
16 Nov 2025
📜Well done Akio!!! for your paper at INLG 2025 on Towards Trustworthy Lexical Simplification: Exploring Safety and Efficiency with Small LLMs Akio Hayakawa, Stefan Bott, @h_saggion
aclanthology.org/2025.inlg-m…… #LLMs #TextSimplification #INLG2025 @idem_EU
2
144

8 Jul 2025
📢 Call for Participation: TSAR 2025 Shared Task 📢
Simplify English paragraphs to a specified CEFR level
🔹 No training data
🔹 Eval: CEFR match, meaning preservation, ref similarity
🗓️ Starts July 16
🔗 Info registration: tsar-workshop.github.io/shar…
#EMNLP2025 #TextSimplification
6
10
3,217

7 Jun 2025
Streamlined Knowledge: AI Summarizer Tool
zurl.co/v6clB
#AI #Summarizer #TextSimplification #Information #Efficiency #Technology #ArtificialIntelligence #Content #Productivity #TextProcess

2
26
8 Apr 2025
Streamlined Knowledge: AI Summarizer Tool
zurl.co/4xKDq
#AI #Summarizer #TextSimplification #Information #Efficiency #Technology #ArtificialIntelligence #Content #Productivity #TextProcessing

1
2
16

24 Jan 2025
#Daily_Share
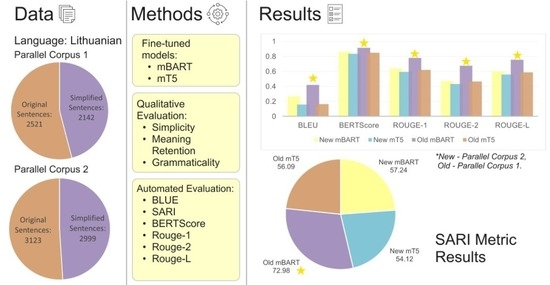
Welcome to read and share the newly published paper "Automatic Simplification of Lithuanian Administrative Texts".
Read via: mdpi.com/1999-4893/17/11/533
#textsimplification #Lithuanian #transformers #finetuning #mT5 #mBART #ChatGPT
3
60
9 Dec 2023
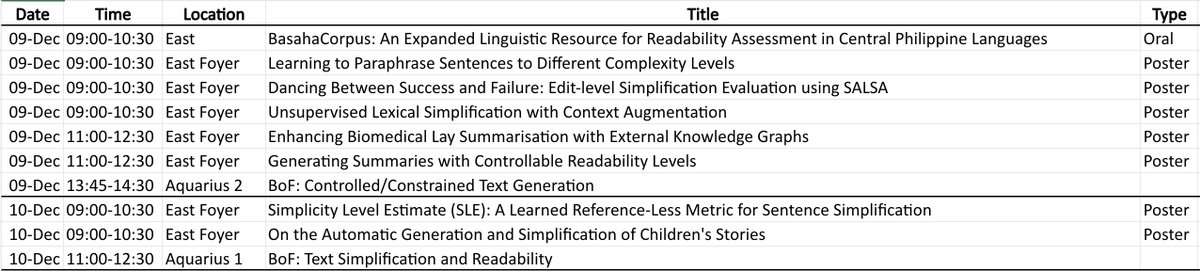
Schedule updated with a couple more presentations today (great to see so many!) #EMNLP2023 #textsimplification #readability #NLProc
7 Dec 2023

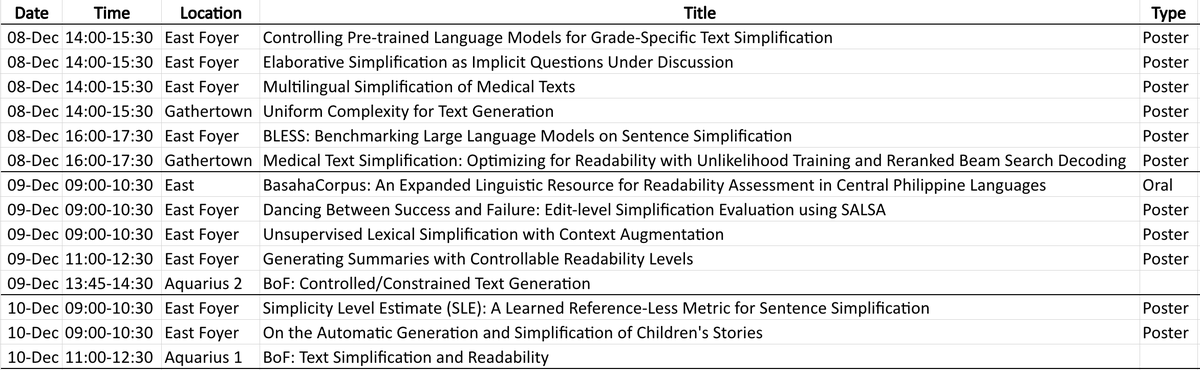
Are you attending #EMNLP2023 and interested in text simplification and readability?
Here are the papers on these topics that are being presented at the main conference so you don't miss them! (and a couple of relevant BoF sessions, too!)
2
430

15 Nov 2023
Let us be clear: #Lamarr scientist and author Vanessa Toborek (@InformatikBonn / @UniBonn) explains in our latest #blog post why #TextSimplification is important and what #ML can do to help. 💬
➡️ Read now: lamarr-institute.org/blog/te…

1
8
254
10 Jul 2023
Always great to see papers on #textsimplification at *ACL conferences! I’ll add the ones at #acl2023nlp as I see them (if I forget any, let me know!) 🧵
3
5
25
3,452

26 May 2023
📖For our weekly @MilaNLProc lab seminar, it was a pleasure to have @lmvasquezr for a talk about Text Simplification
#NLProc #TextSimplification

2
8
993

7 Dec 2022
Tomorrow, Iker Gutierrez-Fandiño will present our paper "IrekiaLF_es: a New Open Benchmark and Baseline Systems for Spanish Automatic #TextSimplification" at the TSAR-2022 Workshop (#emnlp2022) together \w @OscarCumbicus and @Aitor57.

1
3
9

28 Sep 2022
Our paper "SimpLex: a lexical text simplification architecture" has been accepted for publication in Neural Computing and Applications (WOS Q2)!
Congratulations 🎊and thank you 🙏to
📌Andrei-Ionuț Stan
📌@SElenaApostol (@upb1818/@UU_University)
#TextSimplification #NLG #NLP

1
3
20 Jun 2022
"Simple TICO-19: A Dataset for Joint Translation and Simplification of COVID-19 Texts" (with @MattShardlow) #textsimplification
Paper: lrec-conf.org/proceedings/lr…
Data: github.com/MMU-TDMLab/Simple…
(2/3)
1
5
12 Oct 2021
This looks pretty interesting! #TextSimplification #NLProc
12 Oct 2021

Are you doing research on text simplification? If yes, then join us in this ICT with Industry workshop at the Lorentz Center Leiden from 17-21 January 2022. @NWO_Science @ictwithindustry @lorentzcenter @KB_Nederland @KBNLresearch @marijnkoolen @yangjiera @MartijnKleppe
3
21 Sep 2021
At #CTTS2021, w/ @OscarCumbicus and @Aitor57, we propose a set of linguistic capabilities for a checklist based evaluation of #textsimplification systems
ceur-ws.org/Vol-2944/paper5.…
2
3


22 Apr 2021
Highly informative presentation by Alessandra Rossetti to our students. She shared her research on the impact of #TextSimplification on #MachineTranslation quality and some inputs on new research avenues, such as document-level MT evaluation🔍
Thanks @ale_rossetti89!
@FTI_UNIGE

ALT Slide: the impact of text simplification on machine translation quality
2
5

22 Dec 2020
I'm searching for #participants to rate the #complexity of some texts in my #survey related to #PlainLanguage, #TextSimplification and #EinfacheSprache. #LanguageLearners are very welcome! The #study will take approximately 15min.
ww3.unipark.de/uc/Text_compl…
Thanks a lot!
1
2

8 Jul 2020
#acl2020nlp #acl2020en #NLProc #textsimplification
Dhruv Kumar, Lili Mou, Lukasz Golab, Olga Vechtomova: Iterative Edit-Based Unsupervised Sentence Simplification
Session 14A/15A Jul 8
Paper : aclweb.org/anthology/2020.ac…
Code: github.com/ddhruvkr/Edit-Uns…
1
2
8

#textsimplification is often looked @ from an either syntactic or a lexical pov. The paper on ASSET: Dataset for Assessing Sentence Simplification in English explains the robustness of the dataset that was created keeping these points in mind. #acl2020nlp
1
1
4
7 Jul 2020
#acl2020nlp #acl2020en #textsimplification #NLProc
Fernando Alva-Manchego, Louis Martin, Antoine Bordes, Carolina Scarton, Benoît Sagot, Lucia Specia
ASSET: A Dataset for Tuning and Evaluation of Sentence Simplification Models with Multiple Rewriting Transformations
2
1
10