
Jun 11
@zilliz_universe Unveils Vector Lakebase, Transforming the Leading Vector Database Into an Integrated AI Data Platform
aitech365.com/data-managemen…
#AI #AIDataPlatform #AITech365 #CentralizedData #DataLakeSearch #DataManagement #news #vectordatabase #VectorLakebase #Zilliz
5

Zilliz just launched Vector Lakebase in public preview on Zilliz Cloud, bringing vector search, analytics, and data discovery into one single platform.
Read more - businessleadersreview.com/zi…
#Zilliz #VectorLakebase
9

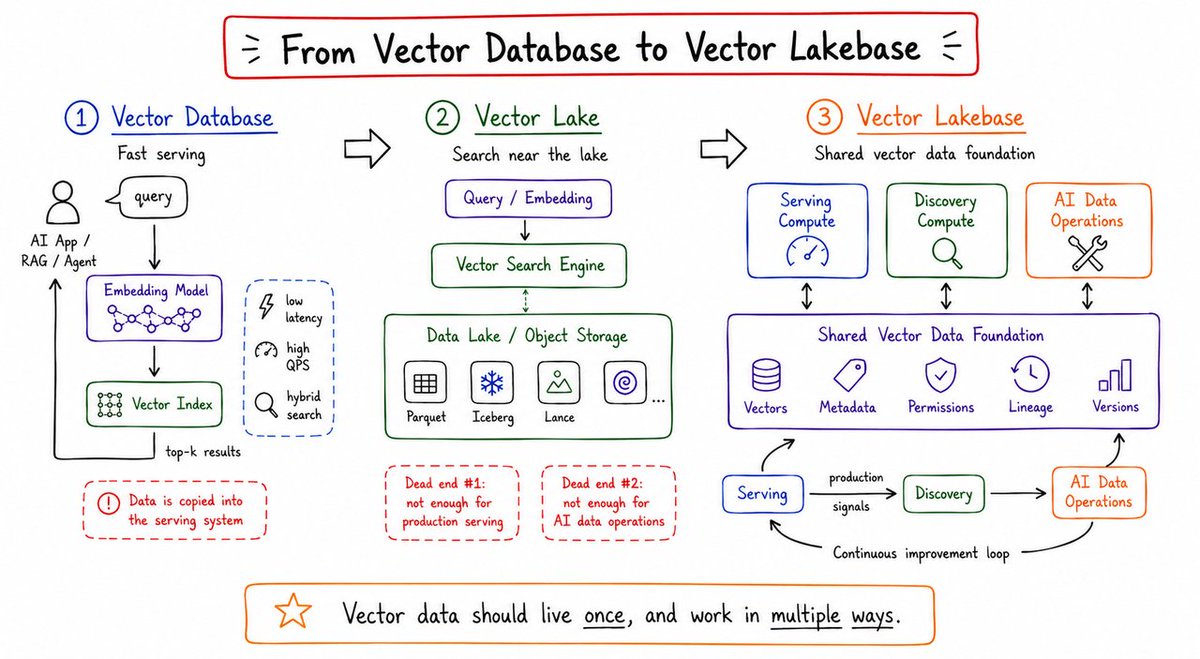
Most AI teams do not start with a blank slate.
They already have data in object storage, pipelines, logs, labels, evaluation sets, and production systems. Then vector search enters the picture.
𝗧𝗼 𝘀𝗼𝗹𝘃𝗲 𝘁𝗵𝗶𝘀 𝗱𝗮𝘁𝗮 𝗴𝗿𝗮𝘃𝗶𝘁𝘆 𝗽𝗿𝗼𝗯𝗹𝗲𝗺, 𝘃𝗲𝗰𝘁𝗼𝗿 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗵𝗮𝘀 𝗲𝘃𝗼𝗹𝘃𝗲𝗱 𝘁𝗵𝗿𝗼𝘂𝗴𝗵 𝘁𝗵𝗿𝗲𝗲 𝗴𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝘀.
𝟭-𝗩𝗲𝗰𝘁𝗼𝗿 𝗱𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀 solved the first problem: low-latency semantic retrieval for production AI applications.
They are still critical for production RAG, agents, recommendation, search, and multimodal apps that need database-speed serving at high QPS.
But as teams scale, more data already lives in lakes and lakehouses. Moving it into a separate serving system creates pipelines, sync jobs, and stale indexes.
𝟮-𝗩𝗲𝗰𝘁𝗼𝗿 𝗹𝗮𝗸𝗲𝘀 brought the search closer to the data.
Useful, but incomplete. Search near the lake is not the same as production serving. It also does not cover the broader AI data lifecycle: embedding, evaluation, clustering, deduplication, and multimodal processing.
𝟯-𝗩𝗲𝗰𝘁𝗼𝗿 𝗹𝗮𝗸𝗲𝗯𝗮𝘀𝗲 takes one step further.
It is a new AI-native and lake-native architecture evolved from vector database systems. It combines production-grade vector serving with lake-native storage and elastic compute, so online search and offline AI data operations can run on the same source of truth.
That is the architecture behind Zilliz Vector Lakebase:
𝗔𝗜 𝗱𝗮𝘁𝗮 𝘀𝗵𝗼𝘂𝗹𝗱 𝗹𝗶𝘃𝗲 𝗼𝗻𝗰𝗲, 𝗮𝗻𝗱 𝘄𝗼𝗿𝗸 𝗶𝗻 𝗺𝘂𝗹𝘁𝗶𝗽𝗹𝗲 𝘄𝗮𝘆𝘀.
No permanent tax from duplicate storage, sync pipelines, and stale data.
---
👉 Follow @zilliz_universe for vector database and vector lakebase updates built for production AI.
#VectorDatabase #VectorLakebase #ScaleWithZilliz #AIInfrastructure
1
3
232