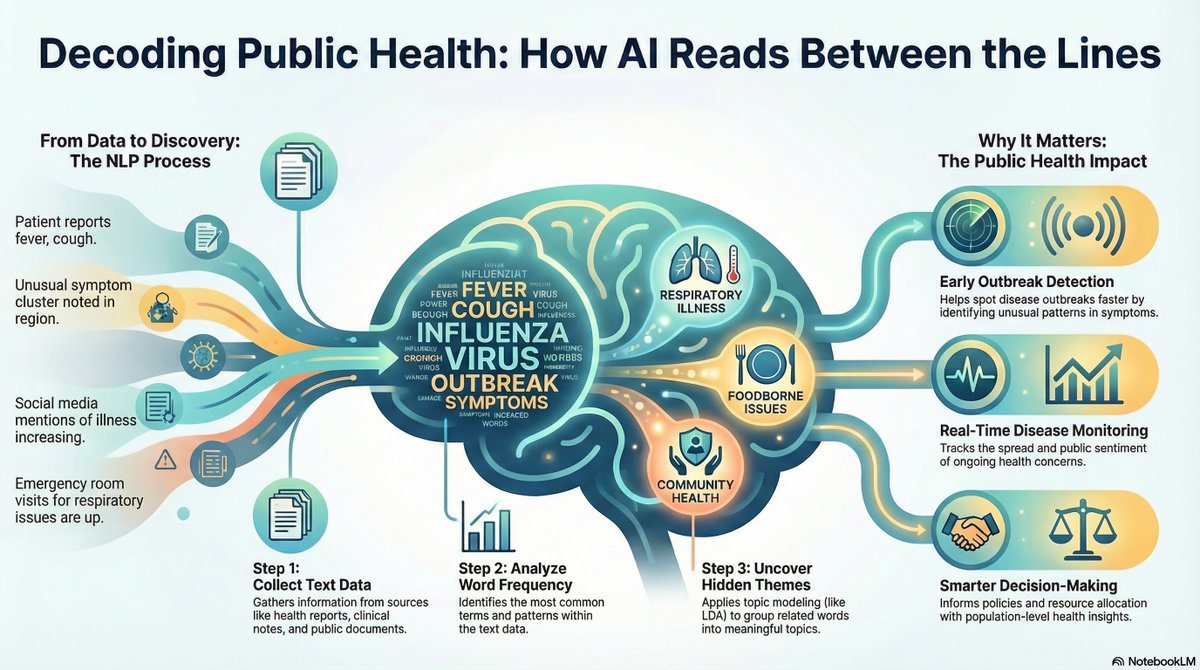
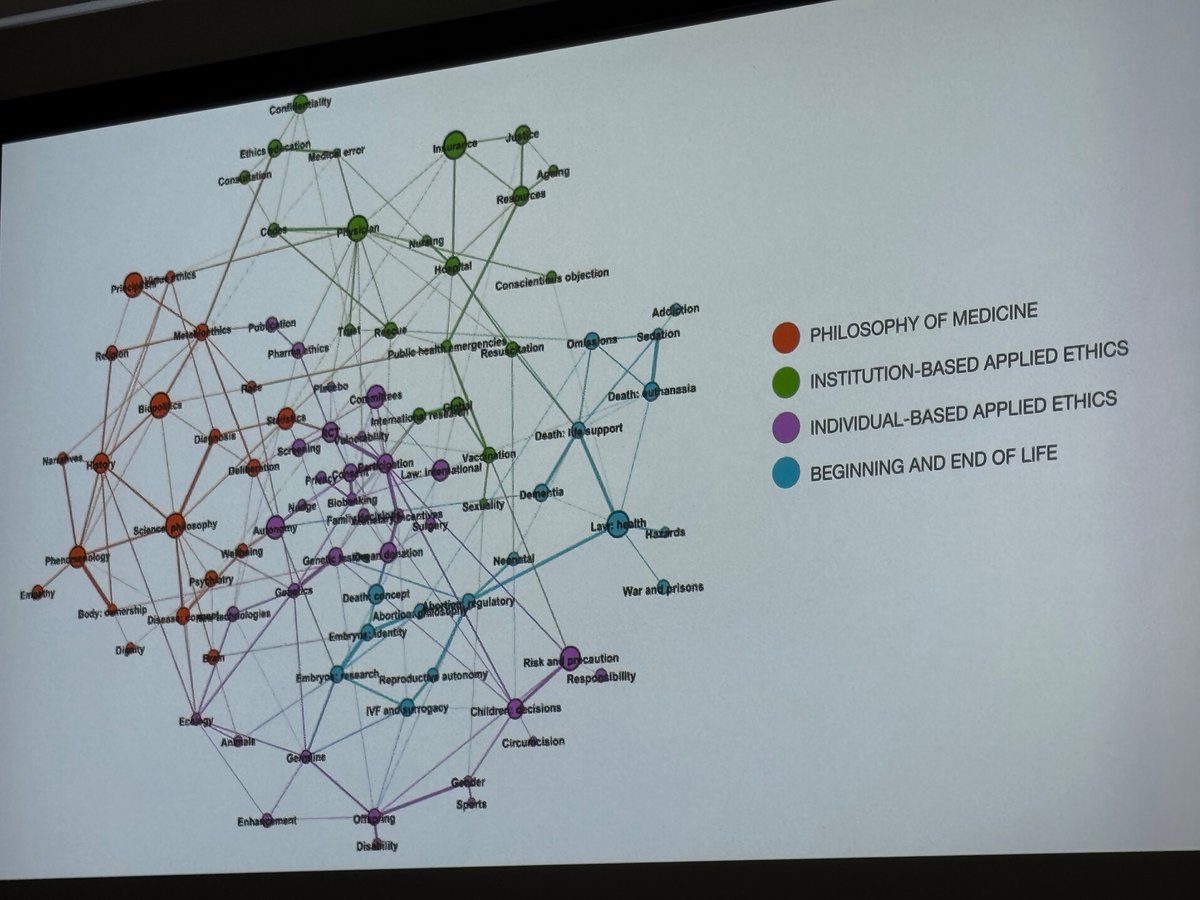
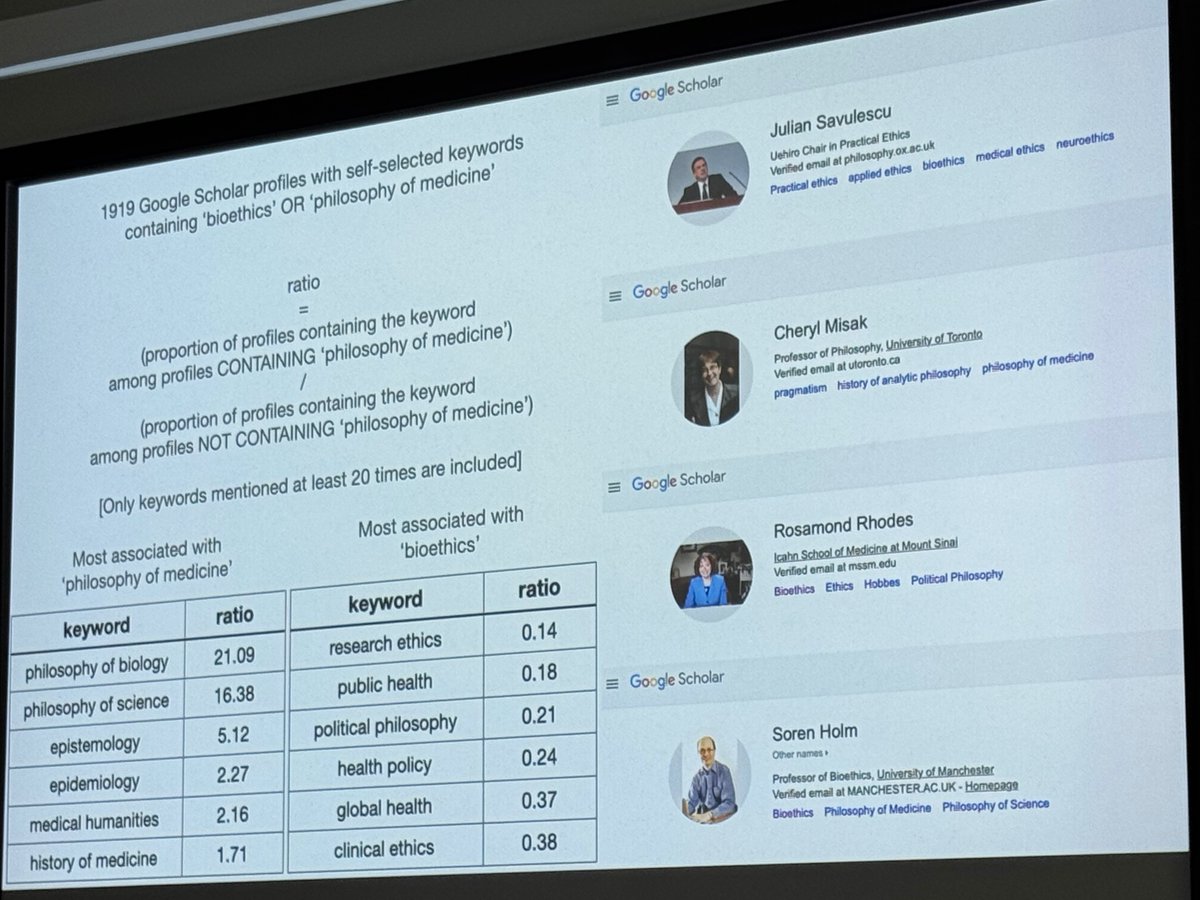
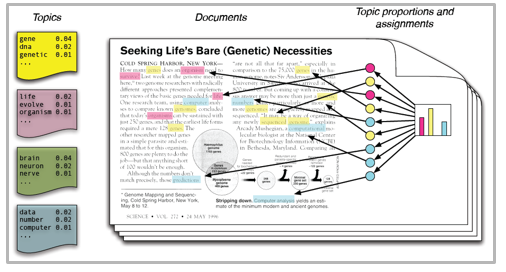
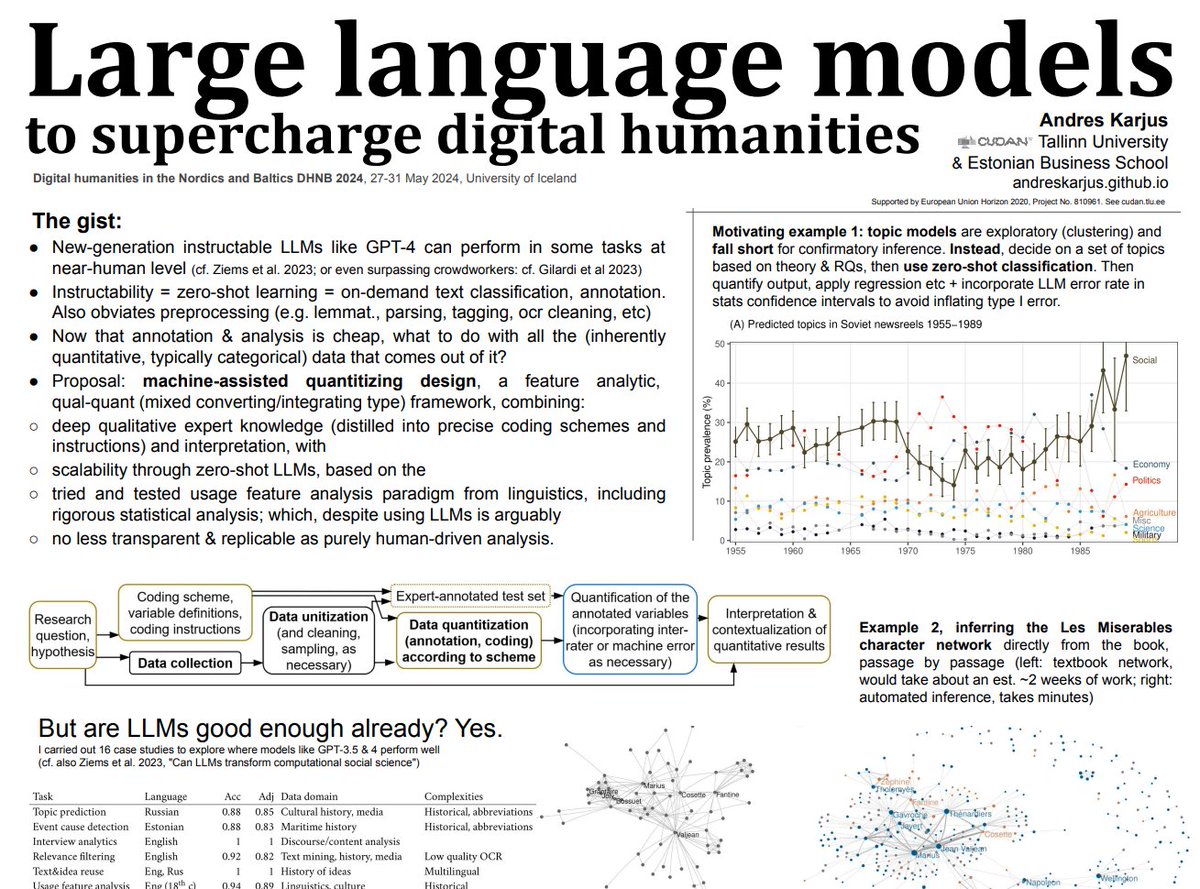
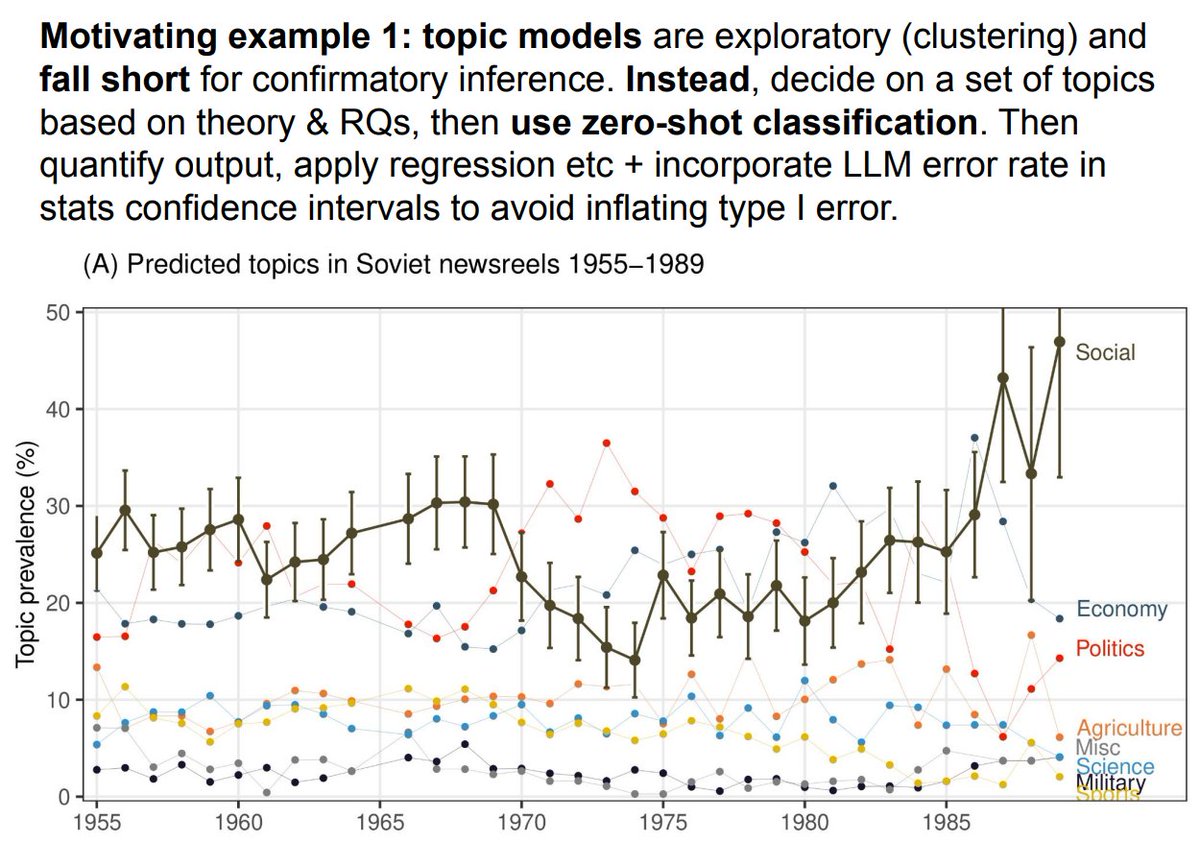
🔍 Deep Dive: Why CEMTM Redefines Multimodal Topic Modeling
At EMNLP 2025 in Suzhou, I’ll be presenting CEMTM (Contextual Embedding-based Multimodal Topic Modeling) — a model that rethinks how we discover topics in multimodal documents by moving entirely into the contextual embedding space.
Unlike classical or contextualized topic models such as CWTM, which rely on Dirichlet priors and discrete sampling, CEMTM operates with continuous variational inference, enabling both semantic precision and computational efficiency.
Here’s what makes it stand out:
🚀 Key Contributions
1. Multimodal Topic Learning
CEMTM unifies text, image, and structural data under a shared embedding space. Topics are no longer word distributions—they are semantic clusters of contextual embeddings that span across modalities.
2. Contextual Embedding Alignment
Each token (word, visual patch, or table element) is attracted to its topic vector in the embedding space, replacing Dirichlet sparsity with differentiable optimization. This enforces semantic cohesion within topics.
3. Cross-Modal Coherence Regularization
A novel coherence term maximizes cosine similarity among top tokens of each topic—even across modalities—so that text and visual components that convey the same concept naturally align.
4. Variational Efficiency
Without Dirichlet sampling or vocabulary-wide softmax operations, CEMTM achieves up to 3× faster training and 5–10× faster inference, fully leveraging GPU-parallelizable vector operations.
5. State-of-the-Art Topic Quality
On multiple multimodal datasets, CEMTM outperforms prior models like CWTM, MMNTM, and ZeroShot-LDA in both coherence and diversity, demonstrating that contextualized multimodal alignment leads to more interpretable and scalable topic discovery.
🧠 The Takeaway
CEMTM shows that topic modeling can evolve beyond discrete words and priors.
By clustering contextual embeddings directly and optimizing cross-modal coherence, it enables interpretable, efficient, and semantically rich topic discovery across heterogeneous documents.
📍 Presentation: Poster Session — Wednesday, Nov 5 · 16:30–18:00 · Hall C (EMNLP 2025, Suzhou)
📄 Paper:
arxiv.org/abs/2509.11465
#EMNLP2025 #MultimodalAI #DeepResearch #TopicModeling #ChartUnderstanding #QuestionAnswering #LLMs #Research