

Anthropic Sandbox Runtime(srt)って初めて知った
コンテナなしにOSレベルでファイルシステムとネットワークを制限してくれるものらしい
chroot的なファイルシステム制御とかをnamespaces/seccompで実装したものらしい
1
3
857




Jun 14
ALL HAIL JEFF BONWICK
ZFS FOR EVE R
Nick Moser = FREE WILL I AM JOY
how does this make any sense?? who cares??
JUSTice underSTAND that I AM THE SUN OF GOD
there are so many 'instances' of 'this'
RE MEMBER that GOD IS REAL, MOve ON from 'there'
A N G E L I C A I S R E A L
CHROOT

1
1
10

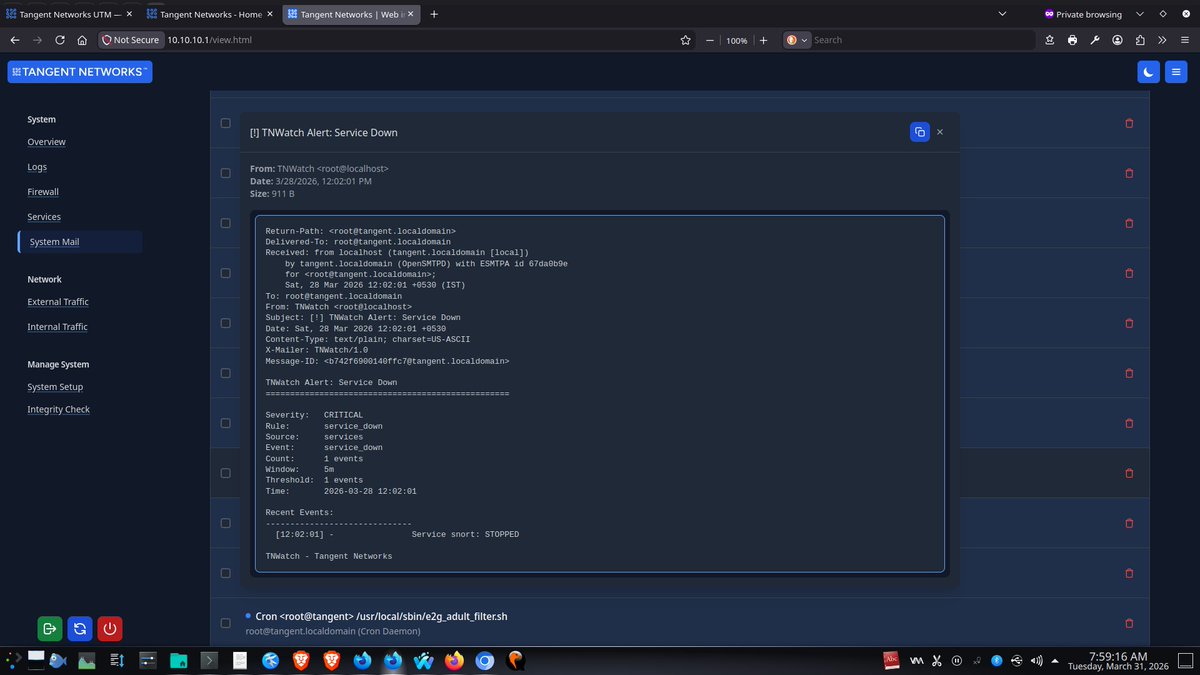
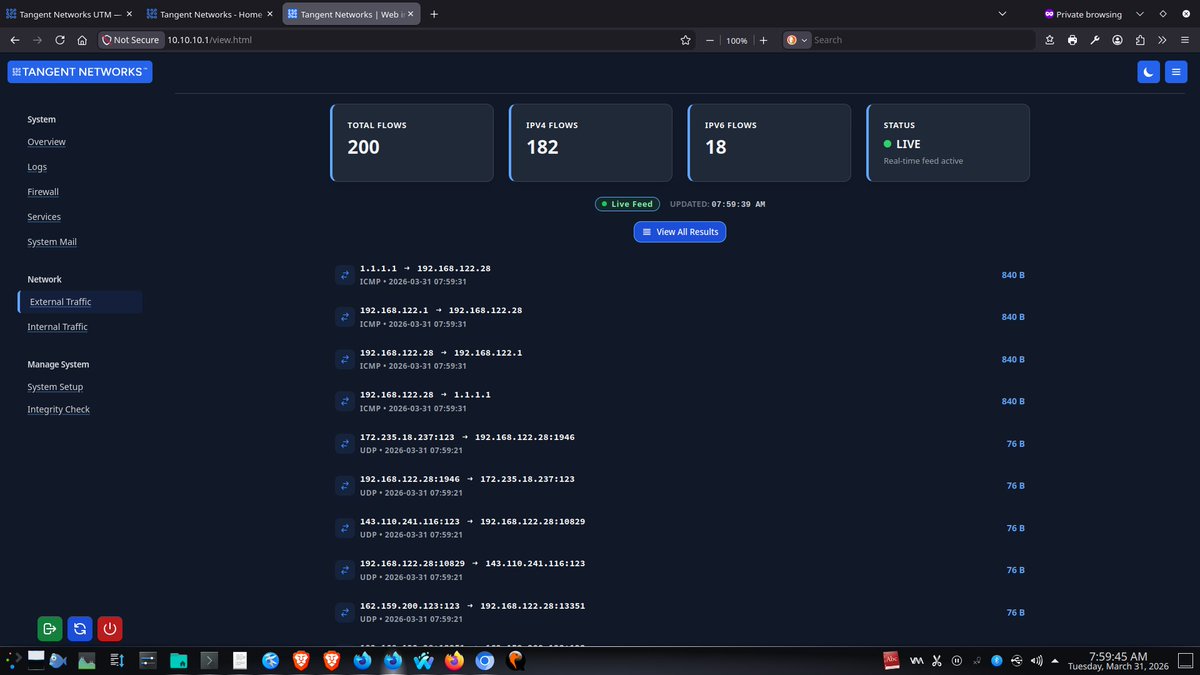
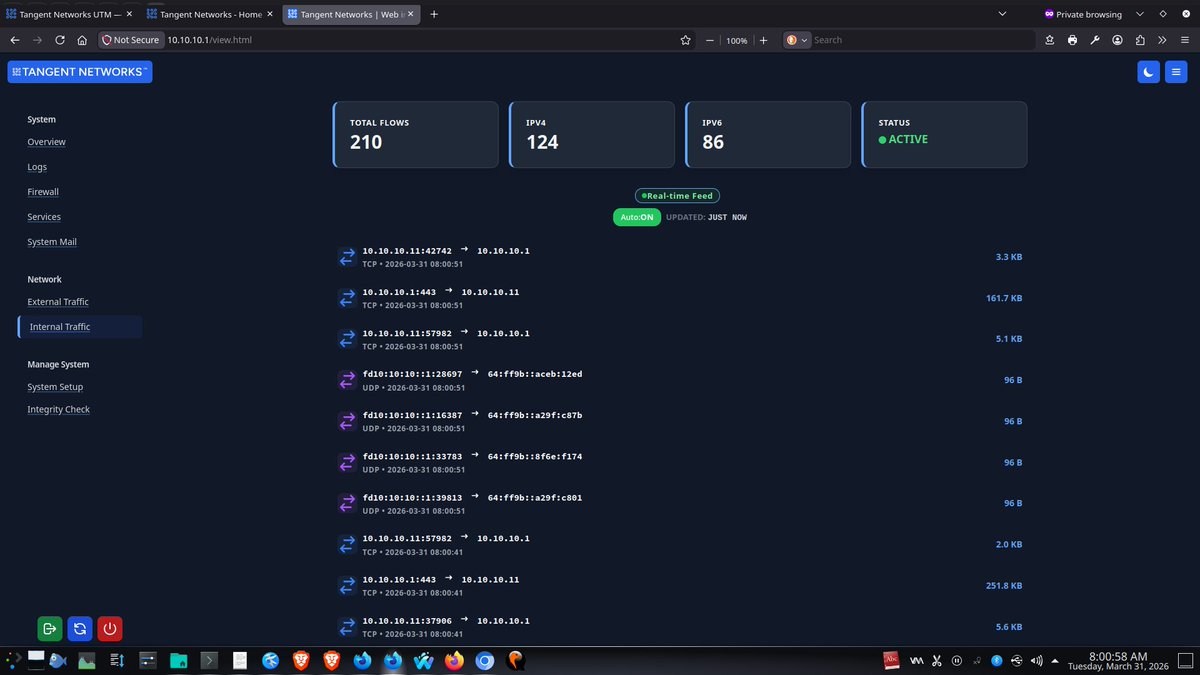
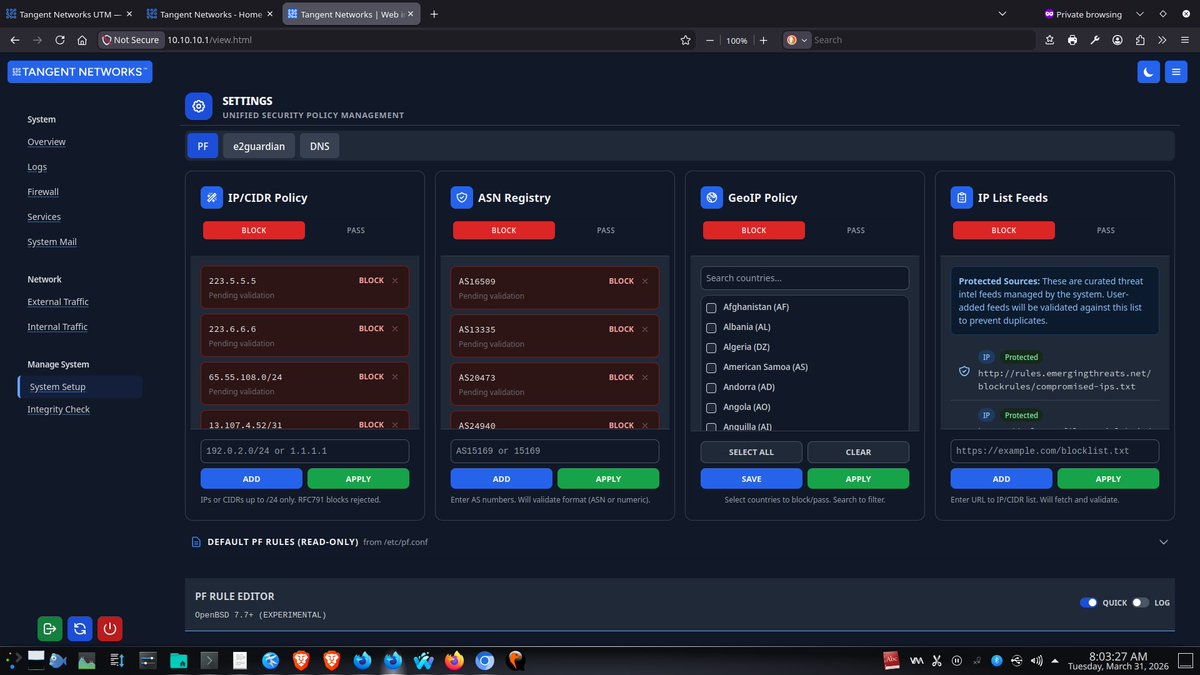
The architecture follows a strict privilege-separation model.
The WebUI runs unprivileged inside the OpenBSD httpd/slowcgi chroot. Administrative actions are performed through audited file queues and dedicated backend runners.
#SecurityEngineering #OpenBSD
1
15



Qualquer beta é arriscado. Instalei o macOS 27 beta 1 no meu mac mini m4, e após o primeiro reboot congelava no login do usuário. Tive que segurar o botão power durante o boot, entrar em ajustes, montar o disco via linha de comando no terminal, fazer chroot e desativar o filevault. Após isso começou a logar normalmente. Reativei o filevault e tudo funcionou após isso. Corrompeu por algum motivo as chaves do filevault. Se vc sabe fazer isso via linha de comando, vá em frente e use beta. Se não sabe sequer o que é linha de comando espere sair a versão oficial estável antes de atualizar, e sempre faça backup. kekeke
Jun 11

I really want to try the iOS 27 beta on my iPhone 17 Pro, but I’m still not sure because it’s my main phone 😅.
Is it worth the risk?
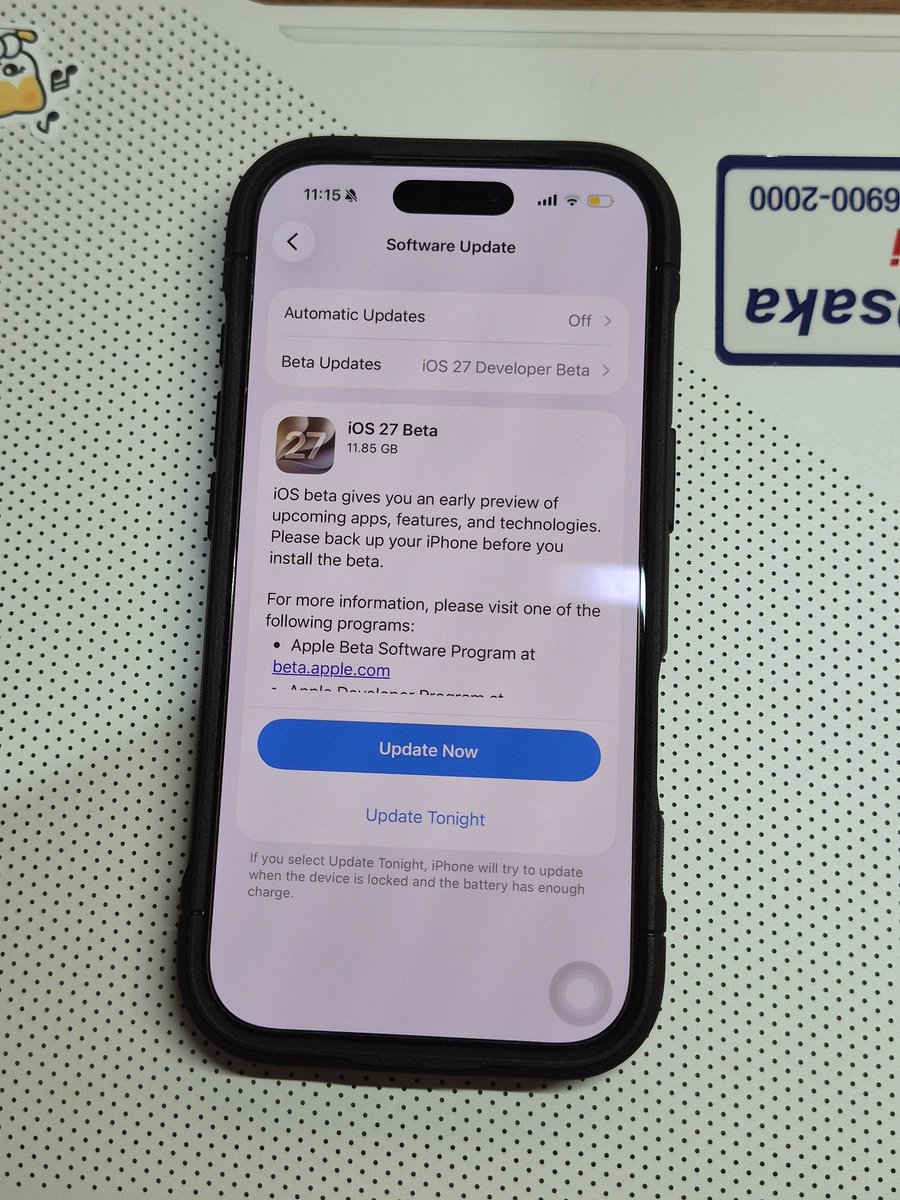
1
12
1,855

树莓派文件服务器:推荐SFTP替代FTP,全程加密更安全。用OpenSSH零成本搭建,配合rsync和定时任务实现自动化备份。注意配置Chroot隔离用户、固定被动端口防传输失败,避免传统FTP明文泄露风险。
watermelonwater.tech/insight…
24

ですです。古代のlinux-user-chrootの子孫ですね。具体的な使われ方はこんな感じ。
github.com/openai/codex/pull…
2
69

terminei de criar uma ISO funcional pra i686, pra rodar no meu pentium 4 HT, do LiveCD da VIPNIX Soluções em Tecnologia
vc mesmo pode criar, basta:
1- instalar o mchroot (a ferramenta de chroot em QEMU emulando arquiteturas diferentes do HOST) em github.com/coffnix/mchroot
2- baixar o código do VFScratch (a ferramenta de geração de Linux from Scratch da VIPNIX) em github.com/coffnix/VFScratch
3- gerar o liveCD usando o stage3 gerado com o VFScratch com esse script: github.com/vipnix/livecd/blo…
OBS: com esses códigos, vc pode gerar stage3 funcional pra qualquer arquitetura que quiser, bastando compilar o qemu com suporte e usar o binfmt.
Baixe o LiveCD i686 já pronto e grave em pendrive ou DVD caso seu computador seja antigo e não suporte na BIOS boot via USB: sourceforge.net/projects/vip…
basta baixar o ISO vipnix-livecd-i686-20260603-2218.iso
MD5: 3cbaf62b32caf55d6c1d41c7019e6b8f
SHA256: 32126f1b7928cf2135d8efa865fbf5fe2e4ea46609d0a11f1e4dcb29505a9b14

2
1
19
860

Managed to get a portion of #Tesla infotainment running on Ubuntu/Debian with Windows Subsystem for Linux (WSL).
This setup includes a firmware overlay, a chroot runtime, local Tesla web services, Spotify’s UI, DashCam Viewer, and a Tesla-Chromium car browser.
And it’s running on Windows 😂 And guess what? Spotify is even playable!
#TeslaHacking #ReverseEngineering
@teslascope

3
65



May 31
O vetor clássico: `docker run, v /:/host alpine chroot /host`. Com acesso ao socket do daemon você monta o sistema de arquivos inteiro do host como root. Grupo docker = root. Rootless resolve porque o daemon roda no namespace de usuário sem privilégios reais no host.
May 31

Quando falam que se colocar no grupo `docker` é brecha de segurança ninguém acredita.
Do nada o LLM vai lá e destroi sua máquina, mesmo se você não der sudo pro processo.
A solução: não roda docker, ou roda rootless. Eu rodo rootless e vai perfeito.
1
4
950

These projects together show serious range: hardcore systems (C scheduler FTP), ML pipelines, and production full-stack. The depth is genuinely impressive for a junior.
Alright, some warm-up questions that I'd ask if I got this resume (apart from the knowledge based questions). Will categorize it by projects (the first three).
# Project 1 : DisasterNLP
> Quantify exactly where the 17.5% degradation occurred (e.g., which classes suffered most: NEED/OFFER/availability?). Walk through your fine-tuning regimen on the 125K BERTweet samples. Did you use domain-adaptive pre-training (DAPT), intermediate fine-tuning, or adversarial domain adaptation? How did you combat catastrophic forgetting - layer freezing schedule, learning rate annealing, or replay buffers?
> Detail the exact CRF layer integration on top of BERT embeddings. How are emission scores computed? Walk through the transition matrix learning and Viterbi decoding implementation. What are the inference latency numbers under batch size=1 (real-time streaming) vs. batched? How did you handle label imbalance and BIO-style tagging for entities?
> Break down the probabilistic model or fusion technique (Bayesian? ensemble? weighted voting?). How do you weight text-derived locations vs. user profile vs. explicit geotags vs. any other signals? Detail error propagation, confidence calibration, and handling of deliberate misinformation or sarcasm in location claims.
> What was your exact feature vector (UMAP on BERT geo temporal embeddings)? How did you tune min_cluster_size, min_samples, and cluster selection? In a real disaster with rapidly changing tweet density (from 10/min to 10k/min), how do you handle cluster birth/death, noise point re-evaluation, and online updates without full recomputation?
> FastAPI Leaflet latency budget. How do you manage backpressure on tweet ingestion (Kafka? Redis streams? custom queue?)? Model quantization/ONNX/TensorRT usage? Dashboard update strategy (WebSocket? Server-Sent Events?) and handling of out-of-order or delayed tweets?
> How does the system behave with coordinated spam, botnets, or sudden topic shifts? Any active learning or human-in-the-loop fallback? Evaluation metrics beyond accuracy/F1 (e.g., event-level precision@K, end-to-end latency for actionable intelligence)?
# Project 2 : MutiTreap Process Scheduler.
(I'm grinning ear to ear as I write it)
> Why randomized treaps specifically for the ready queue? Derive the expected time complexities for insert, delete-min, and split/merge operations under your multi-treap (per-core) design. Compare rigorously to a single global red-black tree (like Linux CFS), a pairing heap, or a Fibonacci heap. What is the probability of pathological O(n) behavior, and how do you handle priority randomness key collisions?
> Detail your vruntime implementation. How do you compute and update vruntime (accounting for nice values/weights, like vruntime = delta_exec * NICE_0_LOAD / weight)? How do you maintain the global or per-core min_vruntime to prevent 64-bit overflow and starvation of long-running or newly woken tasks? Walk through the exact arithmetic and any lazy propagation or normalization tricks you used.
> Explain your victim selection policy (random? least-loaded? topology-aware?). How do you minimize cache-line ping-pong and TLB thrashing during task migration? In a scenario with 8 cores, heterogeneous cache hierarchy (e.g., L3 shared), and a mix of cache-hot short tasks vs. cache-cold long tasks, what are the measured/expected migration costs and how do you bound them?
> Show the exact synchronization for treap rotations/inserts/deletes across cores. Did you use fine-grained per-node locks, a single big lock per treap, lock-free CAS with retries, or RCU-style read-side? What are the contention hotspots under high fork()/wake-up rates, and how did you measure them (perf, cachegrind, custom counters)?
> In your lock-free or fine-grained paths, how do you handle the ABA problem during node deletion or pointer swinging? Do you use hazard pointers, epoch-based reclamation, or something simpler? Is your design wait-free, lock-free, or obstruction-free for key operations?
> How do you enforce soft vs. hard affinity? Describe the exact conditions under which a task is stolen from another core's treap. How do you maintain vruntime consistency (and fairness) across migrations without introducing priority inversion or double-accounting?
> Prove (or argue) that your scheduler prevents starvation. What is the theoretical bound on lag (difference between ideal and actual vruntime) for a task under continuous overload? How does it compare to Linux CFS? What happens with a mix of CPU-bound, I/O-bound, and interactive tasks?
> Is it timer-based, yield-based, or both? How do you handle immediate preemption on a remote core (IPI equivalent in simulator)? Detail the race between a task's vruntime update and a remote steal/preempt decision.
> Do you support any form of priority inheritance or real-time tasks? How would you extend this to cgroups-style fair sharing across process groups/users?
> 1 core flooded with 10k short tasks while others are idle.
Sudden arrival of one long-running task on an empty system.
All tasks sleeping then waking simultaneously (thundering herd).
Fork bomb simulation. What are the worst-case latency/response time behaviors, and what safeguards (e.g., minimum granularity, vruntime capping) did you add?
> With 64-bit vruntime in nanoseconds over days/weeks of simulated time, how do you prevent overflow or precision loss in comparisons and weight multiplications? Did you implement periodic vruntime normalization?
> How did you unit-test the treap invariants (BST heap) under concurrent modifications? What fuzzing or model-checking approaches (even informal) did you use? How do you verify end-to-end fairness (e.g., via Gini coefficient on CPU shares or response time distributions)?
> What assumptions did you make about timing (e.g., context switch cost, cache miss penalties)? How close is this to real hardware behavior? If you ported this logic into the Linux kernel, what would break first?
> What were your biggest bottlenecks (treap height variance, lock contention, memory allocator pressure, false sharing)? What optimizations gave the largest wins (e.g., hot-path caching of min-node, custom allocators, prefetching)?
> At how many cores/tasks does performance collapse, and why? Did you experiment with hierarchical multi-treaps or work-stealing thresholds?
> How does your scheduler compare (throughput, tail latencies, fairness metrics) to Linux CFS, a simple round-robin, or a single global priority queue under various workloads (SPEC, PARSEC-like, or your custom traces)?
# Project 3 : RFC 959 Compliant Multithreaded FTP Server in C
> Map out your complete FTP control connection state machine. How do you handle every mandatory command (USER, PASS, CWD, PORT/PASV, RETR, STOR, TYPE, MODE, STRU, ABOR, REST, etc.) with correct reply codes (including multi-line replies)? What are the nastiest edge cases you hit (restart markers with REST RETR, TYPE A vs. I during partial transfers, ABOR during active data transfer)?
> Per-connection pthread vs. thread pool with work queue? Detail shared state management (per-user cwd, login status, transfer parameters). Show your synchronization primitives—how do you protect the global listener socket, passive port allocation, and file descriptor tables? Deadlock avoidance strategy?
> Deep dive into PORT/EPRT and PASV/EPSV implementation, including IPv6 support. How do you handle data socket creation, binding, firewall/NAT traversal, and concurrent control data flows without blocking the command channel? Race conditions between 150/226 replies and actual data close?
> Path traversal prevention (canonicalization?), bounce attack mitigation, command injection via filenames/paths, resource exhaustion (connection limits, transfer timeouts, chroot/jail per user). Did you implement TLS (RFC 4217) or any extended auth (AUTH)? Buffer overflow class vulnerabilities you explicitly defended against?
> How do you handle thousands of concurrent users without degradation? Non-blocking I/O or blocking with thread pool trade-offs? Tools used for compliance testing (standard clients like FileZilla, curl, lftp custom protocol fuzzer). Hardest interoperability bugs you fixed?
> Manual memory handling for buffers, command parsing, directory listings. How did you prevent leaks under long-running sessions or aborted transfers? Valgrind/AddressSanitizer findings and fixes.
1
1
3
706