
4 Mar 2025
🔥 Read our Paper
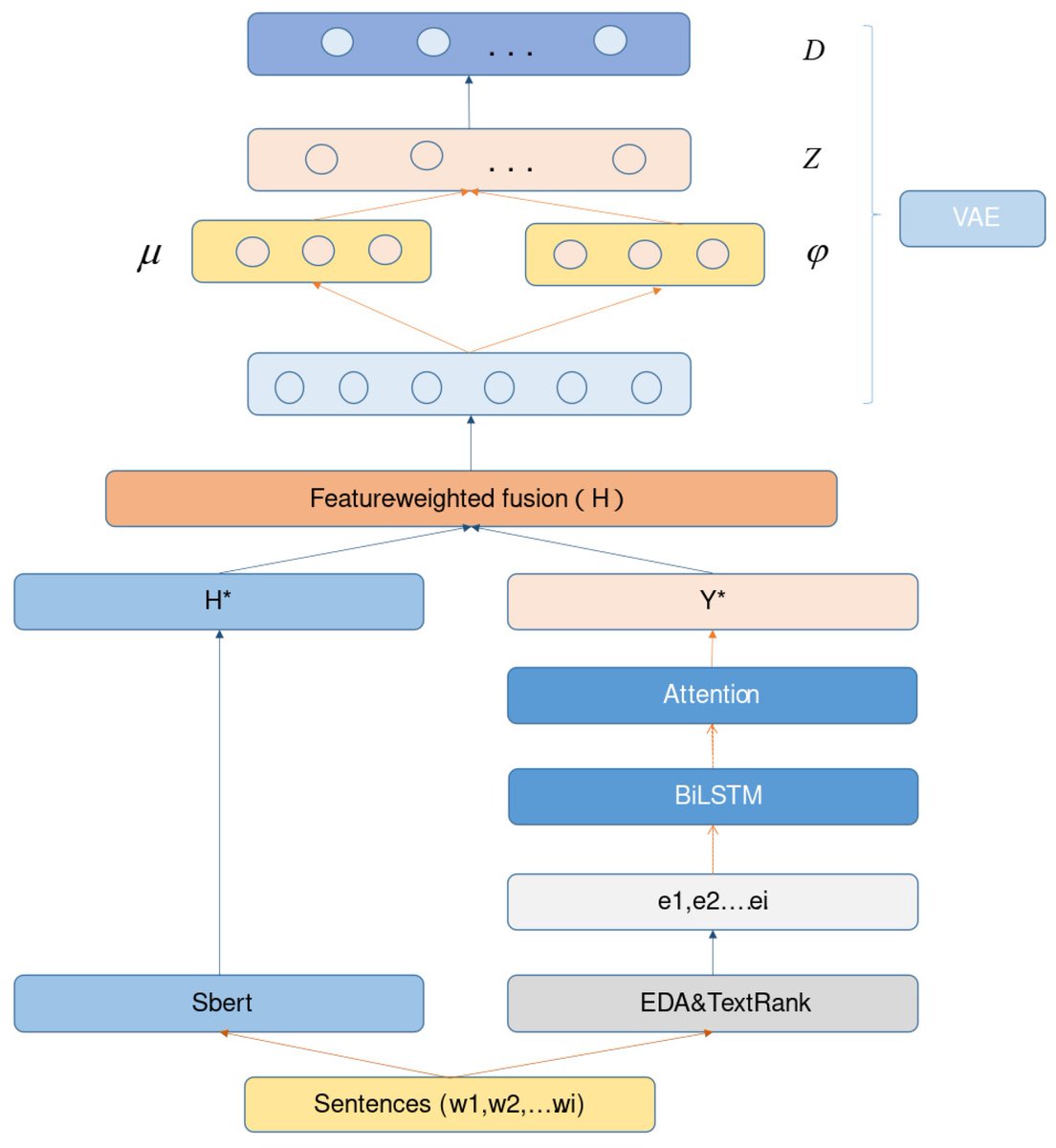
📚 A Neural Topic Modeling Study Integrating SBERT and Data Augmentation
🔗 mdpi.com/2076-3417/13/7/4595
👨🔬 by Huaqing Cheng et al.
#SBERT #topicmodels #dataaugmentation #featurefusion
1
80

1 Mar 2025
Under the hood update: We’ve tuned topic assignment to increase the coverage of TopicModels.
When scoring a note, the Community Notes algorithm factors in whether the note is found helpful by people who normally disagree. It factors in whether raters have disagreed in general and whether they've disagreed on on the specific topic of the note.
Assigning more topically-relevant notes to TopicModels results in the notes that show across X being found more helpful to people from different points of view.
As always, the code is open source: communitynotes.x.com/guide/e…
20
28
291
65,894

6 Dec 2024
Supercharge Your Content Strategy with AI! bit.ly/3VsozZ7
#AI #AIContentCreation #PillarPages #TopicModels #BlogPost #ArtificialIntelligence #SEOStrategy #ContentStrategy #SEO #DigitalMarketing #SEOStrategy #ContentMarketing #WebDesign #Members #MembershipAssociation
2
3
35

29 Oct 2024
Glad to see you making use of the open source data & code. A key thing to know about topic models is that they score many notes that end up rated Helpful and shown across X, but the only time you'll see "TopicModel" show up as the "scored by" model is when the note is receiving a Needs More Ratings status. That's why you're not seeing the TopicModels assign a Helpful status, despite many notes they score ending up as Helpful -- the "scored by" field for those Helpful notes will list the initial model that assigned that Helpful status, e.g. CoreModel.
Obviously there are a large number of Community Notes related to these topics that show widely across X. Topic models just help increase the likelihood that the notes will be found helpful to people from different points of view. They've been live for ~7 months and you can see full detail on how they work here: communitynotes.x.com/guide/e…
Now, I know it can be frustrating if a note one feels is good does not get rated helpful and shown, or flips status. It does not mean the note is bad or flawed. There are undoubtedly notes that would be found broadly helpful but don't end up getting shown. We're continually improving the open source scoring algorithm to show as many helpful notes as possible. In general, the scoring system is designed to err on the side of ensuring the notes it shows are helpful and informative to people of different points of view, and avoiding showing notes that are not.
1
5
355

Make data-driven marketing decisions. 📈
Learn how to use R packages such as tidytext, wordcloud, rtweet, topicmodels, and ggplot2 to help you improve your company’s marketing strategy!
Start learning for free 👉 ow.ly/x93U50SSY7Q
#DataScience #MarketingAnalytics

1
6
2,032

4 May 2024
Excited to have led a workshop on validating text-as-data and topic models at COMPTEXT24! Ensuring that our analysis meets scientific standards is key & don't forget: validate, validate, validate! #textasdata #topicmodels #COMPTEXT24
3 May 2024



2
20
1,798

20 Jan 2024
Was alerted to Pritchard's work by old friend @aleksj who showed me early models were a variant of our #topicmodels . Took the #MachineLearning community another 10 years to figure it out. In the meantime Remco Bouckaert adapted later methods to linguistics. Small world.
1 Oct 2023

I'm delighted to release the first half of my new open-access online textbook in human population genetics:
web.stanford.edu/group/pritc…

2
269

5 Oct 2023
Our work was published in Advances in Computational Intelligence! Check out "Unsupervised Topic Modeling with BERTopic for Coarse and Fine-Grained News Classification" link.springer.com/chapter/10… @moduluniversity #IWANN2023 #neuralnetworks #BERTopic #newsclassification #topicmodels
2
3
86

18 Aug 2023
Excited to share our paper on US higher ed responses to the murder of George Floyd. #topicmodels show shift in talk from colorblind racism to systemic racism. #ergm shows schools in blue states, elites, and HBCUs focus more on systemic racism @Noorealism
dx.plos.org/10.1371/journal.…
1
3
7
1,289

22 May 2023
6/9 Tool Demo: topiconR - A Tool for Extracting Characteristic Words and Documents From Topicmodels and Labeling Them. - with Saïd Unger, Johanna Klapproth and @ZwiZwaSvens
1
1
4
231

18 May 2023
Emergent #Twitter publics through #political scandal : an example from the #Covid-19 Crisis in the UK strathprints.strath.ac.uk/83… #SocialMedia #politics #journalism #TopicModels #networks #OpenAccess @MichaelTHiggins @TraversingBits

2
203

17 Feb 2023
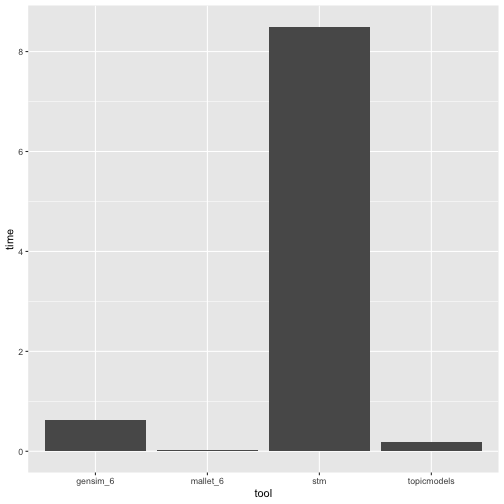
Headaches to fit topic models on a corpus with 2.3 million documents: See 👇 benchmark comparing Mallet and Gensim (6 cores), stm and topicmodels. Takeaway for @textasdata: Mallet is fast! 'biglda' makes sense: github.com/PolMine/biglda. Read blogpost: polmine.github.io/posts/2023…
2
3
496

BigML #TopicModels help understand the hidden insights in unstructured text data and document collections. The extracted topics often prove highly effective as new input features to train different types of models. Try it today! #MachineLearning bigml.com/features/topic-mod…

1
3
199

6 Aug 2022
We'll hear about applying #topicmodels on Craigslist housing listings, #eviction dynamics in ethnic enclaves, racial inequalities in being a #landlord, the role of #nonprofits in mitigating eviction, and the role of #investors and non-local landlords in shaping eviction!
1
3

Last working day and happy 😊 to taste “lo spazio latente”, 🍷 produced to honor the graduation of Francesca 👩🎓 who patiently worked on #topicmodels with #humanintheloop in the form of constraints. 🎉 👏 to the new data scientist (and off to 🏝)

ALT Lo spazio latente, wine label made for graduation
11



16 Apr 2022
まともに勉強をし始めたきっかけが、ギブスサンプリングも知らないのにtopicmodels::LDA()を使ってたの?って言われたからだった
1
6

23 Mar 2022
In Lecture 18, we continue w/ #clustering and discuss #mixedmembershipmodels! We cover 1) how this relates to fuzzy/hard clustering, 2) #GMMs, and 3) briefly cover #topicmodels & #lda (not many #NLP-ers this yr) What would you cover re: MMMs? #ML #CUDBMIMLHC #followme #comment👇
2

2 Mar 2022
In no way a proper benchmark but if you're doing topic modeling in R, textmineR::FitLdaModel took about 2 minutes on my dataset, topicmodels::LDA closer to 30 minutes #rstats
1
1
4