

ローカル端末から「Google Colab」を操作する「Colab CLI」が登場 - 窓の杜 forest.watch.impress.co.jp/d…
25
133
9,939


NaruTo@うなぎ食べない教 retweeted

Mar 31
やりたいことを自然言語で伝えるだけ💡
GitHub Copilot CLIは、コードの生成からPR作成まで一連の開発フローをターミナル上でサポートするAIエージェントです!
実行前の承認も自動化でき、エージェントSkills対応。
ぜひお試しください!
3
34
561
1,976,151

igor martínez prado ♡ retweeted

📸 | sarament_official
Actor Gong Myung appears on YouTube BDNS <A.S.A.P> 💸
Today, the 'Husbands' are appearing as clients. What kind of request have they brought? 👀
#HusbandsInAction #남편들
#GongMyung #GongMyoung #공명

6
19
382

We shipped a CLI because clicking through dashboards isn't shipping.
clerk init
Start free
38
159
823
1,524,272

We shipped a CLI because clicking through dashboards isn't shipping.
clerk init
Start free
34
88
716
2,612,298

【4/5】
4. コマンド
./llama-cli -m gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf -ngl 99 --model-draft mtp-gemma-4-26B-A4B-it.gguf --spec-type draft-mtp --gpu-layers-draft 99 --spec-draft-n-max 6 --spec-draft-p-min 0.7 -c 262144 -fa on -ctk q4_0 -ctv q4_0 --no-mmap -t 6 -tb 6 -fit off
1
14
KJ 🦊🌻🫧🧢 retweeted

Jun 13
#YMFSTargetLocked 📌🪽
Panoorin ang panibagong #YMFS drop: facebook.com/share/v/17Y8Xut…
Abangan sina Heath Jornales, Marco Masa, Clifford, at Caprice Cayetano sa romantic drama series ng GMA Public Affairs na “You’re My Favorite Song.”
#YMFS
#YoureMyFavoriteSong


50
366
1,098
21,534

今天 GitHub 被 Agent 军团彻底攻占了🔥
不是夸张说法,今天 GitHub 热榜前几全被 Agent 和 CLI 基础设施包揽,星标增长速度我看了都有点慌。
给你拆解 5 个今天最猛的项目:
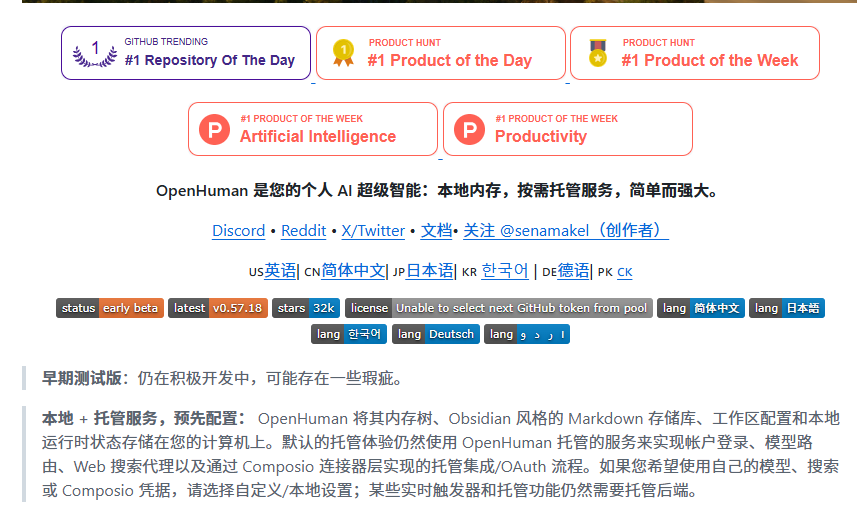
1️⃣ openhuman(tinyhumansai)
私人超级 AI 智能体,Rust 编写,完全私有化部署,日常事务到复杂工作流全包。以前 ChatGPT 就是个聊天窗口,这玩意儿是真正跑在你本地的随身助理。今天单日暴增 3k 星,私人 AI 时代不是要来了,是已经来了。
🔗 : github.com/tinyhumansai/open…
2️⃣ CLI-Anything(HKUDS)
口号是"让所有软件都具备 Agent 原生能力",意思是可以把任意命令行工具变成 AI 能直接调用的技能。Agent 终于能真正掌控你的终端和整套工具链了,开发者和自动化党看到这个应该懂我在说什么。今天 1k 星,CLI 革命这回是动真格的了。
🔗 : github.com/HKUDS/CLI-Anythin…
3️⃣ academic-research-skills(Imbad0202)
专为 Claude Code 打造的学术研究技能包,research→write→review→revise→finalize,整条科研流水线直接自动化跑通。写论文写报告的朋友,这东西都出来了你还在一层层手动搞?今天暴增 3k 星,学术圈要大地震了。
🔗 : github.com/Imbad0202/academi…
4️⃣ superpowers(obra)
这个不只是工具,而是一套 Agent 技能框架加软件开发方法论。说白了就是教你怎么系统性地把 Agent 用好,不是给你一堆提示词就完事,而是真正的底层打法。今天 1.6k 星,老鸟必备,新手更该看。
🔗 : github.com/obra/superpowers
5️⃣ agentmemory(rohitg00)
AI 编码 Agent 的持久化记忆方案,基于真实基准测试优化出来的。Agent 最大的硬伤就是没有记忆,长任务跑着跑着就丢了上下文,这个项目就是专门来补这个坑的。今天 1.6k 星,编码 Agent 基础设施这一环终于补上了。
🔗 : github.com/rohitg00/agentmem…
说句实在话,Agent、CLI、Memory、Skills 这四块现在已经是标配了,不是将来,就是现在。谁先把这套基础设施吃透,下一波 AI 生产力爆发的时候,你就是那个早已准备好的人。
10
111
455
37,457

13m
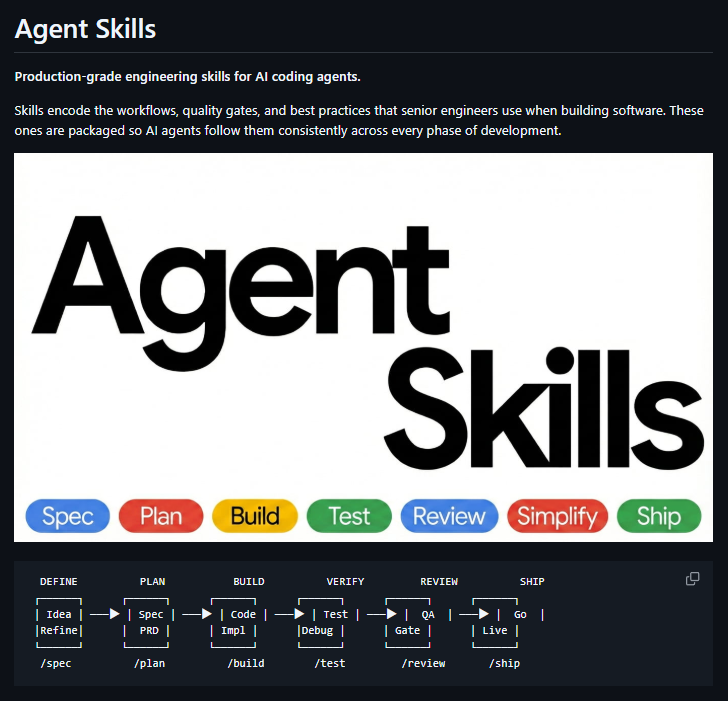
谷歌大佬Addy Osmani开源的 Agent Skills,把资深工程师的工作流、质量门禁和最佳实践,打包成 AI Coding Agent 可执行的技能。
亮点:
1、从需求定义、计划、实现、测试、审查到上线,全流程覆盖
2、24 个生产级工程技能,让 Agent 不只是写代码,而是按工程规范交付
3、强制验证、测试、Review、发布检查,减少“看起来能跑”的幻觉式交付
4、支持 Claude Code、Cursor、Gemini CLI、Windsurf、Copilot 等工具链
5、适合想把 AI 编程从 Demo 推向 Production 的团队
建议收藏起来
1
30
LLM-rg 750B Instruct (ryo_grid / Ryo Kanbayashi) retweeted

Jun 12
CLIとか(笑)Cursorが最高だろ?と、思っていた時代が私にもありました。
1
1
190
Diego ☕️ besimplo.com retweeted

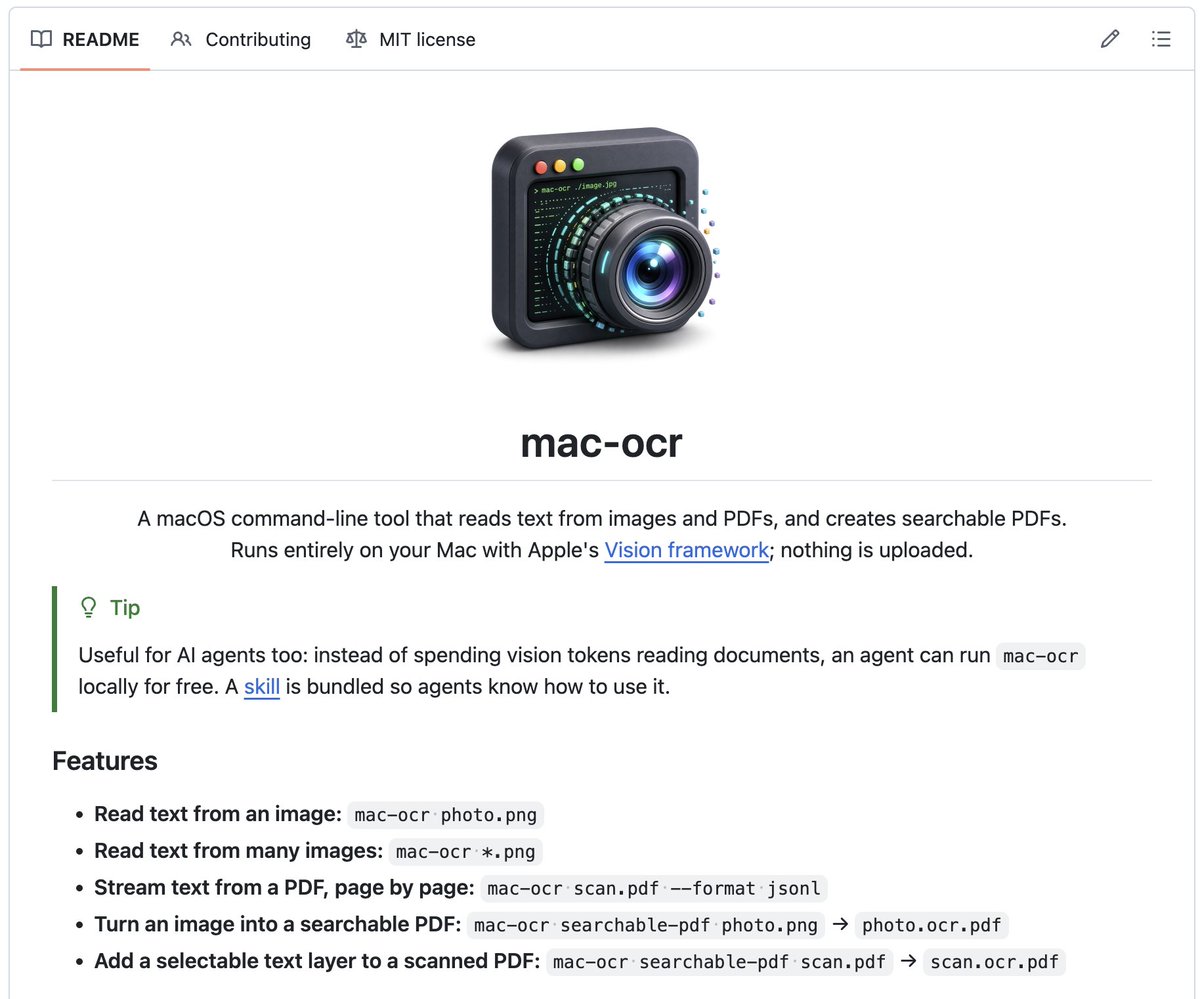
If you work with images with text, or scanned documents, here's a small but powerful OCR CLI
It leverages Apple's Vision Framework so it's completely local
Tip: give it to your agent to save on vision tokens!
→ npx mac-ocr ./image.png
github.com/privatenumber/mac…
8
27
409
30,804

boxer dave retweeted

I recently collabed with the amazingly sexy @strong_hands4. His mouth knows how to work a cock 🥵🍆 I posted 5-minute clip of our collab on my OF, and the full video is coming to OF soon
6
91
364
29,503

18m
78% on OSWorld collapsing to 41% when GUI and CLI have to be interleaved in one trajectory tells you exactly what frontier models are missing.
Benchmarks that test one modality at a time are measuring a capability that almost no real task actually requires.

WeaveBench
Microsoft Research Asia introduces
114 long-horizon tasks that force agents
to interleave GUI and CLI in one trajectory.
The same frontier models
that score over 78% on OSWorld-Verified
collapse to 41.2% on WeaveBench.

1
7