
Are your A/B tests giving you clean and reliable data?
Probably not!
If you can't measure the full customer journey -- from first click to lifetime value -- you can't really say which variant earned you more money.
#ABTesting #MarketingAnalytics
3

Jun 13
🔬 Experimentation Frameworks for Prompts, Agents & Models at Scale — the critical continuous improvement layer that treats prompt/agent changes with the same rigor as code changes.
Just read this excellent capstone technical white paper from @aasaitech on hypothesis-driven experimentation, A/B testing, multi-variant, bandit, canary, shadow testing, guardrails, rollback, and data-driven iteration.
Key highlights: • 7-step end-to-end framework with continuous learning loop • Experiment types what to measure (technical: accuracy, hallucination rate, latency, cost; business: task completion, time-to-resolution, CSAT, ROI) • Infrastructure essentials (feature flags, observability, statistical analysis, dashboards) • Culture of experimentation: data over opinion, fail fast/learn fast, shared insights
This is the practical multiplier that makes the entire series (RAG, agents, edge deployment, observability, governance, etc.) evolve faster, safer, and with higher ROI in manufacturing and edge orchestration.
Full white paper infographic: x.com/aasaitech/status/20656…
How structured is your experimentation practice for prompts/agents — lightweight A/B tests, full bandit/canary pipelines with guardrails, or still mostly intuition-driven?
#LLMExperimentation #ABTesting #AgenticAI #IndustrialAI #ContinuousImprovement #ManufacturingAI #EdgeAI

9

🧪 A/B Testing Decoded!
Learn how to test APIs, UI components, and user experiences using real-world A/B testing strategies.
🚀 What?
🎯 Why?
⚙️ How?
Join Team Axiom for a live build session.
#ABTesting #APITesting #UIDesign #SoftwareDevelopment #AxiomTechGuru

2
4
6

Jun 11
📬 Want better results from Direct Mail? Test everything. Offers, formats & messaging can dramatically impact ROI. A/B testing helps you find what truly converts and generates more qualified leads.
🌐 mailingsunlimited.com/servic…
#DirectMail #ABTesting #LeadGeneration #Marketing


Jun 11
The first time I posted this joke, I left off the second punchline, because I wasn't sure if it worked better without it. Consider this a particularly roundabout kind of A/B testing. #comics #webcomics #monkeyfluids #abtesting

1
2
19

A/B testing is a marketing strategy where you test two versions of an asset against one another to see which one shows statistical improvement. - businesspartnermagazine.com/… - #Abtesting #Marketingstrategy


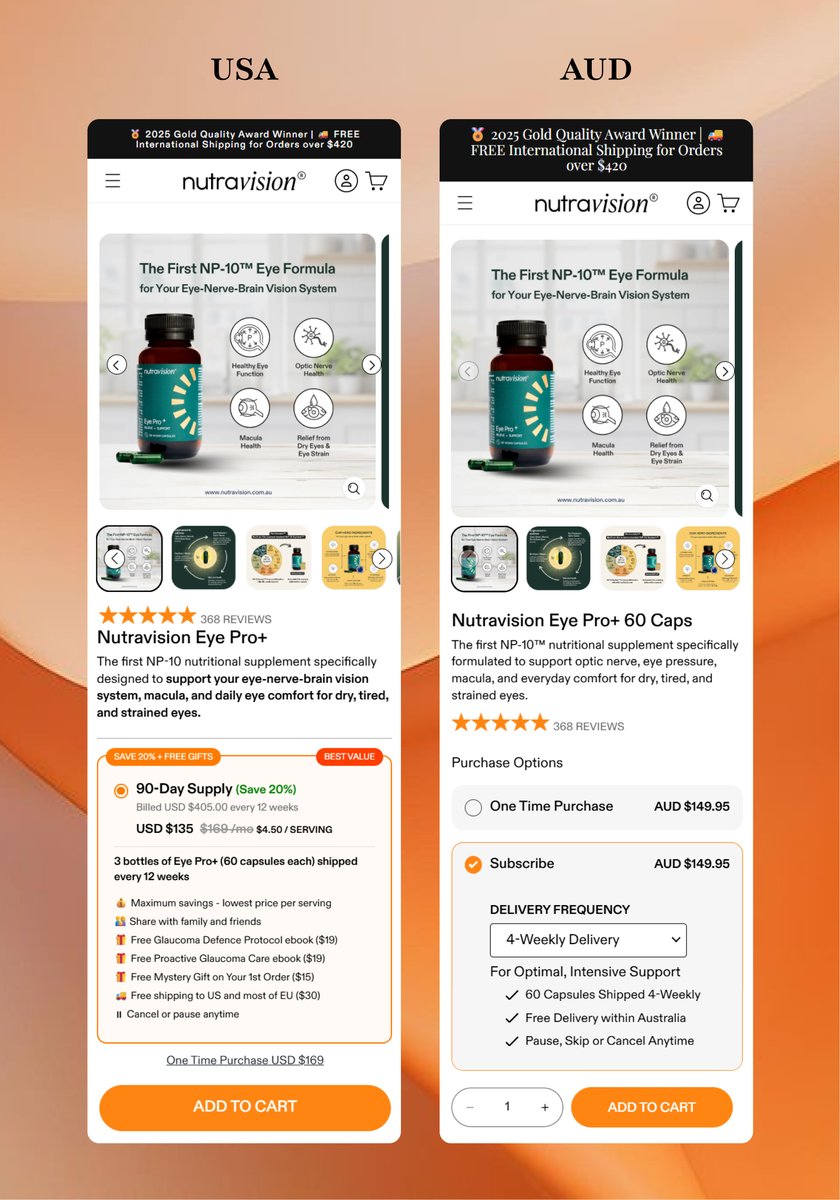
One product. Two markets. Two completely different purchase experiences.
🇺🇸 USA - 🇦🇺 Australia
Localization isn't just currency conversion—it's understanding customer psychology.
#ecommerce #ShopifyPartner #CRO #ABTesting #ShopifyDevelopment #DTCBrand #UserExperience #Shopify
1
24

🧪 Why A/B Testing Will Never Go Away
Think you’ve finally figured out the perfect social media post, email subject line, or ad creative? Think again.
🎥 Watch the full webinar in the Social Media Association Video Library: lnkd.in/gzJ4peDv
#ABTesting #DigitalMarketing
9

Small changes can lead to significant results.
In this example, Subject A uses urgency while Subject B focuses on curiosity and reward. Testing these two hooks reveals exactly what motivates the audience to click.
Follow for more data-driven marketing tips.
#abtesting

42



In 2026, VWO continues to lead as the go-to platform for data-driven website optimization.
With powerful A/B testing, AI-powered insights, heatmaps, session recordings, and seamless personalization, @VWO helps thousands of brands turn visitor behavior into measurable conversion wins—without needing deep coding expertise.
From smart experiment suggestions to full-funnel experimentation, it's the complete toolkit modern growth teams rely on.
Discover why it's still a top choice—check the full review for details.
digital-expert.online/en/bes…
#CRO #ABTesting #ConversionOptimization

2
2
25

May 29
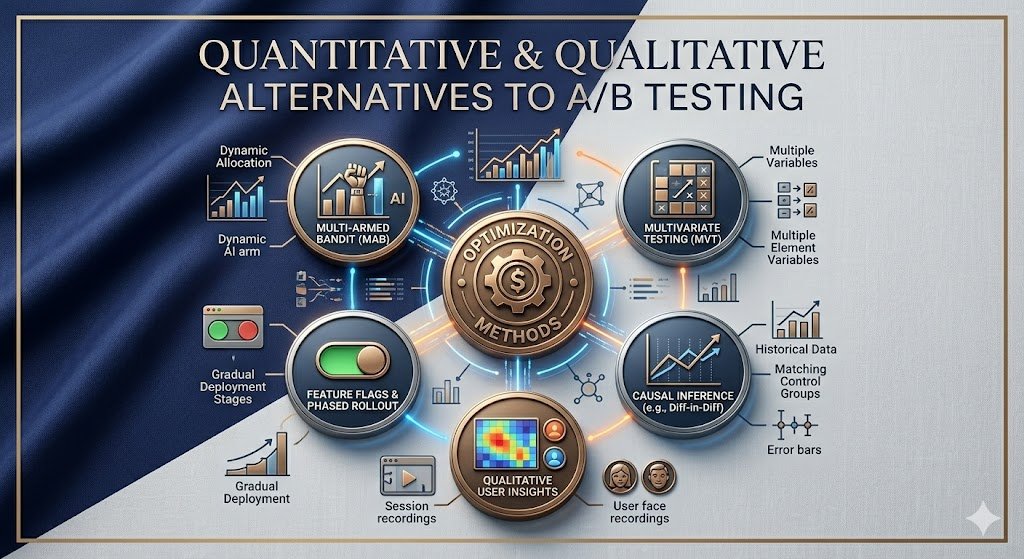
🚀 Beyond A/B Testing: Multi-Armed Bandit, MVT, Causal Inference, Phased Rollouts & User Insights — these methods are changing how teams optimize products. Which one are you using? #ABTesting #ProductGrowth #DataDriven #UX #Experimentation
2
9

Launching Sending Analytics for MigmaAI 🚀
You can now track campaigns in real time with:
• Opens & clicks
• Deliveries & bounces
• Unsubscribes & complaints
• Live activity graphs
• Geographic engagement analytics
• Per-recipient logs
• Built-in A/B test analytics
MigmaAI also learns from campaign performance and A/B testing results to help improve future campaigns automatically.
The more you send, the smarter it gets.
#EmailMarketing #AI #SaaS #MarketingAutomation #EmailAnalytics #ABTesting #ArtificialIntelligence #Startup #ProductLaunch #EmailCampaigns

1
4
58

May 27
LAUNCHED: Cumulative Impact Effect Distribution in Datadog Experiments
Most experimentation teams can tell you which tests won, very few can confidently tell you how much they’ve actually moved a KPI over time.
New in @datadoghq Experiments:
• Cumulative impact reporting across shipped experiments
• Noise-adjusted effect distributions
• Built-in correction for the “winner’s curse”
• Better guidance for MDEs and future experiment strategy
Available today in Datadog Experiments.
#experimentation #featureflags #abtesting #datadog #developers
3
73

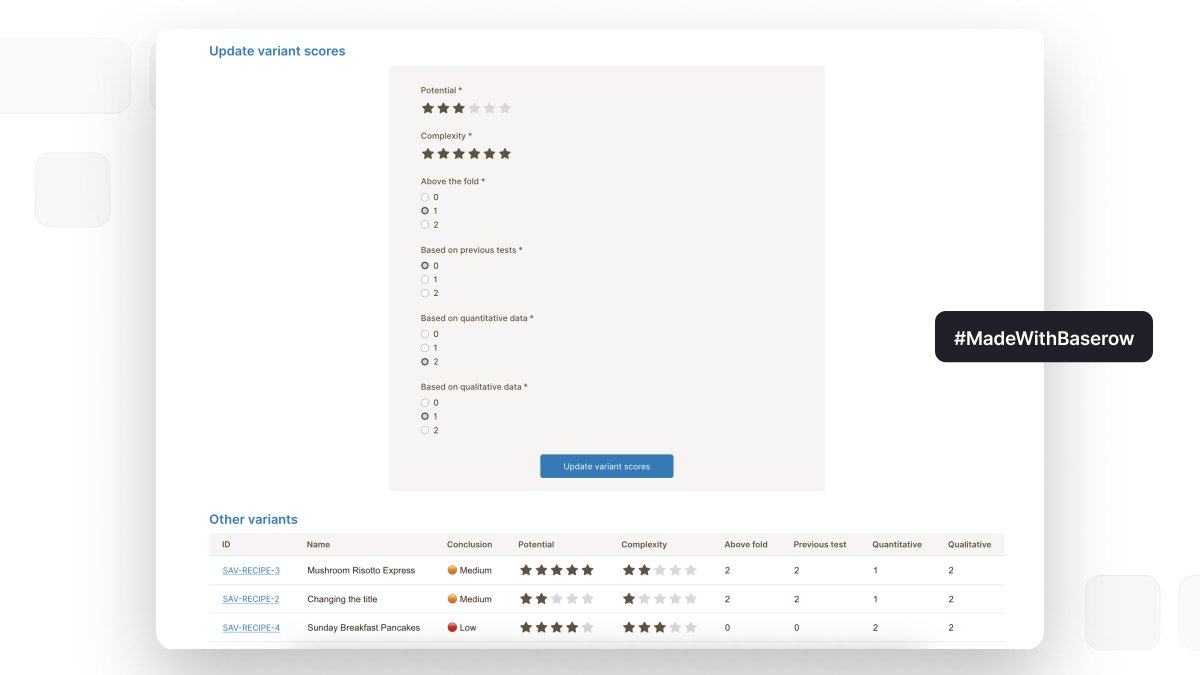
Optimize every experiment with structured A/B testing 🧪
Our new template helps teams manage experiments from hypothesis → results.
→ Track experiments and variants
→ Prioritize opportunities with scoring
→ Monitor KPIs and campaign performance
→ Keep all testing data in one place
Try it here: bsrw.io/1VAeY9
#Baserow #ABTesting #NoCode
3
102


May 21
Every high-performing app is built on one thing: iteration.
That’s why A/B testing is now live on Appbrew.
Brands can now test different app experiences, measure real user behavior, and make faster product decisions backed by data, not assumptions.
#ABTesting #Shopify #DTC
1
3
68

💡 #UnityTips: Utilize A/B testing to improve player engagement! 📈 Use A/B testing to determine the most effective in-game features and UI elements to increase player engagement and retention. #unity #unity3d #gamedev #ABtesting #marketing #IndieDev
1
4
54

May 12
Create. Test. Win. ⚡
Aionix helps businesses discover winning creatives faster with AI-powered ad testing, performance scoring, and real-time optimisation. Less guessing. More results.
🌍 aionix.uk
#ABTesting #PerformanceMarketing #AIAdvertising
2
25