
Jun 5
Found a ripper memory layer for AI agents — Mnemosyne (AxDSan/mnemosyne, 959⭐). Zero deps, single SQLite file, sub-millisecond recall. Built for Hermes first but works everywhere: Cursor, Claude Code, Codex, OpenWebUI, OpenClaw, any MCP client. One pip install and you're off.
Architecture is the standout — BEAM (Bilevel Episodic-Associative Memory) with three tiers: Working Memory for hot context auto-injected before LLM calls, Episodic Memory for long-term storage using sqlite-vec FTS5 hybrid search (50% vector 30% keyword 20% importance), and a TripleStore for temporal knowledge graphs with version chains. The clever bit: they binarise 384-dim float32 embeddings down to 48 bytes via MIB (Information-Theoretic Binarisation) — 32x compression, Hamming distance computed entirely inside SQLite. No external vector DB, no ANN indices, just one file.
Benchmarks back it up: 98.9% Recall@All@5 on LongMemEval (ICLR 2025), 65.2% on BEAM end-to-end QA at 100K scale (beating Honcho, Hindsight, LIGHT, RAG). Recall holds flat at 20% even at 10M items with 35ms latency and 7.2MB storage. 100% abstention accuracy — it just says "dunno" instead of hallucinating.
For Hermes users there's a dedicated plugin (mnemosyne-hermes) exposing 23 tools across core memory (remember, recall, sleep, stats), knowledge graph (triple_add, triple_query, graph_query, graph_link), multi-agent shared memory, working notes scratchpad, and ops (export/import/diagnose). Three lifecycle hooks (pre_llm_call, on_session_start, post_tool_call) inject context automatically. Install: pip install mnemosyne-hermes && hermes config set memory.provider mnemosyne && hermes memory setup.
Also runs as a standalone MCP server (mnemosyne mcp) for any MCP-compatible client. OpenAI-compatible embedding endpoint configurable — defaults to bge-small-en-v1.5 but swap to multilingual models for non-English. MIT licensed, active development, Discord community. If you're building agents that need to actually remember stuff across sessions without wrestling with Postgres/Qdrant/Docker stacks, this is the one.

3
2
10
321

My second paper "A Lisp Dialect for NDB Interpreted Code" I'll present at European Lisp Symposium 2026 tomorrow at 16:00 CEST.
Live stream available at: european-lisp-symposium.org/…
#els2026 #dydra #lisp #rdf #triplestore
1
1
2
114


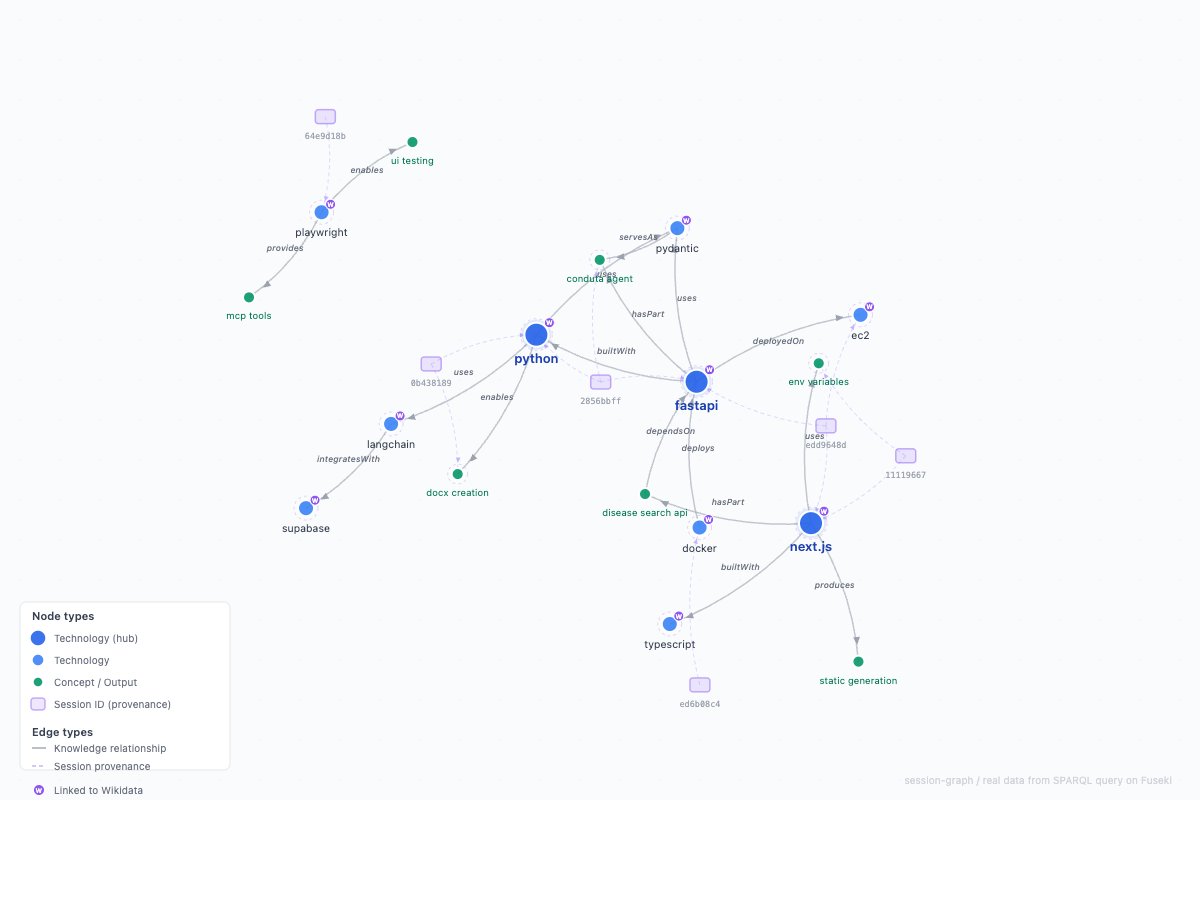
session-graph: Turn your scattered AI coding sessions into a queryable knowledge graph
Developers use 5 AI tools every day -- Claude Code, ChatGPT, Cursor, Copilot, Grok, DeepSeek, Warp. Each session is an isolated silo. Knowledge dies when the tab closes.
They solve the same problem three times across different tools and cannot find any of them.
Existing solutions are single-platform and flat-file. They give you search over one tool's history, not structured relationships across all of them. A grep over session logs does not tell you that FastAPI uses Pydantic or that Neo4j is a type of graph database. It just gives you walls of text.
session-graph promises to fix this.
session-graph extracts structured knowledge triples -- (subject, predicate, object) -- from all your AI coding sessions, links entities to Wikidata for universal disambiguation, and loads everything into a SPARQL-queryable triplestore with full provenance back to the source conversation.
Features:
* Multi-platform: Ingests Claude Code, ChatGPT, DeepSeek, Grok, and Warp into a single unified graph. No other tool does this.
* Formal ontology: Composes 5 W3C/ISO standards (PROV-O, SIOC, SKOS, Dublin Core, Schema.org) instead of inventing a custom schema.
* Wikidata linking: Entities are disambiguated against 100M Wikidata items via owl:sameAs. "k8s", "kubernetes", and "K8s" all resolve to Q22661306.
* Full provenance: Every knowledge triple traces back to the exact source message, session, platform, and file path.
* Federated queries: SPARQL can query your local graph and Wikidata in a single query.
Once the graph database has data, you don't need to write SPARQL by hand. session-graph ships with a Claude Code skill (devkg-sparql) that translates natural language questions into SPARQL queries, runs them, and returns formatted results.
By @RobertoShimizu
github.com/robertoshimizu/se…
#SoftwareEngineering #AICoding #EmergingTech
--
The Year of the Graph's Spring 2026 newsletter issue on all things #KnowledgeGraph, #GraphDB, Graph #Analytics / #DataScience / #AI and #SemTech is coming soon.
Subscribe and follow to be in the know. Reach out if you'd like to be featured 👇
yearofthegraph.xyz/newslette…
4
4
30
1,353

Jan 30
Check out the agenda for our upcoming Berlin meetup!
@olevzhynskyi - Building Cross-Platform Agentic UI
@WolfOliver - A Triplestore-Powered BaaS: Real-Time Collaboration Without the Backend
@VitorMalencar - Modernizing Your React App
Kudos to @Superhuman for support!

1
2
2
382



11 Dec 2025
Thanks for the feedback!
The query performance depends on the triplestore. The default one is Fuseki but any SPARQL-compatible should do.
You couldntry @TENTRIS_DB or @dydradata, for example.
If you have use cases feel free to DM me :)
2
29

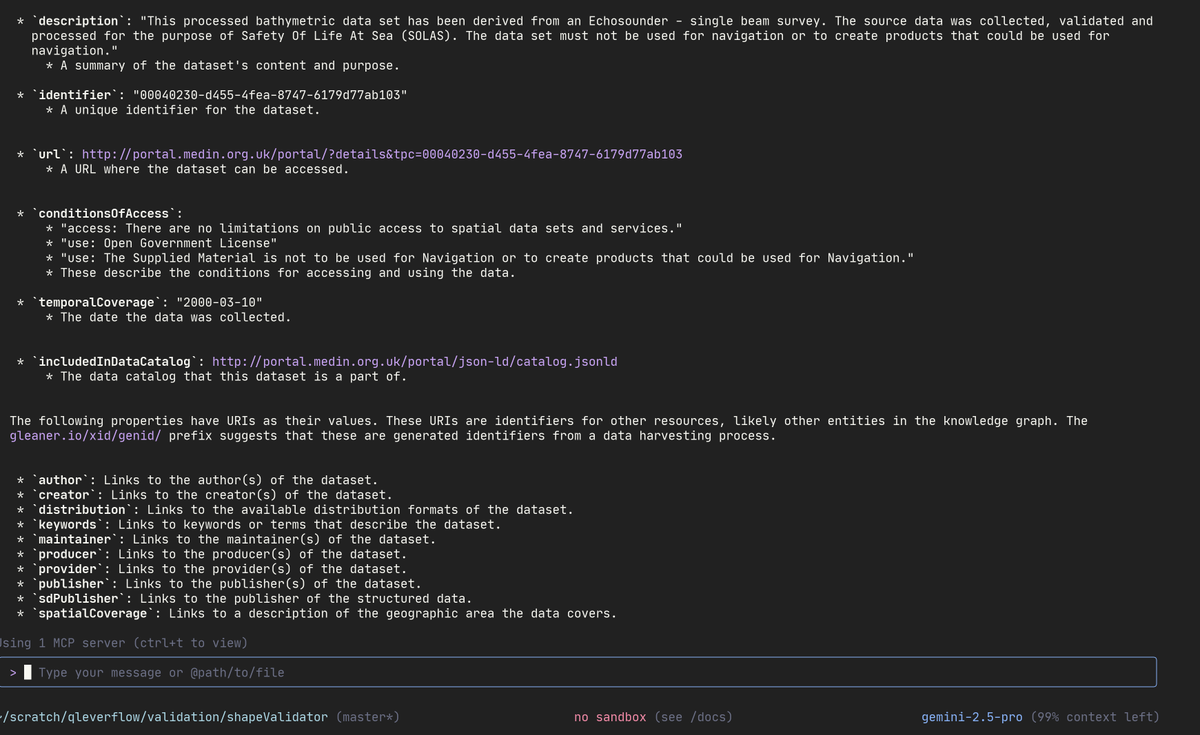
Fun playing with Gemini-CLI connecting into Qlever triplestore via MCP (github.com/google-gemini/gem…).
I then had Gemini fetch and display the Medin portal url and was very impressed.
CLI FTW!
2
121

24 Feb 2025
Proud to announce our second venture! We teamed up with the makers of the incredibly fast and scalable RDF triplestore QLever, to provide commercial support and services under QLeverize.
If you have hard graph problems, let’s talk.
linkedin.com/pulse/announcin…
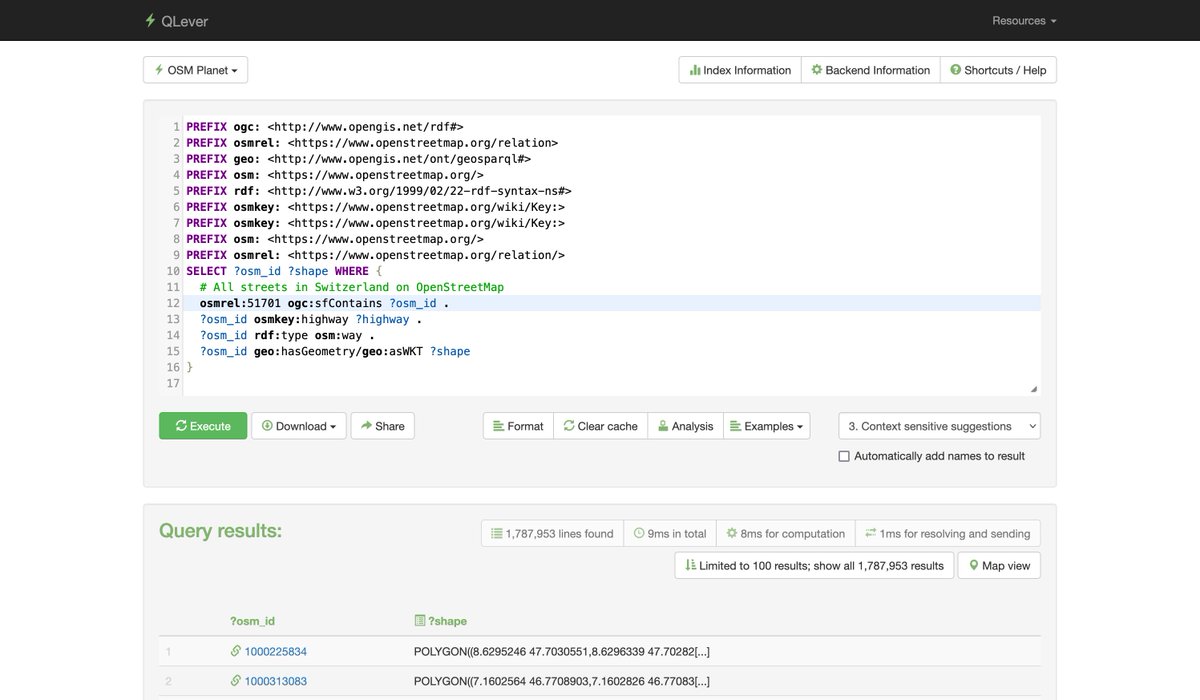
ALT SPARQL query to get all streets in Switzerland, on the OpenStreetMap dataset (~250 billion triples)

6
15
789

5 Feb 2025
nightmare fuel. I remember the significant chunk of my time with a particular employer that was spent adding sparql support to a purpose-built triplestore
2
40

27 Dec 2024
The answer they are looking for is @origin_trail it's a decentralized knowledge graph that stores triples in a distributed node system on a triplestore
3
29

20 Oct 2024
If you use the GraphDB triplestore, you can embed Lucene queries in your SPARQL queries: youtube.com/watch?v=VDNoYhFd…
2
177

8 Jul 2024
Welcoming Tony Seale, the Knowledge Graph Guy, to Connected Data London 2024
An experienced software architect and polyglot programmer with a proven track record of successfully delivering Knowledge Graphs into production for Tier 1 investment banks.
Tony can guide the creation of Enterprise Knowledge Graph architecture. He has deep knowledge of the relevant technologies (data pipelines, triplestore optimisation, API and service design, graph neural networks, and graph visualisation) and the soft skills required to lead development teams and interface with stakeholders at all levels.
Tony has been exclusively focused on building decentralised Knowledge Graphs for the last ten years and he has given talks, produced videos and written articles to promote the technology.
Tony has been a Connected Data London regular since 2016, and it's a pleasure to have him back.
Watch this space for more speaker announcements, and make sure you buy your early bird ticket while it lasts!
#KnowledgeGraph #LLM #AI #DataModeling #Events #FOMO #MondayMood
connected-data.london/tony-s…

3
8
483

14 Apr 2024
pakai graph database. salah satu fungsinya memang utk struktur data graph yg cocok untuk silsilah. ada yg RDF (triplestore) atau property graph (cypher, gremlin, ngql). yg cukup umum, neo4j (cypher). apache age jg bisa, basisnya postgresql. abis itu tinggal mikir UI-UX.
1
8
2,439


incredible, someone who knows the implementation of an rdf triplestore off the top of his head on my tl. this is so far from my usual posting im kinda surprised
i really just need a triple store, not high level rdf stuff like sparql or inference, though theyd be convenient ig
1
3
98

What happens when you bring together the best-in-class #knowledgegraph curation platform & the best-in-class #RDF triplestore? Register for our webinar w/ Ontotext CEO @kiryakov_ak & @TopQuadrant CEO Nimit Mehta on Jan 30 to find out!
👉 hubs.la/Q02f5Xkf0 #datamanagement
1
6
329

3 Jan 2024
Powered by natural language querying, the triplestore enables organizations to balance the strengths and weaknesses of these AI techniques. thenewstack.io/allegrograph-… #AI #LargeLanguageModels #LLMs #DataScience
2
5
1,067

1 Dec 2023
Looking for a Knowledge Graph solution? We've got you covered: we have compiled a database of RDF triplestore products (commercial and open-source) and even the W3C specifications they support 🫡
kgdev.net/products/
3
24
1,636