
And this is my exact problem with NDC and their useless waste of money with these influencers like KalyJay and stvpid Bongo Ideas … look at this fool here bragging that he’s trending #StopRed as if junkies have time to come and Twitter and be like oh ok I will stop drugs.. Kwasia there are rehab centers like Chosen Rehab that you could partner with and push against the opioid crises but instead let’s trend with KalyJay … fools … NDC ankasa I think they are allergic to success..
15
14
76
10,146



Mar 10
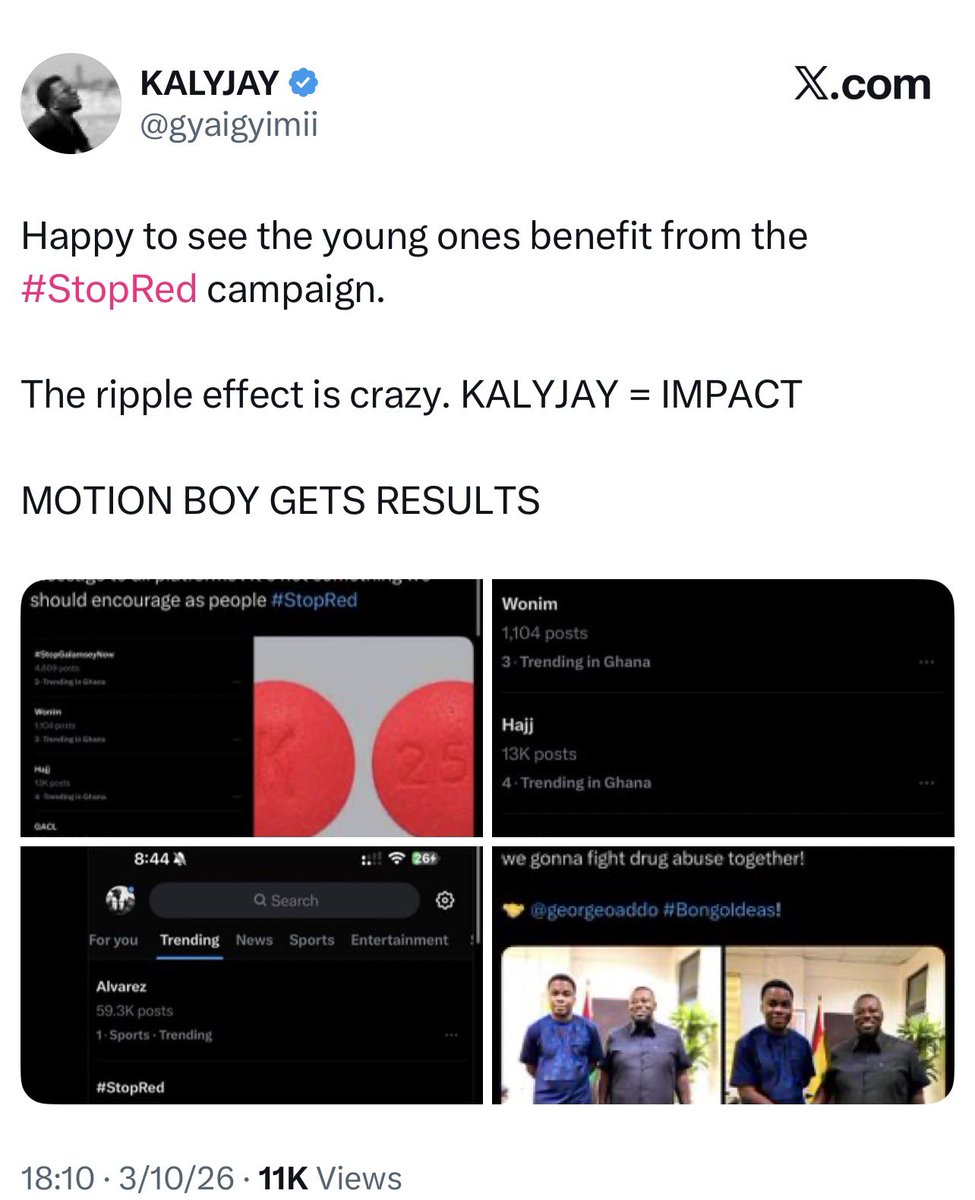
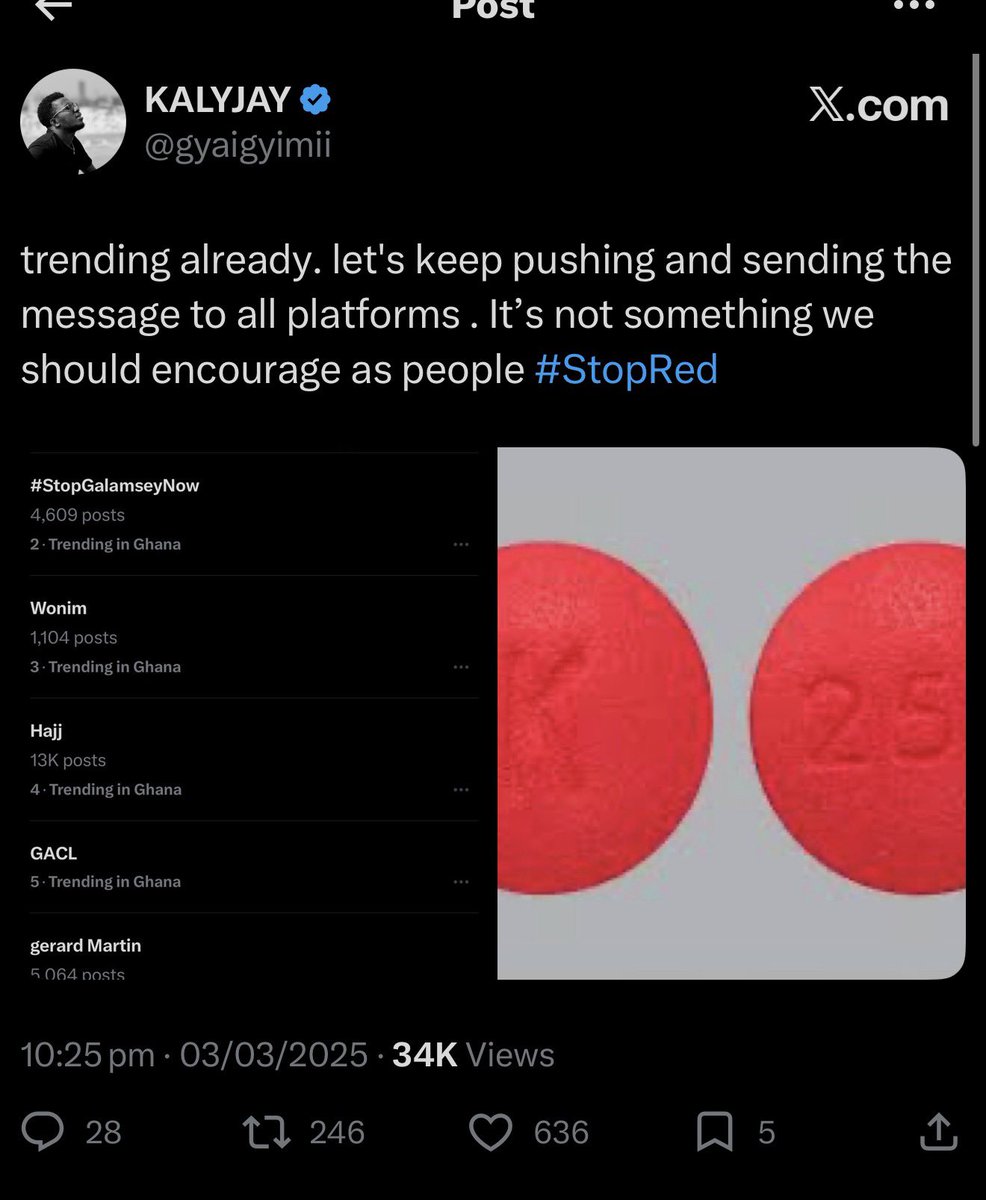
Happy to see the young ones benefit from the #StopRed campaign.
The ripple effect is crazy. KALYJAY = IMPACT
MOTION BOY GETS RESULTS
22
75
408
14,650

Jan 20
The rate at which people are being drawn into the red has risen sharply, and the impact it’s having on them is truly alarming.#StopRed
2
59

Jan 12
#StopRed now!
Jan 11

"Some women tell me they are buying kenkey for GHS 10, bottled water that was GHS 28 is now GHS 36, sachet water was GHS 8, now GHS 10.” — Dennis Miracles Aboagye
#JoyNewsFocus ||
7
18
115
6,017

24 Oct 2025
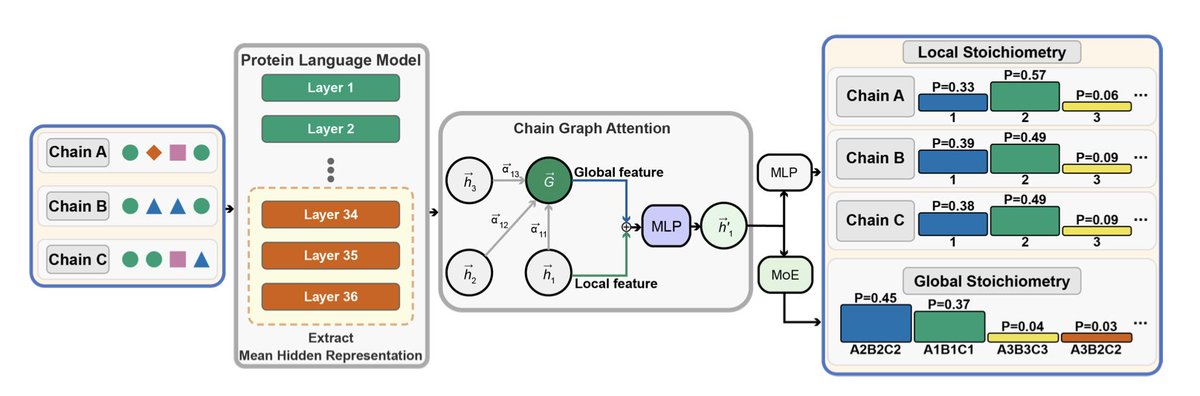
StoPred: Accurate Stoichiometry Prediction for Protein Complexes Using Protein Language Models and Graph Attention
1. A new method called StoPred has been introduced for predicting the stoichiometry of protein complexes. This method integrates protein language models (pLM) with graph attention networks (GAT) to model subunit-level interactions, offering a novel approach to predict both homo- and hetero-oligomer stoichiometry directly from sequence or structure features without requiring template assemblies or predefined composition.
2. StoPred outperforms existing methods in terms of accuracy and efficiency. It achieves up to 16% higher top-1 accuracy for homomeric complexes and 41% higher for heteromeric complexes compared to the strongest prior method on the held-out test dataset. This demonstrates its significant improvement over traditional template-based and deep learning-based approaches.
3. The method leverages protein language models to capture structural and functional features embedded within amino acid sequences. By using a graph attention network, StoPred can model dependencies between different subunits in a protein complex, which is crucial for predicting the stoichiometry of hetero-oligomeric complexes.
4. StoPred was benchmarked against various methods, including deep learning-based and template-based approaches, on curated and blind datasets. It consistently showed superior performance, especially in predicting the stoichiometry of heteromeric complexes, which are more biologically complex and important but often challenging to predict.
5. The study also includes case studies that highlight the advantages of StoPred over AlphaFold3 score-based selection. For example, StoPred correctly identifies the stoichiometry of certain protein complexes, whereas AlphaFold3 may assign higher ranking scores to incorrect models due to its focus on structural accuracy rather than stoichiometry correctness.
6. StoPred is designed to be computationally efficient, making it a practical tool for predicting the stoichiometry of protein complexes with unknown or uncertain composition. It can guide the setup of high-resolution modeling and support downstream structural and functional analysis.
7. Future work includes improving structure-based embeddings to capture more features and developing multi-modal models that integrate template information, sequence, and structural features in a unified framework. The authors also plan to extend the method to protein–nucleotide complexes.
📜Paper: biorxiv.org/content/10.1101/…
#ProteinComplexes #StoichiometryPrediction #ProteinLanguageModels #GraphAttentionNetworks #ComputationalBiology
1
9
998

14 Aug 2025
14 Aug 2025

Life-saving choices behind the wheel:
🔴 Stop on red
📵 Stay distraction-free
🚦 Slow down, buckle up
🚗 Don’t tailgate
😮💨 Avoid road rage
👀 Watch children in school zones
Drive like your life & the lives of others depends on it, cuz it does.
#roadsafety #visionzero

2
28

31 Jul 2025
Our Minister of Youth Development and Empowerment, Pablo joins the National voices tackling Ghana’s growing opioid crisis. This reinforces his clear commitment to protecting young Ghanaians from the dangers of drug abuse. #YouthPower #StopRed

1
18
29
620

23 Jul 2025
Unfortunately, we need to refuel the #StopRed campaign once again. Let’s hit the streets and ghettos🤔
26
32
190
10,083




6 Jul 2025
2
7
26
2,317
6 Jul 2025
1
3
24
198

30 Jun 2025
“The future of Ghana depends on the strength of our youth, and we cannot afford to lose them to drugs,” - Bridget Bonnie
#OnGod #MomentumWalk #StopRed #Focus

8
83
866
17,873




12 Jun 2025
🔴RED MEANS ST🚫P
Opioids can also lead to seizures; mood disorders and depression. An overdose can kill.
✍️—Vickie Bright Writes
#opioidaddiction #opioidcrisis #WonimRed #redmeansstop #drugaddiction #stopred #addictionghana #addictionawareness

2
118
12 Jun 2025
🔴RED MEANS ST🚫P
As I have mentioned here previously, the surge of opioid abuse among Ghana’s youth is deeply disturbing. The emergence of the ‘Red’ drug – which is a high-strength painkiller – has become a particularly troubling trend.
✍️—Vickie Bright Writes
#opioidaddiction #opioidcrisis #StopRed #WonimRed #redmeansstop #drugaddiction #addictionghana #addictionawareness


2
62