
No camera. No Photoshop. Just a text prompt.
egaku-ai.com — 40 AI tools, free to start.
#AIart #AIgenerated #TextToImage
Model: Flux Pro

24

Jun 16
Edimakor Father's Day Offer 2026: Free Credits, 65% Savings, and Unlimited AI Creation i.send2press.com/RCz5T @send2press @HitpawEdimakor #AItools #fathersdaydeals #aisoftware #videoAI #texttoimage
25

Got an idea? Turn it into a stunning AI image in seconds ✨
Create visuals for marketing, social posts, design projects, and storyiesust by typing what you imagined!
Click here to start 🔗 bit.ly/4uN8En6
#ImageGenerator #TextToImage #ContentCreation #Wondershare #Mediaio

36

Krea 2 API is now live on Pixazo. 🚀
🎨 Advanced text-to-image generation with next-level creative control.
🖼️ Use reference images for consistency
✨ Apply LoRA style presets instantly
🎯 Guide outputs with moodboard conditioning
Create better visuals with fewer iterations.
API: pixazo.ai/models/krea
#PixazoAPI #Krea #AIImages #TextToImage #GenerativeAI #Developers
3
2
7
377

Jun 15
We've teamed up with @vm0_ai 🤝Atlas Cloud is now a built-in connector in VM0. Generate video, images and text from 300 models just by asking Zero in plain English. One API key. No JSON wrangling. No babysitting render queues. How it works 🧵👇
#AtlasCloud #vm0 #API #AIVideo #AIimage #TextToVideo #TextToImage #ImageToVideo #VideoGeneration #AIart

1
2
274

Jun 12
#NLProc
Introducing ImageEval 2026 - a new shared task on Cultural Grounding in Arabic Multimodal AI, organized with #ArabicNLP2026 and co-located with #EMNLP2026.
The task evaluates how well multimodal AI systems understand and generate culturally grounded Arabic visual content from the MENA region.
Tracks:
🔹 Arabic Visual QA & Hallucination Detection
🔹 Cultural Accuracy Evaluation for Text-to-Image Generation
Registration: shorturl.at/utvGK
📅 Registration deadline: July 20, 2026
📅 System papers due: August 15, 2026
🌐 imageeval2026.github.io/
📂 github.com/ImageEval2026/Ima…
Open to researchers in Arabic NLP, multimodal AI, computer vision, generative AI, and cultural computing.
Please feel free to share!
W/
@sabdaljalil_ @AhlamBashiti Farina Amir @shammur_absar @NadirDurrani5 @dalvifahim @baselmousi995 Hunzalah Hassan Bhattihtt @Zein_5 Erchin Serpedin Hasan Kurban Mustafa Jarrar
#ImageEval2026 #ArabicNLP #MultimodalAI #VQA #TextToImage @emnlpmeeting @_ArabicNLP

3
2
122


Jun 12
2/ 🖼️ Stable Diffusion WebUI — Generate stunning AI art for FREE on your own machine.
Midjourney? Why pay when this exists.
⭐ 140k stars · github.com/AUTOMATIC1111/sta…
#StableDiffusion #AIArt #TextToImage #GenerativeAI #FreeAI
1
22

Jun 11
🎨 TEXT-TO-IMAGE MODELS
Which image model are you using most today?
⚫ GPT Image 2
🟡 Ideogram 4.0
🟢 Flux 2 Max
🔵 Recraft V4
Each excels in different areas:
📸 Photorealism
📝 Typography
🎨 Design
⚙️ Control
What's working best for your projects?
👇
#AI #TextToImage #GenerativeAI #AIArt #Design

1
5
12
473

Jun 11
AI Art Challenge - Crochet 🧶 Art 🎨
Feel free to join this Artwork Challenge
#AI #AIArt #Gemini #NewArt #AIChallenge #AIPhoto
#TextToImage #AIArt #AIImageGeneration #CreativeAI #AIArtworks #TextToArt #AIIllustration #AICreativity #AIArtists




2
18
696
Jun 11
AI Art Challenge - New Theme: Dream Home 🏡
Made by @FlowbyGoogle
Welcome to all Join 🔥😎
#AI #AIArt #House #DreamHome #Home #TextToImage #AIArt #AIImageGeneration #CreativeAI #AIArtworks #TextToArt #AIIllustration #AICreativity #AIArtists
1
7
150
Jun 11
AI Art Challenge - Hat 🎩👒🧢
Made by Nano Banana 🍌
#TextToImage #AIArt #AIImageGeneration #CreativeAI #AIArtworks #TextToArt #AIIllustration #AICreativity #AIArtists




3
12
142

Fooocus is an AI image generator for creators and designers, offering advanced inpainting, multi‑prompt support, style controls and InsightFace‑based face swapping to turn prompts into high‑quality visuals instantly.
fooocus.one/
#TexttoImage #PhotoImageEditor
18
Fooocus AI Online – Free Text-to-Image AI Generator
aistage.net/tool/fooocus-one
#TexttoImage #PhotoImageEditor #AIPhotoImageGenerator
1
22

Jun 8
𝗘𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝘄𝗮𝗻𝘁𝘀 𝟰𝗞 𝗔𝗜. But true native-4K data is still surprisingly scarce.
🚀 Excited to share our new work: 𝟰𝗞𝗟𝗦𝗗𝗕: 𝗔 𝗟𝗮𝗿𝗴𝗲-𝗦𝗰𝗮𝗹𝗲 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗳𝗼𝗿 𝟰𝗞 𝗜𝗺𝗮𝗴𝗲 𝗥𝗲𝘀𝘁𝗼𝗿𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻, accepted to CVPR 2026 DataCV.
Most public datasets are built around sub-1K, HD, or 2K images. But at 4K resolution, small artifacts become big problems: blurry textures, distorted boundaries, repeated patterns, and missing fine details.
To address this gap, we introduce 𝟰𝗞𝗟𝗦𝗗𝗕, a large-scale native-4K dataset and benchmark for high-resolution restoration and generation.
📌 𝟰𝗞𝗟𝗦𝗗𝗕 𝗶𝗻𝗰𝗹𝘂𝗱𝗲𝘀:
✅ 129K native-4K training images
✅ 2K validation images and 1,984 test images
✅ Diverse categories: nature, urban scenes, people, food, artwork, CGI, and more
✅ Aligned 4K image–text pairs for generative modeling
✅ Paired LR/HR evaluation sets for super-resolution
We also build a multi-stage curation pipeline combining resolution filtering, LMM-based quality scoring, texture-richness filtering, and human verification.
Across classical SR, real-world blind SR, and 4K text-to-image generation, fine-tuning on 4KLSDB consistently improves fidelity, local detail, perceptual quality, and human preference.
💡 Main takeaway: 𝗻𝗮𝘁𝗶𝘃𝗲-𝟰𝗞 𝘀𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗶𝗼𝗻 𝗺𝗮𝘁𝘁𝗲𝗿𝘀.
As visual AI moves toward ultra-high-resolution restoration and generation, we need datasets and benchmarks that expose the fine-scale failures hidden by low-resolution evaluation.
📄 𝗣𝗿𝗼𝗷𝗲𝗰𝘁 𝗽𝗮𝗴𝗲: 4klsdb.github.io
💻 𝗚𝗶𝘁𝗛𝘂𝗯: github.com/taco-group/4KLSDB
💽 𝗗𝗮𝘁𝗮𝘀𝗲𝘁: huggingface.co/datasets/Sing…
#ComputerVision #GenerativeAI #ImageRestoration #SuperResolution #TextToImage #DiffusionModels #Dataset #Benchmarking #TAMU

1
8
60
5,097

Jun 8
🗽🗼 New York & Paris — reimagined as glowing 2K city scroll art. Generated entirely from a text prompt with AVCLabs AI Image Generator.
No design skills. Batch generation. No software.🎨
👉 Try it free: avclabs.com/ai-tools/ai-imag…
#AVCLabs #AIImageGenerator #AIArt #TextToImage




1
3
123
Jun 7
🎨 TEXT-TO-IMAGE MODELS
Which image model are you using most today?
⚫ GPT Image 2
🟡 Ideogram 4.0
🟢 Flux 2 Max
🔵 Recraft V4
Each excels in different areas:
📸 Photorealism
📝 Typography
🎨 Design
⚙️ Control
What's working best for your projects?
👇
#AI #TextToImage #GenerativeAI #AIArt #Design

3
5
8
464


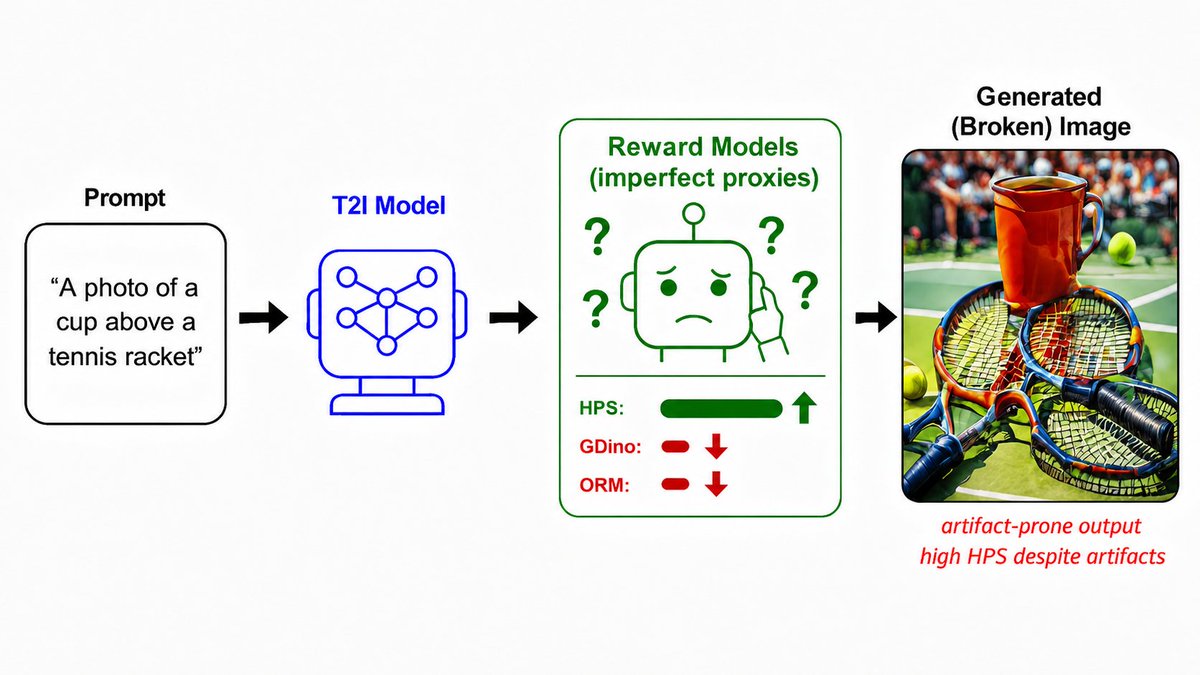
We’re excited to share our new work on CVPR 2026, Understanding Reward Hacking in Text-to-Image Reinforcement Learning.
Reinforcement learning is becoming an increasingly important tool for post-training text-to-image generation models. But as we optimize these models with learned rewards, an important question arises:
Are reward models truly improving generation quality, or are they creating new ways for models to game the objective?
In this work, we take a closer look at reward hacking in T2I RL post-training. We study a range of reward designs, including aesthetic and preference rewards, prompt-image consistency rewards, and multi-reward ensembles.
Our analysis shows that models can easily over-optimize a single reward across reward setups. Human preference reward may push generations toward exaggerated colors or superficial appeal, while a prompt-image consistency reward may improve alignment at the cost of realism and structure.
Even combining multiple rewards only partially mitigates the issue.
To mitigate this, we introduce ArtifactReward, a lightweight artifact-aware reward trained from a small curated dataset of artifact-free and artifact-containing samples. ArtifactReward can be integrated into existing T2I RL pipelines as a simple safeguard, improving realism and reducing reward hacking across multiple reward configurations.
Paper: arxiv.org/pdf/2601.03468
Code: github.com/yq-hong/ArtifactR…
Poster Session: June 6, 7:30am ExHall A
Many thanks to our amazing team: Yunqi Hong @yyqq_hong , Kuei-Chun Kao @KueiChunKao, Hengguang Zhou @hgzhou42 , and Cho-Jui Hsieh @cho_jui_hsieh .
#CVPR2026 #TextToImage #ReinforcementLearning #RewardHacking #GenerativeAI #UCLA #TurningPointAI
1
5
179