
Oda a Pedro Rodríguez. Un homenaje a la persistencia. #winner youtu.be/SLls8aeiEQU?si=8J9D… via @videoworld
12

May 15
Excited to share our new survey paper: the first comprehensive survey on Vision World Model (VWM), a joint effort by researchers from BJTU, ByteDance, Tencent, NUS, and more.
🌟 From Seeing to Knowing the World: A Survey of Vision World Models
🚀 Our core message is a paradigm shift toward vision-centric world modeling:
Vision should not be treated merely as an input modality. It should be the primary driver of how world models are represented, learned, and evaluated.
🌈 This is also the longstanding view behind our #VideoWorld series: learning directly from visual observation and interaction offers a scalable path for AI agents to acquire world knowledge, laying the foundation for higher machine intelligence.
🤔 Why Vision World Models?
From biological evolution to human intelligence, vision has been central to learning about the world through observation and interaction. AI should have this capability too. This motivates Vision World Models: models that learn world knowledge from visual data and simulate future world states conditioned on interaction.
🤖 In this survey, we thoroughly review 400 recent papers and provide a vision-centric roadmap for Vision World Models, covering architectures, functional roles, applications, evaluation protocols, datasets, benchmarks, and future outlook.
Key takeaways:
1️⃣ Vision is a fundamental basis of intelligence and a rich source of world knowledge. We advocate vision-centric world modeling, where AI learns the physical and causal principles behind world evolution from visual data.
2️⃣ We propose a unified framework that decomposes Vision World Models into three core components: Vision Encoding → Knowledge Learning → Controllable Simulation and organize current methods into 4 major families and 7 representative architectures.
3️⃣ We review evaluation from three levels: Visual Quality, Physical Plausibility, and Task Performance, and group datasets/benchmarks into foundational world modeling and domain-specific world modeling.
4️⃣ We outline three directions for next-generation world models: Re-grounding in physical and causal knowledge, Re-evaluating beyond visual appearance, and Re-scaling toward generalist, reliable, and interaction-aware world models.
Check out our paper and the continuously updated curated list of Vision World Model papers for more details!
📄 Paper: aiworldlab.github.io/survey/…
🌐 Project Page: aiworldlab.github.io/survey/
📚 Curated VWM Paper List: github.com/AIWorldLab/Awe
#VisionWorldModel #WorldModel #Survey #VideoWorld #EmbodiedAI #Robotics #AI #CV

7
23
151
22,745

Mar 19
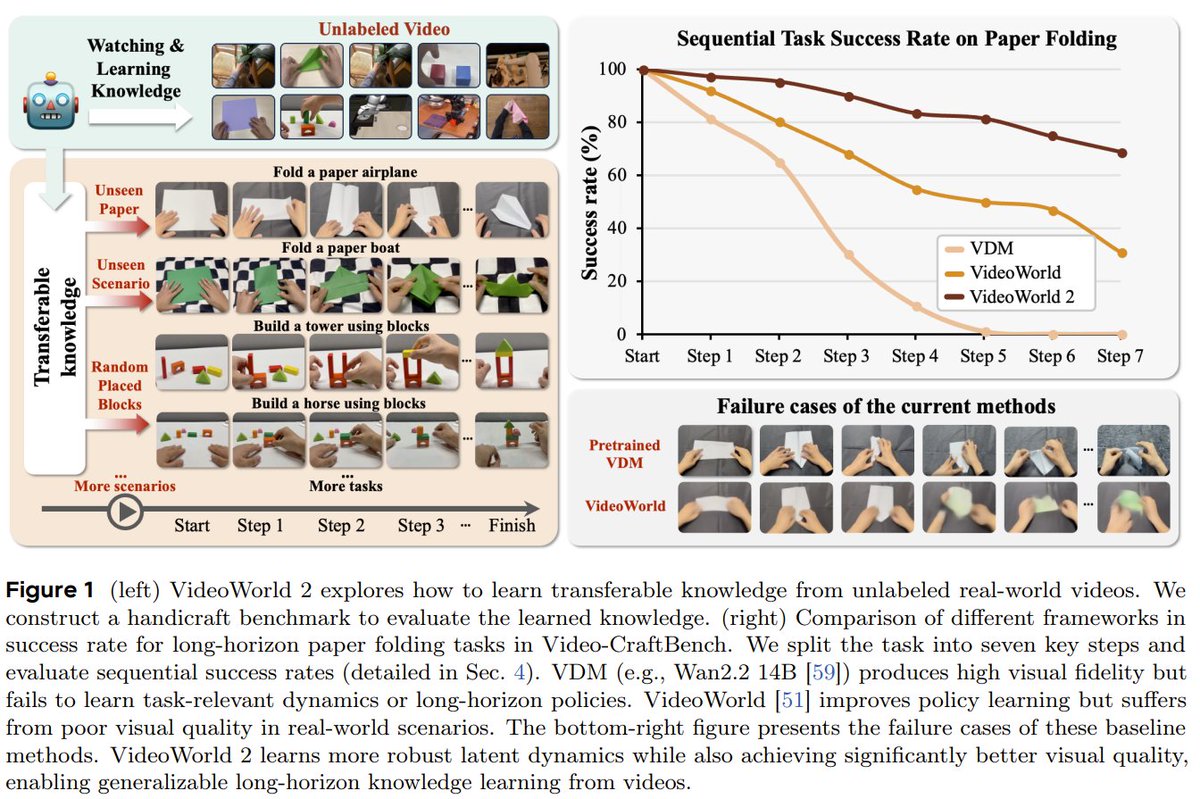
Wow, AI could learn complex, long-term tasks and transfer that knowledge, just by watching real-world videos!
Researchers from ByteDance Seed and Beijing Jiaotong University just unveiled VideoWorld 2.
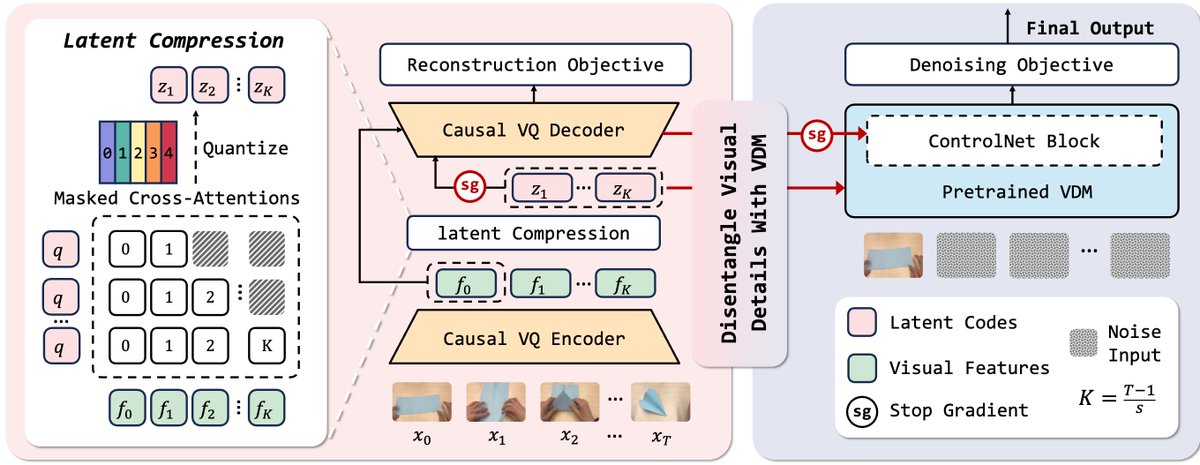
Their new dynamics-enhanced Latent Dynamics Model wisely separates visual information from core action dynamics. This lets AI learn essential task mechanics from raw video, enabling long-horizon reasoning.
VideoWorld 2 achieves up to a 70% improvement in challenging real-world handcraft tasks and dramatically boosts robotic manipulation performance on CALVIN, demonstrating impressive cross-domain generalization from raw video data.
VideoWorld 2: Learning Transferable Knowledge from Real-world Videos
Paper: arxiv.org/abs/2602.10102
Project: maverickren.github.io/VideoW…
Our report: mp.weixin.qq.com/s/FX8XjEKRr…
📬 #PapersAccepted by Jiqizhixin
Feb 11

🎬 Toward a Cambrian Moment for Visual Intelligence.
Can AI learn complex real-world skills from video alone, just like humans learn paper folding or LEGO by watching?
🚀 ByteDance Seed and BJTU present VideoWorld2, a simple generative model that masters complex, long-horizon real-world knowledge purely through visual data, without relying on language models.
👩🏫 As also noted by @drfeifei, the emergence of visual capability sparked the Cambrian Explosion and enabled a rapid leap in intelligence. VideoWorld 2 explores this frontier by learning complex task knowledge directly from real-world videos. It reliably executes minute-long handcraft tasks such as paper folding and block building with far higher success rates, while current SOTA (e.g., Sora2, Veo3, Wan2.2) fail to execute them (over 70% improvement). It also demonstrates cross-domain transfer and strong scaling in robotics.
🌟 Continuing the vision of the #VideoWorld series, we believe that visual learning offers a scalable path toward agents that acquire knowledge the way humans do — by observing the world directly.
Our main contributions are:
👉 We first explore learning complex, long-horizon task knowledge directly from unlabeled real-world videos, identifying the disentanglement of visual appearance from task-critical dynamics as key to transferable skill acquisition.
👉 We propose VideoWorld 2, leveraging a dynamics-enhanced Latent Dynamics Model (dLDM) to extract task-critical dynamics, significantly outperforming SOTA video generation models on complex real-world tasks.
👉We construct Video-CraftBench, a large-scale handcraft video benchmark to advance research in visual knowledge learning and world modeling.
Check out our paper for more details and results!
[Project Page]: VideoWorld2.github.io/
[Arxiv]: arxiv.org/abs/2602.10102
[Code]: github.com/ByteDance-Seed/Vi…
#VideoWorld2 #VideoWorld #VisionLearning #Robotics #EmbodiedAI
1
9
43
4,755

Feb 21
Thrilled to share that VideoWorld 2 has been accepted to CVPR 2026! Huge congrats to the team 🎉🥳
⚡️ VideoWorld 2 is the first to learn complex, long-horizon tasks directly from real-world videos without relying on language models. It significantly outperforms sota video generation models (Veo3/Wan2/Sora2) and prior world models on minute-long handcraft tasks and generalizes to robotics.
🤖 Building on the vision of our #VideoWorld series, VideoWorld 2 and VideoWorld 1 reflect our belief that video learning offers a promising path for robotics to learn and act in the real world, much like how visual capability sparked the rise of biological intelligence in the Cambrian Explosion🌟
See you in Denver this summer! 🌞
📄 Paper: arxiv.org/abs/2602.10102
💻 Code: github.com/ByteDance-Seed/Vi…
(VideoWorld 1 @ CVPR2025: arxiv.org/abs/2501.09781)
#CVPR2026 #VideoWorld #EmbodiedAI #Robotics #AI #CV
Feb 11
🎬 Toward a Cambrian Moment for Visual Intelligence.
Can AI learn complex real-world skills from video alone, just like humans learn paper folding or LEGO by watching?
🚀 ByteDance Seed and BJTU present VideoWorld2, a simple generative model that masters complex, long-horizon real-world knowledge purely through visual data, without relying on language models.
👩🏫 As also noted by @drfeifei, the emergence of visual capability sparked the Cambrian Explosion and enabled a rapid leap in intelligence. VideoWorld 2 explores this frontier by learning complex task knowledge directly from real-world videos. It reliably executes minute-long handcraft tasks such as paper folding and block building with far higher success rates, while current SOTA (e.g., Sora2, Veo3, Wan2.2) fail to execute them (over 70% improvement). It also demonstrates cross-domain transfer and strong scaling in robotics.
🌟 Continuing the vision of the #VideoWorld series, we believe that visual learning offers a scalable path toward agents that acquire knowledge the way humans do — by observing the world directly.
Our main contributions are:
👉 We first explore learning complex, long-horizon task knowledge directly from unlabeled real-world videos, identifying the disentanglement of visual appearance from task-critical dynamics as key to transferable skill acquisition.
👉 We propose VideoWorld 2, leveraging a dynamics-enhanced Latent Dynamics Model (dLDM) to extract task-critical dynamics, significantly outperforming SOTA video generation models on complex real-world tasks.
👉We construct Video-CraftBench, a large-scale handcraft video benchmark to advance research in visual knowledge learning and world modeling.
Check out our paper for more details and results!
[Project Page]: VideoWorld2.github.io/
[Arxiv]: arxiv.org/abs/2602.10102
[Code]: github.com/ByteDance-Seed/Vi…
#VideoWorld2 #VideoWorld #VisionLearning #Robotics #EmbodiedAI
9
74
8,113

Remember watching that on VHS. Though I have no idea why Videoworld in Westbury Park, Newcastle Under Lyme had a copy. Nor why my parents let me select it for rent.
3
872
Feb 11
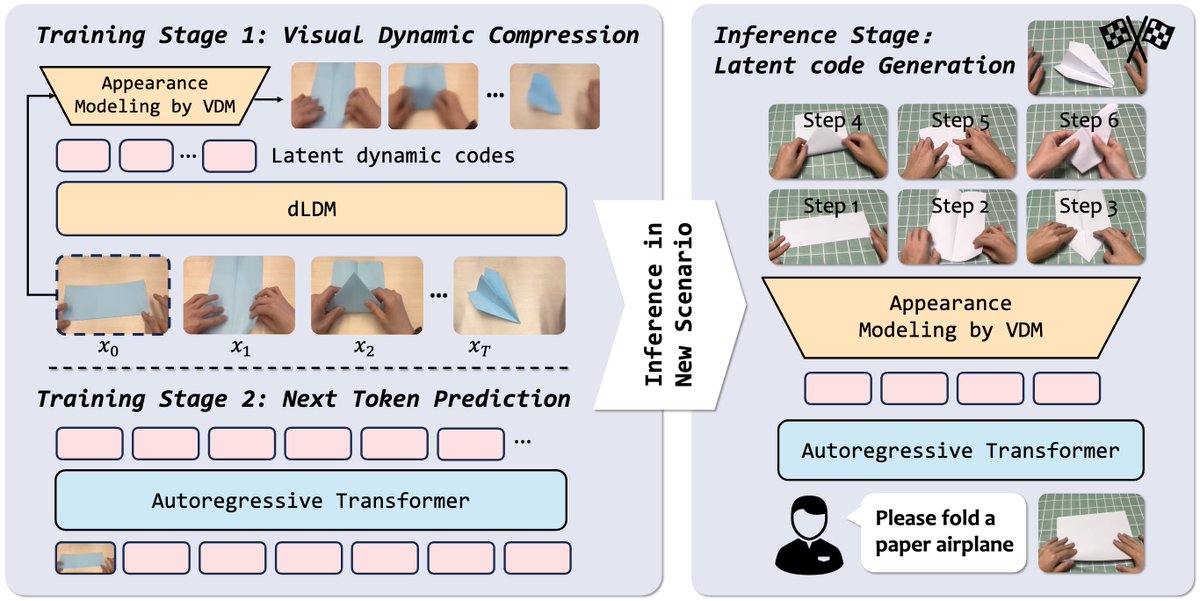
8/N Without any text or action labels, VideoWorld 2 completes minute-long handcraft tasks such as paper folding and block building across unseen environments. It also demonstrates multi-task, cross-domain robotic manipulation after large-scale video pretraining.
We believe visual learning provides a scalable path toward agents that acquire knowledge the way humans do — by observing the world directly.
1
1
3
309
Feb 11
7/N At the core of VideoWorld 2 is a dynamics-enhanced Latent Dynamics Model (dLDM). It extracts compact, transferable action dynamics from visual changes, improving long-horizon stability and generalization.
1
1
3
242
Feb 11
6/N Building on this insight, we propose VideoWorld 2, which robustly learns from real-world videos by mitigating appearance interference and focusing on task-relevant dynamics.
1
1
3
263
Feb 11
4/N However, extending this paradigm to real-world videos is far more challenging. When exposed to minute-long, multi-step real-world tasks, VideoWorld struggles to extract core task knowledge or generalize to new environments. Similarly, even SOTA video models like Sora2, Veo3, and Wan2.2 fail to faithfully execute such tasks.
1
1
4
309
Feb 11
3/N Our previous work, VideoWorld, was among the first to explore learning knowledge from synthetic videos. It showed that video generation models can learn reasoning and planning purely from visual signals.
1
1
4
362
Feb 11
🎬 Toward a Cambrian Moment for Visual Intelligence.
Can AI learn complex real-world skills from video alone, just like humans learn paper folding or LEGO by watching?
🚀 ByteDance Seed and BJTU present VideoWorld2, a simple generative model that masters complex, long-horizon real-world knowledge purely through visual data, without relying on language models.
👩🏫 As also noted by @drfeifei, the emergence of visual capability sparked the Cambrian Explosion and enabled a rapid leap in intelligence. VideoWorld 2 explores this frontier by learning complex task knowledge directly from real-world videos. It reliably executes minute-long handcraft tasks such as paper folding and block building with far higher success rates, while current SOTA (e.g., Sora2, Veo3, Wan2.2) fail to execute them (over 70% improvement). It also demonstrates cross-domain transfer and strong scaling in robotics.
🌟 Continuing the vision of the #VideoWorld series, we believe that visual learning offers a scalable path toward agents that acquire knowledge the way humans do — by observing the world directly.
Our main contributions are:
👉 We first explore learning complex, long-horizon task knowledge directly from unlabeled real-world videos, identifying the disentanglement of visual appearance from task-critical dynamics as key to transferable skill acquisition.
👉 We propose VideoWorld 2, leveraging a dynamics-enhanced Latent Dynamics Model (dLDM) to extract task-critical dynamics, significantly outperforming SOTA video generation models on complex real-world tasks.
👉We construct Video-CraftBench, a large-scale handcraft video benchmark to advance research in visual knowledge learning and world modeling.
Check out our paper for more details and results!
[Project Page]: VideoWorld2.github.io/
[Arxiv]: arxiv.org/abs/2602.10102
[Code]: github.com/ByteDance-Seed/Vi…
#VideoWorld2 #VideoWorld #VisionLearning #Robotics #EmbodiedAI
3
29
202
26,931

16 Dec 2025
🟩Los jefes del cortijo y el presentador allí en medio, sin videoworld
🟡Un pino chuchurrio con las bolas x los suelos
💜Posicionamientos, salvaciones y expulsión del tirón, al otro lado del salón
Esto es la h0stia en lata 🤣 #LaCasaDeLosGemelos2D9

4
13
2,669

30 Oct 2025
very good piece on mass literacy as a fragile political project, one that capitalist elites no longer any value in
we are reentering the mysterious, hallucinatory world of Peasant Mindset (VIDEOWORLD)

28 Oct 2025

We’ve entered a second age of orality. The written word’s influence is fading, replaced by short-form video slop. But if smartphones are to blame, so are the elites: as Noah McCormack argues, the history of literacy is the history of class.
thebaffler.com/salvos/we-use…
2
1
9
584

26 Sep 2025
Digital media/videoworld, NGOs and possibly even some more on my own case next week
24 Sep 2025

Tom Studans now going door-to-door asking media organisations to substantively cover welfare rights issues
2
14
1,360
1 Aug 2025
please read my friend @RevanOluklu's phenomenal, mind-altering essay on our terrifying new existence in VideoWorld - a world that has reshaped our temporal experience alongside cognition, politics, and cinema. This even helped me understand Tenet a bit more


1
3
9
651

22 May 2025
Nicht nur da.🙄
Bei VideoWorld hatte uns mal ein Kunde in der 18er-Abteilung in ne Videohülle geschissen.
Hatte fast ne Woche gedauert, bis wir die Quelle des Gestanks gefunden hatten.🤢
1
4
151

20 May 2025
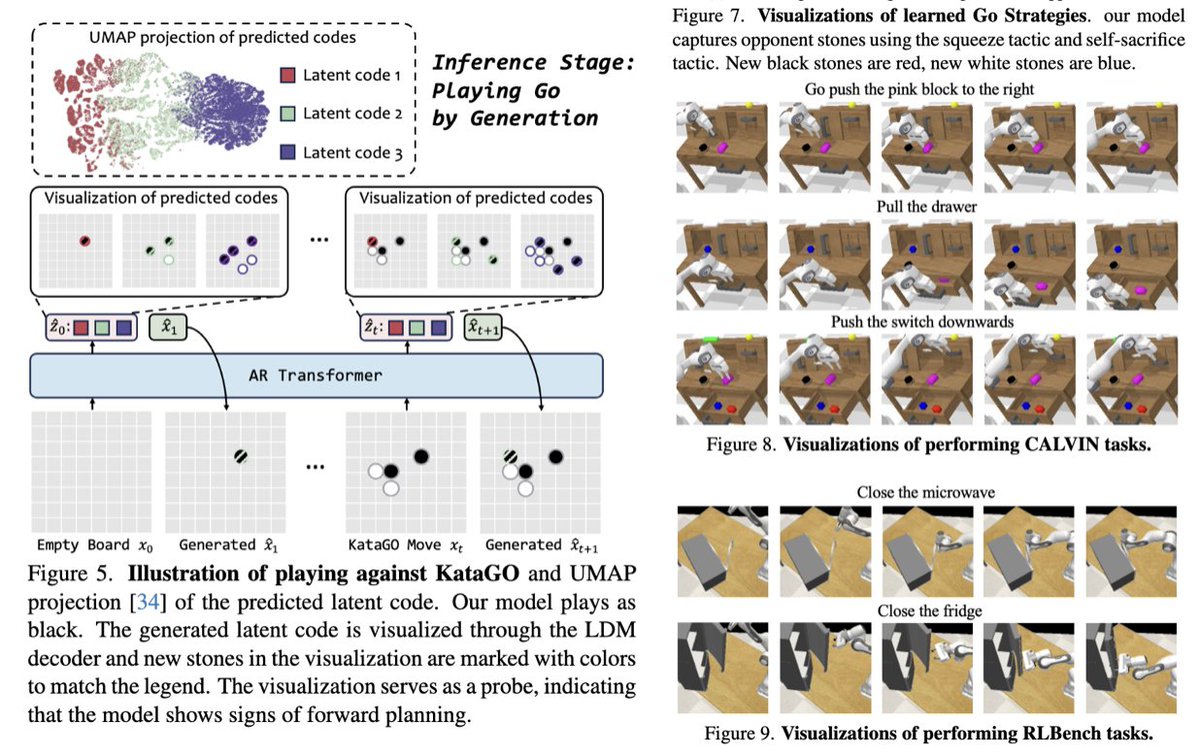
Now there is very likely some RL component in post-train. VideoWorld (ByteDance) do mention a series of pre-determined tasks with RL rewards, highly formal in nature, but knowing DeepMind wouldn't be surprised they cracked something more generalist. arxiv.org/pdf/2501.09781
1
1
4
959

4 May 2025
bscscan.com/token
/0x26527be17a0fa6ded74c13b6ed
85c828e5764444
pancakeswap.finance/swap
?outputCurrency=
0x26527be17a0fa6ded74c13b6ed8
5c828e5764444
Join the movement. Meme, laugh, earn.
#VIDW #VideoWorld #BSC #MemeCoin #Crypto #binance #kripto #memecoin

5
4
96
4 May 2025
bscscan.com/token
/0x26527be17a0fa6ded74c13b6ed
85c828e5764444
pancakeswap.finance/swap
?outputCurrency=
0x26527be17a0fa6ded74c13b6ed8
5c828e5764444
Join the movement. Meme, laugh, earn.
#VIDW #VideoWorld #BSC #MemeCoin #Crypto #binance #kripto #memecoin

15
8
163