
Jun 14
Je viens d’acquérir le livre de Alya Hamza: Ateliers d’artistes, imprimé chez SIMPACT, dans format géant , un beau livre d’art.
Le livre est à conseiller aux amoureux des arts plastiques



45
John retweeted

Painful SIMPact punishment is now for sale on my platforms!
I beat him so hard my nipples fell out of my top oops 😜🪭 A very red ass is what he gets for trying to act strong around me!
2
17
141
5,290

Jun 11
SIMPACT
VLMs have common-sense and semantic reasoning capabilities.
But, they suck at predicting physical consequences.
We equip VLMs with physical reasoning through simulation-in-the-loop world modeling!
simpact-bot.github.io/

1
11
1,108


Counter Shooting 2, Call of Duck, Smart Game 2, Cubes in the mine and SIMPACT IMSHIN.
Offbrand names LOL
1
51

Jun 7
SIMPACT treats simulation as a reasoning primitive.
Instead of asking a VLM to imagine contact dynamics, it lets it:
• propose actions
• run physics rollouts
• observe consequences
• refine plans iteratively

1
1
4
363
Jun 7
Most VLM-based robots can tell you what is happening but struggle with what will happen next.
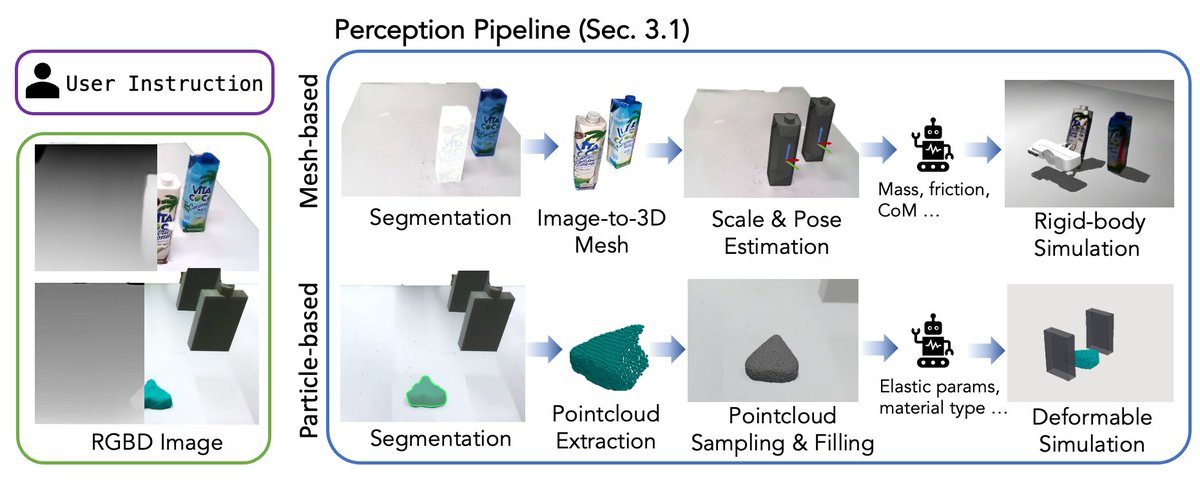
SIMPACT gives VLMs a physics engine at test time: build a simulation from a single RGB-D observation, roll out candidate actions, then reason over the outcomes before acting.
1
6
23
1,710

Jun 6
What happens if you give your everyday ChatGPT:
a camera, a robot arm, and a simulation where it can go nuts?
Not exactly ChatGPT, but SIMPACT asks a very similar robotics question.
The current bet is VLAs: models that turn images and instructions directly into robot actions.
They look strong, until the task needs physical judgment.
Push this carton forward, but don’t topple it. Shape this rope into a U.
These are not language problems. They are data or contact problems.
SIMPACT takes an off-the-shelf VLM and gives it test-time physical reasoning.
From one RGB-D image, it builds a rough physics simulator.
Then it samples action plans, rolls them out, and lets the VLM revise before the real robot moves.
There is no training at all!
If the carton falls in sim, the model can reason:
push lower, change contact point, try again.
That is the interesting shift.
Not bigger data, nor another policy trained on more demos.
Inference compute spent on physical rehearsal.
Real robot intelligence may need test-time compute, not just bigger models.
Which, in some way, this paper proves.
On 7 fine-grained manipulation tasks, SIMPACT reports 40-90% zero-shot success.
π0.5, one of those VLAs everyone has been obsessing over lately, gets 0% on all of them.
The limits are obvious: single-view 3D reconstruction is fragile, sim-to-real is never free, and the planning loop is slow.
Robots may need less “answer instantly” and more “simulate before you touch the world.”
Congrats on the paper @ShaoxiongYao, @HaonanChen_, @WinstonGu_ and the rest of the team.

Excited to share our CVPR work: SIMPACT: Simulation-Enabled Action Planning using Vision-Language Models, 11:45 PM – 1:45 PM at ExHall F 611
simpact-bot.github.io/
How can we make VLMs plan robotic manipulation actions with grounded physical reasoning?
4
11
969

How can we effectively use VLMs for robotics manipulation?
Excited to share SIMPACT, which uses simulation as a tool to enable VLMs to reason and plan continuous robotics actions.
Excited to share our CVPR work: SIMPACT: Simulation-Enabled Action Planning using Vision-Language Models, 11:45 PM – 1:45 PM at ExHall F 611
simpact-bot.github.io/
How can we make VLMs plan robotic manipulation actions with grounded physical reasoning?
2
9
93
12,193

Jun 6
SIMPACT turns physics simulation into a test-time reasoning tool for VLMs, enabling zero-shot robotic manipulation through physically grounded action planning!
Excited to share our CVPR work: SIMPACT: Simulation-Enabled Action Planning using Vision-Language Models, 11:45 PM – 1:45 PM at ExHall F 611
simpact-bot.github.io/
How can we make VLMs plan robotic manipulation actions with grounded physical reasoning?
1
6
712

Excited to share our CVPR work: SIMPACT: Simulation-Enabled Action Planning using Vision-Language Models, 11:45 PM – 1:45 PM at ExHall F 611
simpact-bot.github.io/
How can we make VLMs plan robotic manipulation actions with grounded physical reasoning?
5
11
47
16,527
Jun 6
VLMs are great for their semantic reasoning capabilities.
BUT, they don't have a grounded understanding of physical dynamics.
So, we equip VLMs with physical reasoning through
simulation-in-the-loop world modeling.
Come talk with Haowen about SIMPACT (#611): simpact-bot.github.io/
1
2
15
2,656


May 30
Welcome to Simpact Spank$ 💰📝



2
2
179

May 29
HAPPY PREMIERE WEEK-END! @theeflixxx @SummerSexxy 98SparkzProductions always gonna support the Simpact Nation!
1
3
6
363
May 29
Can my baby daddies not be into it on Simpact Premiere Day 😭 DADDIES CHILL
1
2
4
134

KCU’s SIMPACT program has earned full human simulation accreditation from the Association of SP Educators, recognizing excellence in simulated patient-based medical education.
Read the full article: bit.ly/4umxlal
2
116