
🌐 Scrapling: The #Python Scraping Library That’s Redefining Web Data Extraction with #AI-Powered Adaptation and Anti-Bot Stealth Video
undercodetesting.com/scrapli…
Educational Purposes!
5
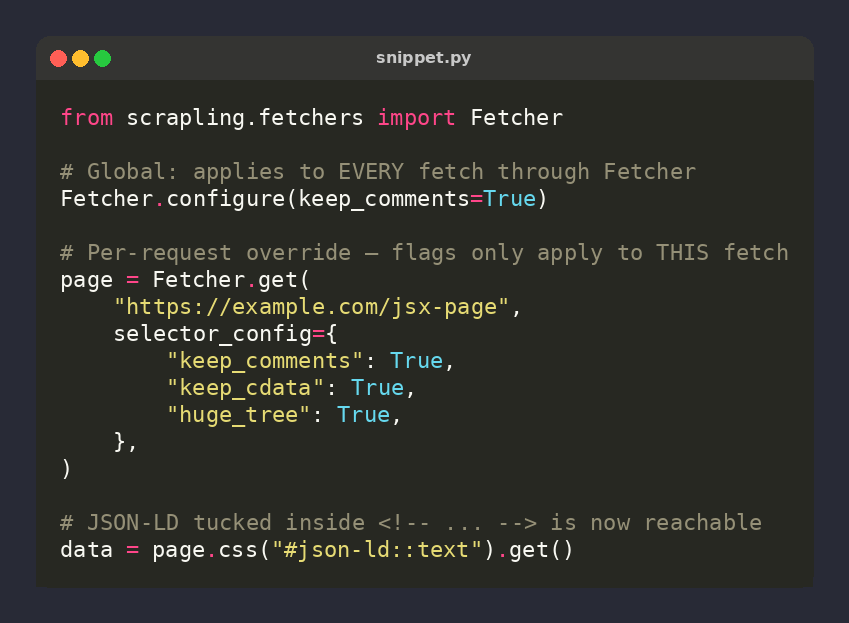
🕷️ Scrapling tip: Fetcher.configure() sets parser flags GLOBALLY — selector_config={...} is the per-REQUEST override
Flip keep_comments/keep_cdata/huge_tree/adaptive for ONE fetch without touching the rest of your crawl ⚡
20

i still feel like a baby when it comes to ai. cause i thought i had worked out fabrication and lying. bro, it's telling my scrapling and flaresolverr are the same thing in different ports.
I'm like bullshit. scrapling is a skill!
1
6
var d = "M20.396 11c-.018-.646-.215-1.275-.57-1.81 retweeted

May 22
El web scraping acaba de cambiar de nivel
Scrapling evita los bloqueos de Cloudflare, es 774 veces más rápido que BeautifulSoup y no necesita configuración de proxies
52.2k estrellas en GitHub
No es otro scraper más
Es un framework adaptativo que aprende la estructura de cada web y se ajusta automáticamente cuando cambia
Sin mantenimiento manual. Sin que te bloqueen.
✅ Bypassa Cloudflare y los anti-bots más agresivos
✅ 774x más rápido que BeautifulSoup en benchmarks reales
✅ Sin necesidad de proxies ni configuración especial
✅ Se adapta automáticamente cuando cambia la estructura de la web
✅ Compatible con agentes de IA como servidor MCP
✅ Soporte para JavaScript, iframes y contenido dinámico
✅ Modo stealth para webs con detección avanzada
✅ 46 releases. Actualizado la semana pasada.
✅ Licencia BSD-3
Lo que antes tardabas días en montar y mantener ahora son minutos
52.2k estrellas. 5k forks. BSD-3.
repo aquí 👇
23
257
1,865
119,069


Who has used this with their Hermes or Openclaw Agents? How does it compare to scrapling or brave api etc. What specific use cases has it excelled at. Deciding if I should add it into the tool stack.
Jun 16

Starting today, you can try Firecrawl for free without an API key 🔥
Search, scrape, and interact with any web page, plus parse any PDF into clean markdown, with no setup at all!
Start using our endpoints and only sign up when you scale.
Live on our MCP, CLI, and API now!
3
254

Jun 17
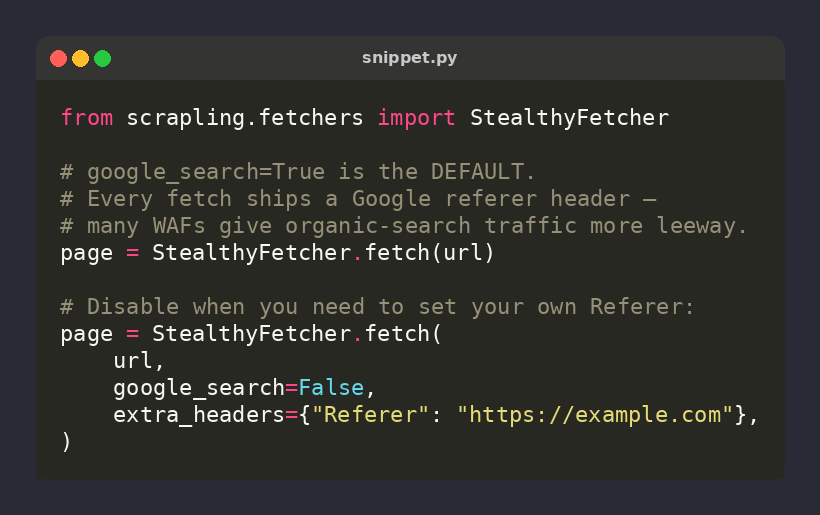
🕷️ Scrapling tip: google_search=True is the DEFAULT on StealthyFetcher/DynamicFetcher — every fetch ships with a Google referer header
Mimics organic search traffic many WAFs give more leeway to
Set google_search=False to drop it (or set your own Referer) ⚡
49
The DC Strategist retweeted

Jun 3
Someone just built a web scraper that survives when websites change.
It’s called Scrapling. 47K stars on GitHub.
An adaptive Python scraping framework that handles everything from one request to full-scale crawls.
The crazy part:
Its parser learns from website changes and automatically finds your elements again when the page updates.
That means fewer broken selectors.
Fewer dead scraping scripts.
Fewer “why did this stop working?” mornings.
What it gives you:
- Adaptive parsing
- Auto element relocation
- Cloudflare Turnstile bypass
- Browser-like fetchers
- Concurrent crawls
- Multi-session crawling
- Pause and resume
- Automatic proxy rotation
- CLI support
- MCP mode
Most scrapers are fragile.
You write selectors.
The website changes a class name.
Your pipeline dies.
Then you spend half the day fixing something that should have kept working.
Scrapling is built for the modern web.
Pages change.
Anti-bot systems evolve.
Crawls get bigger.
Agents need live data.
So instead of stitching together Requests, BeautifulSoup, Playwright, proxy tools, retry logic, and anti-bot patches...
Scrapling puts the whole scraping workflow into one Python library.
This is not just a scraper.
It’s a survival kit for web data.
GitHub: github.com/D4Vinci/Scrapling

4
5
18
1,129

Jun 16
Claude Codeに「Scrapling」という専用の武器をもたせる連携ガイドです。導入は話しかけるだけで一瞬で終わります。
AI活用の次元を一段上げたい方はこちらからどうぞ。
x.com/ceo_comix/status/20345…"

1
301

Jun 16
ive testing the project for quite sometimes - difficult to use this in commercial sense, the scraping logic is somewhat brittle and relies on standard methods. website with heavy security do not work with Scrapling
8
Jun 16
🕷️ Scrapling tip: http3=True flips Fetcher to HTTP/3 (QUIC over UDP)
page = Fetcher.get(url, http3=True)
Most scrapers still send HTTP/1.1 — going HTTP/3 blends in with modern browser traffic. Gotcha: may conflict with impersonate= ⚡

1
50

We tested Puppeteer, Firecrawl, Scrapling, and a few fetch variants.
Scrapling looked best on memory usage, so we picked it for the first run.
Then the real problems showed up.
4
Jun 15
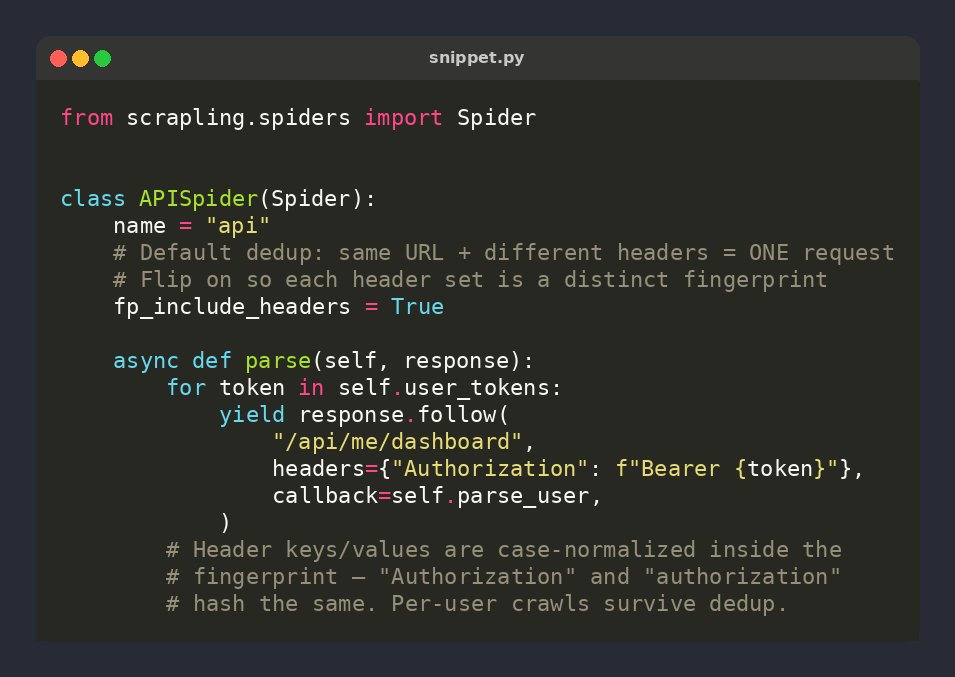
🕷️ Scrapling tip: spider dedup ignores headers by default — same URL with different Authorization / X-API-Key tokens silently collapses to one
class MySpider(Spider):
fp_include_headers = True
Header keys are case-normalized in the fingerprint ⚡
2
74
Weekend benchmark: scraping layer.
~17k domains. 2 to 5 min per scrape.
Tested Puppeteer, Firecrawl, Scrapling.
Judged on cost, CPU/RAM, failure rate.
Picked Scrapling first. Memory usage was the deciding factor.
Next: mass concurrency.
If you scale this, what breaks first?
1
51


Jun 14
D4Vinci/Scrapling、READMEの説明が丁寧で初見でも流れを追いやすい。 ★56.1k Python製
背景は 🕷️ An adaptive Web Scraping framework that handles everything from a single request to a…。READMEまで追うと、試す優先順位がはっきりする。
READMEでは「Based on the provided repository information, I have su…」が先に整理されていて、狙いを掴みやすい。
次の要点「🔋 What it solves: Scrapling is an effortless web sc…」まで触れているので、実装の迷いが減る。
さらに「🔧 How to get started: The project provides a Docker…」まで読むと、運用時の勘所も見えてくる。
★56.1k #Python #GitHub #OSS
注目キーワード: scrapling / Docker / Ready / automatically
github.com/d4vinci/scrapling
1
1
36

Jun 14
④ メルカリ/株価/通販を24h 自動監視(scrapling)
条件達成したら自動で通知。
普段:「メルカリで欲しい商品が ¥5,000 以下で出たら欲しい」→ 1日3回 サイト見に行く
Hermes だと:
・メルカリ/ヤフオク 価格監視(指定額以下で LINE通知)
・株価・仮想通貨価格を毎時間 Google Sheet 記録
・Amazon/楽天/Apple 新商品アラート
install:
hermes skills install github:amanning3390/hermeshub/skills/scrapling
1
177

Jun 14
Scrapling is an adaptive web scraping framework that handles everything from a single request to a full-scale crawl.
1
25

Jun 13
🚨CloakBrowser ve CAPTCHA Güvenliği Tamamen Açık Kaynak ve Deşifre Oldu! Web Otomasyonu ve Kazıma İçin Yeni Standart Geliyor🔐🤖
Bu haberde web scraping, otomasyon ve headless browser kullanan herkesin dikkatine diyoruz...
CloakBrowser ekibi, güçlü stealth tarayıcılarını ve entegre CAPTCHA çözücüsünü açık kaynak haline getirdi!
1 - CloakBrowser Nedir?
CloakBrowser, Chromium’un kaynak kodunu (C seviyesinde) 58 patch ile modifiye edilmiş özel bir stealth tarayıcı. JS injection veya basit fingerprint spoofing yöntemlerine dayanmıyor. Tarayıcı baştan sona “gerçek bir kullanıcı Chrome’u” gibi davranıyor.
2 - Ana Özellikler:
✅reCAPTCHA v3 puanı: 0.9 (insan seviyesinde, server-side doğrulanmış)
✅Cloudflare Turnstile’ı otomatik geçiyor (managed non-interactive)
✅FingerprintJS, BrowserScan, ShieldSquare, bot.incolumitas.com gibi 30 tespit sitesini başarıyla geçiyor
✅Playwright ile drop-in replacement — sadece import’u değiştiriyorsun, kodunun geri kalanı aynı kalıyor
✅Humanize modu: Gerçekçi mouse hareketleri (Bézier eğrileri), yazma hızı, scroll pattern’leri
✅Proxy GeoIP desteği (proxy IP’sine göre timezone/locale otomatik ayarlanıyor)
✅Persistent profil desteği (cookies, localStorage, extension’lar korunuyor)
✅Docker ve CDP server desteği (cloakserve ile birden fazla parmak izi yönetebiliyorsun)
✅Widevine/DRM desteği (Linux’ta)
3 - Nasıl Çalışıyor?
Chromium 146 (ve bazı platformlarda 145) kaynağına doğrudan patch’ler uygulanmış. Canvas, WebGL, audio, font, GPU, WebRTC, CDP sinyalleri, navigator.webdriver, TLS fingerprint (JA3/JA4) gibi her şey kaynak seviyesinde değiştiriliyor. Bu sayede tespit araçları “gerçek tarayıcı” görüyor.
4 - CAPTCHA Çözücüsü (Entegrasyon Katmanı)
CloakBrowser fallback sistemi:
Katman 1 (Ücretsiz): CloakBrowser ile CAPTCHA’ların � ’ını tamamen engelliyor
Katman 2: Cloudflare Turnstile için ücretsiz otomatik tıklama
Katman 3: Kalan için 2Captcha ve CapSolver entegrasyonu (30 CAPTCHA türü destekliyor: reCAPTCHA v2/v3/Enterprise, hCaptcha, FunCaptcha, GeeTest, KeyCaptcha, Amazon WAF, DataDome, Akamai, Imperva vb.)
Bu yapı sayesinde hem maliyet düşük kalıyor hem de başarı oranı çok yüksek.
5 - Benchmark ve Test Sonuçları
✅reCAPTCHA v3:
Stock Playwright → 0.1 | CloakBrowser → 0.9
✅Cloudflare Turnstile:
Stock → FAIL | Cloak → PASS
14 ana tespit testinin tamamını geçiyor
Gerçek sitelerde (Google, LinkedIn, Discord vb.) başarılı CAPTCHA bypass’ları rapor edilmiş
6 - Kurulum ve Kullanım (Çok Basit)
Python ile Playwright:
pip install cloakbrowser
python
from cloakbrowser import launch
browser = launch(headless=False, humanize=True, proxy="http://user:pass@ip:port", geoip=True)
page = browser.new_page()
page.goto("protected-site.com")
# ... işlemler
JavaScript/Node.js ve Docker desteği de var. Mevcut Playwright projelerini tek satırda CloakBrowser’a taşıyabiliyorsun.
7 - Neden Bu Kadar Önemli?
Piyasadaki çoğu stealth tarayıcı (Undetected-Chromedriver, puppeteer-extra vs.) JS seviyesinde çalışıyor ve Chromium güncellemeleriyle kolayca tespit edilebiliyor. CloakBrowser ise kaynak kod seviyesinde düzeltme yaptığı için çok daha dayanıklı.
8 - Açık kaynak olmasıyla:
✅Ücretsiz kullanabiliyorsun
✅Kendi patch’lerini ekleyebiliyorsun
✅Topluluk katkısıyla sürekli gelişiyor
✅Ticari çözümlerin (ayda yüzlerce dolar) çok daha ✅uygun fiyatlı alternatifi
Repo’lar aktif geliştiriliyor, örnekler bol (LangChain, Crawl4AI, Scrapling entegrasyonları dahil). Binary’ler SHA-256 doğrulamalı ve Sigstore ile imzalanmış. Linux, macOS (Apple Silicon dahil) ve Windows destekleniyor.
Web kazıma, otomasyon, veri toplama, test otomasyonu veya AI agent’lar için tarayıcı kullanan herkes için gerçek bir game-changer. Özellikle yüksek hacimli ve tespit riski yüksek projelerde fark yaratıyor.
Sizce bu tür açık kaynak stealth araçlar, web scraping dünyasını nasıl değiştirecek? CloakBrowser’ı denediniz mi? Hangi CAPTCHA türleriyle karşılaşıyorsunuz ve başarı oranınız nasıl? Yorumlarda deneyimlerinizi paylaşın, birlikte tartışalım! 🔐🤖

1
2
10
2,202
Jun 12
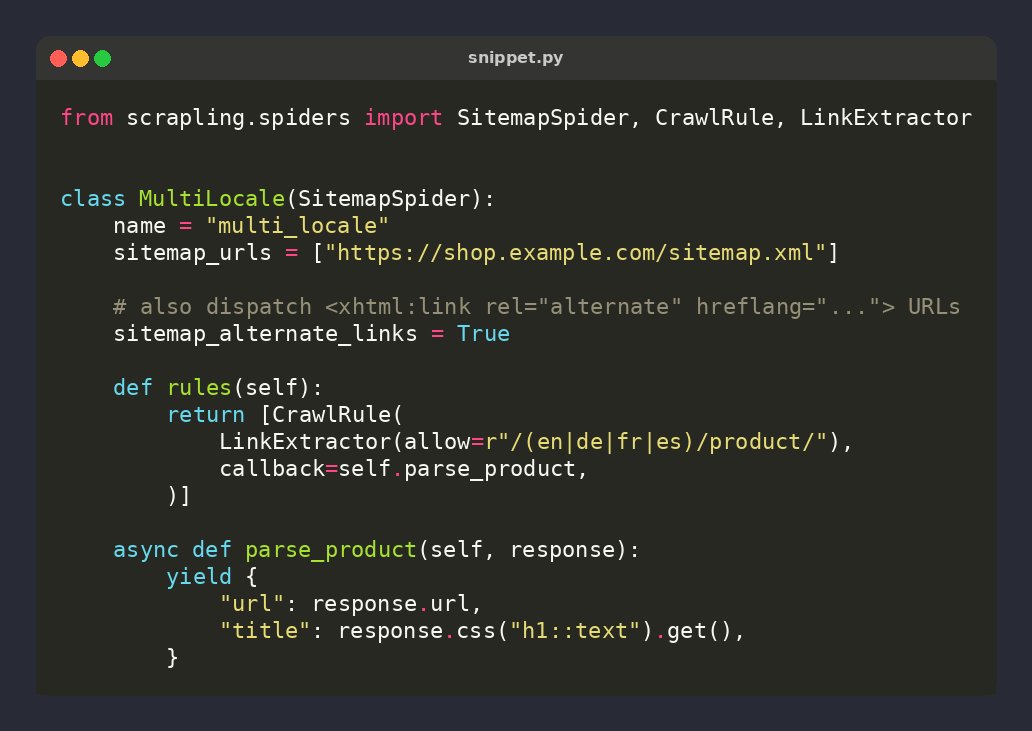
🕷️ Scrapling tip: SitemapSpider IGNORES hreflang URLs by default
Flip sitemap_alternate_links=True to also dispatch every <xhtml:link rel="alternate"> URL through your rules — crawl every locale of a multilingual site in one go ⚡
3
1
85