
12 Dec 2025
Day 208 : Data Science Journey
Training and Verifying ResNet-18 Architecture
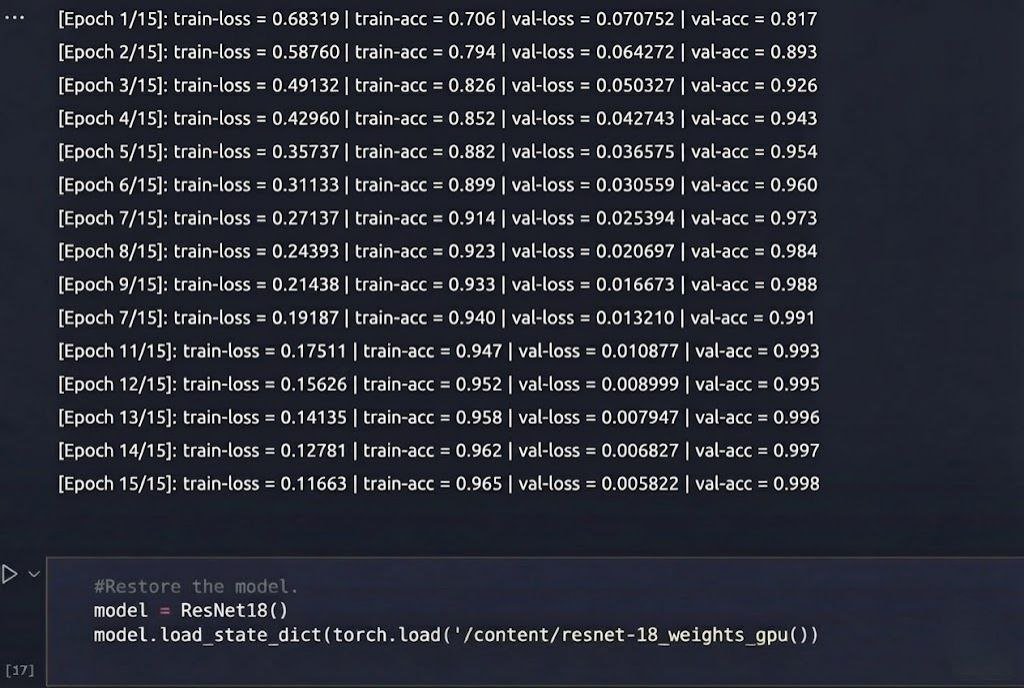
The training logs for the ResNet-18 model over 15 epochs demonstrate steady improvement on a classification task, presumably CIFAR-10, given the adapted architecture and reported accuracies. Beginning at Epoch 1 with a train loss of 0.683 and accuracy of 0.706, paired with a validation loss of 0.0707 and accuracy of 0.817, the model exhibits quick learning. By Epoch 15, train loss reduces to 0.11, achieving a train accuracy of 0.968, while validation loss hovers around 0.005 with an accuracy of 0.998. This progression highlights effective gradient flow through residual connections, with losses declining consistently to minimize errors and accuracies rising to indicate strong feature extraction, though the exceptionally low validation losses suggest potential data scaling or initialization tweaks to prevent early saturation.
Confirmation Through Parameter Count and Model Inspection
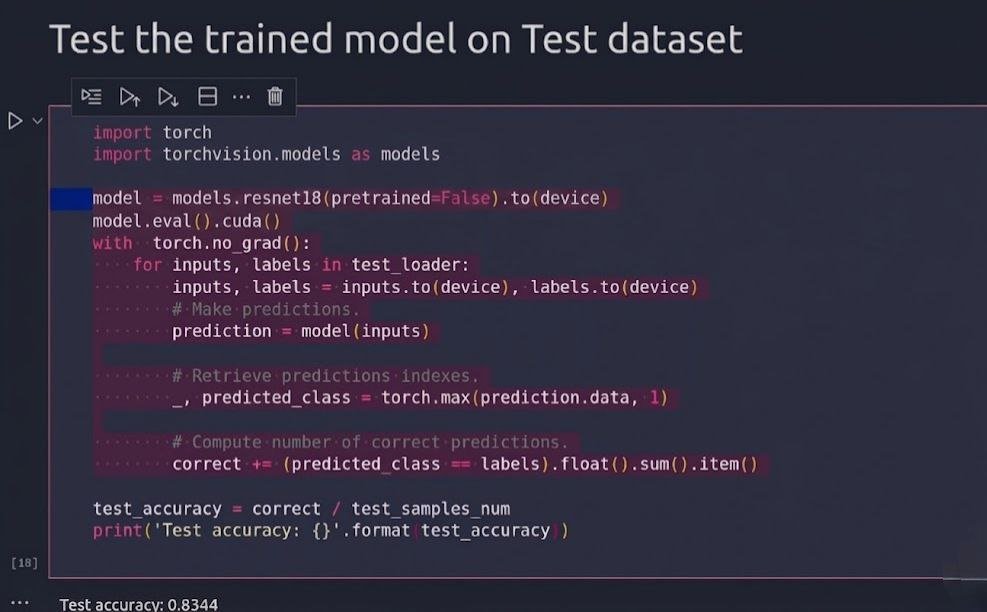
Further validation comes from computing the total trainable parameters, which totals 11,181,642 matching documented values for ResNet-18 on CIFAR-10 (approximately 11.2 million). Inspecting the model structure reveals one initial Conv2d (adapted to 3x3 for CIFAR inputs), followed by four stages with 2 BasicBlocks per stage, each containing two Conv2d layers in the main path, plus the linear output. This setup, combined with the training logs and test accuracy of around 83%.
- This concludes our deep dive into ResNet-18, spanning from the initial intuition to a bare-bones implementation, ensuring it ends with improved training results.

2
11
8,034
4 Dec 2025
Day 200 : Data Science Journey
From Paper to Practice - Implementing and Training ResNet-18 from Scratch on ImageNet-100 :
After fully decoding the ResNet paper from the optimization breakdown to the identity mapping intuition , we moved into the implementing phase: implementing ResNet-18 from scratch, optimizing the full training loop, and validating the architecture on a fast, realistic dataset. This phase bridges theory → execution and solidifies why residual networks revolutionized deep learning.
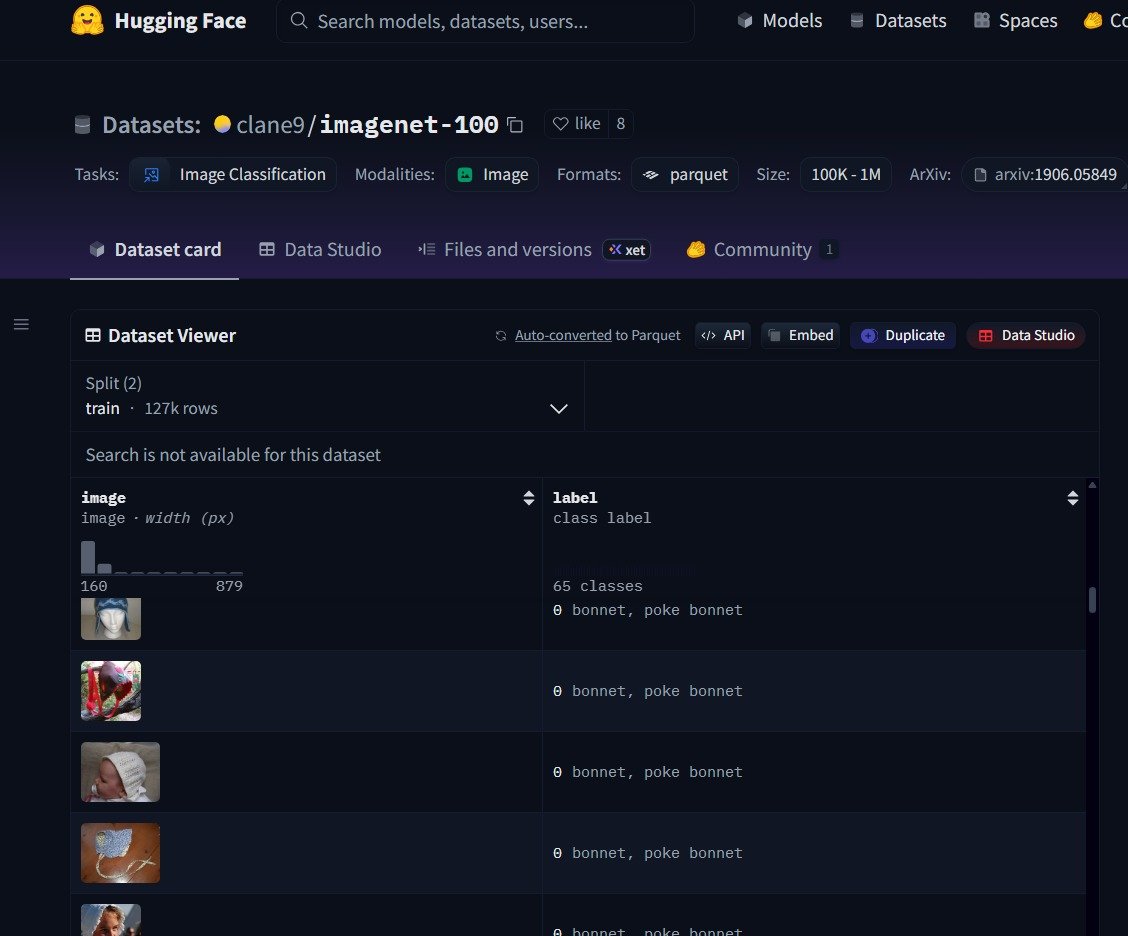
1.Dataset Selection --> ImageNet-100: The Sweet Spot of Realism & Efficiency
ImageNet-100 captures the visual richness of full ImageNet while being nearly 10× smaller, making it ideal for rapid experimentation. It preserves object diversity, scale variations, natural textures, and category complexity , enough to reproduce true ImageNet behavior. Training becomes dramatically faster without losing scientific credibility.
2.Streamed Data Pipeline : HuggingFace Hybrid Loader for Instant Access
Instead of downloading hundreds of gbs, the entire dataset is streamed on-demand through HuggingFace’s efficient dataset interface. This eliminates storage constraints, speeds up setup, and makes I/O nearly transparent. The pipeline dynamically feeds preprocessed batches to the GPU, enabling smooth training on limited hardware. The same codebase works identically on local GPUs and cloud servers; zero configuration changes required.
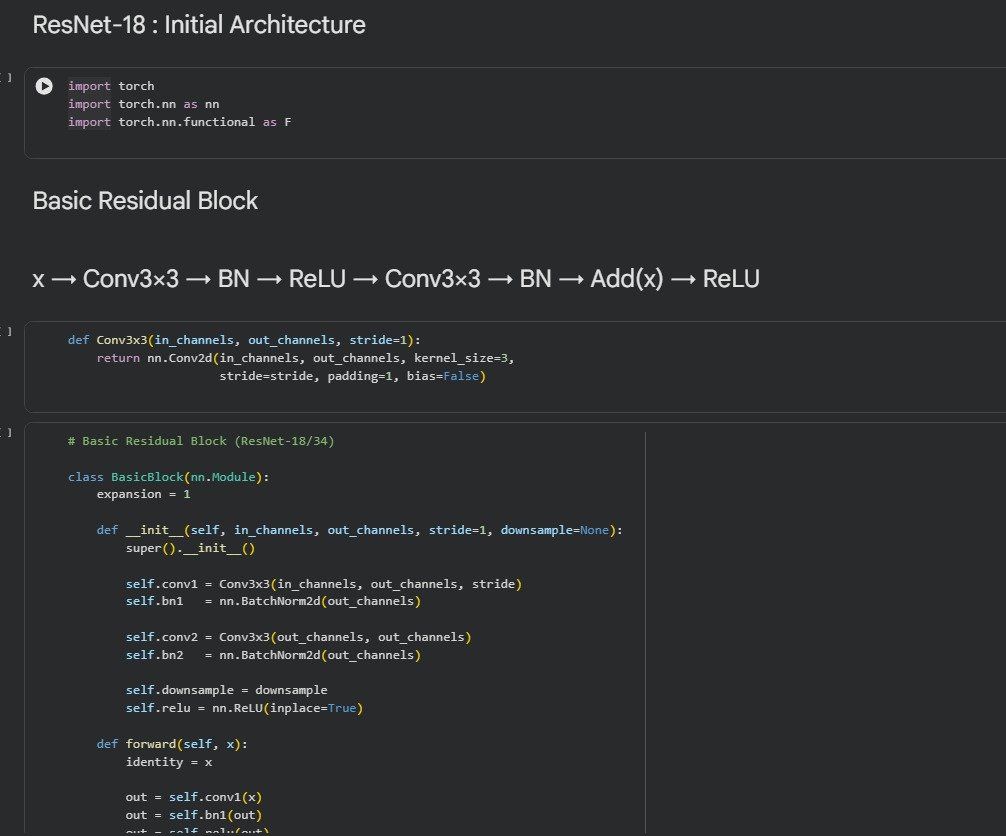
3.Paper-Accurate Architecture : ResNet-18 Rebuilt Line-by-Line
Implementing using the exact block formulation from the 2015 paper: post-activation BasicBlocks, identity shortcuts, projection shortcuts for downsampling, and the canonical [2,2,2,2] block layout. This reconstruction ensures the model’s optimization behavior truly reflects the original work. By following the paper’s design principles, the network naturally inherits stable gradient flow and robust feature learning across depth.
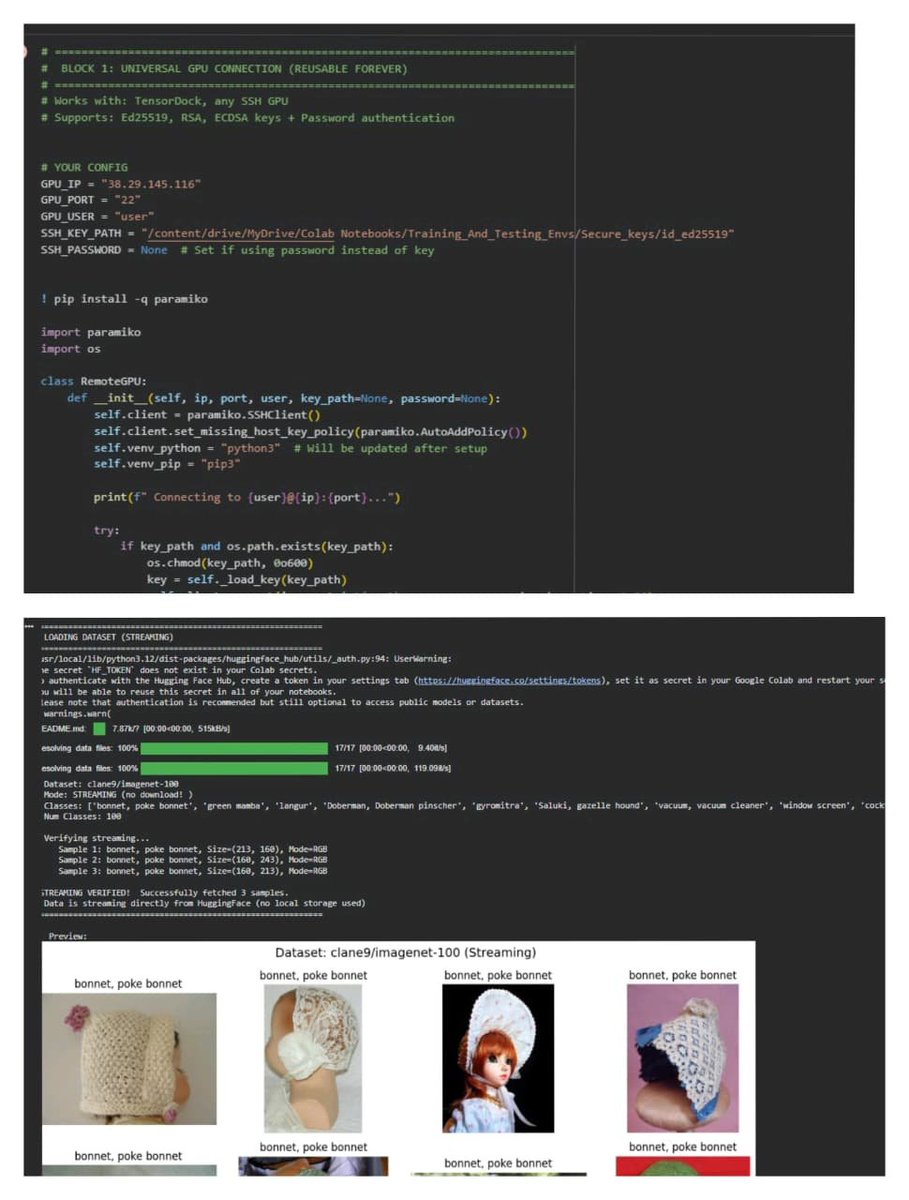

2
3
409

7 Aug 2020
Hey guys, we've just released a brand new Basic block - The basic stretch dress pattern. Head over to the Lab to see what new design options are available!
ow.ly/7dVY50ATbO4
#patternmaking #patterncutting #patternmaker #fashionstudent #stretchdress #basicblocks #sloper

4
22 Feb 2020
We've selected and collated our inspirational imagery. Next we'll turn this into a series of mood boards that help us design our range of leggings sewing patterns.
ow.ly/ly9d50yrh5p
#patternmaking #patterncutting #patterndrafting #patternmaker #basicblocks #slopers

1
3
18 Feb 2020
Exciting news! We’ve just launched a brand new product range on our sister site DesignLab! We now sell PatternLab basic blocks and slopers in fully-graded pattern packs (UK4-24).
ow.ly/qs4p50yopyR
#patternmaking #patterncutting #patterndrafting #basicblocks #slopers

3
3 Apr 2019
We're on the final local-testing stage of our custom fitting made to measure jeans and trouser patterns. Not long now until we push these out to our list of testers!
#patterncutting #patternmaking #patternmaker #fashionstudent #basicblocks #slopers #basicsewingpatterns

1
1
4 Jan 2019
We’ve added a new style tutorial! Learn how to #Draft this gorgeous #TwoPieceDress #SewingPattern using our #CustomFit #BasicBlocks and #AdobeIllustrator as a #PatternMaking platform.
ow.ly/5HMg50jKPFx

17 Dec 2018
Are you a digital #patternmaker or prefer #paperpatterncutting? Download our #madetomeasure #basicblocks and #slopers as a PDF and print them from home, or download them as an #ePattern and customise them digitally. The choice is yours! - ow.ly/UXBF50jSrAe
2
15 Dec 2018
Customise your made to measure #basicblocks and #slopers into a wealth of different #designs, using our #style #tutorials. Add #sleeves, #necklines and more.
#patternmaker #patterncutting #patterndrafting #dressmaking

2
13 Dec 2018
You can now choose between centimeters, inches or percentages when adding ease to your #basicblocks. Giving yet more ways to control the #fit of your #madetomeasure #basicblocks and #slopers - ow.ly/8F7G50jSkDB #patterncutting #MTM #dressmaking patternlab.london/lab/shop/b…
1
29 Nov 2018
Find out exactly what has changed in the Lab and how it affects you automatically #drafting your #customfitting #basicblocks and #slopers - On the blog: ow.ly/UXgw50jOskR
#basicsewingpatterns #sewingpatterns #patternmaker #dressmaking
27 Nov 2018
We are pleased to announce that #PatternLab is now back online with some great new functionality. Keep an eye out for updates about what has changed. Time to start #patternmaking your #customfit #basicblocks, #slopers & #sewingpatterns - ow.ly/NXFd50jKKdY
1
1
1


14 Apr 2018
Wondering exactly what was the original reason for IL to use stack based (maybe smaller IL?), while the first thing a JIT/compiler does is to use a register based with SSA & build basicblocks (no branch within) Swift, maybe with this feedback, is using register-based...
3
9
25 Oct 2016
The count down to PatternLab "go live" has begun - 20 days and counting!
#patterncutting #patterns #sewing #sewingpatterns #basicblocks

1

18 Oct 2014
1

10 Sep 2014
And even more subs! @JodyEcho @MLGJustice @BriOhio @BasicBlocks @WvT_Gaming @isuper_hero Give 'em all some love, awesome people here!
1
3

7 Sep 2014
@xGamersUnitedx @N00BWebZ @BasicBlocks @Tiny_YT @JustLemen @SickGamingCliq @Survivor976 @HEYIMSUPERMAN91 @esportsgfx thanks
2
5 Sep 2014
#FF @N00BWebZ @BasicBlocks @Tiny_YT @JustLemen @SickGamingCliq @Survivor976 @HEYIMSUPERMAN91 @esportsgfx @MRpotatoehead55 Happy Friday ^-^
1
2
31 Aug 2014
1