
Feb 11
🎬 Toward a Cambrian Moment for Visual Intelligence.
Can AI learn complex real-world skills from video alone, just like humans learn paper folding or LEGO by watching?
🚀 ByteDance Seed and BJTU present VideoWorld2, a simple generative model that masters complex, long-horizon real-world knowledge purely through visual data, without relying on language models.
👩🏫 As also noted by @drfeifei, the emergence of visual capability sparked the Cambrian Explosion and enabled a rapid leap in intelligence. VideoWorld 2 explores this frontier by learning complex task knowledge directly from real-world videos. It reliably executes minute-long handcraft tasks such as paper folding and block building with far higher success rates, while current SOTA (e.g., Sora2, Veo3, Wan2.2) fail to execute them (over 70% improvement). It also demonstrates cross-domain transfer and strong scaling in robotics.
🌟 Continuing the vision of the #VideoWorld series, we believe that visual learning offers a scalable path toward agents that acquire knowledge the way humans do — by observing the world directly.
Our main contributions are:
👉 We first explore learning complex, long-horizon task knowledge directly from unlabeled real-world videos, identifying the disentanglement of visual appearance from task-critical dynamics as key to transferable skill acquisition.
👉 We propose VideoWorld 2, leveraging a dynamics-enhanced Latent Dynamics Model (dLDM) to extract task-critical dynamics, significantly outperforming SOTA video generation models on complex real-world tasks.
👉We construct Video-CraftBench, a large-scale handcraft video benchmark to advance research in visual knowledge learning and world modeling.
Check out our paper for more details and results!
[Project Page]: VideoWorld2.github.io/
[Arxiv]: arxiv.org/abs/2602.10102
[Code]: github.com/ByteDance-Seed/Vi…
#VideoWorld2 #VideoWorld #VisionLearning #Robotics #EmbodiedAI
3
29
202
26,931

1 Sep 2023
Launching of Vision Science Academy's Exclusive Learning Centre - VSALC 🌟
September 2023
We are excited to announce a monumental addition to our educational offerings — the Vision Science Academy Learning Centre - VSALC. This specialised learning hub is designed to provide an array of exclusive courses that focus on the intriguing field of Vision Sciences.
Stay tuned for more information!
Visit our website 🌎: visionscienceacademy.org
#vision #visionscience #visionresearch #visioneducation #vsalc #eye #eyescience #visionacademy #visionlearning #optomcourses #eyecare #eyehealth #eyesight #optometry #optics #ophthalmology #neuroscience #neurovision #newcourse #moptom #boptom #optom #education #sciencecourses #learning #learningcentre #bestcourse #visionscienceacademy #vsa #visionscience

2
43

23 Feb 2022
Another #SciCommJob! @visionlearning is hiring a Physical Science Education Editor and three Science Education Authors to help plan, write, edit, and launch website content.
Rate: $1100 per module for editor, $2000 per module for authors.
Deets: ow.ly/3mOl50HV1wQ

2

28 Jan 2021
Science Education Editor, Visionlearning, Three jobs #EarthScience, #LifeScience, and #PhysicalScience to support instruction that is aligned with the Next Generation Science Standards (NGSS) to better meet the needs of future teachers. #physicsjobs
jobs.physicstoday.org/jobs/1…
1
1

25 Jan 2021
Hey #SciComm community, here's a PAID opportunity as freelance science editor for visionlearning.com, an open-resource STEM site with materials for #highSchool and #HigherEd
@visionlearning
#AcademicChatter #academicjobsearch #STEMJobs
1
2
2

19 Jan 2021
VSBLTY (CSE $VSBY, OTC $VSBGF) Investor Webinar TODAY @ 2PM ET. Management will be answering live questions at the end of the webinar.
Register HERE: bit.ly/3bAdgIb
#ArtficialIntelligence #Techstocks #technology #AI #Security #Visionlearning #SaaS #biometrics #tech

2
13 Jan 2021
VSBLTY (CSE $VSBY, OTC $VSBGF) Investor Webinar on Jan 19 @ 2PM ET.
Management will be answering live questions at the end of the webinar. Register HERE: bit.ly/3bAdgIb
#ArtficialIntelligence #Techstocks #technology #AI #Security #Visionlearning #SaaS #biometrics #tech

ALT VSBLTY (CSE $VSBY, OTC $VSBGF) Investor Webinar on Jan 19 @ 2PM ET
8

6 Oct 2020
A resource for teaching the N cycle. Either to further your own understanding or to use with students...@chatbiology
The Nitrogen Cycle | Earth Science | Visionlearning visionlearning.com/en/librar…
3
17
30 Jun 2020
One of the projects @JJCPRISM collaborates with is @visionlearning, a free resource for students and teachers in #STEM visionlearning.com/en
1
1
2

7 Apr 2020
Thanks! I just wrote the module, the images were by @visionlearning :)
7 Apr 2020

In lab meeting today my colleague made me aware of some beautiful DNA replication images by @nathanlents: visionlearning.com/en/librar…
1
3

8 Jan 2020
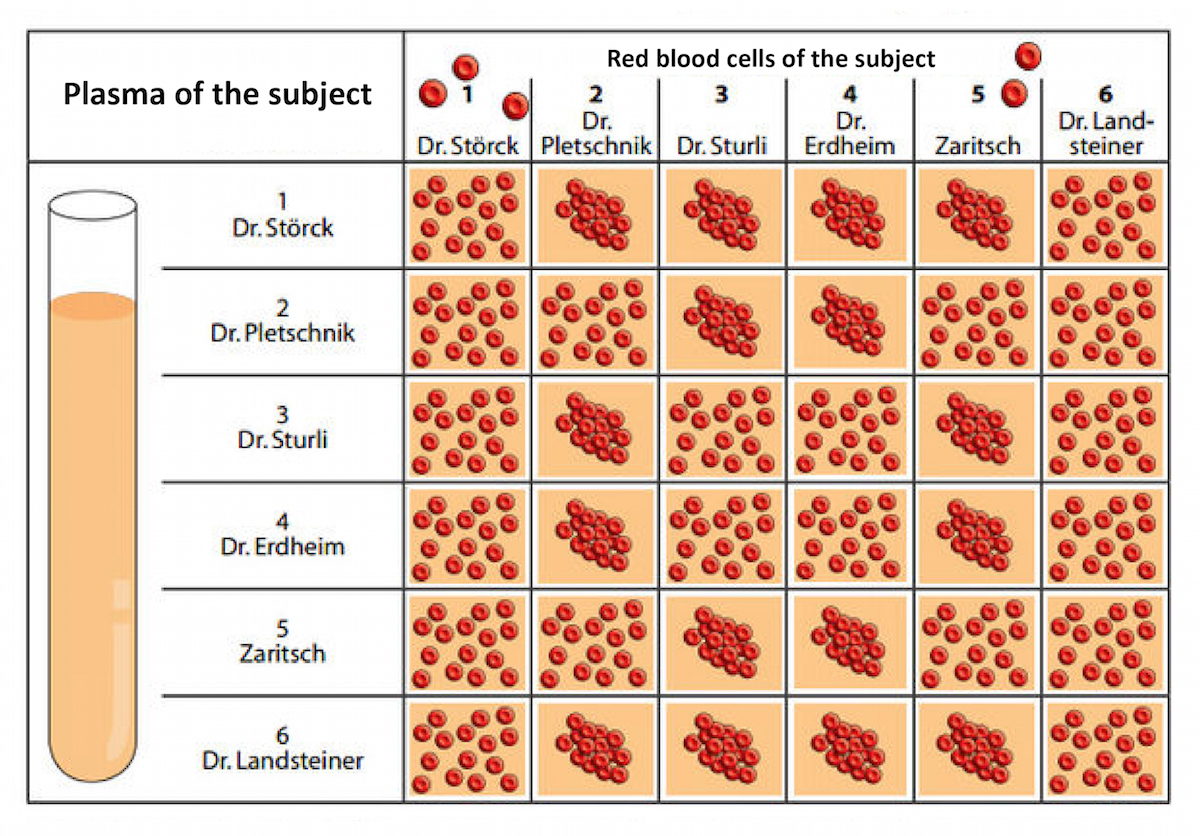
By mixing red cells and plasma taken from several of his lab staff, Landsteiner discovered what he initially called the “ABC” blood group system. Each person's plasma agglutinated RBCs from some people but not from others. (Image source: VisionLearning/Biologie/Schulbuch-O-Mat)/4
1
2
9

24 Dec 2019
Visionlearning disagrees with you re ethics being outside of science

1
3

6 Nov 2019
Buongiorno amici 😃
Ieri ho avuto il piacere di far visita a un'innovativa azienda della provincia di Padova: #VisiOnLearning.
Un luogo dove la fantasia si trasforma in realtà!
#MadeInItaly
@FratellidItaIia @GiorgiaMeloni @EGardini



2
3
23
18 Apr 2019
Besides memorizing the phases of #mitosis, what do bio students learn about the cell cycle & cell division? Here is a little something I wrote for @visionlearning. I got my PhD in this area and I sometimes miss it! (G1 phase for life!) #cancer #STEM visionlearning.com/en/librar…

2
2
15 Apr 2019
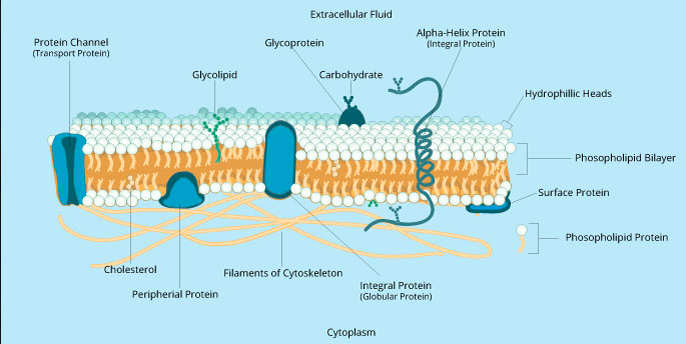
With that pesky membrane on the outside, how do things get in & out of our cells? Here's a short summary of passive/active transport, pumps, channels, diffusion that I wrote for @visionlearning. #cellbiology #biochemistry #Scienceeducation visionlearning.com/en/librar…
3
8
15 Apr 2019
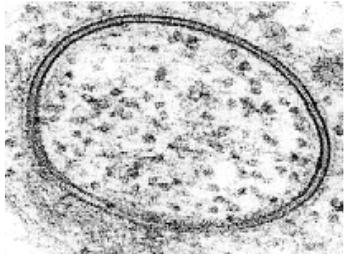
Back to basics... #membranes! These curious biochemical structures are, in some ways, the most essential component in the #evolution of life, allowing "contained chemistry" to emerge. Here's a brief intro from @visionlearning #biology #STEMed visionlearning.com/en/librar…
3
12
12 Apr 2019
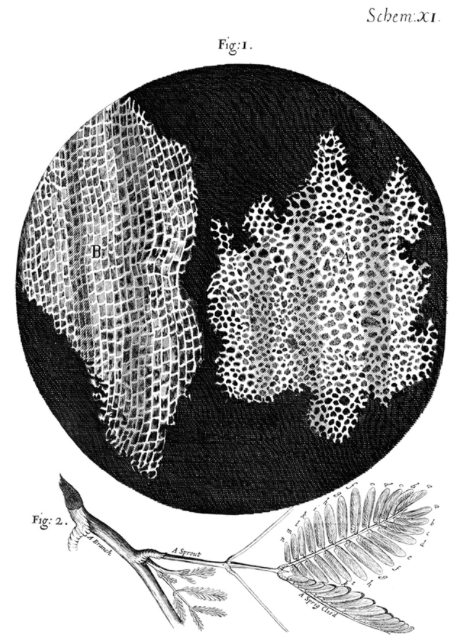
I don't care how old, jaded, or famous you are as a scientist, reading about the early microscopists as they first discovered cells will always be thrilling. (via @visionlearning) #microbiology #STEMeducation #cellbiology visionlearning.com/en/librar…
2
10
6 Apr 2019
How much do you know about #blood? Test your knowledge with this short module that @CosmicEvolution and I wrote for @visionlearning. We cover quite a bit! #STEM #health visionlearning.com/en/librar…
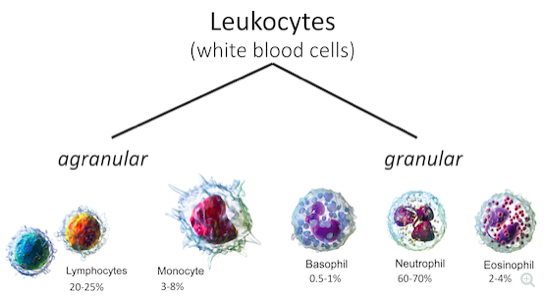
5
7
3 Apr 2019
We're going back to the basics with this module, an introduction to life's most creative, diverse, and interesting molecules: proteins. Check out this intro to #proteins on @visionlearning (by @cosmicevolution and me) #STEM #biology visionlearning.com/en/librar…
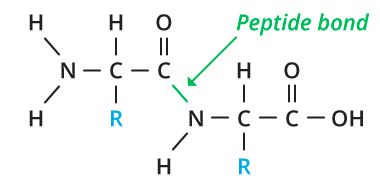
1
3
1 Apr 2019
Is photosynthesis a total mystery to you? Check out this little primer that I wrote for @visionlearning and I think you'll agree that #photosynthesis is kind of amazing! #biology #plants #STEMeducation visionlearning.com/en/librar…

2
3