𝐓𝐡𝐞 𝐃𝐚𝐭𝐚 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐒𝐭𝐚𝐜𝐤: 𝐅𝐫𝐨𝐦 𝐑𝐚𝐰 𝐒𝐢𝐠𝐧𝐚𝐥𝐬 𝐭𝐨 𝐀𝐮𝐭𝐨𝐧𝐨𝐦𝐨𝐮𝐬 𝐀𝐜𝐭𝐢𝐨𝐧
Most data teams build storage and analytics then wonder why AI fails.
The problem is not the model.
It is the 4 layers between your Data and your AI that do not exist yet:
𝟏. 𝐅𝐨𝐮𝐧𝐝𝐚𝐭𝐢𝐨𝐧 𝐋𝐚𝐲𝐞𝐫: 𝐃𝐚𝐭𝐚 𝐒𝐭𝐨𝐫𝐚𝐠𝐞
• Ingest from anywhere. Scalable, cost-effective, all data types.
• Technologies: PostgreSQL, Azure Data Lake, Delta Lake, Amazon S3, Google Cloud Storage, HDFS.
The single source of truth for all your data.
Get this wrong and every layer above it inherits the mess.
𝟐. 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐢𝐧𝐠 𝐋𝐚𝐲𝐞𝐫: 𝐓𝐚𝐛𝐥𝐞𝐬 𝐚𝐧𝐝 𝐅𝐨𝐫𝐦𝐚𝐭𝐬
• Schema evolution, optimized storage, ACID reliability, analytics performance.
• Technologies: Parquet, Delta Lake, Apache Iceberg, ORC.
Raw data is not usable data.
This layer makes it consistent, efficient, and reliable.
𝟑. 𝐃𝐢𝐬𝐜𝐨𝐯𝐞𝐫𝐲 𝐋𝐚𝐲𝐞𝐫: 𝐃𝐚𝐭𝐚 𝐂𝐚𝐭𝐚𝐥𝐨𝐠
• Metadata, ownership, lineage, impact analysis, access governance, data quality.
• Technologies: DataHub, Alation, Unity Catalog, AWS Glue.
If your team can not find the data or trust it, nothing downstream works.
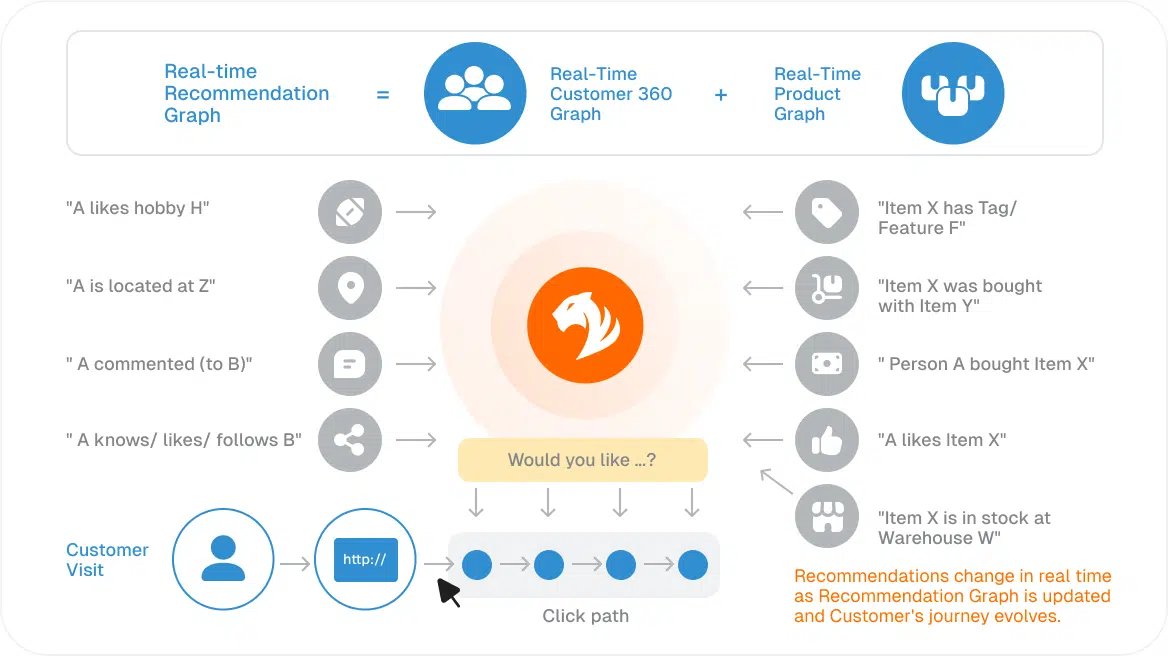
𝟒. 𝐂𝐨𝐧𝐭𝐞𝐱𝐭 𝐋𝐚𝐲𝐞𝐫: 𝐊𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐆𝐫𝐚𝐩𝐡
• Entities, relationships, and context-aware reasoning.
• Technologies: Neo4j, Amazon Neptune, Stardog, TigerGraph.
This is the layer most teams skip entirely.
Knowledge graphs connect the dots understanding context and relationships, not just rows and columns.
𝟓. 𝐁𝐮𝐬𝐢𝐧𝐞𝐬𝐬 𝐋𝐚𝐲𝐞𝐫: 𝐒𝐞𝐦𝐚𝐧𝐭𝐢𝐜 𝐋𝐚𝐲𝐞𝐫
• Define and govern metrics. Consistent definitions. Reusable models.
• Technologies: Cube, Looker, AtScale, Unity Catalog, dbt Semantic Layer.
One source of truth for metrics and KPIs.
Without this, two teams asking the same question get different answers.
𝟔. 𝐈𝐧𝐭𝐞𝐥𝐥𝐢𝐠𝐞𝐧𝐜𝐞 𝐋𝐚𝐲𝐞𝐫: 𝐀𝐈 𝐑𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐚𝐧𝐝 𝐀𝐜𝐭𝐢𝐨𝐧
• LLMs, RAG and retrieval, AI agents, ML models, continuous learning.
• Technologies: MLflow, Mosaic AI, Agent Bricks, LangChain.
Intelligent applications that reason, decide, and act autonomously.
This layer only works if the five below it are solid.
Most teams jump from layer 1 to layer 6 and skip everything in between.
That is why their AI hallucinates it has no catalog, no context, no semantic definitions, and no knowledge graph to reason over.
𝐖𝐡𝐢𝐜𝐡 𝐥𝐚𝐲𝐞𝐫 𝐢𝐬 𝐦𝐢𝐬𝐬𝐢𝐧𝐠 𝐟𝐫𝐨𝐦 𝐲𝐨𝐮𝐫 𝐝𝐚𝐭𝐚 𝐬𝐭𝐚𝐜𝐤 𝐭𝐨𝐝𝐚𝐲?
♻️ Repost this to help your network get started