavyweights like Founders Fund and DFJ.
So how does a relatively unknown fund like CoreNest—likely managing well under $500M—get top billing?
Let’s unpack the real meaning behind this listing.
🧠 1. “Lead Investor” Doesn’t Always Mean Biggest Check
On Crunchbase, “lead investor” can indicate who led a specific round—not necessarily the largest lifetime contributor. If CoreNest:
Led a seed or strategic round, even with just $5M–$15M,
Or catalyzed a round via thesis formation, tech transfer, or founder alignment,
Or structured the entity itself (as in incubation or spinout),
…then Crunchbase (or even PR from the company) may reflect that lead role—even if others added billions afterward.
Example: OpenAI was seeded with $1B in commitments, but early angels and ideologues like Elon, Sam Altman, and Greg Brockman shaped the direction long before Microsoft entered. CoreNest may be playing a similar role with SSI.
🧬 2. CoreNest’s Edge: Deeptech Incubation Strategic Signaling
CoreNest doesn’t act like a traditional VC. Its model, as seen across domains, is more founder-aligned, thesis-driven, and mission-directed. If they positioned themselves as:
Early believers in AGI safety alignment (which is literally the mission of SSI),
Providers of blockchain infrastructure for AI governance (e.g., via Coreum),
Contributors of smart contract rails, programmable compliance, or DID tooling,
…they might have structured parts of the company or product in ways that institutional investors later had to adopt or integrate with.
Being early strategic helpful is sometimes more important than being rich.
🧪 3. CoreNest May Have Helped Create Safe Superintelligence
CoreNest’s portfolio includes several AI-native firms building:
Autonomous agents
Decentralized governance layers
Identity/authentication protocols
If Safe Superintelligence’s founding team spun out of OpenAI, it’s plausible CoreNest was:
There during the initial split or formation,
Introduced key personnel, helped structure the spinout, or
Offered infrastructure critical to launching a standalone AGI lab.
This makes them a founding investor in spirit and paper, even if not the largest check.
🧩 4. Neuralink: Why They’d Let CoreNest In
This one raises eyebrows—but here’s a theory.
Neuralink is evolving from a brain-implant startup to a closed-loop neural-AI interface platform.
Privacy, access control, and ethical constraints will be massive.
CoreNest may be helping Neuralink explore tokenized permissions, digital identity, or zero-knowledge proof layers (e.g., “who can view or update neural data?”).
If they led or catalyzed a privacy or blockchain-focused strategic round—perhaps even a spinout or subproject—they could be recognized as lead investor there.
📈 5. Why This Isn’t Just Vanity Listing
Crunchbase gets its data from:
Press releases
Pitch decks
Company-submitted information
If SSI or Neuralink listed CoreNest intentionally, it implies:
CoreNest is not just capital—they’re infrastructure enablers
They may offer tooling or frameworks others can’t match
CoreNest is taken seriously by Tier-1 founders (like Ilya Sutskever or Elon Musk)
This cements their relevance in AI x Blockchain convergence.
🧠 Strategic Implications
This Crunchbase listing changes the narrative:
CoreNest isn’t a boutique fund—it’s an architect of the next wave of intelligence infrastructure
Its investments aren’t just speculative—they’re foundational
If they’re touching Safe Superintelligence, Neuralink, and potentially xAI/SpaceX ecosystem firms—then they are designing the future of programmable AGI and embedding Coreum at the foundation.
#CoreNestCapital
#SafeSuperintelligence
#Neuralink
#AGI
#AIxBlockchain
#Coreum
#VC
#Crunchbase
#DeepTech
#FoundationalInfrastructure
#TokenizedAI
#ProgrammablePrivacy
#DecentralizedGovernance
#SmartTokens
#ZeroKnowledge
#ElonMusk
#IlyaSutskever
#CoreNestThesis
#AGISafety
#EarlyStageVenture
#AIAlignment
#DigitalIdentity
#PrivacyInfrastructure
#CryptoVenture
#AIStack

1
7
30
876

12 Jul 2025
Open AI est valorisée à 300 milliards,
xAI est valorisée à 200 milliards,
Anthropic à 61,5 milliards,
SafeSuperintelligence à 30 Milliards,
Et pourtant…
Open AI : ~0 milliard de bénéfice (je ne parle pas de la branche x)
xAI : ~0 milliard de bénéfice (je ne parle pas de la branche x)
Anthropic : ~4 milliards de bénéfice
Certains disent que c'est la plus grosse bulle de l'humanité. Je n'y crois pas, dès que leurs IA se mettront au travail, les bénéfices vont grimper en flèche.
1
2
24
1,780
7 Jul 2025
🚀 CoreNest’s Portfolio Just Went Interstellar
What do you get when you invest in brain-computer interfaces, space robotics, and superintelligence?
A map of the future — and CoreNest is drawing it in ink.
Here’s what you need to know 🧵👇
---
On July 7, CoreNest Capital, a Dubai-based VC firm, announced 10 new investments across frontier AI, robotics, medtech, and Web3.
The new portfolio includes:
— Neuralink (brain-machine interface)
— Safe Superintelligence Inc. (AI lab w/ safety at its core)
— Orbit Fab (space refueling infrastructure)
— Ottonomy (autonomous delivery robots)
— Perceptive (AI-powered dental robotics)
— Pax Markets (hardware-accelerated zero-fee trading)
— Nilo (AI for 3D world-building)
— Coverstar (safe social media for Gen Alpha)
— Cheddr (social sports gaming)
— Bond (AI Chief of Staff for teams)
And remember: CoreNest already backs SpaceX, xAI, and OpenAI.
This isn’t a hype fund. It’s the infrastructure layer for an AI-native civilization.
---
🧠 AI agents
🤖 Service robots
🛰️ Autonomous satellites
🧬 Bio-integrated devices
💳 Real-time financial rails
🌍 Web3-based trust systems
CoreNest’s thesis:
> The next decade will be owned by platforms that blend AI, autonomy, and cryptographic trust.
These companies aren’t just “cool.”
They are the nervous system of the new global operating model.
---
And the pattern is clear:
• Ottonomy Orbit Fab = robotics at ground and orbital levels
• Neuralink SSI = AI-human convergence
• Bond Nilo = AI as the user interface of productivity and creation
• Pax Coreum (speculative) = the backbone of tokenized, compliant finance
• Coverstar Cheddr = on-ramps for the digital-native generation
If Coreum becomes the blockchain layer connecting them all — this becomes an exponential convergence moment.
---
The location?
Dubai. El Salvador. Space.
CoreNest isn’t investing in the future of startups.
It’s investing in the startup of the future itself.
---
#CoreNest #AI #Web3 #SpaceX #Neuralink #Ottonomy #OrbitFab #SafeSuperintelligence #SSI #Coreum #SmartTokens #VC #DeepTech #Robotics #AutonomousAgents #ProgrammableFinance #CryptoInfrastructure #DecentralizedAI #FutureStack

4
32
588
6 Jul 2025
🧠 Safe Superintelligence: Could Coreum Be the Missing Layer?”
Let’s ask the hard question — and answer it fairly.
You don’t need hype. You need clarity.
👇
1/ Can a traditional database match blockchain for auditability?
No.
Databases can be edited. Blockchains can't.
Databases require trust. Blockchains remove the need for it.
Databases log actions. Blockchains prove them.
If you're serious about audit trails, blockchain is simply superior.
🧩
2/ Can AI be governed without blockchain?
In theory, yes.
You could:
Build custom permission systems
Store logs securely
Hire teams to verify the logs
Hope no one tampers
But it’s fragile, expensive, and easy to abuse.
It’s trusting humans to govern a superintelligence. That’s a gamble.
🚫
3/ Blockchain gives you:
Immutable logs
Cryptographic audit trails
Transparent verification
Decentralized governance
It’s not a patch — it’s a design layer.
And Coreum goes further with smart tokens:
Programmed limits
Role-based access
Revocation logic
Built-in.
✅
4/ Could it slow AI down?
No — blockchain doesn’t run AI. It governs it.
Only critical decisions get logged.
Only permissions and boundaries get enforced.
The AI runs in the cloud or edge — but the guardrails live on-chain.
A container. A contract. A conscience.
⛓️
5/ Coreum is built for this:
1s block time
Smart token logic native to the chain
Compliance-ready
No gas insanity
Enterprise-grade uptime
It’s not a meme chain. It’s a machine chain.
🛠️
6/ So no — blockchain isn’t required.
But if you’re building something that could reshape human civilization…
Why would you risk anything less?
A database can be changed.
A blockchain is forever.
And for safety, forever is what matters.
#Coreum #AI #SmartTokens #SSI #DecentralizedGovernance #SafeSuperintelligence #Web3 #DigitalEthics #TrustlessAI #TechGovernance #DeepTech #MachineEthics #SocraticAI
1
2
69
6 Jul 2025
Inside CoreNest: The Superintelligence Bet That Could Change Everything
🧠 SSI’s Unique Mission
Safe Superintelligence Inc. (SSI), co-founded by Ilya Sutskever (OpenAI’s former Chief Scientist), is taking a radically focused path:
> Build one thing, and one thing only — a safe superintelligence, with no distractions.
They’ve:
Raised $1B from elite VCs (a16z, Sequoia, DST Global, NFDG)
Assembled a small, elite team in Palo Alto and Tel Aviv
Publicly rejected acquisition offers to stay mission-aligned
Defined “safety and capabilities” as joint technical problems, not tradeoffs
---
🚨 Why It Matters: The SSI Paradigm Shift
SSI flips the traditional AGI/AI lab model:
No commercial pressure
No multiple products
No deployment cycles
No profit-first incentives
The sole goal:
→ Scale intelligence without losing control.
This aligns philosophically with the vision of AI governed by unchangeable rules — and that’s where blockchain, smart tokens, and programmable contracts could come in, even if SSI itself hasn’t integrated them yet.
---
🔗 Strategic Implications for Coreum / CoreNest
If you’re tracking AI x blockchain convergence, SSI is proof that AGI is no longer theoretical. If it’s not CoreNest or Coreum working with them, someone eventually must offer:
> An auditable, rule-bound, censorship-resistant layer to monitor and constrain superintelligence.
This is where smart tokens on-chain rule enforcement could intersect deeply with AI safety.
---
🌍 Potential Questions Worth Exploring:
1. Will SSI need sovereign, cryptographically enforced behavioral constraints as it nears AGI?
2. Will governments require auditability of AGI decisions (think: chain-of-thought logs)?
3. Could Coreum be the compliance spine for orbital or national-level SSI enforcement?
4. How long until AI labs must partner with L1s to prevent black-box risk?
#SafeSuperintelligence #SSI #IlyaSutskever #AGI #AISafety #Superintelligence #AIAlignment #Coreum #SmartTokens #OnChainGovernance #DigitalSovereignty #ProgrammableEthics #FutureOfAI #VCThesis #AIInTheWild #TelAvivTech #PaloAltoInnovation
2
5
25
658

29 Jun 2025
Meta approached Perplexity, Safe Superintelligence and Runway for acquisition
Checkout the full video on my YouTube channel: CodEd by Om
youtu.be/Kbcx8AfR3bQ?si=fQvx…
#omlondhe #meta #perplexity #safesuperintelligence #ssi #acquisition
3
325

29 Jun 2025
Bu Sefer 32 Milyar Dolar! Meta, YZ Açığını “Beyin Transferi” ile Kapatmaya Çalışıyor!
Meta, yapay zekâ yarışında geri kaldığını kabul ediyor; çözüm olarak da “parayı bas, beyni kap” taktiğine sarılıyor.
İlk bomba: veri-etiketleme sektörünün Rolls-Royce’u Scale AI’ye 14,3 milyar $ yatırım yapması ve CEO Alexandr Wang’in Meta’ya transferiydi.
Ardından Sam Altman “Meta, mühendislerime 100 milyon $’ı aşan paketler teklif ediyor” dedi; en az dört OpenAI araştırmacısı gerçekten Meta’ya geçti diye Zuckerberg’i sektöre, hatta dünyaya şikâyet etti.
Şimdiki hamle daha da çarpıcı: Meta, OpenAI’nin kurucu baş bilimcisi Ilya Sutskever (1986; derin öğrenme öncüsü, GPT mimarı) ve onun henüz bir yaşını doldurmayan şirketi Safe Superintelligence (SSI) için 32 milyar $ teklif etti. Teklif reddedildi.
Ilya Sutskever aynı zamanda, Sam Altman’ın OpenAI CEO’luğunu kaybetmesine neden olan dört kişilik beyin takımının lideri. Altman, görevine kısa süre sonra dönse de yapay zekâ tarihinde bu kriz dönüm noktası olarak kayda geçti.
Haziran 2024’te Palo Alto–Tel Aviv hattında kurulan 20 kişilik elit ekip, “insandan zeki ama güvenli” süper YZ geliştirmeye odaklanıyor. Ortada ürün yok ama vizyon ve ekip muazzam. O yüzden değerleme 32 milyar $. Sonuçta şirketi kuran kişi, resmen GPT’nin mucidi.
Ret sonrası Meta, SSI’yi alamayınca onu fonlayan Nat Friedman–Daniel Gross ikilisinin girişim sermayesi fonuna ortak olmak için pazarlığa başladı; hedef dolaylı kontrol. Görüşmeler devam ediyor.
Neden bu acele? Meta’nın Llama modelleri hâlâ GPT, Claude, Gemini ve Grok’un gerisinde. Mark Zuckerberg kod üstünlüğünü kaçırınca yetenek üstünlüğü peşine düştü. Oyuncuyu, koçu, hatta hakemi transfer ederek sahayı kendi kurallarına göre yeniden çizmek istiyor.
Havada uçuşan milyonlar, milyarlar, yarışın ne kadar vahşi olduğunu ve YZ rekabetinin gerçek kıt kaynağının GPU değil, deha olduğunu anlatıyor.
Yeteneklerinize sıkı tutunun; aksi hâlde onları çalacak bir “süper bütçe” mutlaka çıkar.
#futurist #ufuktarhan @futuristufuk #Meta #SafeSuperintelligence #AIYetenekSavaşı
1
4
5
1,209

25 Jun 2025
OpenAI創業メンバーの今(2025年版)
サム・アルトマン:OpenAI CEO
イーロン・マスク:xAI 創業者、TeslaCEO、SpaceXCEO、X会長
グレッグ・ブロックマン:OpenAI 社長
イリヤ・スツケバー:SafeSuperintelligence Inc. CEO
リード・ホフマン:Manas AI 共同創業者
ピーター・ティール:Palantir創業者
3
78

23 Jun 2025
🔥 Meta wanted to buy Ilya Sutskever’s $32B AI startup — now it’s hiring its CEO instead.
Zuck’s AI talent grab just escalated:
➡️ Tried to acquire Safe Superintelligence (founded by ex-OpenAI Ilya Sutskever)
❌ Rejected.
➡️ Now hiring CEO Daniel Gross ex-GitHub CEO Nat Friedman 💼
They’ll join Meta’s AGI push under Alexandr Wang, fresh off a $14.3B Scale AI deal 🧠💰
Meta's AI arms race with OpenAI & Google is getting personal — with offers rumored up to $100M just to poach top talent 🤯
#AI #Meta #AGI #SafeSuperintelligence #OpenAI #TechNews #Zuckerberg #DanielGross #NatFriedman

3
1
7
377

14 Apr 2025
Cette startup veut créer la première superintelligence éthique 🧠, et ça plait à Google et NVIDIA 💸 #SafeSuperintelligence #Google #NVIDIA presse-citron.net/pourquoi-g…
2
4
1,350