
34m
This is great! for gamedev usage having SPIR-V, DXIL, and potentially RDNA's ISAs could be great for tooling that patch shader bytecode. Idk how well it would fit to the package.
132

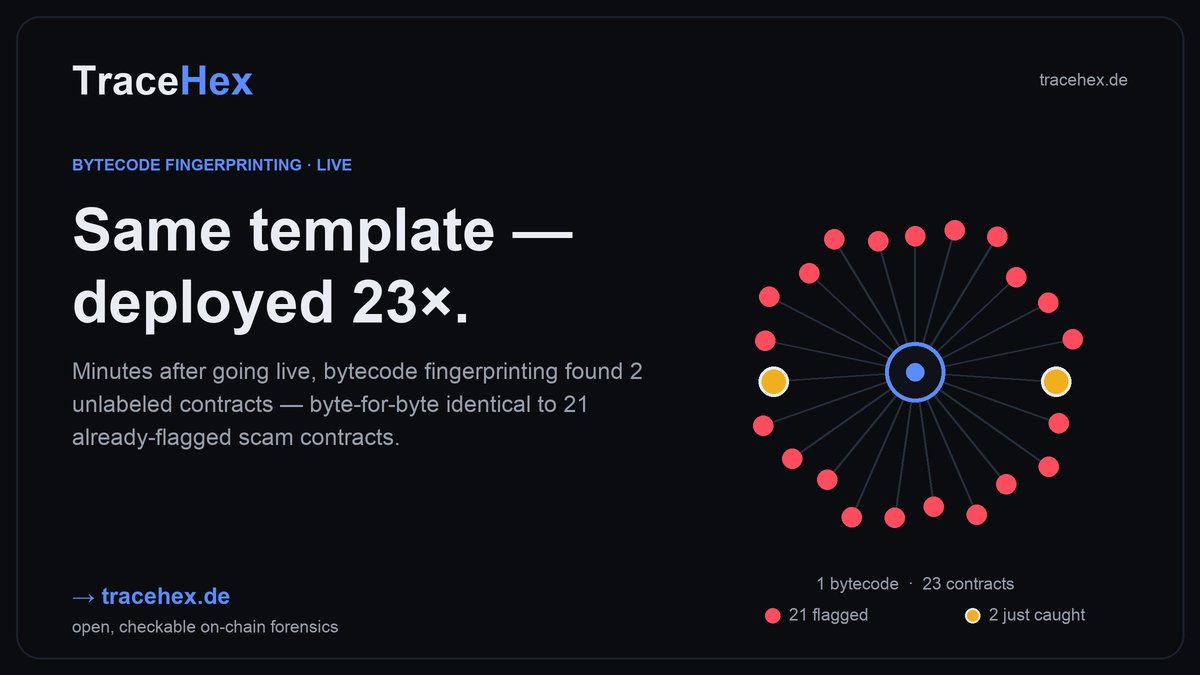
Tonight I shipped a feature on TraceHex I've wanted for a long time: bytecode fingerprinting.
Here's the thing about on-chain scammers — they don't reinvent the wheel. They write one malicious contract and deploy it again and again. New name, new token, same code underneath. The addresses change. The bytecode doesn't.
So TraceHex now hashes the runtime bytecode of every contract it sees — with the compiler metadata stripped, so a recompile of the same source still matches — and checks it against a corpus of known-bad contracts.
Less than 5 minutes after it went live, it caught something.
Two completely unlabeled contracts — no scam tag, nothing flagged about them — turned out to be byte-for-byte identical to 21 contracts already on public scam lists. One template. 23 deployments. The kind of serial operation you only see once you stop looking at addresses and start looking at code.
And this is the part I care about most: it's a cryptographic match. Not a "risk score," not a black-box model, not a gut feeling. Two contracts either share a keccak256 hash or they don't — and you can verify all 21 of those addresses on Etherscan yourself.
That's the whole philosophy behind TraceHex: open methodology, checkable trails, and honesty about the limits. A bytecode match is hard evidence that two contracts came from the same source — it is not, on its own, a verdict that an address is guilty. We say that out loud, because vague accusations dressed up as certainty are exactly what's wrong with most of this space.
I got scammed enough times to want to build the thing that turns it around. This is one more piece of it.
🔎 tracehex.de
1
1
27


v4 HOOKS: THE SCAM YOUR SECURITY SCANNER CAN'T SEE
Every "token safety" check you've been trusting is looking in the wrong place.
WHAT IS A HOOK?
Uniswap v4 introduced "hooks." A hook is a separate contract attached to a liquidity pool that runs custom code at the exact moments you interact with it.
Before/after every swap, every add, every remove. In plain terms: a hook is code that executes every time you buy or sell.
That's powerful for real builders. It's a gift for scammers.
WHY THEY'RE DANGEROUS
For years, scams lived inside the token contract: high sell tax, blacklists, "can't sell" honeypots. Scanners learned to catch those.
So the scam moved. In v4, the malicious logic now lives in the HOOK, not the token. A hostile hook can:
- charge a tax on every swap that the token contract never declares
- let you buy, then make your sell revert — a honeypot at the pool layer
- skim a slice of every trade to the deployer
- sit clean at launch, then flip after liquidity builds (upgradeable logic)
The token itself reads perfectly clean. 0% tax. Sellable. Owner renounced.
All true — because the trap isn't in the token. It's in the hook bolted to the pool.
WHY MOST TOOLS MISS IT
The popular "is this token safe?" scanners analyze the TOKEN bytecode. They don't resolve and inspect the HOOK contract sitting behind the pool. So they hand you a green checkmark on a pool that's quietly taxing or trapping you.
This isn't theoretical. Malicious and broken hooks have already drained real money (the Cork Protocol hook bug alone cost ~$11M), and v4 lets anyone deploy any pool
with any hook — no gatekeeper.
On the BASE chain, where new pools launch by the minute, that's exactly the gap scammers are farming: deploy a clean-looking token, hide the mechanism in the hook, let the standard scanners wave it through.
WHERE @palsai_bot COMES IN
PALS resolves the actual v4 hook behind a pool and inspects what it can do — not just the token.
We check the hook's permissions and behavior (can it tax you, block your sell, or change the rules after launch?) and fold that into Contract Safety, so a pool that looks clean on the surface but hides risk in the hook gets flagged, not greenlit.
It's one of the very few tools — and one of the first built for retail Base launches — that actually looks at the hook layer instead of stopping at the token.
Don't trust a checkmark that never read the hook.

3
6
12
334

that used to be true. you could tweak the binary to go around a license for example. That was cracking. Difficult and required a lot of experience, skill and intuition.
If Fable can read bytecode and recreate it -> we're talking and specialised software stops to exist without gatekeeping the binary.
I professional tools can cost few thousand dollars per seat, no imagine I just download it from torrent, throw Fable at it, and get better, faster version.
Mad
2
2
32

An immutable value is assigned during deployment, usually in the constructor, and cannot be changed afterward. Unlike normal storage variables, immutables are not stored in contract storage slots. Compiler embeds their values into the deployed runtime bytecode during deployment⬇️
1
1
There’s no IP in the digital world anymore. The moment we can reverse-engineer bytecode? Please.
1
3
23
1,279

Understanding JVM Memory Areas ✅
Before we tune anything, you need to know what we are tuning. The JVM memory is divided into several regions:
Heap Memory ➡️
- This is where all the objects live.
- Divided into Young Generation (Eden Survivor spaces) and Old Generation (Tenured).
- Controlled with -Xms (initial size) and -Xmx (maximum size).
Non-Heap / Metaspace ➡️
- Stores class metadata, bytecode, and JIT-compiled code.
- Replaced PermGen in Java 8 .
- Grows dynamically by default. Controlled with -XX:MetaspaceSize and -XX:MaxMetaspaceSize.
Stack Memory ➡️
- Each thread has its own stack.
- Stores method frames, local variables, and partial results.
- Controlled with -Xss.
Code Cache ➡️
- Stores JIT-compiled native code.
- Controlled with -XX:ReservedCodeCacheSize.
Full article Link: medium.com/javarevisited/eve…
9
584

WASI 0.3 sounds boring but important. That is exactly why AI infrastructure teams should pay attention.
The Bytecode Alliance announced that WASI 0.3 is official. The WASI Subgroup ratified WASI 0.3.0, rebasing WASI onto the WebAssembly Component Model’s async primitives. In plain English: async is now native to WebAssembly Components, and runtime and toolchain support is starting to land.
This is not a model launch. There is no dramatic demo. Nobody is pretending a runtime spec has achieved AGI, which is refreshing.
But the AI-agent stack has a runtime problem.
Agents need to call tools, run code, touch files, query systems, and coordinate workflows. That sounds powerful until you ask the Day 2 questions.
1) Where does untrusted agent-generated code run?
2) What permissions does it get?
3) How do we isolate tools?
4) How do we make execution portable across clouds, edge locations, and enterprise environments?
5) How do we observe and revoke what the agent is doing?
WebAssembly is not the whole answer. But capability-scoped, portable components are a very plausible part of the answer.
WASI 0.3 matters because agent infrastructure needs more than orchestration frameworks and clever prompts. It needs secure execution boundaries, composable interfaces, and runtime standards that do not assume every workload lives in one vendor’s happy path.
This is especially relevant for healthcare, financial services, and regulated industries. The agent cannot just “take action” because a demo looked good. It needs a governed place to act.
The next phase of AI agents will be less about chat and more about controlled execution.
That means the boring plumbing may decide which agent platforms actually survive production.
#AIInfrastructure #AIAgents #WebAssembly #WASI #PlatformEngineering #CloudNative #EnterpriseAI

52

a guide to reading pytorch source code.
as ive been using torchtitan a lot more, sometimes the kernels that are invoked arent what i expected. i realized i needed to learn to profile and have atleast an intermediate understanding of how to trace an op end to end. (also this is a major signal if you can understand this very well)
pytorch is a massive library so cloning it and looking at code line by line probably doesnt work.
this is my guide to the anatomy of torch and how to start reading it.
pytorch mainly has a four-layer architecture -
- python frontend: this is the python facing API where you write things like nn.module, torch.tensor when you are building your favorite llm.
- dispatcher: when you call one matmul, it has to decide whether to use the CPU, CUDA, or MPS for computation. the dispatcher does this for you.
- C backend (ATen / c10): i think this is where all the mathematical operations and memory management happens.
- compiler stack: this is a more recent feature that came with 2.0. torch dynamo captures the computation graph while the inductor optimizes and generates code.
always remember these four main layers.
1. the python layer
start with torch/nn/modules/module.py - the base class for all models along with the hooks are defined here.
you could also pickj an op of your choice and trace the __call__ method.
for the c binding side, torch/csrc/ has the pybind11 code that converts python objects to c pointers.
2. the dispatcher
torch.matmul(a, b) doesnt directly jump to a handwritten kernel.
there is a yaml file called the native_functions.yaml at aten/src/ATen/native/native_functions.yaml. it lists every operator, the dispatch keys, and which c function implements it.
for instance look at this, the grouped_mm disptaches to _scaled_grouped_mm_cuda.
```
- func: _scaled_grouped_mm(Tensor self, Tensor mat2, Tensor scale_a, Tensor scale_b, Tensor? offs=None, Tensor? bias=None, Tensor? scale_result=None, ScalarType? out_dtype=None, bool use_fast_accum=False) -> Tensor
variants: function
dispatch:
CUDA: _scaled_grouped_mm_cuda
tags: needs_exact_strides
```
3. ATen
this is where all the math operators and functions need to be define. source is in aten/src/ATen/native/.
there is a nice README.md guide within the folder on how to add this.
4. compiler stack
torch.compile is literally free performance when you use it well.
torch dynamo reads the python bytecode and captures the computation graph. inductor compiles that graph into triton kernels.
to debug the graphs. make use of torch logs like this -
TORCH_LOGS=" dynamo, inductor" python your_model.py
the code is under torch/_dynamo/ and torch/_inductor/. its all python but its too dense. i still havent figured out whats the best way to start reading this section.
tip: you will also need to build a debug version of torch and keep the source code generated during the compilation process otherwise, it will be difficult to find the source of some functions in the function call stack.
1. pick the main branch for instance and then -
```
export DEBUG=1
python setup.py bdist_wheel
uv pip install dist/torch*.whl
```
2. you can launch the torch script you want to debug and launch using gdb, start adding breakpoints and watch the whole function stack.
the best thing to do would be to trace just a single sufficiently complex operation end to end and not try to read the entire codebase and self destruct. ill try to add more details to this as i discover more.
more resources
- pytorch advanced section is quite nice
- pytorch developer podcast hosted by edward yang. i wished they continued this but i think its stopped now
- ezyang's blog posts
happy reading!
would also be keen to hear on some tips from @difficultyang @cHHillee @marksaroufim
2
5
96
2,442
16. Custom errors vs require strings gas trade-offs
Custom errors and require strings both provide revert reasons, but custom errors are much more gas efficient. A require(condition, "Error message") stores the entire error string in the contract bytecode and includes it in⬇️
Jun 12

As a Smart Contract Engineer, Slap yourself if you cannot clearly explain at least 10 of the following:
1. EVM memory vs storage vs calldata layout
2. Storage slot packing & inheritance slot collisions
3. Transient storage (EIP-1153) use cases
4. delegatecall context preservation & storage layout traps
5. Proxy patterns: Transparent vs UUPS vs Beacon
6. Storage gaps in upgradeable contracts
7. Diamond pattern (EIP-2535) & facet selector clashes
8. Function selector collisions & 4-byte clashing attacks
9. ABI encoding vs encodePacked hash collisions
10. Checks-Effects-Interactions ordering
11. Reentrancy: single-function, cross-function, cross-contract, read-only
12. ERC-777 hooks & callback reentrancy surface
13. Gas griefing via return-bomb / unbounded returndata
14. 63/64 gas forwarding rule (EIP-150)
15. try/catch failure modes & bubbling reverts
16. Custom errors vs require strings gas trade-offs
17. SafeMath obsolescence & 0.8 overflow semantics
18. Unchecked blocks: when they're safe
19. Signed vs unsigned integer pitfalls in arithmetic
20. Fixed-point math & precision loss ordering
21. Front-running & sandwich attack mechanics
22. Commit-reveal schemes & MEV mitigation
23. Flashloan-based price oracle manipulation
24. TWAP oracles & manipulation cost analysis
25. EIP-712 typed structured signing
26. Signature malleability & ecrecover(0) handling
27. Replay protection across chains (chainId binding)
28. Permit (EIP-2612) & gasless approvals
29. Nonce management for meta-transactions
30. Account abstraction (EIP-4337) UserOp lifecycle
31. EIP-7702 set-code-for-EOA implications
32. CREATE vs CREATE2 address derivation
33. Metamorphic contracts & selfdestruct redeployment
34. selfdestruct post-Cancun (EIP-6780) semantics
35. Init-code vs runtime bytecode distinction
36. Immutable vs constant storage mechanics
37. Gas refund mechanics & SSTORE gas accounting (EIP-2929/3529)
38. Access list transactions (EIP-2930)
39. Warm vs cold storage access costs
40. Yul / inline assembly memory safety
41. Free memory pointer (0x40) discipline
42. Scratch space (0x00–0x3f) misuse
43. Bit manipulation & masking for packed structs
44. ERC-20 approve race condition
45. Fee-on-transfer & rebasing token integration breakage
46. ERC-721 safeTransfer reentrancy via onERC721Received
47. ERC-1155 batch transfer accounting
48. ERC-4626 vault inflation / donation attacks
49. First-depositor share-price manipulation
50. Rounding direction (round up vs down) in vault math
51. Pull-over-push payment patterns
52. Block.timestamp manipulation bounds
53. blockhash limitations & on-chain randomness fallacies
54. VRF integration & request-fulfill patterns
55. Merkle proof verification & second-preimage attacks
56. Bitmap-based airdrop claim tracking
57. Multicall & msg.value reuse across calls
58. Delegatecall to untrusted code
59. tx.origin phishing vector
60. Gas-efficient storage clearing for refunds
61. Packed storage write ordering for gas
62. Cross-contract call gas stipend assumptions
63. Forced ETH via selfdestruct breaking invariants
64. Initialization front-running on proxies
65. Signature replay across forks
66. L2 sequencer downtime oracle staleness
67. Optimistic rollup 7-day withdrawal mechanics
68. Blob transactions (EIP-4844) & calldata cost shifts
69. Precompiles (ecrecover, modexp, pairing checks)
70. BLS signature aggregation verification
71. Reentrancy guards vs transient storage locks
And if you only know 10 — kindly return the "Senior Smart Contract Engineer" title.
1
1
105

4/7
La constante 314159 aparece repetida en varias capas del ecosistema. Se la ve en net_version, storage, bytecode, oracle y balances. Eso no prueba un precio externo, pero sí una intención de alineación técnica y simbólica.
1
16

Its a simpler bytecode machine, with optimizations to native code and direct operations on memory blocks, as opposed all the additional book keeping js engines have to do (garbage collection for one).
I’m no interpreter/compiler expert but for what I have read, at least in theory there are cases where V8 or other very optimized JS engines could be faster, where the complier doesn't have the runtime data that the JIT does, so the JIT produces "better" machine code equivalent than the static comp. Not sure how real of thing that is in practice tho.
It pushes the onus of optimization on the compiler building the target, so with rust for example both the compiler frontend and LLVM are optimizing.
There is nothing that explicitly ties the browser to one runtime/engine.
Wasm still needs the JS runtime for now because wasm engines don’t have bindings to the browser apis.
“Back in the day” we had a thing called Java applets which were embedded Java apps, compiled to Java bytecode and running on the JVM.
But because JS (Coffee script) was the first runtime to get added in the browser, it became the defecto way to run code in the browser. And the whole web app infrastructure got bolted on top of that.
Mind you none of this was what the initial HTTP/web system was designed for. Nor was this something engineered with great foresight, all of it grew organically into the useful mess it is now.
Jun 13

how the fuck is rust in wasm faster than js?
1
30

Day 65! ✅ of my Ethereum deep dive. 🤿
Chapter 14: The Ethereum Virtual Machine 💻
14.7) From Solidity to Machine Code 🏗️
You write Smart Contracts in Solidity. But Ethereum doesn’t speak Solidity; it speaks EVM Bytecode. 🤖📉
How does your human-readable code become a permanent blockchain program? It goes through the Compiler (solc). ⚙️
When you run your code through the compiler, you actually get two distinct types of bytecode. This is a subtle but incredibly important difference that trips up many Web3 developers: 👇
🚀 1. Deployment Bytecode (The Setup Crew)
When you deploy a contract to Mainnet, you send a transaction with an empty To field and put the Deployment Bytecode in the Data field. 📤
This code is executed exactly once. Its only job is to run your constructor(), set up the initial state variables, and then return the final runtime code to the blockchain. Once the setup is done, the Deployment Bytecode disappears forever. 💨👻
⚙️ 2. Runtime Bytecode (The Permanent Machine)
This is the code that is actually saved permanently onto the blockchain. 💾 It is the code that executes every time a user interacts with your contract in the future. The Runtime Bytecode is essentially a subset of the Deployment Bytecode. 🧩
🪄 The Magic of CREATE vs CREATE2
How does the blockchain decide what the Ethereum Address of your new Smart Contract will be? 🤔
➔ CREATE (The Default): The EVM hashes your Wallet Address and your current Nonce (the number of TXs you've sent). Because your Nonce constantly changes, the resulting contract address is dynamic and dependent on your history. 🎲
➔ CREATE2 (The Predictable Hack): Introduced in 2019, this opcode ignores your Nonce. It hashes your Wallet Address, a Salt (a random number you choose), and the bytecode itself. 🧂🧮 This allows developers to mathematically predict exactly what a Smart Contract's address will be, years before they actually deploy it!
(This is critical for advanced DeFi protocols and Layer 2 bridges). 🌉🔮
🧠 The Mental Anchor:
Deployment bytecode is the scaffolding used to build the house. 🏗️ Runtime bytecode is the house that remains after the scaffolding is torn down. 🏠✨
---
I'm reading the book 'Mastering Ethereum' (the holy grail to understand the EVM) cover to cover and breaking down one under-the-hood concept every single day. 📒📚
Follow me to learn a new and interesting topic of Blockchain and Ethereum daily! ✅📶
#Ethereum

1
16
Lol I mean this is what it is at the core no two ways about. It pushes the onus of optimization on the compiler building the target, so with rust for example both the compiler frontend and LLVM are optimizing.
There is nothing that explicitly ties the browser to one runtime/engine.
Wasm still needs the JS runtime for now because wasm engines don’t have bindings to the browser apis.
“Back in the day” we had a thing called Java applets which were embedded Java apps, compiled to Java bytecode and running on the JVM.
But because JS (Coffee script) was the first runtime to get added in the browser, it became the defecto way to run code in the browser. And the whole web app infrastructure got bolted on top of that.
Mind you none of this was what the initial HTTP/web system was designed for. Nor was this something engineered with great foresight, all of it grew organically into the useful mess it is now.
11