
Apr 24
Wrapped up my first engineering on-call rotation on a global cloud reliability team.
Some of my takeaways from today:
- Alignment matters just as much as speed during incidents. Cross-timezone outages move fast and I had to learn how to communicate status clearly and get to decisions quickly.
- Ask early. Pride is expensive during an incident. Some of our best problem solving came from walking up to a senior engineer's desk and working through it together.
- Write down what broke and what didn't work. Retros only improve things if someone captures the details.
- AIOps is worth learning. This rotation pushed me to use these tools in practice, and learn more about the area.
Grateful to my coworkers for their support & to be in an org that encourages us to learn & build. 🛠️
(Image source: Microsoft Research, AIOps: microsoft.com/en-us/research…)
#AIOps #CloudReliability #AI #DevOps #Cloud

1
4
344

Mar 30
You can build a highly available VM architecture in Azure and still have it fail in production.
One small detail often decides whether your load-balanced design actually works.
Health probes.
Azure Load Balancer does not inherently know whether your application is healthy. It relies on health probes to determine backend endpoint status and which backend instances should receive new connections.
If the probe succeeds, the backend instance stays available for new traffic.
If the probe fails, Azure Load Balancer stops sending new connections to that unhealthy instance.
That sounds simple, but the real issue is what the probe is actually checking.
Many deployments point the probe at a basic port or a minimal endpoint. The probe passes, and Azure keeps sending traffic.
Meanwhile, the application may still be degraded in a way that the probe does not detect.
Microsoft’s documentation is clear that probe configuration and probe responses determine which backend pool instances receive new connections. That means the probe endpoint is part of your reliability design.
The best production architectures treat the probe like a meaningful health signal.
Instead of checking only whether the server is reachable, the probe should reflect whether the application is actually ready to serve requests.
If your load balancer only knows the instance is reachable, it cannot protect you from every kind of application failure.
#Azure #MicrosoftAzure #CloudArchitecture #AzureArchitecture #LoadBalancing #AzureVM #CloudReliability #WellArchitected #CloudEngineering #mvpbuzz

1
3
2,915

Successfully completed a huge campus network design and implementation. Real life experience in a simulation. Sharing with you this midnight.
#ccna #networking #cybersecuritytips #public #packettracer #CCNALAB
#IT #Systemsadmin
#cybersecurity #Cisco #CloudReliability
3
86

Cloud outages are frequent and increasingly disruptive. The blog outlines how enterprises can strengthen #CloudReliability, enabling systems to withstand and recover from disruption.
Read now: infy.com/Vv4Kg
#InfyTesting #InfosysCobalt #IQE #NavigateYourNext

2
2
4
560

We manage the servers, security patches, and backups so you can concentrate on building amazing Oracle APEX applications. 💻 With a 99% Uptime Guarantee, peace of mind comes standard.
Host with confidence: 🔗 maxapex.com/
#ManagedHosting #UptimeGuarantee #OracleAPEX #DeveloperFocus #CloudReliability #ServerManagement #PeaceOfMind
2
2
136

🚀 Session Spotlight | Multicloud AIWorld 2026
Continuous Application Availability with Oracle RAC & Transparent Application Continuity
What if your applications could survive failures automatically — without a single line of code change?
This session showcases how Oracle RAC and Transparent Application Continuity (TAC) deliver true continuous availability by allowing applications to receive real-time events and notifications directly from the database — eliminating the need for developers to build complex retry logic or handle infrastructure failures manually.
You’ll learn how Application Continuity (AC) and TAC integrate with leading application servers to keep your business applications running smoothly, even during outages, maintenance, and unexpected disruptions.
🎯 What You’ll Learn
• How AC & TAC provide the foundation for continuous application availability
• How applications remain resilient without any code changes
• How Oracle removes the burden of writing complex retry logic
• Best practices for deploying RAC for performance, scalability, and uptime
🎤 Featured Speaker
Anil Nair @RACMasterPM
Distinguished Product Manager, Oracle RAC, Oracle USA
A global authority on Oracle RAC with 20 years of experience helping enterprises achieve unmatched performance, scalability, and availability.
📍 Multicloud AIWorld 2026 | Hyderabad & Bengaluru
🎟️ Free Registration | Limited Seats
aioug.org/mc/2026
Design for resilience.
Deliver without disruption.
#MulticloudAIWorld #OracleRAC #HighAvailability #EnterpriseIT #Database #CloudReliability #AIOUG #FutureOfTech
@Oracle @oracleugs @oracleace @OracleDevs @oracledevcomm @OracleDatabase @OracleCloud @googlecloud @awscloud @Azure @MySQL

1
3
128

21 Dec 2025
Claude Opus 4.5 is down for 2 days straight. Can't get any work done.
While everyone's hyping Google @antigravity , where's the reliability? Downtime kills productivity for developers relying on these tools.
Need consistent AI models that actually work when you need them. Don't want promises, want results. 🛑
#AI #DevTools #CloudReliability #antigravity #Google
1
2
270

14 Dec 2025
Documenting targets for workload reliability is key. Did you define recovery targets and health definitions? Knowing where you stand is the first step to improvement your Azure Local journey. #Azure #CloudReliability
2
10
674

23 Nov 2025
#OMG... Severe internet outages keep happening -- and they might get worse.
NBC NEWS: Growing reliance on a handful of major internet infrastructure companies has led to major disruption
While there’s plenty of finger-pointing to go around, two things are clear: Popular consumer businesses increasingly rely on a handful of giant companies that run things more cheaply in the cloud.
When one of those companies isn’t extraordinarily careful, an obscure software vulnerability or tiny mistake can reverberate through to many of their customers, making it seem like half the internet has been unplugged.
“This spate of outages has been uniquely terrible,” said Erie Meyer, the former chief technical officer of the Consumer Financial Protection Bureau under the Biden administration...
nbcnews.com/tech/rcna245043
#TechnologyNewswire #InternetOutage, #CloudFailure, #TechNews, #DigitalDisruption, #CyberBug, #AWSDown, #AzureCrash, #CloudflareFail, #Hyperscalers, #BigTech, #InternetBreakdown, #SoftwareVulnerability, #DNSFail, #CloudComputing, #TechConsolidation, #GlobalOutage, #CyberAttackScare, #ErieMeyer, #ElizabethWarren, #TechRegulation, #MarketFailure, #NationalSecurity, #CrowdStrike, #OpenAI, #DiscordDown, #RobloxOffline, #FortniteFail, #DeltaAirlines, #AlaskaAir, #SmartHomeFail, #RingCamera, #Akamai, #PublicCitizen, #BidenAdmin, #VanderbiltPolicy, #InfrastructureRisk, #TechGiantMonopoly, #CloudReliability, #FutureOfInternet, #SystemicRisk, #GovOversight, #DigitalEconomy, #OutageSpree, #BotSoftwareBug, #ConfigError

2
184

6 Nov 2025
Why the Silence on Cloud Outages? It’s Time for Consultants to Step Up
Cloud outages cost businesses millions of dollars per hour, disrupt operations, and damage reputations. Yet, amidst these high-stakes events, something is glaringly absent: an open conversation from consulting firms.
As consultants, we are trusted advisors—the bridge between technology and critical business decisions. So why do so many stay silent when cloud outages occur? The reasons are complex but boil down to this: financial dependencies, strategic alliances with hyperscalers like AWS and Microsoft, and reputation management.
By not addressing outages and their impacts, we risk more than just strained client relationships—we risk our credibility. Enterprises are left with incomplete narratives about cloud adoption, ignoring the trade-offs of cost, security, resiliency, and reliability.
But here’s the reality cloud clients need to hear:
💡 No cloud provider can ensure 100% uptime. Resiliency is a shared responsibility. Enterprises must have strong multi-cloud or hybrid strategies in place, rather than putting all their trust in a single provider.
💡 Silence on outages erodes trust and limits innovation. We must embrace transparency and foster honest discussions about cloud limitations. These conversations are challenging—but critical for a more resilient business environment.
If we, as an industry, don’t start shifting the narrative, we’re doing a disservice to the businesses that depend on us for truly unbiased advice. It’s time to prioritize partnerships based on value, not blind allegiance.
Let’s have the hard conversations. Let’s address failures openly. Let’s deliver better solutions for everyone.
#CloudComputing #Consulting #TechResilience #CloudOutages #MultiCloud #DigitalTransformation #LeadershipMatters #Innovation #CloudReliability
Why Tech Consulting Titans Stay Quiet About the Cloud Outages youtu.be/KpV0EN27mi4?si=9laP… via @YouTube
1
310

21 Oct 2025
I had the honor of joining Fox 35 Good Day Orlando to discuss the major AWS outage that temporarily disrupted access to major online platforms and services worldwide.
We explored what went wrong, what this means for businesses that rely on cloud infrastructure, and — most importantly — what can be done to prevent it from happening again.
A heartfelt thank-you to the @fox35orlando team for inviting me and for highlighting such a crucial issue that impacts every organization in our increasingly digital world.
🎥 Watch the full segment here: hubs.ly/Q03Pz30t0
If your business runs on the cloud, now’s the time to prepare — not panic.
📞 Contact us today: (407) 995-6766
Let’s make sure your systems — and your customers — stay protected, no matter what happens in the cloud.
#FOX35Orlando #AWSOutage #Cybersecurity #BusinessContinuity #CloudReliability #AuroraInfoTech #CyberResilience #TechNews #GoodDayOrlando




1
2
47

20 Oct 2025
Breaking: Major @awscloud outage region disrupted top platforms like Reddit, Coinbase today.
@configbee remained unaffected — powered by a multi-cloud, Hyper Availability design.
dev.to/srivenkatareddy/aws-o…
#AWSOutage #DevOps #CloudReliability #MultiCloud
1
3
291

16 Sep 2025
Still struggling with Downtime?
Unreliable infrastructure isn’t just frustrating - it’s expensive!
InfraTech Systems offer high-availability cloud hosting that keeps your business running 24/7.
• 99.9% uptime
• Geo-redundant architecture
• Real-time monitoring & failover support
Get a free infrastructure audit today: infratechsystems.co.uk
#CloudReliability #BusinessContinuity #InfraTechSystems #CloudInfrastructure #ITOutages

1
1
19

13 Jun 2025
Downtime? Not here.
When global giants went dark, HS Cloud kept our customers online — no hiccups.
Our multi-region, fault-tolerant infrastructure proves one thing:
You don’t have to go down with the cloud.
#SRE #DevOps #CloudReliability
1
2
85

28 Feb 2025
The recent Slack outage served as a stark reminder: even our most relied-upon tools can falter.
Was your business prepared?
Disruptions like these highlight the critical need for robust business continuity plans, including backup communication strategies.
In today's cloud-dependent world, we can't afford to be caught off guard.
Let's discuss how to build resilient systems that keep your operations running smoothly, no matter what -> cisus.com/contact!
#BusinessContinuity #CloudReliability #ITSupport #DigitalResilience #TechOutage #CIS #Slack

2
5
86

23 Jan 2025
🎉 We Did It – 100% Uptime in Q4 2024!
A big shout-out to our amazing team and loyal customers! We’re proud to announce that Contabo has been recognized by Hosttest.de for achieving 100% availability in Q4 2024.
🌐 This milestone reflects our commitment to providing rock-solid infrastructure and reliable cloud hosting for all your projects.
💡 Want to see what makes us stand out? Explore our hosting solutions today: contabo.com/en/
#Contabo #100PercentUptime #HostingExcellence #CloudReliability

3
1
6
797

18 Jan 2025
While centralized cloud services depend on a few data centers, Drive3 distributes data across multiple nodes.
This drastically reduces the risks associated with server outages and security breaches, ensuring better uptime and reliability. #CloudReliability #Decentralized

6
1
24
8,226
7 Jan 2025
Drive3 ensures your data is always available with its multi-level fault tolerance system.
By using multiple copies and advanced error correction, Drive3 guarantees that your data remains intact and accessible, even during system failures.
#CloudReliability #DataProtection

8
9
29
7,911

26 Jun 2024
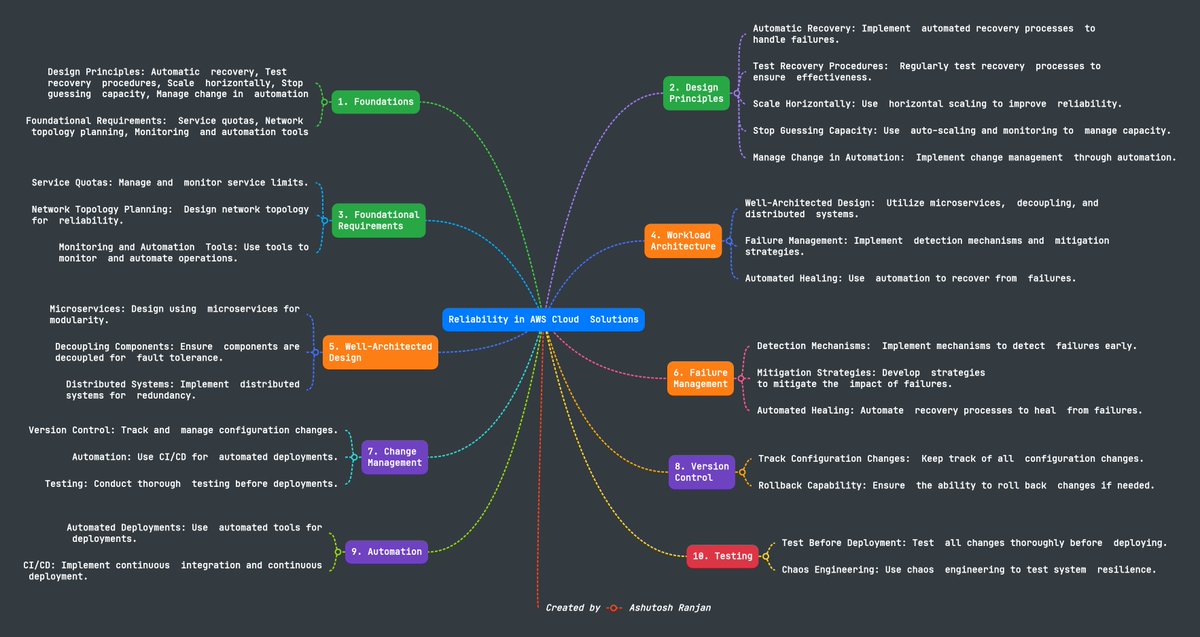
Sharing the key principles of achieving Reliability in AWS Cloud! This visual exploration covers foundational requirements, design principles, workload architecture, change management, and failure management. I'm sure it's worth a look.
linkedin.com/posts/ashutosh-…
#AWS #CloudReliability #AWSCertified #CloudComputing #TechLeadership #AWSWellArchitected #CloudSolutions
60

🚨Attention all Cloud Reliability Engineering Candidates. Listen to Matt, a Staff Cloud Architect, describe what your first 3 months will look like as a new CRE on the DoiT team. Click the link in our bio to apply!
#lifeatdoit #cloudreliability #aws #cloudengineering #remotework
2
113