
Deleting for one user never breaks another user's search → Concurrent uploads are handled safely with no extra infra Vectors are shared. Access is isolated. That's the right model for multi-user RAG.
#RAG #Qdrant #VectorDatabase #LLM #AIEngineering #Python
1
3

Jun 13
🧬 High-Quality Vector Embeddings & Vector Databases — the critical foundation that powers accurate retrieval in all modern RAG, semantic search, and agentic systems.
Just read this excellent technical white paper from @aasaitech on building reliable retrieval layers for industrial and manufacturing domains.
Key highlights: • Embedding models (text-embedding-3-large/small, BGE, E5, Instructor/GTE) domain-specific fine-tuning • Smart chunking strategies rich metadata filtering (equipment, location, date, safety, document type) • Vector DB options (Pinecone, Weaviate, Milvus, Qdrant, Chroma, Redis) • 5-step semantic search pipeline with continuous feedback evaluation (Recall@K, Precision, Context Relevance) • Industrial impact: Maintenance manuals, SOPs, logs, drawings — dramatically reducing hallucinations and improving reliability
This is the retrieval backbone that makes everything else (CoT, agents, multimodal, long context) actually work in production edge orchestration and manufacturing AI.
Full white paper infographic: x.com/aasaitech/status/20656…
How are you handling embeddings and vector stores in your systems — open-source fine-tuned models, managed DBs, or full custom industrial pipelines with heavy metadata?
#VectorEmbeddings #VectorDatabase #RAG #SemanticSearch #IndustrialAI #AgenticAI #EdgeAI

20

Building AI-Powered Database Apps with @Hibernate #Vector and the Oracle AI Database 26ai — Part 2 — Using the Hibernate Vector module with Oracle AI Vector Search rb.gy/ab8dc2 #Java #AI #Hibernate #VectorDatabase #JavaOracleDB @OracleDatabase @JakartaEE @juarezjunior

22

Jun 11
Most people think LLMs remember everything you tell them.
They don't.
One of the biggest misconceptions in AI is confusing memory with context.
When you interact with an LLM, every message is converted into tokens and placed inside a context window. Think of it as the model's working space. As long as information remains within that window, the model can use it. Once the window fills up, older information gets compressed, summarized, or dropped to make room for new context.
This is why long conversations sometimes become less reliable. The model isn't actually forgetting. It simply no longer has access to some of the information it saw earlier.
Memory works very differently.
Suppose a user shares their preferences with an AI agent today and returns a month later. The model won't remember those preferences unless they were stored somewhere and retrieved when needed. That's why modern AI systems rely on memory layers, vector databases, retrieval pipelines, and RAG architectures.
In many ways, building great AI products isn't about making models smarter. It's about ensuring the right information reaches the model at the right time. That's the difference between a good AI demo and a production-grade AI system.
#AIAgents #RAG #GenerativeAI #LLM #AIEngineering #AgenticAI #VectorDatabase #SoftwareEngineering
1
8

Jun 11
One of the most expensive mistakes in a RAG project is choosing a vector database based on benchmarks instead of workload characteristics.
The question isn't "Which vector database is best?"
The question is "What failure mode can your system tolerate?"
Most teams evaluate vector databases by looking at latency, recall, and throughput numbers. Those metrics matter, but they rarely determine whether your architecture succeeds in production.
What actually matters is the shape of your retrieval workload.
If you're building an internal knowledge assistant with a few hundred thousand documents, pgvector may be the most practical choice. Your vectors live beside your application data, backups stay simple, and your team doesn't need another distributed system to operate.
If you're expecting billions of vectors, multi-tenant workloads, and aggressive latency targets, dedicated systems like Pinecone, Qdrant, or Milvus start making more sense.
If metadata filtering is central to retrieval quality, database architecture often matters more than raw ANN search speed. Many production bottlenecks appear in filtering, ranking, and retrieval orchestration—not vector similarity itself.
The deeper lesson is that vector databases are only one layer of retrieval quality.
I've seen teams spend weeks comparing databases while ignoring chunking strategy, embedding selection, hybrid search, reranking, and evaluation pipelines.
A mediocre vector database with excellent retrieval design usually outperforms a world-class vector database with poor retrieval design.
Another observation: the industry is slowly moving away from treating vector databases as standalone infrastructure. More teams are asking whether vector search should be a dedicated service at all, or simply a capability inside their existing data platform.
That's why the "best" database keeps changing.
The real decision framework is:
How much data will you store in 12 months?
What latency can your users tolerate?
How much operational complexity can your team support?
How important are filtering, hybrid search, and governance requirements?
Is vector search your core product capability or just one feature?
Those answers usually narrow the field faster than any benchmark chart.
For engineers running RAG systems in production:
What was the first bottleneck you hit—vector search itself, metadata filtering, retrieval quality, or operational complexity?
#RAG #VectorDatabase #AIEngineering #GenerativeAI #SoftwareArchitecture #DataEngineering #DistributedSystems

1
58

Jun 11
We benchmarked 5 engines on what agents actually do with sustained writes concurrent reads:
-> seekdb: 1,523 QPS, 21.7ms P99, 1.1× jitter.
->Next closest: 470 QPS, 53.6ms P99, 10.3× jitter.
That gap is architecture, not config.
Configs raw results: app.marketbeam.io/m/i2oThxs8…
#seekdb #VectorDatabase #AIAgents

2
5
11
967

Jun 11
@zilliz_universe Unveils Vector Lakebase, Transforming the Leading Vector Database Into an Integrated AI Data Platform
aitech365.com/data-managemen…
#AI #AIDataPlatform #AITech365 #CentralizedData #DataLakeSearch #DataManagement #news #vectordatabase #VectorLakebase #Zilliz
5

Jun 10
Vector Databases are the secret weapon behind AI that truly understands what you mean, not just what you type.
bit.ly/4ungQtJ
#AI #VectorDatabase #innovations #AIDevelopment

4

Jun 9
Getting a RAG demo to run is easy.
Understanding what happens between ingestion, retrieval, and generation is harder.
The Zilliz Cloud onboarding experience helps users go from sign-up to a working RAG workflow in minutes.
In one guided flow, you can ingest data, run Hybrid Search, inspect retrieval results, and generate grounded answers.
At the end, you get packaged RAG app code that you can adapt locally.
It is built for developers who want to understand the retrieval layer by seeing it work, not by reading another setup guide.
Try it here: try.zilliz.com/?utm_source=x
---
👉 Follow @zilliz_universe for vector database and vector lakebase updates built for production AI.
#Zilliz #RAG #VectorDatabase
111

Everyone is obsessed with LLMs.
Almost nobody talks about the database that makes them useful.
Because without retrieval, most AI applications would be surprisingly forgetful.
Think about it:
❌ ChatGPT doesn't know your company's internal documents.
❌ Claude doesn't automatically know your product manuals.
❌ AI agents don't magically remember every customer interaction.
They need a way to find the right information at the right time.
That's exactly what Vector Databases do.
They turn millions (or billions) of embeddings into searchable knowledge.
When you ask a question, the model isn't searching documents.
It's searching meaning.
That's why Vector Databases have become one of the most important pieces of the modern AI stack.
Some of the major players:
→ Pinecone
→ Weaviate
→ Qdrant
→ Milvus
→ Chroma
→ pgvector
→ Redis Vector
→ FAISS
→ MongoDB Atlas Vector Search
→ Elasticsearch
→ OpenSearch
→ LanceDB
→ Vespa
→ Azure AI Search
The interesting part?
The AI race isn't only about building smarter models anymore.
It's about building better memory.
Because the model generates the answer.
But retrieval decides what the answer is based on.
In many production AI systems, retrieval quality matters more than model quality.
The companies winning with AI aren't always using the largest models.
They're often using the best retrieval architecture.
What's powering your RAG stack today? 👇
#AI #GenAI #RAG #VectorDatabase #LLM #AIAgents #MachineLearning #DataEngineering #SoftwareEngineering #ArtificialIntelligence

8
14
81
1,794

Building AI Systems Isn't About Choosing the Best LLM
Most teams spend weeks comparing GPT, Claude, Gemini, DeepSeek, Llama, and Qwen.
In reality, that's usually the easiest part.
The real challenge is everything around the model.
A production-grade AI system typically looks like this:
🧠 LLMs
The reasoning engine behind your application.
Examples:
• GPT
• Claude
• Gemini
• DeepSeek
• Llama
• Qwen
🔗 Frameworks
Connect models to tools, workflows, and business logic.
Examples:
• LangChain
• LlamaIndex
• Haystack
🗄️ Vector Databases
Long-term memory for AI applications.
Examples:
• Pinecone
• Qdrant
• Weaviate
• Chroma
• Milvus
📥 Data Extraction
Pull information from websites, PDFs, documents, and knowledge bases.
Examples:
• FireCrawl
• Crawl4AI
• Docling
• LlamaParse
🤖 Open Model Access
Run models locally or through open providers.
Examples:
• Ollama
• Hugging Face
• Groq
• Together AI
🔎 Embeddings
Convert text into vectors for semantic search.
Examples:
• OpenAI Embeddings
• Voyage AI
• SBERT
• Nomic
📊 Evaluation
The most overlooked layer.
Measure:
• Accuracy
• Relevance
• Latency
• Hallucinations
Examples:
• Ragas
• TruLens
• Giskard
The Workflow Is Surprisingly Simple
1️⃣ Collect data
2️⃣ Extract and clean it
3️⃣ Generate embeddings
4️⃣ Store them in a vector database
5️⃣ Retrieve relevant context
6️⃣ Send context to the LLM
7️⃣ Evaluate and improve continuously
The Biggest Lesson I've Learned
The model rarely determines whether an AI project succeeds.
Data quality, retrieval quality, evaluation, and system architecture usually matter far more than whether you're using GPT, Claude, Gemini, or DeepSeek.
Most AI failures are actually:
❌ Data failures
❌ Retrieval failures
❌ Architecture failures
Not model failures.
💭 Which layer of the AI stack do you think is currently the most underrated?
#AI #GenAI #LLM #RAG #ArtificialIntelligence #MachineLearning #DataEngineering #VectorDatabase #LangChain #LlamaIndex #AgenticAI
#SoftwareArchitecture #SystemDesign #Python #Java #AWS #CloudComputing #Developers
17
18
51
2,132

🔍 Frustrated with intranet search that only finds documents with exact keywords?
Traditional search fails when employees use different terms than those in your documents. RAG with vector databases enables semantic search that understands meaning, not just word matches.
Learn how to integrate Milvus with Open Intranet for intelligent knowledge base search.
👉 Read the guide: eu1.hubs.ly/H0vSYHG0
#Drupal #OpenIntranet #AI #RAG #SemanticSearch #VectorDatabase #Intranet

1
17

Vector databases vs traditional databases 👇
📖 Traditional DB:
searches for words
🧠 Vector DB:
searches for meaning
Search for "pet" and you might get:
🐶 dog
🐕 puppy
🐱 cat
That's why vector databases power RAG and semantic search.
#AI #VectorDatabase #RAG #NoSQL
5
142

📣 𝗢𝘂𝗿 𝘄𝗲𝗯𝗶𝗻𝗮𝗿 𝗮𝗯𝗼𝘂𝘁 𝗠𝗶𝗹𝘃𝘂𝘀 𝟯.𝟬 𝗶𝘀 𝗵𝗮𝗽𝗽𝗲𝗻𝗶𝗻𝗴 𝘁𝗼𝗱𝗮𝘆!
Join us with core maintainers Li Liu and Jiang Chen for:
Milvus 3.0 architecture → A clear picture of the Milvus 3.0 roadmap → How Milvus 3.0 powers Zilliz Vector Lakebase → 15–20 min AMA with maintainers
Time: June 8, 2026, 4:00 PM PDT
🔗 Link: zilliz.com/event/whats-new-i…
#Milvus #VectorDatabase #Zilliz #VectorSearch #AIInfrastructure

🌐 𝗪𝗲𝗯𝗶𝗻𝗮𝗿 | 𝗪𝗵𝗮𝘁’𝘀 𝗡𝗲𝘄 𝗶𝗻 𝗠𝗶𝗹𝘃𝘂𝘀 𝟯.𝟬: 𝗟𝗶𝘃𝗲 𝗪𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵 & 𝗔𝗠𝗔, 𝗝𝘂𝗻𝗲 𝟴 𝗼𝗻𝗹𝗶𝗻𝗲
Milvus 3.0 beta is the biggest architectural upgrade since the project began. It brings native support for indexing and querying vectors directly on your data lake, along with a query engine that goes beyond top-K search.
In this live session, core maintainers Li Liu and Jiang Chen will walk through what shipped, the design choices behind it, and how Milvus 3.0 powers 𝗭𝗶𝗹𝗹𝗶𝘇 𝗩𝗲𝗰𝘁𝗼𝗿 𝗟𝗮𝗸𝗲𝗯𝗮𝘀𝗲.
🎤 𝗧𝗼𝗽𝗶𝗰𝘀
• What changed in Milvus 3.0 beta
• Why data lake-native vector search matters
• What’s in beta now and what’s coming in GA
• How Milvus 3.0 powers Zilliz Vector Lakebase
• 15–20 min Live AMA with core maintainers
📅 𝗝𝘂𝗻𝗲 𝟴, 𝟮𝟬𝟮𝟲, 𝟰:𝟬𝟬 𝗽𝗺 𝗣𝗗𝗧
🔗 Register here: zilliz.com/event/whats-new-i…
Bring your questions about migration, performance, architecture, or anything else you’d like to ask the maintainers. Looking forward to the conversation!
#Milvus #VectorDatabase #Zilliz

210

Jun 8
SQL is no longer enough for the AI era. Enter Vector Databases. 📊⚡
Learn how high-dimensional vectors are changing how apps store data and understand human meaning.
Full article 👇
globaltech112.blogspot.com/2…
#VectorDatabase #DataScience #LLM #TechExplained #Developers
1
1
1
11

Jun 8
10/ AI is becoming a commodity.
Reliable AI systems are not.
That's where the real advantage is built.
#RAG #LangChain #VectorDatabase #AIEngineering #ProductionAI
7

Jun 7
One more in 🇺🇲!
As you may have observed, I don't do things only once; I keep repeating them (except a few 😜)! I am thrilled to announce my 2nd speaking engagement in the USA 🇺🇲. I will be presenting at the Michigan .NET Users Group (MI.NET) on September 16, 2026, in Southfield, MI!
A huge thank you to Dustin Kingen for organizing and to EPITEC for being the Platinum Sponsor!
And of course, none of this is worth anything without an amazing audience. Can't wait to learn and build together with the MI.NET community!
If you are in the Detroit area, come join us! RSVP here 👉 meetup.com/midotnet/events/3…
#RAG #GenerativeAI #AzureAI #dotNET #CosimeSimilarity #MINet #Embeddings #VectorDatabase #TechSpeaker

1
77

Jun 7
Day 25 🚀
Today was all about AI foundations 🤖
• LLMs
• Vector Databases
• Embeddings
• High-dimensional vectors
• Gemini Embedding models
• Similarity search & retrieval
Understanding how AI finds the right information is fascinating 💻✨
#AI #LLM #VectorDatabase #RAG

1
16

Jun 7
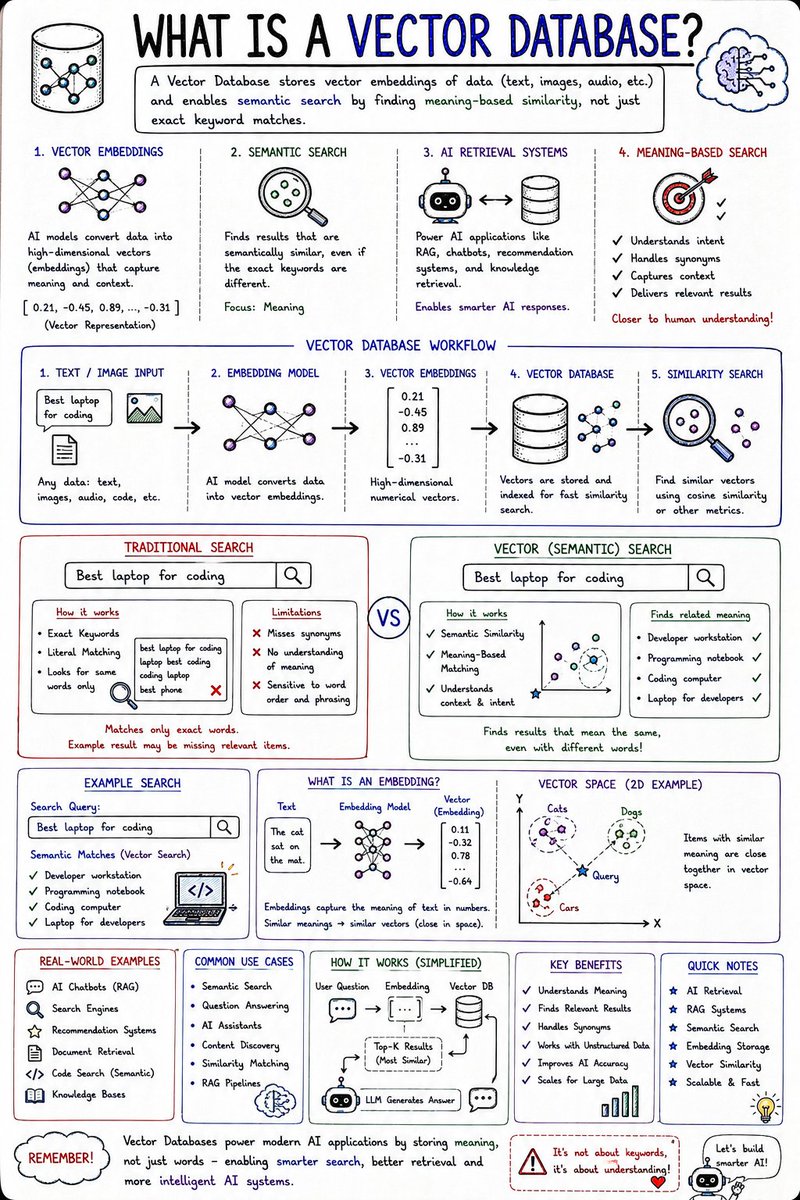
Traditional databases store rows & tables.
Vector databases store:
🧠 Meaning.
That’s how AI systems can perform:
✅ Semantic search
✅ AI retrieval
✅ Recommendation systems
✅ RAG pipelines
Modern AI search increasingly depends on vector databases.
#AI #VectorDatabase #LLM #MachineLearning
9

Jun 6
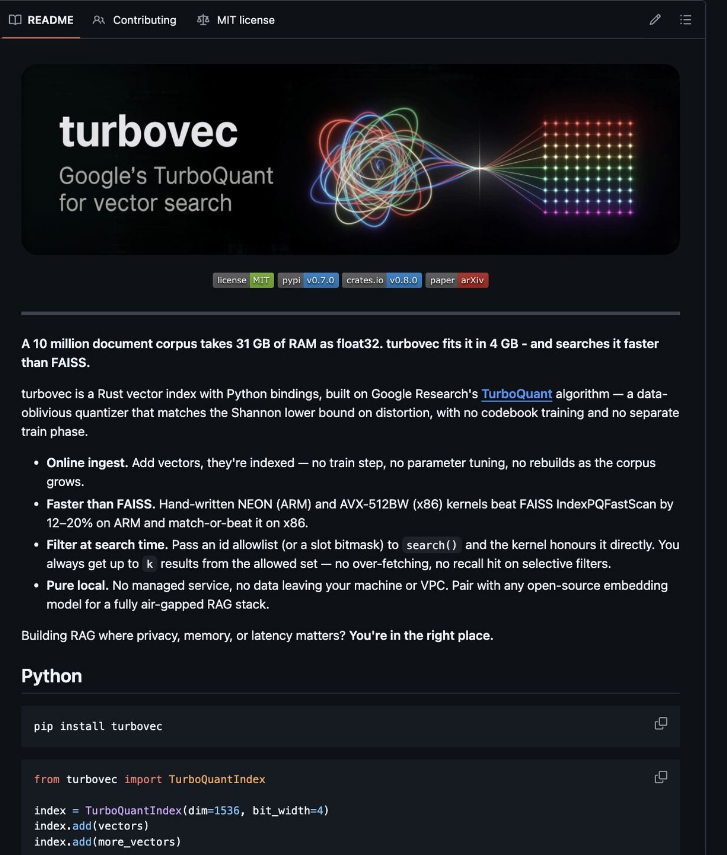
🤯 Google just found a way to squeeze 31GB of AI search data into only 4GB of memory.
That's nearly 8x less memory usage without sacrificing search quality.
The project is called TurboVec.
And it's completely open source.
Why does this matter?
Because every AI app needs to search through data:
→ RAG systems
→ AI agents
→ Chatbots
→ Knowledge bases
→ Vector search engines
The bigger your data gets, the more memory you need.
TurboVec attacks that problem directly.
According to the project:
✅ Stores vector data using dramatically less memory
✅ Faster search than FAISS in some workloads
✅ Works on Mac and Linux servers
✅ Supports LangChain & LlamaIndex
✅ Runs fully offline
✅ Python ready out of the box
The interesting trend here isn't TurboVec itself.
It's that open-source AI infrastructure keeps getting better, faster, and cheaper every month.
What required expensive hardware a year ago can now run on a normal machine.
That's a huge deal for developers building AI products.
🔖 Bookmark this one.
#AI #OpenSource #GitHub #MachineLearning #RAG #VectorDatabase #LangChain #LlamaIndex #AIAgents #Developer
1
4
391