解析機能の中でもビジュアルウェイト、Scanpath、構図アドバイスはこれまでのレタッチツールはない機能で色々気づきを得られると思います!
ポートレート、風景、スナップなどジャンル問わず使えます。
ポートレートでご使用いただきありがとうございます!

あまと〜さんのレタッチツール「Amadeus」を過去に投稿した写真に使ってみました。
1枚目:WARM FILM 40011適用
2枚目:AQUA適用
「解析機能」の活用でいろいろと気づきもありました。
#Amadeus


6
2,273

Jun 13
【お知らせ】
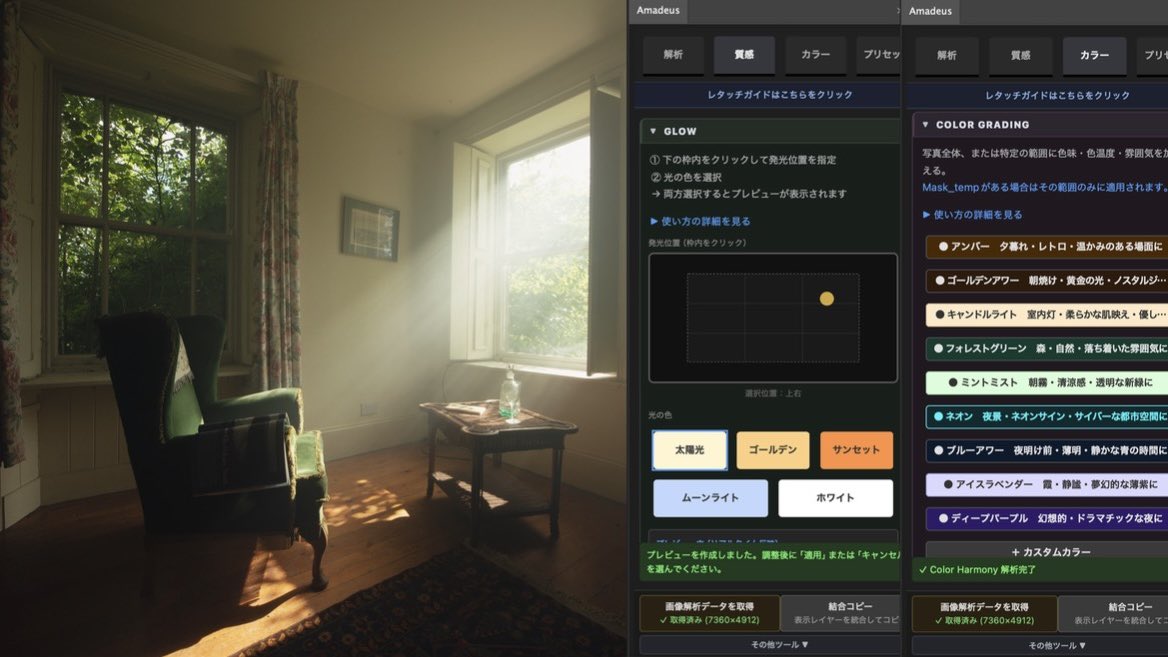
開発したレタッチツールAmadeusがリリースされました!
国際フォトコンテスト1位を多数受賞してきた自分のレタッチをそのままPhotoshopプラグインにしました。
写真を解析し最大34レイヤーをワンクリックで自動生成します。
できること(抜粋)👇
● 16種の多層構造プリセット(プロの「仕上げの設計」をそのまま再現)
● 憧れの写真の色を自分の写真へ移植する Chromatic DNA
● 視線の流れを予測しスコア化する Visual Weight / Scanpath
● 写真ごとの構図改善アドバイス
● すべて非破壊編集。あとからレイヤーで自由に微調整
「Lightroom中心だけど、Photoshopも本格的に使ってみたい」
「自分の作風をもっと確立したい」
そんな方のために日本語UI・ガイド付きで作りました。
Mac/Windows対応・買い切りです。
公式サイトのURLはリプ欄に👇




2
24
168
212,744
Jun 6
Amadeusの公式サイトを先行公開しました!
Amadeusはレタッチ初心者から上級者まで使える、Photoshopで本格的に写真を仕上げる人のためのレタッチ支援プラグインです。
● 写真の色・輝度情報を解析し、最大34レイヤーをワンクリックで生成する全16種類の本格プリセット
● 憧れの写真の明るさや色味を自分の写真へ転送できる Chromatic DNA
● 写真の中で目立つ場所を可視化する Visual Weight
● 視線の流れを予測し、写真ごとの構図アドバイスを行う Scanpath
マスク・質感・カラー・プリセット・構図アドバイスまで、写真の仕上げで迷いやすい部分をまとめて支えるツールとして作りました。
「レタッチはLightroom中心だけど、Photoshopを本格的に使ってみたい」
「Photoshopでレタッチしているけど自分の作風をもっと確立させたい」
「レタッチ前に写真の方向性や改善点を確認してから取り組みたい」
そんなLightroom・Photoshopユーザーの方に使っていただきたいツールです!
風景・ポートレート・夜景・スナップなどあらゆるジャンルでご使用いただけます!
発売記念価格も予定しています。
ぜひ一度サイトを見ていただけると嬉しいです!
サイト内に実画面での機能紹介動画もご用意してます。
リプ欄にURL載せています!



5
27
142
38,275

New publication ✨🧩
Our latest work explores AI-driven eye-tracking for #autism screening , leveraging hybrid ensemble learning on scanpath data.
🔗 Article Link
is.gd/bbwHxA
A collaborative effort between Emirates Health Services & the University of Dubai.
@EHSUAE @uniofdubai
#Autism #AI #MachineLearning #Research #UAE

1
4
287


4 Dec 2025
Hi all, today, we will be presenting "𝑫𝒊𝒇𝒇𝑬𝒚𝒆: 𝑫𝒊𝒇𝒇𝒖𝒔𝒊𝒐𝒏-𝑩𝒂𝒔𝒆𝒅 𝑪𝒐𝒏𝒕𝒊𝒏𝒖𝒐𝒖𝒔 𝑬𝒚𝒆-𝑻𝒓𝒂𝒄𝒌𝒊𝒏𝒈 𝑫𝒂𝒕𝒂 𝑮𝒆𝒏𝒆𝒓𝒂𝒕𝒊𝒐𝒏 𝑪𝒐𝒏𝒅𝒊𝒕𝒊𝒐𝒏𝒆𝒅 𝒐𝒏 𝑵𝒂𝒕𝒖𝒓𝒂𝒍 𝑰𝒎𝒂𝒈𝒆𝒔" with Harris Nisar at:
📆 𝐒𝐞𝐬𝐬𝐢𝐨𝐧: 11 a.m. — 2 p.m. PST
📍 𝐏𝐨𝐬𝐭𝐞𝐫: #1406 (Exhibit Hall C, D, E)
𝐓𝐋;𝐃𝐑: DiffEye achieves SOTA scanpath generation and high-fidelity trajectory synthesis by modeling raw data rather than processed scanpaths.
Stop by to say hi!

1
16
2,226

2 Dec 2025
🧠 Gaze-guided streaming data construction
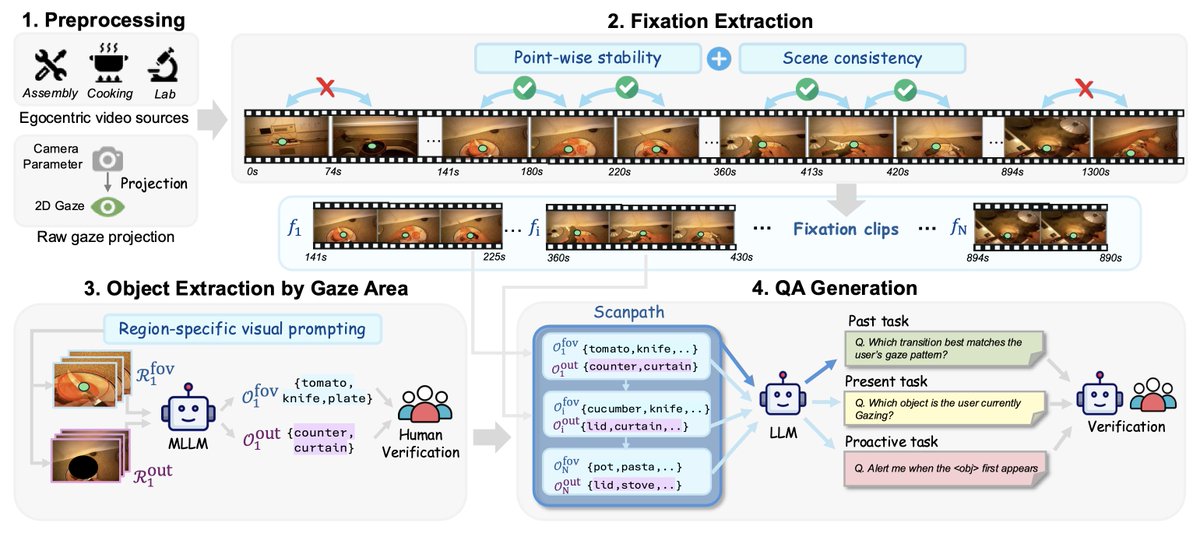
We design a novel data construction pipeline to build gaze-guided streaming video understanding tasks.
1. Preprocessing: We project raw gaze trajectories onto video frames using camera parameters.
2. Fixation Extraction: We extract stable fixation periods that represent meaningful, attention-driven moments.
3. Object Extraction: We divide each frame into FOV and out-of-FOV regions and extract objects from each area using region-specific visual prompting.
4. Scanpath & QA Generation: We construct scanpaths and conduct human verification to ensure quality, consistency, and alignment with human annotations.
1
6
220
2 Dec 2025
🤔 We rely on gaze to guide our actions, but can current MLLMs truly understand it and infer our intentions?
Introducing StreamGaze 👀, the first benchmark that evaluates gaze-guided temporal reasoning (past, present, and future) and proactive understanding in streaming video settings.
➡️ Gaze-Guided Streaming Benchmark: 10 tasks spanning past, present, and proactive reasoning, from gaze-sequence matching to alerting when objects appear within the FOV area.
➡️ Gaze-Guided Streaming Data Construction Pipeline: We align egocentric videos with raw gaze trajectories using fixation extraction, region-specific visual prompting, and scanpath construction to generate spatio-temporally grounded QA pairs. This process is human-verified.
➡️ Comprehensive Evaluation of State-of-the-Art MLLMs: Across all gaze-conditioned streaming tasks, we highlight fundamental limits of current MLLMs. All MLLMs fall far below human performance. Models particularly struggle with temporal continuity, gaze grounding, and proactive prediction.
1
25
46
12,927

30 Nov 2025
🚨 New paper at #NeurIPS2025!
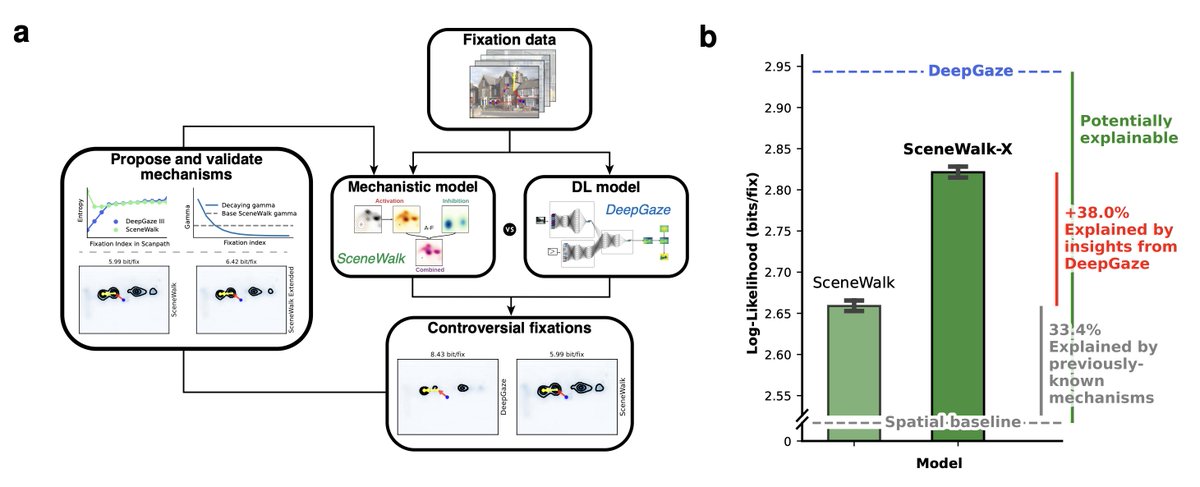
A systematic fixation-level comparison of a performance-optimized DNN scanpath model and a mechanistic cognitive model reveals behaviourally relevant mechanisms that can be added to the mechanistic model to substantially improve performance.
🧵👇
1
4
8
1,946

26 Sep 2025
This Monday Trong Thang Pham from University of Arkansas will be joining us to talk about their work on a dataset and baselines for 3D volumetric scanpath modeling. Catch it at 1-2pm PT this Monday on Zoom! Subscribe to mailman.stanford.edu/mailman… #ML #AI #medicine #healthcare

2
5
586

21 Jul 2025
We present a probabilistic model that jointly generates the three components of each fixation: onset time, landing position (saccade planning) , and duration (duration modelling). Here below an animation of our model on an unseen scanpath sequence (slower version in our repo):
1
6
442
21 Jul 2025
💥 New #ACL2025 main paper!💥
Most #eye #tracking studies collapse fixations into a single “gaze time” metric. We model the full scanpath with a generative probabilistic model. Why? To test how disaggregated modeling stacks up against aggregated approaches.🧵 #Psycholinguistics

1
4
12
1,354

23 Apr 2025
We are excited to announce two big new features for Pupil Cloud. Check out the video for an overview & head over to Pupil Cloud to try them out.
Manual Correction for Enrichments
We added a way to augment and correct the results from our automated gaze mappers. You can now correct for missed classifications, occlusions and anything else that needs a human in the loop. It can also be used to add a validation step to each automated enrichment.
Scanpath Visualization
This is a new visualization that renders fixation and saccade patterns on reference images. You can make visualizations for one or more recordings, and adjust the visual properties of the scanpath(s) to suit your requirements.
Full release notes: pupil-labs.com/releases/v7-5…
1
4
278

10 Feb 2025
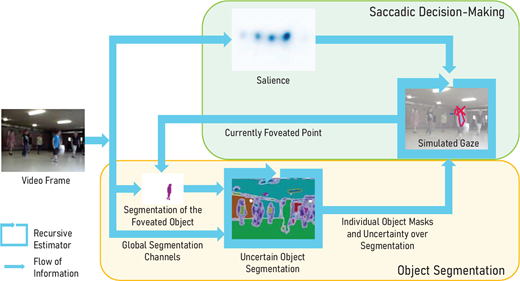
New in the Uncertainty in Sensory Processing and Action Control Issue bit.ly/4b4tepa, Vito Mengers et al. show A Robotics-Inspired Scanpath Model Reveals the Importance of Uncertainty and Semantic Object Cues for Gaze Guidance in Dynamic Scenes, jov.arvojournals.org/article….
2
233

21 Nov 2024
What an awesome venue for the 8th ScanPath meeting 👌


4
112

12 Nov 2024
The paper aims to develop a unified model, called UniAR, to predict different types of human behavior on visual content, including attention, viewing sequence, and subjective preferences or likes. Prior research has often focused on modeling these behaviors in isolation and for specific types of visual content, such as natural images, webpages, or graphic designs.
UniAR achieves state-of-the-art performance across 11 benchmark datasets spanning natural images, webpages, and graphic designs, for predicting attention/saliency heatmaps, scanpath sequences, and subjective ratings. UniAR outperforms or performs comparably to dedicated models trained on specific tasks and datasets.
full paper: openread.academy/en/paper/re…

3
266

6 Nov 2024
See the flaw in the definition of 1Hz scanpath? For a 1-second duration, the event of that specific gaze sample isn't guaranteed to be a fixation! Instead, it could be a part of scanpath, smooth pursuit, or any other eye events. (3/n)
2
566

12 Oct 2024
I will present our paper on scanpath prediction on user interfaces at #UIST2024.
Our model has the unique capability of producing personalized predictions when given a few user scanpath samples.
See the paper, video, and code:
yuejiang-nj.github.io/Public…
@oulasvirta @luileito
1
6
58
3,289
20 Aug 2024
Follow along with our latest Alpha Lab guide to build custom scanpath visualizations. 👀
Scanpaths are graphical representations of fixations and saccades over time. They show how a person has looked at different aspects of a scene, and in what order, making them useful for understanding visual attention and perception.
Key features:
- Builds on results from Pupil Cloud’s Reference Image Mapper and Manual Mapper enrichments.
- Runs in Google Colab for quick and flexible visualizations, with an option to run scripts locally.
- Supports generation of both static and dynamic (video) scanpath visualizations, depending on your requirements.
Check it out: docs.pupil-labs.com/alpha-la…
1
6
387

A Robotics-Inspired Scanpath Model Reveals the Importance of Uncertainty and Semantic Object Cues for Gaze Guidance in Dynamic Scenes. arxiv.org/abs/2408.01322
2
115