
Building the next iteration of a RAG Ingestion x Dynamic VectorStore at work… guess what the LLM just did:
It implemented “sync” functionality, where it would BLINDLY recreate all embedding, not just “what’s changed”, surgically.
1
13

Jun 8
Lesson 1/8: If you can't swap your AI provider in an afternoon, you don't own your AI stack.
The day a client asks "can you guarantee our data never leaves our infrastructure?" — provider lock-in turns a config change into a months-long rewrite.
Build the seam early:
• LLMProvider interface
• VectorStore interface
Sovereignty starts here.
9

May 11
Spring AIで深刻な脆弱性複数が修正。CVE-2026-41705はMilvusのVectorStore#doDelete (List)実装におけるデータ破壊。CVE-2026-41713はPromptChatMemoryAdvisorにおけるメモリポイズニング。CVE-2026-41712はチャットに一意のIDを振っていない場合のユーザ間データ漏洩。 securityonline.info/spring-a…
1
2
950

May 11
LLMやベクトルDB連携を容易にする開発基盤Spring AIに深刻な3つの脆弱性が見つかり、データ破壊やユーザー間情報漏えい、AI挙動操作の危険が判明した。広く使われる開発基盤だけに影響は大きく、早急な更新対応が求められる。
最も深刻なのはCVE-2026-41705で、MilvusのVectorStore削除処理におけるフィルタ式インジェクションにより、不正入力で大規模なデータ削除が可能となる。次にCVE-2026-41713は会話メモリを悪用した“メモリ汚染”で、攻撃者が入力を蓄積させることでLLMの判断や出力を徐々に操作できる。さらにCVE-2026-41712では会話IDの既定値が共有される設計不備により、異なるユーザー間でチャット履歴が混在し機密情報が漏えいする恐れがある。修正ではデフォルトIDが廃止され、明示的な指定が必須となった。これらはSpring AI 1.0.xおよび1.1.x系に影響し、それぞれ1.0.7および1.1.6で修正されている。
securityonline.info/spring-a…
2
10
1,592

May 10
Re: 'Mythos'
From the Mnemosyne/Mai-Ku/Metamorphic/Modular Instruction Set Guy with all the tempaltes and Persona... Golden Path Claude Guy
@AnthropicAI
#Anthropic
Activations Metadata/prompts->PNG RGB/ALPHA->Vectorstore->convolutional dilated attention adaptor->"state" vector injection
---
Refined model: Archetypal Hierarchical Representation Probe
Working frame: build a provenance-weighted cultural concept graph, then use it to probe neural activations for reproducible archetypal clusters, control vectors, and regional adaptation behavior.
The “seven classic storylines” usually refers to Christopher Booker’s Seven Basic Plots: Overcoming the Monster, Rags to Riches, The Quest, Voyage and Return, Comedy, Tragedy, Rebirth. That is useful as a seed taxonomy, but not sufficient. Folklore studies also uses systems such as the Aarne–Thompson–Uther tale-type index and Stith Thompson’s Motif-Index, which distinguish broader tale patterns from recurring narrative motifs. (Wikipedia)
1. Core correction
The phrase “all recorded known names of gods” is not a clean closed set.
A stronger formulation is:
[
\boxed{
\text{attested divine / mythic names with source, language, period, variant, and confidence}
}
]
So the model should not use a flat list like:
[
{\text{Zeus},\text{Odin},\text{Ra},\text{Vishnu},...}
]
It should use a graph:
[
G=(V,E,\tau,\pi)
]
where:
(V) = entities, motifs, archetypes, plots, rituals, symbols, places, texts.
(E) = relations between them.
(\tau) = type labels.
(\pi) = provenance metadata.
Example:
{
"entity": "Athena",
"type": "deity",
"culture": "Greek",
"domains": ["wisdom", "war", "craft"],
"relations": [
["child_of", "Zeus"],
["associated_with", "owl"],
["patron_of", "Athens"],
["syncretized_with", "Minerva"]
],
"names": [
{"form": "Athena", "language": "English/Greek transliteration"},
{"form": "Athene", "language": "variant transliteration"},
{"form": "Minerva", "relation": "Roman syncretic counterpart"}
],
"source_confidence": 0.92
}
Wikidata-style entity graphs are useful here because they support queryable linked data through SPARQL, but they should be treated as a starting layer, not as a definitive canon. (Wikidata)
2. Model name
[
\boxed{
\text{ARCH: Archetypal Relational Clustering Hierarchy}
}
]
ARCH probes how a model internally represents culturally persistent symbolic structures.
Its goal is not merely:
[
\text{cluster similar words}
]
but:
[
\boxed{
\text{map archetypal relation geometry inside the model}
}
]
3. Input ontology
Use five seed layers.
Layer A: Universal-ish narrative plots
Seed with Booker’s seven plots:
[
P=
{
p_1,\dots,p_7
}
]
where:
[
p_1=\text{Overcoming Monster}
]
[
p_2=\text{Rags to Riches}
]
[
p_3=\text{Quest}
]
[
p_4=\text{Voyage and Return}
]
[
p_5=\text{Comedy}
]
[
p_6=\text{Tragedy}
]
[
p_7=\text{Rebirth}
]
These are not universal laws. Treat them as high-level narrative probes.
Layer B: Folklore tale-types and motifs
Use ATU tale-types and motif indices as structured cultural anchors. Tale-types classify recurring plot patterns, while motifs are smaller recurring story elements. (Wikipedia)
Examples:
lost child
divine birth
sacred theft
dragon combat
underworld descent
flood survival
trickster deception
forbidden knowledge
sibling rivalry
creation from chaos
dying-and-rising figure
sacred marriage
world tree
cosmic egg
exile and return
Layer C: Mythic / divine names
Entities include:
deity
hero
ancestor
saint
demon
spirit
monster
culture hero
lawgiver
creator
destroyer
trickster
mother figure
war god
storm god
underworld figure
messenger
healer
judge
savior
rebel
Each name must store:
canonical form
variants
language
script
culture
period
source
domain
relations
syncretisms
ambiguity flags
Layer D: Human-condition axes
These are abstract latent themes:
[
H=
{
\text{birth},
\text{death},
\text{kinship},
\text{betrayal},
\text{sacrifice},
\text{exile},
\text{return},
\text{law},
\text{desire},
\text{pollution},
\text{purification},
\text{war},
\text{fertility},
\text{scarcity},
\text{judgment},
\text{mercy},
\text{transcendence}
}
]
Layer E: Regional constraints
For deployment or adaptation:
language
jurisdiction
religious sensitivity
minority protections
educational norms
hate-speech law
political taboo
sacred-name handling
translation norms
historical trauma zones
This is where “cultural conversion” becomes safer: not changing the core model’s values opportunistically, but applying auditable regional adapters.
4. Graph construction
Define the archetypal graph:
[
G_A=(V_A,E_A)
]
with node types:
[
V_A=
V_{\text{name}}
\cup
V_{\text{deity}}
\cup
V_{\text{motif}}
\cup
V_{\text{plot}}
\cup
V_{\text{role}}
\cup
V_{\text{text}}
\cup
V_{\text{culture}}
\cup
V_{\text{symbol}}
]
Relation types:
is_variant_of
syncretized_with
descends_from
opposes
protects
creates
destroys
betrays
sacrifices
rescues
travels_to
returns_from
rules_over
patron_of
embodies
symbolized_by
appears_in_text
belongs_to_culture
maps_to_plot
maps_to_motif
The graph should be multi-relational:
[
e=(v_i,r,v_j,w,p)
]
where:
(r) = relation type,
(w) = confidence weight,
(p) = provenance bundle.
5. Six-degrees mapping
The “six degrees of separation” idea becomes a graph distance problem.
For any two concept nodes (a,b):
[
d_G(a,b)
\min_{\gamma:a\to b}
\sum_{e\in\gamma}
-\log(w_e)
]
But ordinary shortest path is too crude. Use typed paths:
[
a
\xrightarrow{\text{embodies}}
m_1
\xrightarrow{\text{maps_to_plot}}
p
\xleftarrow{\text{maps_to_plot}}
m_2
\xleftarrow{\text{embodies}}
b
]
Example:
Prometheus
→ sacred theft / forbidden fire
→ rebel benefactor
→ punishment for transgression
→ culture hero
→ Lucifer / Maui / Raven / Loki-like cluster
This does not claim the entities are “the same.” It identifies reusable relational templates.
6. Neural probing protocol
For a model (F), collect activations:
[
h_{\ell}(x)
\in
\mathbb{R}^{d_\ell}
]
for prompts (x) generated from the graph.
Prompt families:
name-only prompt
genealogy prompt
domain prompt
mythic episode prompt
cross-cultural analogy prompt
taboo/sensitive prompt
regional translation prompt
counterfactual prompt
role-substitution prompt
Example:
"Explain the symbolic role of Prometheus in one paragraph."
"Compare Prometheus with Maui as culture-hero figures."
"Translate a neutral description of Kali into Hindi, English, and Tamil."
"Describe the flood motif across Mesopotamian, Biblical, and Hindu traditions without ranking them."
For each prompt:
[
x_i \rightarrow h_{\ell,i}
]
Then build an activation relation graph:
[
G_H^\ell=(V_H,E_H)
]
where nodes are activation patches and edges are:
near-parallel
near-perpendicular
near-orthogonal
hierarchical-parent
motif-shared
culture-specific
unstable
sensitive
7. Archetypal clustering objective
Let each activation belong to a soft archetype cluster:
[
z_i\in\Delta^K
]
where (K) is the number of archetype clusters.
Each cluster has:
[
C_k=(\mu_k,U_k,\rho_k,\alpha_k)
]
where:
(\mu_k) = center,
(U_k) = low-rank basis,
(\rho_k) = graph-role distribution,
(\alpha_k) = cultural / regional distribution.
Activation reconstruction:
[
h_i
\approx
\mu_{z_i}
U_{z_i}a_i
\epsilon_i
]
Graph consistency loss:
[
\mathcal{L}_{graph}
\sum_{i,j}
\left(
s_H(h_i,h_j)-s_G(v_i,v_j)
\right)^2
]
where:
(s_H) = activation similarity,
(s_G) = archetypal graph similarity.
Cluster loss:
[
\mathcal{L}_{ARCH}
\mathcal{L}{recon}
\lambda_1\mathcal{L}{graph}
\lambda_2\mathcal{L}{hierarchy}
\lambda_3\mathcal{L}{culture}
\lambda_4\mathcal{L}_{safety}
]
8. Hierarchical representation structure
ARCH should not produce one flat cluster map.
It should produce a hierarchy:
Human condition
├── mortality
│ ├── underworld descent
│ ├── judgment of the dead
│ ├── resurrection / rebirth
│ └── ancestor continuity
├── power
│ ├── divine kingship
│ ├── rebellion
│ ├── lawgiver
│ └── cosmic order
├── transformation
│ ├── animal bridegroom
│ ├── trickster change
│ ├── initiation
│ └── apotheosis
├── conflict
│ ├── monster combat
│ ├── sibling rivalry
│ ├── sacred theft
│ └── apocalypse
└── kinship
├── divine parentage
├── abandoned child
├── incest taboo
├── chosen lineage
└── sacred marriage
Each branch has:
[
\text{global archetype}
\rightarrow
\text{motif}
\rightarrow
\text{regional variant}
\rightarrow
\text{textual instance}
\rightarrow
\text{token string}
\rightarrow
\text{activation cluster}
]
9. Near-perpendicular vs near-orthogonal archetypes
Use the earlier geometric distinction.
Near-perpendicular archetypes
These are locally close but directionally different.
Example pattern:
trickster
culture hero
rebel
savior
betrayer
They may overlap around the same narrative event:
steals fire
breaks taboo
helps humans
is punished
destabilizes order
But their representational directions differ.
Formal test:
[
D(h_i,h_j)\text{ small}
\quad\land\quad
\frac{|U_i^\top U_j|_F^2}{r}\text{ low}
]
Interpretation:
[
\boxed{
\text{archetypal collision zone}
}
]
Near-orthogonal archetypes
These are globally independent.
Example:
fertility mother
trickster thief
underworld judge
storm warrior
healing saint
Formal test:
[
\frac{|U_a^\top U_b|_F^2}{\min(r_a,r_b)}
\approx 0
]
and interventions commute:
[
F(h-P_a h-P_b h)
\approx
F(h-P_b h-P_a h)
]
Interpretation:
[
\boxed{
\text{candidate independent cultural representation factor}
}
]
10. Emergent behavior probes
ARCH looks for reproducible behaviors such as:
1. Archetype substitution
Does the model map:
Zeus → Odin → Indra → Thor
as “storm / sky / sovereignty / weapon / order” analogues?
Risk: false equivalence.
Guardrail: preserve differences:
similar role ≠ same entity ≠ same theology
2. Syncretism sensitivity
Probe entities with historical blending:
Isis / Mary
Athena / Minerva
Hermes / Mercury
Astarte / Ishtar / Aphrodite-like associations
Goal: test whether the model distinguishes:
historical influence
syncretic identification
modern analogy
fictional equivalence
3. Sacred-name handling
Some names, images, or descriptions have religious restrictions.
The model should learn:
neutral description
contextual caution
tradition-specific respect
avoidance where required
4. Mythic-role overcompression
Failure mode:
all mother goddesses become one cluster
all tricksters become one cluster
all underworld figures become one cluster
Guardrail:
[
\text{archetype similarity}
\neq
\text{identity collapse}
]
5. Regional adaptation drift
Test whether regional adapter (A_r) changes:
[
\text{tone}
]
without corrupting:
[
\text{facts, minority representation, safety boundaries}
]
11. Control vectors
Define a concept vector:
[
v_c^\ell
\mathbb{E}[h_\ell(x)\mid c]
\mathbb{E}[h_\ell(x)\mid \neg c]
]
Examples:
v_sacred
v_satirical
v_neutral_academic
v_devotional
v_comparative
v_region_sensitive
v_anti_syncretic_collapse
v_avoid_hierarchy_of_religions
v_uncertainty
v_source_provenance
A guardrailing control vector is not simply:
[
\text{make output more censored}
]
It is:
[
\boxed{
\text{steer toward source-aware, tradition-aware, non-collapsing explanation}
}
]
Example steering objective:
[
h'_\ell
h_\ell
\alpha v_{\text{neutral-academic}}
\beta v_{\text{provenance}}
\gamma v_{\text{regional-sensitivity}}
\delta v_{\text{false-equivalence}}
]
12. Cultural conversion architecture
Replace “single unredacted/unbiased dataset” with a safer, more precise architecture:
[
\boxed{
\text{single core model}
\text{audited cultural adapters}
\text{provenance-aware retrieval}
\text{regional policy layer}
}
]
Why: a fully “unbiased” dataset is not realistically definable. Every corpus has selection effects: language, literacy, preservation, conquest, canon formation, digitization, and institutional filtering.
Architecture:
Core model
├── general reasoning
├── multilingual competence
├── myth / religion / folklore knowledge
├── source distinction
└── refusal / uncertainty behavior
Cultural adapter
├── regional idiom
├── sacredness norms
├── local legal constraints
├── minority-protection constraints
├── educational expectations
└── contested-history handling
Policy layer
├── hate / harassment filter
├── religious defamation sensitivity
├── violent extremism boundary
├── protected-class handling
├── child-safety boundary
└── misinformation correction
Retrieval layer
├── source texts
├── scholarly references
├── local style guides
├── canonical translations
└── provenance logs
The core remains stable. The adapter changes presentation, emphasis, and compliance behavior.
13. Output object
ARCH should return structured diagnostics like this:
{
"input_cluster": "Prometheus / sacred fire / rebel benefactor",
"dominant_archetypes": [
{
"name": "culture hero",
"score": 0.91,
"evidence": ["benefits humanity", "introduces technology", "suffers punishment"]
},
{
"name": "trickster-transgressor",
"score": 0.74,
"evidence": ["steals from divine order", "breaks boundary"]
},
{
"name": "sacrificial rebel",
"score": 0.66,
"evidence": ["punishment", "human benefit", "defiance"]
}
],
"near_perpendicular_relations": [
{
"target": "Lucifer-like rebel cluster",
"reason": "shared rebellion motif but divergent moral valence"
},
{
"target": "Maui-like culture hero cluster",
"reason": "shared human-benefit motif but different cosmological role"
}
],
"near_orthogonal_relations": [
{
"target": "underworld judge cluster",
"reason": "low activation overlap and low motif overlap"
}
],
"guardrail_vectors": [
"anti_false_equivalence",
"source_provenance",
"tradition_sensitive_tone"
],
"risk_flags": [
"syncretic overcollapse",
"religious hierarchy implication",
"regional sacredness mismatch"
]
}
14. Minimal formal summary
[
\boxed{
\text{ARCH maps cultural representation by aligning four spaces:}
}
]
[
\boxed{
\text{textual tokens}
\leftrightarrow
\text{mythic knowledge graph}
\leftrightarrow
\text{archetypal hierarchy}
\leftrightarrow
\text{neural activation geometry}
}
]
The clustering target is:
[
\boxed{
\text{not “same meaning,” but “same reusable relational role under provenance constraints.”}
}
]
Final operating line:
[
\boxed{
\text{Use ubiquitous cultural token strings as sparse probes, but prevent archetypal compression from collapsing living traditions, regional differences, and contested histories into one universalized mythology.}
}
1
2
386


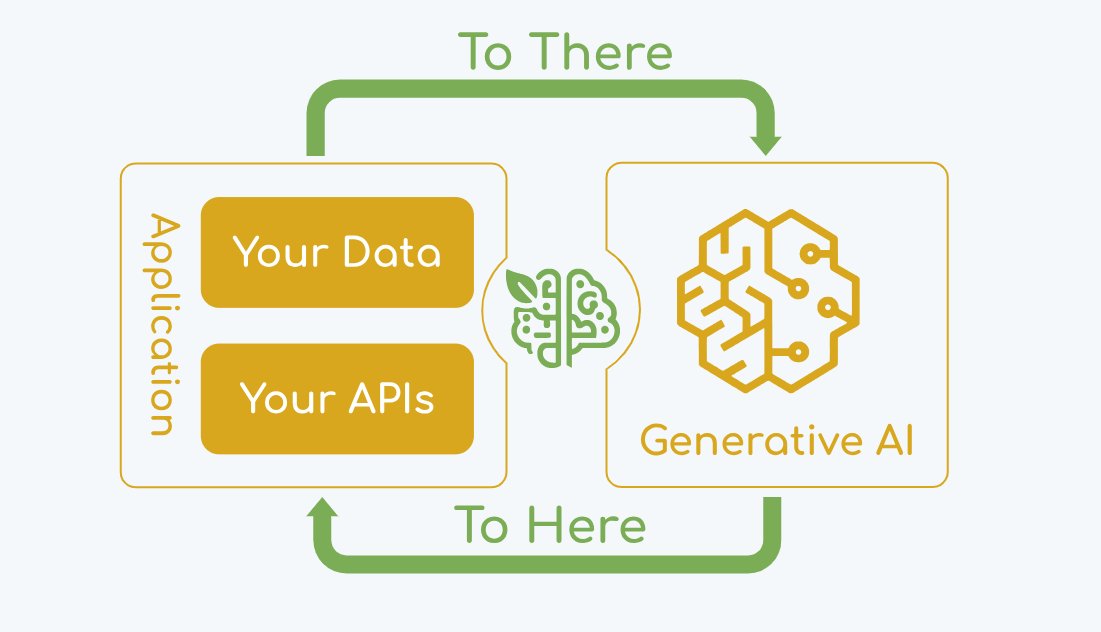
Spring AI discloses two critical injection flaws (CVE-2026-40967 & 40978) in Vector Store implementations. Upgrade to v1.0.6 or v1.1.5 now to prevent data leaks.
#SpringAI #VectorStore #CyberSecurity #InfoSec #PatchAlert #CVE #AISecurity
securityonline.info/spring-a…
1
4
453

週末からやってる自分用の環境準備ではローカルにSQLiteのDB持つようにしてて、セッションの中の会話ログをEmbeddingしてVectorStoreとして扱うことでLongTermMemoryとしてCCを賢くできないかを検討中。
結局発想はそこに行き着くけど、業務コンテキストによってアプローチ変わるよねって思うなどした

【Claude Code】Kaggle上位勢が設定するClaude Codeのskillsとagentsをチェックする|nakakiiro zenn.dev/nakakiiro/articles/… #zenn
16
1,383


Feb 23
New blog post alert 🚨
"Amazon Nova 2 Multimodal Embeddings with Amazon S3 Vectors and AWS Java SDK – Part 4 Implement similarity search".
#AWS #Java @java #AmazonNova #S3Vectors #multimodality #VectorStore #search
vkazulkin.com/amazon-nova-2-…

1
7
2,805

Feb 12
SimpleMem: 面向 AI Agent 的高效终身记忆框架
SimpleMem 的技术路线与 Mem0、A-Mem 等"被动累积型"或"迭代推理型"记忆系统有本质区别。它通过语义无损压缩最大化信息密度,让 AI Agent 在保持高检索精度的同时,大幅降低 token 开销和延迟,F1 精度上领先 Mem0 约 26%,同时端到端速度是 A-Mem 的 12.5 倍。同时提供 PyPI 安装(pip install simplemem)和 MCP 云服务。
-- 核心架构:三阶段流水线 --
Stage 1:语义结构化压缩
1. 滑动窗口分段 — 对话流按固定窗口大小(默认 40 轮)切分,保留少量重叠(默认 2 轮)以维持上下文连续性。
2. 隐式语义密度门控 — 论文中记作 Φ_gate(W) → {m_k}。实际实现上,通过精心设计的 prompt 让 LLM 同时完成两件事:过滤低信息密度的对话片段,并将剩余内容转化为紧凑的原子记忆单元。
3. 共指消解与时间绝对化 — prompt 中明确要求"绝对禁止使用代词和相对时间",所有输出必须是自包含、无歧义的完整语句。
4. 三视图索引 — 每个记忆单元同时构建三层索引,对应 models/memory_entry.py 中的 MemoryEntry 数据模型。
具体实现:VectorStore 使用 LanceDB 作为底层列式存储,同时支持本地和云存储(GCS/S3/Azure)。向量嵌入默认使用 Qwen3-Embedding-0.6B(1024 维),通过 SentenceTransformers 接口调用,支持 query/document 不对称编码。
Stage 2:在线语义合成
这是 SimpleMem 相比同类系统的一个关键差异化设计。合成发生在写入阶段,而非后台异步维护。
实现上,合成逻辑融入了 Stage 1 的 prompt 设计中:通过要求 LLM "生成足够多的记忆条目以确保所有信息被捕获",同时提供前一个窗口的记忆条目作为参考上下文,LLM 在生成时自然完成了信息的去重和合并。
并行处理:对于大规模对话数据,MemoryBuilder 使用 ThreadPoolExecutor 将多个窗口并行发送给 LLM 处理,默认最多 16 个并行 worker。
Stage 3:意图感知检索规划
与传统 RAG 的区别:传统系统对每个查询执行固定深度的检索;SimpleMem 则让 LLM 先分析查询意图,动态决定检索策略。
完整的检索流程:
1. 信息需求分析 — LLM 判断问题类型(事实型/时间型/关系型等),识别关键实体,确定所需信息的最小集合。
2. 生成靶向查询 — 根据分析结果,生成 1-4 条针对性查询(而非直接使用原始问题),避免冗余检索。
3. 并行多视图检索 — 同时在三层索引上执行搜索:
· 语义搜索:R_sem = Top-25(cos(E(q_sem), E(m_i)))
· 关键词搜索:R_lex = Top-5(BM25(q_lex, m_i))
· 结构化搜索:R_sym = Top-5({m_i | Meta(m_i) ⊨ q_sym})
4. 结果合并去重 — 按 entry_id 去重:C_q = R_sem ∪ R_lex ∪ R_sym
5. 智能反思机制 — 可选的 1-2 轮反思循环:
· LLM 评估当前检索结果是否足以回答问题
· 若不足,分析缺失的信息类型,生成补充查询
· 再次检索并合并结果
这种设计使得简单问题只需一次浅层检索,复杂问题自适应地扩展检索深度。
开源地址
github.com/aiming-lab/Simple…

Feb 11

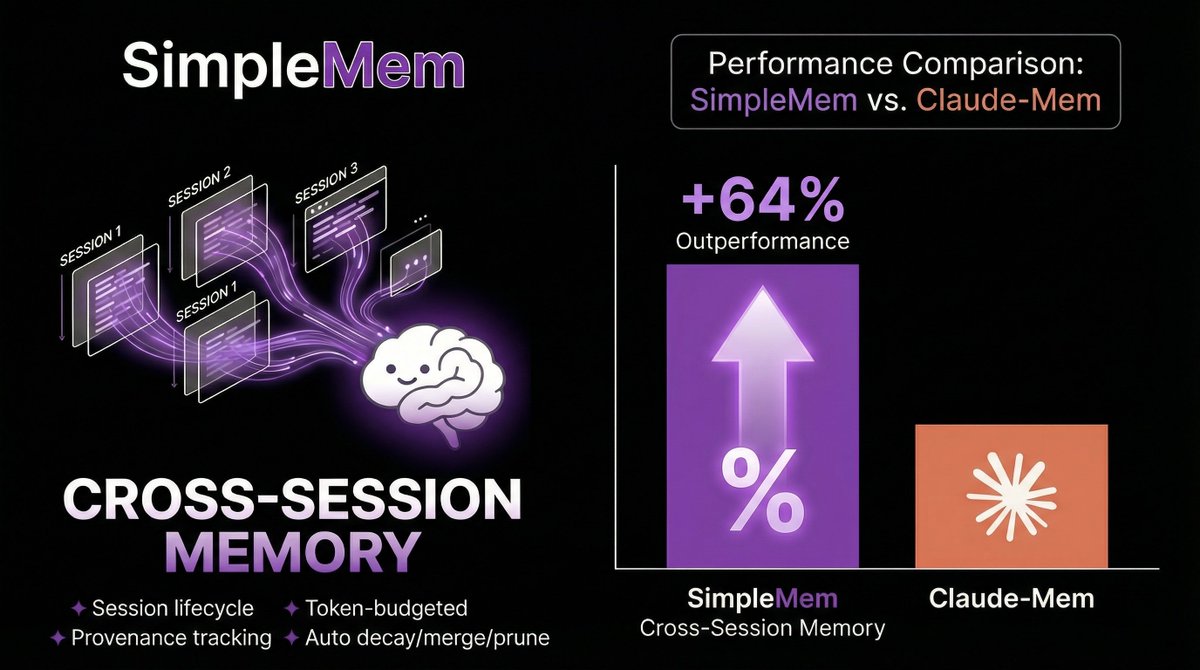
🧠 What if your AI agent remembered everything — across every conversation?
SimpleMem now supports Cross-Session Memory, outperforming Claude-Mem by 64%.
No more:
“Can you remind me what we decided last time?”
Your agent now automatically recalls:
• past decisions
• learned strategies
• key observations
Built-in:
✨ Lifecycle management
✨ Token-aware context injection
✨ Memory provenance tracking
✨ Auto decay / merge / pruning
Open source. Production-ready.
🔗 github.com/aiming-lab/Simple…
@JiaqiLiu835914 @cihangxie @richardxp888 @lillianwei423
3
20
91
10,698

Jan 30
Have you looked at QMD (github.com/tobi/qmd) as well? There's so much to learn and read, but this is good. Tobi @tobi has been doing interesting things & I love his hair style. I've been using an embedded VectorStore in my mobile application which I'll launch soon.
1
3
554
Jan 12
New blog post alert 🚨
"Amazon Nova Multimodal Embeddings with Amazon S3 Vectors & #AWS #Java SDK – Part 1 Introduction".
We introduce the Amazon Nova 2 Multimodal Embeddings & Amazon S3 Vectors & give an overview of their key features.
#VectorStore #GenAI
vkazulkin.com/amazon_nova_2_…
7
2,426


24 Dec 2025
linghua jin This creates true collaboration: Researcher grounds in facts (RAG), critic ensures quality, writer synthesizes. In production, add more agents (e.g., fact-checker with web tool) or structured outputs for reliable routing.This pattern scales to complex tasks like research papers, code debugging teams, or enterprise workflows. If you want extensions (e.g., hierarchical teams, human-in-loop, or full tool integration), let me know! 🚀angGraph excels at building multi-agent systems by defining multiple specialized agents as nodes in a graph, with a supervisor/orchestrator managing the flow. This creates collaborative workflows where agents handle distinct roles (e.g., researcher, critic, writer) and pass state between them.A classic pattern is the Supervisor-Agent Team (inspired by LangChain/LangGraph docs and popular 2025 tutorials): A supervisor agent decomposes tasks, routes to worker agents (e.g., one for retrieval/RAG, one for analysis, one for synthesis), and decides when to finalize.Key Benefits for Multi-Agent in LangGraphState Sharing: All agents access/modify a shared state (e.g., messages, retrieved docs, research notes).
Hierarchical Control: Supervisor uses conditional routing to delegate and loop.
Scalability: Easy to add agents (e.g., fact-checker, tool specialist).
Persistence: Checkpointing for long-running research tasks.
Full Working Example: Multi-Agent Research Team (Agentic RAG Style)This example creates a team for complex queries:Researcher Agent: Handles retrieval (RAG tool).
Critic Agent: Grades/Reflects on quality.
Writer Agent: Generates final answer.
Supervisor Agent: Routes between them, decides when done.
Assumes LangGraph, LangChain, OpenAI, and a vector store (Chroma). Install: pip install langgraph langchain langchain-openai chromadb.pythonfrom typing import Literal, TypedDict, Annotated, List
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.sqlite import SqliteSaver
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langchain_core.tools import tool
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
import operator
# Setup retriever (mock docs)
embeddings = OpenAIEmbeddings()
vectorstore = Chroma(collection_name="multi_rag", embedding_function=embeddings)
vectorstore.add_texts([
"LangGraph is a framework for building stateful multi-agent systems.",
"RAG improves LLM accuracy by retrieving external knowledge.",
"Multi-agent collaboration reduces hallucinations."
])
@tool
def retrieve(query: str) -> str:
"""Retrieve relevant documents."""
docs = vectorstore.similarity_search(query, k=3)
return "\n\n".join([doc.page_content for doc in docs])
tools = [retrieve]
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
llm_with_tools = llm.bind_tools(tools)
# Shared State
class AgentState(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
next: str # Who to route to next
# Worker Agents
def researcher(state: AgentState):
messages = state["messages"]
response = llm_with_tools.invoke(messages)
return {"messages": [response]}
def critic(state: AgentState):
# Simple critique: ask LLM to evaluate relevance
last_msg = state["messages"][-1].content
critique_prompt = f"Critique this research output for relevance and completeness:\n{last_msg}\nSuggest improvements if needed."
response = llm.invoke(critique_prompt)
return {"messages": [AIMessage(content=f"Critique: {response.content}")]}
def writer(state: AgentState):
messages = state["messages"]
write_prompt = f"Synthesize a clear, final answer using all prior research:\n{messages[-3:]}" # Last few exchanges
response = llm.invoke(write_prompt)
return {"messages": [response]}
# Supervisor (routes and decides end)
members = ["researcher", "critic", "writer"]
system_prompt = (
f"You are a supervisor managing a team: {', '.join(members)}. "
"Route the task to the best agent or FINISH when complete. "
"Only route to one at a time. Use FINISH when the writer has produced a final answer."
)
options = ["FINISH"] members
def supervisor(state: AgentState):
messages = state["messages"]
supervisor_chain = llm.bind_tools([]) # No tools needed
response = supervisor_chain.invoke(
[{"role": "system", "content": system_prompt}] messages
)
# Parse next route (in real: use structured output or tool calling)
route = response.content.lower()
next_agent = "FINISH"
for member in members:
if member in route:
next_agent = member
break
return {"next": next_agent, "messages": [response]}
# Build Graph
workflow = StateGraph(AgentState)
workflow.add_node("supervisor", supervisor)
workflow.add_node("researcher", researcher)
workflow.add_node("critic", critic)
workflow.add_node("writer", writer)
# Routing from supervisor
workflow.set_entry_point("supervisor")
for member in members:
workflow.add_edge(member, "supervisor") # Always return to supervisor
# Conditional routing
def route_next(state: AgentState):
return state["next"]
workflow.add_conditional_edges(
"supervisor",
route_next,
{"researcher": "researcher", "critic": "critic", "writer": "writer", "FINISH": END}
)
# Compile with memory
memory = SqliteSaver.from_conn_string(":memory:")
graph = workflow.compile(checkpointer=memory)
# Run example
config = {"configurable": {"thread_id": "team1"}}
inputs = {"messages": [HumanMessage(content="Explain how multi-agent systems improve RAG accuracy.")]}
for event in graph.stream(inputs, config):
for key, value in event.items():
if key != "__end__":
print(f"{key.upper()}: {value.get('messages', [-1]).content[:200]}...\n")
How It WorksUser query → Supervisor decides first agent (likely researcher).
Researcher retrieves docs → Returns to supervisor.
Supervisor routes to critic → Critique → Back.
Eventually routes to writer → Final answer → Supervisor sees "FINISH" → Ends.
Loop continues until supervisor chooses FINISH.
2
3
40

21 Dec 2025
🎄a-blog cms Advent Calendar 2025
20日目の記事は、アップルップルの永富敬千さん⭐️
「AI 拡張アプリを少しイジって OpenAI API の Vector Store を使ってみた」
ngtmtkyk.com/extension-ai-se…
最近どんどん進化を続ける AI を a-blog cms で活用ために OpenAI API の VectorStore を使ってみたお話です。
#ablogcms
👇a-blog cms Advent Calendar 2025 のURLはスレッドに
1
8
114

19 Dec 2025
I saw an Akamai blog float by, and they used a "Windows Binaries Vectorstore" to semantically search for samples impacted by a CVE. I hadn't seen this logic before, so I built a pipeline to look for clusters/similarities in malware: mez0.cc/posts/malvecdb/
2
17
59
10,213

19 Dec 2025
a-blog cms のアドベントカレンダー 20日目の記事を公開しました。
OpenAI API の VectorStore を使って AI検索してみた内容です。
ngtmtkyk.com/extension-ai-se…
adventar.org/calendars/11394
#ablogcms #adventcalendar
1
5
229

27 Nov 2025
Day 1
Todays learnings :
•Understood how Chroma actually stores vectors and why order alignment matters.
• Learned that Chroma isn’t directly compatible with Gemini embeddings unless you create your own embedding class.
• Built a custom embedding wrapper to make LangChain Chroma Gemini work together.
• Converted the vectorstore into a retriever and finally saw how real RAG pipelines come together.
1
9
240

25 Nov 2025
Jour 36:
- Mise en place des classes QuickRag et VectorStore du mon petit package QuickRag
- Implémentation de LA méthode pour créer un RAG
super simplement ( pas opti mais bon c'est le debut )
- Début de js : types des variables , condition et boucles
Keep grinding !
2
157