

Jun 9
Limitations are often good things bejng limited makes you actively think way more about how and why youre conveying information. Im sorry one of the guys who codesigned the game is just wrong. The game looks worse now then ce did then.

It literally was, the guy who co-designed the game literally said so-

1
36


Jun 3
Surprised to see the speedup of SOAP-H here as it seems much larger than the gap on attention based arch! We are entering an era where arch and optimizers clearly need to be codesigned. Curious about the underlying principles here.
Jun 2

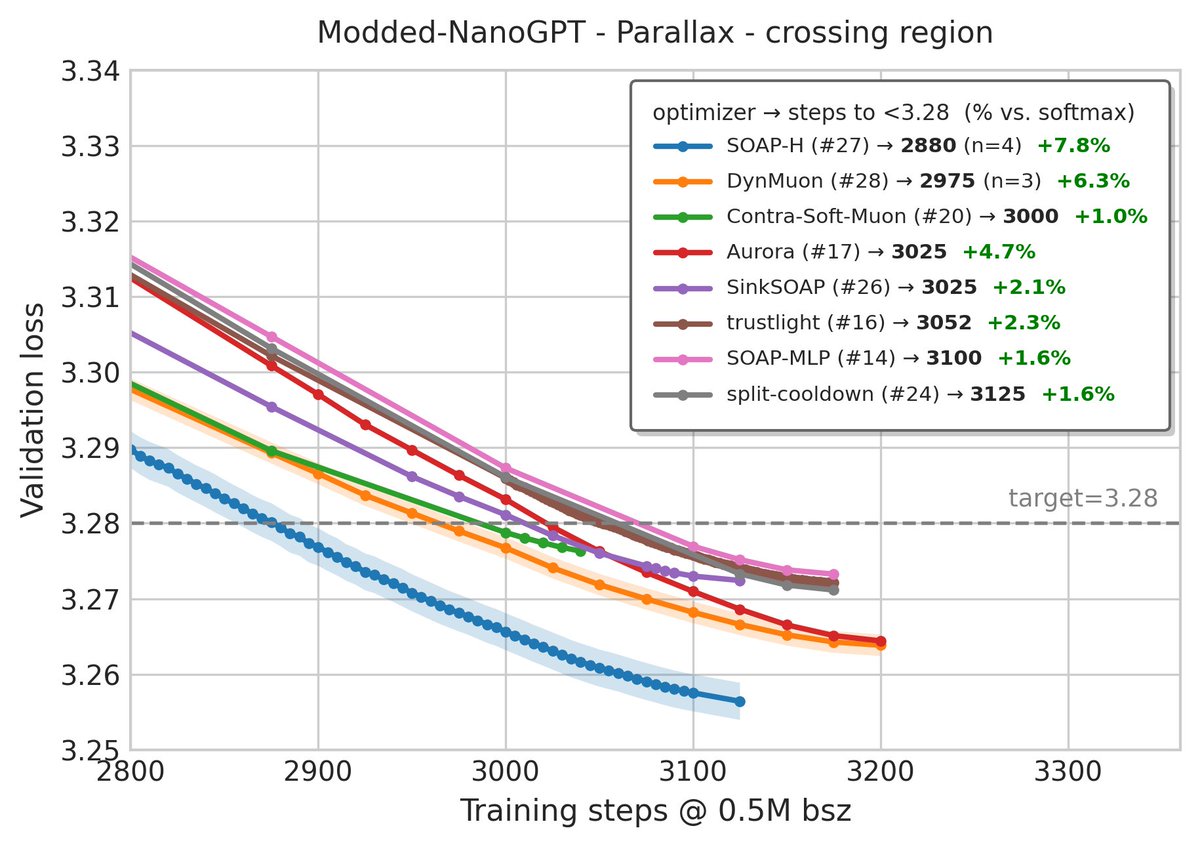
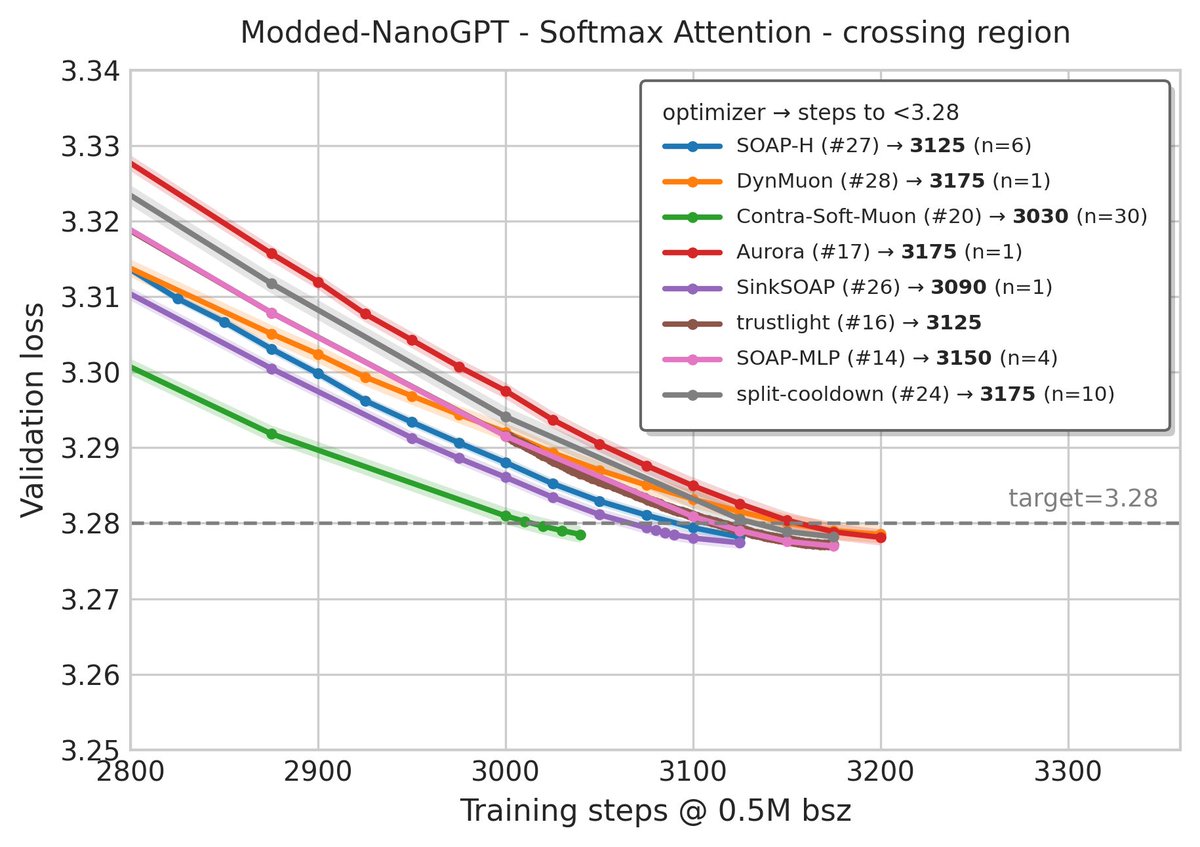
Very impressive results from Min Li and @Haoxiang__Wang: simply swapping Attention for Parallax reaches 2880 steps with the SOAP-H optimizer, beating the latest SOTA record on modded-nanogpt (@kellerjordan0) with no hyperparameter tuning.
A few observations:
- Parallax is uniformly stronger than Softmax Attention across all records.
- Optimizers don't transfer to Parallax with the same magnitude, which confirms the optimizer–architecture interaction from the Parallax paper.
- The cleanest modifications often transfer best; records built on heavy tuning transfer less reliably.
These are preliminary results, I believe both the Parallax architecture and the optimizer side have room to improve. Code is open-sourced below, give it a try.
Code: github.com/Yifei-Zuo/modded-…
Kernel: github.com/Yifei-Zuo/Paralla…
Paper: arxiv.org/abs/2605.29157
2
5
69
6,753

Jun 1
youtube.com/watch?v=wSp6AiNI…
$NVDA $MU $SNDK $LITE EXECUTIVE SUMMARY
The GTC Taipei 2026 keynote was a strategically important NVIDIA event staged around Computex in Taiwan and centered on a single operating thesis: agentic AI is shifting compute demand from episodic model training and chatbot inference toward persistent, tool-using, memory-intensive, latency-sensitive workloads that require entire AI factories rather than stand-alone GPUs. The source transcript frames the event as both a product launch and an ecosystem call-to-action for Taiwan, with Jensen Huang repeatedly emphasizing that NVIDIA’s Taiwan supply chain, ODMs, server makers, memory partners, packaging partners, and infrastructure partners are now central to scaling the next phase of AI compute. The keynote’s primary message was not simply that Vera Rubin is the next GPU architecture; it was that NVIDIA is attempting to define the full agentic AI system architecture across GPU, CPU, DPU, networking, storage, software runtime, AI factory design, enterprise agent tooling, PC agents, autonomous vehicles, and robotics. (Reuters)
The investment significance is that NVIDIA is broadening from an accelerator supplier into a vertically integrated AI infrastructure platform company. The event reinforced 5 key vectors: 1) Vera Rubin is ramping into full production as a 5-rack, POD-scale agentic AI system rather than a discrete GPU; 2) Vera CPU is positioned as a new data center CPU category optimized for agentic workloads and designed to expand NVIDIA’s share of rack-level bill of materials; 3) DSX is an attempt to make AI factory design, deployment, power management, cooling, operations, and grid integration part of the NVIDIA platform; 4) the Agent Toolkit, OpenShell, CUDA-X skills, and Nemotron 3 Ultra are designed to move NVIDIA higher into enterprise software orchestration; and 5) RTX Spark and DGX Station for Windows extend the agentic stack to PCs and deskside workstations. NVIDIA’s official materials state that Vera Rubin integrates Vera Rubin NVL72, Vera CPU, Groq 3 LPX, Vera BlueField-4 STX, and Spectrum-6 SPX Ethernet racks, with 10x agent throughput at scale versus Grace Blackwell and production shipments beginning this fall. (NVIDIA Newsroom)
The keynote was incrementally positive for NVIDIA’s medium-term data center durability because it provided a coherent architecture for why post-Blackwell demand should not mechanically fade after the current hyperscale buildout. The argument is that agentic workloads increase the amount of inference, retrieval, tool use, sandbox execution, memory movement, and orchestration required per user task, thereby raising the compute intensity of successful AI applications. This is a materially stronger demand narrative than a pure training-cycle story because it shifts the revenue model from periodic frontier model builds to always-on production workloads. However, the most promotional claims in the keynote, especially the conversion of GitHub commit growth into implied global productivity and the broad statement that “tokens are profitable units of revenue,” should be treated as directional rather than analytically proven. The correct investment framing is that agentic AI can raise inference intensity and infrastructure demand if application monetization scales, but the capex cycle still must convert into end-customer revenue, utilization, and cash flow. Reuters recently highlighted investor concerns that hyperscaler capex must increasingly show conversion into revenue growth over the next few quarters. (Reuters)
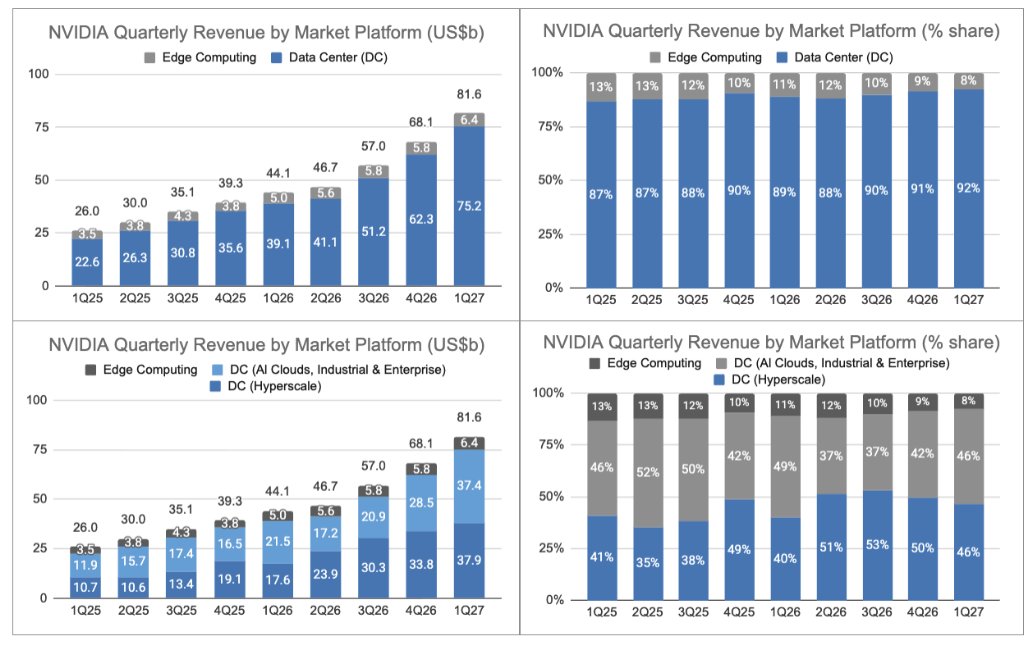
Financially, NVIDIA entered this event from a position of exceptional strength. Q1 FY27 revenue was $81.6 billion, up 85% year-over-year and 20% sequentially; Data Center revenue was $75.2 billion, up 92% year-over-year; GAAP and non-GAAP gross margins were 74.9% and 75.0%; and Q2 FY27 revenue guidance was $91.0 billion plus or minus 2%, with no China Data Center compute revenue assumed. Under the prior sub-market view, Data Center compute revenue was $60.4 billion, up 77% year-over-year, and Data Center networking revenue was $14.8 billion, up 199% year-over-year. The latest finance data show NVDA at $211.14, with a market cap of approximately $5.15 trillion and a P/E of approximately 32.1x, meaning the stock already prices a significant amount of execution success, revenue durability, and sustained margin power. (NVIDIA Investor Relations)
The objective investment conclusion is constructive but not unqualified. The keynote strengthened NVIDIA’s strategic moat by showing a plausible expansion from GPUs into rack-scale systems, CPUs, DPUs, networking, software runtime, data center operating software, edge PCs, and physical AI. The counterweight is that the strategy increases execution complexity, supply-chain dependence, energy and cooling exposure, geopolitical sensitivity, and customer ROI scrutiny. At this valuation, the equity is less about whether NVIDIA remains the dominant AI compute vendor and more about whether the company can sustain hyperscale and AI cloud demand through the Blackwell-to-Rubin transition while also monetizing CPUs, networking, software, and AI factory infrastructure without triggering faster substitution by custom ASICs, internal hyperscaler silicon, AMD, Intel, or sovereign alternatives.
KEYNOTE CONTENT AND STRATEGIC NARRATIVE
The keynote’s foundational claim was that the AI industry has crossed from generative AI into useful agentic AI. The transcript defines an agent as a model plus harness, tools, skills, memory, and runtime, with repeated cycles of observing, reasoning, planning, acting, and using external tools. This framing matters because it changes the compute bottleneck from a single model call to an end-to-end distributed workflow: LLM reasoning runs on GPUs, tool execution can run on CPUs and accelerated libraries, security and isolation run on DPUs, memory retrieval stresses storage, and orchestration requires low-latency CPU scheduling. NVIDIA’s argument is that a traditional server architecture is mismatched for this workload, which is why the company is packaging Vera Rubin as a disaggregated but tightly codesigned system.
The most important investment insight is that NVIDIA is attempting to redefine the unit of competition. Historically, the debate was GPU versus GPU, with AMD, custom ASICs, and internal hyperscaler silicon competing on accelerator performance, cost, power, availability, and software ecosystem. The keynote shifts the relevant unit to “tokens per watt per factory,” including time-to-first-token, uptime, power utilization, cooling efficiency, memory hierarchy, storage performance, networking reliability, security isolation, software compatibility, and asset life. This raises the competitive bar because it advantages a vertically integrated vendor that can codesign chips, racks, networking, software, and operations. It also increases NVIDIA’s potential revenue capture per AI factory because more of the system stack becomes proprietary or NVIDIA-defined.
The transcript repeatedly describes compute as revenue, performance per watt as revenue, and AI factories as financial assets whose output is tokens. This is the right conceptual frame for production AI economics, but it remains only partially proven across the broader market. In frontier labs, coding agents, search, advertising, recommendation systems, and selected enterprise automation, token generation can map to monetizable output. In many enterprises, however, AI deployment still requires workflow redesign, data governance, security approvals, change management, and measurable productivity capture. Therefore, the keynote is strongest as a supply-side architecture presentation and weaker as proof that every incremental GPU-hour will clear at attractive economic returns.
VERA RUBIN AND AI FACTORY IMPLICATIONS
Vera Rubin was the centerpiece. NVIDIA’s official announcement says the platform is ramping into full production, that top server makers and supply chain leaders are manufacturing Vera Rubin-based systems at scale, and that production shipments begin this fall. The platform is described as a 5-rack, purpose-built agentic AI supercomputer composed of Vera Rubin NVL72 systems, Vera CPU, Groq 3 LPX, Vera BlueField-4 STX storage, and Spectrum-6 SPX Ethernet racks, with 10x agent throughput at scale versus Grace Blackwell. NVIDIA also disclosed that hundreds of supply-chain ecosystem partners, including 150 in Taiwan, are ramping Vera Rubin across 350 factories and 30 countries. (NVIDIA Newsroom)
The Vera Rubin announcement materially extends visibility beyond the Blackwell cycle. The practical investor question has been whether Blackwell demand represents a 1-time buildout, an elongated supply-constrained cycle, or the 1st leg of a multi-generation AI infrastructure replacement curve. Vera Rubin’s full-system framing supports the 3rd interpretation. If agentic workloads are materially more CPU-, memory-, storage-, and network-intensive than standard chatbot inference, then the next generation is not simply “more FLOPS.” It becomes a different factory design problem. That benefits NVIDIA because its moat is strongest when the customer buys an architecture rather than a component.
The manufacturing claims are notable because they address the market’s most important near-term constraint: deliverability. The transcript says Vera Rubin’s supply chain is 2x as large as Grace Blackwell’s and that rack assembly time has been reduced from 2 hours to 5 minutes, while NVIDIA’s official materials say major system builders including Dell, HPE, Lenovo, Supermicro, ASUS, Foxconn, GIGABYTE, Pegatron, QCT, Wistron, and Wiwynn are adopting DSX or Vera Rubin-related systems. Even allowing for keynote promotional tone, this directly targets investor concerns around rack-scale complexity, liquid cooling readiness, networking supply, HBM availability, and time-to-revenue for cloud customers. (NVIDIA Newsroom)
The full-stack approach also changes the margin debate. A narrow view would assume future AI compute competition pressures accelerator gross margins as custom silicon proliferates. A broader view suggests NVIDIA can preserve economics by increasing total rack value through CPUs, networking, DPUs, storage processing, software, and infrastructure design. The Q1 FY27 data already show the importance of networking: under the prior sub-market view, Data Center networking revenue was $14.8 billion, up 199% year-over-year, far outgrowing the already extraordinary 77% growth in Data Center compute. This validates that NVIDIA’s AI infrastructure business is not merely a GPU-card business. (NVIDIA Investor Relations)
DSX AND THE AI FACTORY OPERATING LAYER
DSX is strategically important because it moves NVIDIA into the design and operating logic of AI factories. NVIDIA describes DSX as a platform that combines open-source modular software libraries, APIs, reference designs, accelerated computing platforms, and partner technologies for AI factory design, deployment, and operations. DSX MaxLPS is designed to maximize token performance per megawatt within fixed power budgets and, according to NVIDIA, can allow operators to run up to 40% more GPUs at their most energy-efficient operating point with minimal workload performance impact. DSX OS provides lifecycle management, runtime consistency, health automation, resiliency, multi-tenant operations, and platform services. (NVIDIA Newsroom)
This matters because power, cooling, and deployment latency are becoming financial constraints rather than engineering footnotes. At gigawatt scale, the scarce asset is not just the GPU; it is permitted power, liquid-cooling capacity, grid interconnection, commissioning speed, uptime, and utilization. A software and digital-twin layer that improves power allocation, rack placement, network validation, and remediation can have real economic value if it increases revenue-generating compute inside a fixed power envelope. The transcript’s discussion of DSX Sim, DSX OS, DSX MaxLPS, 45°C liquid cooling, dynamic power allocation, in-rack power smoothing, and grid-responsive DSX Flex reflects an attempt to turn AI infrastructure operations into a NVIDIA-controlled platform layer.
The risk is that DSX may be more enabling ecosystem glue than high-margin monetizable software in the near term. Large hyperscalers already have deep internal data center design, operations, and scheduling capabilities. For AI cloud providers, sovereign clouds, enterprise AI factories, and smaller regional players, DSX could be more differentiated because it reduces complexity and time-to-market. The most likely outcome is that DSX enhances hardware pull-through and customer stickiness before it becomes a large stand-alone revenue line. That is still strategically valuable because it protects NVIDIA’s architecture at the point where customers make multi-$10 billion infrastructure decisions.
VERA CPU AND THE CPU TAM EXPANSION
Vera CPU is arguably the most strategically consequential non-GPU announcement. NVIDIA’s official press release says Vera is the 1st CPU built for AI agents, is in full production, delivers 1.8x faster task completion versus x86 CPUs across agentic AI, reinforcement learning, and data processing, and uses 88 Olympus cores with LPDDR5X memory delivering up to 1.2 TB/s of bandwidth. NVIDIA also states Grace CPUs have nearly 2.5 million shipments to date, which provides an installed-base bridge from Grace Blackwell to Vera Rubin. Vera systems are expected to be available from system builders and cloud partners starting this fall. (NVIDIA Newsroom)
The CPU argument is technically coherent. Agentic systems often run Python runtimes, tool calls, database queries, sandboxed code execution, retrieval, memory management, and orchestration around GPU-bound reasoning steps. If the CPU becomes the gating factor that leaves expensive GPUs idle, then traditional “cores per dollar” server economics become less relevant than “agent task completion per watt” or “GPU utilization enabled per CPU watt.” NVIDIA’s keynote directly attacks x86’s historical model of maximizing rentable cores and positions Vera as a low-latency, bandwidth-rich coordinator for GPUs.
The investment implication is that NVIDIA is making a direct move into value pools historically controlled by Intel and AMD. The immediate risk to x86 server vendors is not a wholesale displacement of general-purpose enterprise servers; it is displacement in the highest-growth, highest-budget AI factory nodes where the CPU is attached to NVIDIA GPUs and where customers prioritize end-to-end token economics over vendor diversity. If Vera becomes the default host CPU for Vera Rubin and adjacent AI storage or sandbox workloads, NVIDIA gains more of the rack BOM, reduces reliance on third-party CPUs, and increases system lock-in through NVLink-C2C and confidential computing integration.
There is also an important competitive nuance. Custom AI accelerators from Google, Amazon, Meta, Microsoft, OpenAI-related programs, Broadcom-linked ASICs, and Marvell-linked custom silicon are the most credible medium-term pressure on NVIDIA accelerator economics. Vera CPU partially addresses this by increasing NVIDIA’s control over the surrounding compute fabric, not just the accelerator. The more NVIDIA can make the CPU, DPU, networking, software runtime, and memory architecture jointly optimize agentic workloads, the harder it becomes to compare a custom accelerator only on raw TOPS, FLOPS, or cost per chip.
ENTERPRISE AGENTS, SOFTWARE, AND NEMOTRON
The enterprise software portion of the keynote was strategically underrated relative to the hardware announcements. NVIDIA’s Agent Toolkit combines models, harnesses, tools, CUDA-X skills, and OpenShell secure runtime. NVIDIA’s official materials state that the toolkit includes NemoClaw blueprints, Nemotron models, OpenShell, and CUDA-X libraries with agent skills. Cadence, Dassault Systèmes, Siemens, and Synopsys are among the 1st software leaders using the stack to build autonomous AI engineers for simulation and verification workflows. NVIDIA also stated that Cadence and NVIDIA verification agents can compress weeks of engineering work into hours, and the transcript cites verification cycles over 40x faster. (NVIDIA Newsroom)
This is a direct attempt to make CUDA-X relevant in the agent era. If AI agents become users of domain-specific software tools, libraries, simulators, solvers, and databases, then NVIDIA can expose CUDA-X libraries as callable agent skills. That would extend CUDA’s moat from human developers writing accelerated code to agents autonomously choosing NVIDIA-optimized tools. The transcript explicitly frames CUDA-X libraries as tools for agents, including computational lithography, optimization, sparse solvers, deep research, AI-RAN, differentiable physics, and genomics.
Nemotron 3 Ultra was presented as the open model foundation for enterprise agents. NVIDIA’s official announcement describes Nemotron 3 Ultra as a 550 billion-parameter mixture-of-experts model built for long-running agents, with up to 5x faster inference and up to 30% lower cost versus open frontier models in its class. The model is post-trained for major agent harnesses including Hermes Agent, LangChain Deep Agents, OpenClaw, OpenHands, and OpenCode. The strategic point is not that NVIDIA must win the general-purpose model race against OpenAI, Anthropic, Google, Meta, or xAI; rather, NVIDIA can provide efficient open models and runtime infrastructure that increase utilization of NVIDIA systems and reduce friction for enterprises deploying on NVIDIA infrastructure. (NVIDIA Newsroom)
The software read-through is mixed. For EDA and industrial software vendors, agentic workflows can expand usage by automating more simulations, verification cycles, and design iterations. That is positive for Cadence, Synopsys, Siemens, Dassault, and other tools vendors if pricing captures incremental usage. For seat-based enterprise software, the agent thesis is more ambiguous. Agents may increase tool calls and API consumption, but they can also reduce human seats, compress services hours, and shift value capture toward orchestration layers, model providers, and infrastructure. NVIDIA’s keynote naturally emphasizes expansionary tool usage, but the investment outcome will depend on how software vendors reprice from seats to outcomes, transactions, tokens, or agent actions.
RTX SPARK, WINDOWS AGENTS, AND THE PC EDGE
RTX Spark is NVIDIA’s attempt to re-enter and redefine the PC market for local agentic AI. NVIDIA’s official release says RTX Spark powers the world’s 1st Windows PCs purpose-built for personal agents, with 1 petaflop of AI performance, up to 128 GB of unified memory, a Blackwell RTX GPU with 6,144 CUDA cores, a 20-core Grace CPU, MediaTek collaboration, and Windows-native security primitives plus NVIDIA OpenShell. Systems are expected from ASUS, Dell, HP, Lenovo, Microsoft Surface, and MSI this fall, with Acer and GIGABYTE models to follow. (NVIDIA Newsroom)
The strategic rationale is clear. If personal agents need continuous local context, privacy, low latency, file access, and cross-application control, then all inference cannot be cloud-only. Local AI PCs would reduce metered cloud anxiety, improve responsiveness, preserve privacy, and create a new premium replacement cycle. RTX Spark also extends CUDA, TensorRT, RTX, DLSS, and NVIDIA developer tooling to an edge platform that could run local models, agent runtimes, creative workflows, coding tools, and games. Reuters correctly framed RTX Spark as a direct competitive move against AMD, Intel, Qualcomm, and Apple in AI PCs. (Reuters)
The near-term financial materiality is likely lower than the data center announcements, but the strategic optionality is meaningful. Even a successful premium AI PC cycle would not match current Data Center scale in the near term, given Q1 FY27 Data Center revenue of $75.2 billion versus Edge Computing revenue of $6.4 billion. However, RTX Spark matters because it prevents the agentic edge from being dominated by Apple silicon, Qualcomm ARM PCs, AMD APUs, Intel AI PCs, or Microsoft-controlled silicon road maps. It also gives NVIDIA a way to participate in agentic workflows that move from cloud to device due to privacy, latency, or cost constraints. (NVIDIA Investor Relations)
Execution risk is high. The PC market is price-sensitive, Windows-on-ARM history has been uneven, battery life and thermals must meet consumer expectations, and most users still lack must-have personal agents that justify a premium hardware upgrade. The better base case is not immediate mass adoption; it is a high-end developer, creator, workstation, and enthusiast wedge that establishes a local AI software ecosystem. Adobe’s rearchitecture of Photoshop and Premiere for RTX Spark, with NVIDIA claiming up to 2x faster AI and graphics performance, is an important ecosystem proof point because creative professionals are among the most plausible early adopters of local AI acceleration. (NVIDIA Newsroom)
PHYSICAL AI, COSMOS, AUTONOMOUS VEHICLES, AND ROBOTICS
The physical AI portion of the keynote extends the agentic pattern into robotics, autonomous vehicles, manufacturing, satellites, base stations, and industrial systems. The transcript’s key conceptual point is that physical AI is constrained by data from the robot’s perspective, not merely by model capacity. Most video data is 3rd-person, while robot policies require egocentric and action-conditioned understanding. This is why NVIDIA frames simulation, Omniverse, Cosmos, and synthetic data as critical infrastructure for robotics.
NVIDIA’s official announcement says Cosmos 3 is an open physical AI foundation model built on a mixture-of-transformers architecture that combines vision reasoning, world generation, and action prediction. NVIDIA describes it as a fully open omnimodel that can understand and generate text, images, video, ambient sound, and actions, and says Cosmos 3 Super and Cosmos 3 Nano are available now, with Cosmos 3 Edge coming soon. The company also announced the Cosmos Coalition with robotics and AI model partners including Agile Robots, Black Forest Labs, Generalist, LTX, Runway, and Skild AI. (NVIDIA Newsroom)
Alpamayo 2 Super extends the physical AI stack into robotaxis. NVIDIA describes it as a 32 billion-parameter open reasoning vision-language-action model for safe level 4 robotaxi development, with AlpaGym for closed-loop reinforcement learning and OmniDreams for photorealistic closed-loop AV scenario generation. The importance is less near-term revenue and more platform positioning: NVIDIA is trying to offer the model, simulator, data pipeline, in-vehicle compute, and ecosystem tooling for autonomy developers. (NVIDIA Newsroom)
The Isaac GR00T humanoid robot reference design is also more strategic than immediately financial. NVIDIA’s official materials describe an open humanoid reference design built on Jetson Thor and Isaac GR00T, combining a Unitree H2 Plus humanoid robot, Sharpa 5-finger hands, Jetson Thor onboard compute, and open software. The system is nearly 6 feet tall, weighs 150 pounds, includes 75 degrees of freedom across body and hands, and will be available from Unitree in late 2026. The investment relevance is that NVIDIA is standardizing the research and developer stack for humanoids, similar to how DGX standardized AI training infrastructure. This can seed future demand for Jetson Thor, simulation, Omniverse, robotics software, and edge inference, but humanoid commercialization remains uncertain and likely multi-year. (NVIDIA Newsroom)
5
2
6
13,265

$NVDA Nvidia announced the Nvidia DSX platform, which gives infrastructure builders a playbook to create AI factories. Nvidia DSX brings together open source, modular software libraries, application programming interfaces, reference designs, Nvidia accelerated computing platforms and partner technologies into a common, codesigned platform for AI factory design, deployment and operations. "We're not just shipping chips - we're giving every infrastructure builder a complete playbook to build AI factories," said Jensen Huang, founder and CEO of Nvidia. "With the DSX platform, you can simulate the entire factory before you spend a dollar, validate performance before a single rack is installed and operate with the kind of reliability that production AI demands."
2
4
33
4,654

Jun 1
$IREN - At GTC Taipei yesterday, NVIDIA unveiled the DSX platform, a complete "playbook" for building AI factories that ties together silicon, systems, open source modular software, reference designs, facilities and partner technologies into one codesigned framework.
The stated goal is to drive the lowest token cost and accelerate time to first production by aligning every layer of the stack.
Key new components include DSX MaxLPS, which maximizes token performance per megawatt within a fixed power budget by combining 45°C liquid cooling with in-rack technologies to run up to 40% more GPUs at their most energy efficient operating point.
And guess who is working with $NVDA to build DSX-aligned AI infrastructure across its global data center portfolio. -> IREN 🧐


10
14
232
18,059

May 29
every day many thousands (millions?) are hooking up model harness codesigned agent systems to exclusive datasets (real world tasks). improvement signals are drawn from actual use.
Harness Hyper War: Moat is Sticky Agents
May 29

LARRY ELLISON: AI IS RAPIDLY COMMODITIZING BECAUSE MOST MODELS ARE TRAINED ON THE SAME PUBLIC INTERNET DATA.
THE REAL COMPETITIVE EDGE ISN’T THE MODEL ANYMORE — IT’S ACCESS TO EXCLUSIVE, PROPRIETARY DATASETS.
THAT MAY BE THE ONLY MOAT LEFT.
1
7
722

This what DSX Sweetwater will soon look like 👀
Nvidia x Iren
$IREN
- The new NVIDIA Vera Rubin DSX AI Factory reference design provides a guide for building codesigned AI infrastructure that delivers maximum token per watt and accelerated time to first production.
- The NVIDIA Omniverse DSX Blueprint, now generally available with the NVIDIA Vera Rubin AI Factory reference design, powers digital twins for large-scale AI factory design and simulation.
- Industry leaders Cadence, Dassault Systèmes, Eaton, Jacobs, NScale, Phaidra, Procore Technologies, PTC, Schneider Electric, Siemens, Switch, Trane Technologies and Vertiv are contributing to the DSX architecture and blueprint by integrating platforms, providing SimReady assets and connecting software to help design, build and optimize AI factories.
(Iren already works with Schneider Electric at Childress H1-H4)
- Energy leaders Emerald AI, GE Vernova, Hitachi and Siemens Energy are using the NVIDIA DSX reference architecture to unlock grid capacity, delivering the power needed to build and connect new AI factories.
nvidianews.nvidia.com/news/n…


5
3
61
6,492

May 26
Ferrari Luce: Stock market reacts to the Italian luxury sports carmaker’s first EV, codesigned by Jony Ive f-st.co/0rCSFbr
1,916

ok tbh unfair comparison because Jony codesigned the interior not the exterior but I couldn’t help myself lol
2
9
1,591

Yes. Balanced. Finally. None of this obsessive fury and finger pointing. He said. She said. They said. IMO Had the numbers been lower, had Berkeley spoken to locals and all three worked together. Were the cost of land determined differently, a lovely, perhaps even beautiful gentle density scheme could have been agreed on by all sides. As it is there is nothing. Millions of pounds and words wasted. Animosity grown. Planning in the UK really is a masterclass in division. Had everyone sat around a table and everyone agreed some kind of compromise I am sure this would not have happened. Collaboration is the name of the game. It’s all too high stakes. The very successful Phase 1 of the Heygate estate was codesigned with the local community. It is that part that is the posterboy for the scheme.

2
42

May 23
Eventually DS 5 / 6 will be codesigned deeply with Huawei Hardware , even if US labs could copy there will be a significant delay for them to put it in production . Ant OAI will thrive but rest of non sino labs will struggle hard without DS research to leech from .
6
579

May 21
Agentic AI that does your work efficiently, and on your device.
Releasing MagenticLite: an agentic stack built for small models. Browser tasks, local files, forms, bookings.
MagenticBrain orchestrator Fara1.5 (SOTA small CUA) a harness codesigned for both.
youtube.com/watch?v=wKMQ3CZi…
aka.ms/MagenticLite
24
35
276
1,496,992

NVIDIA $NVDA 1Q27 Earnings
- Rev $81.6b 85% ⤴️🟢
- GP $61.2b 129% ⤴️🟢 margin 74.9% 1441 bps ✅
- NG EBIT $53.8b 147% ⤴️🟢 margin 65.9% 1642 bps ✅
- EBIT $53.5b 147% ⤴️🟢 margin 65.6% 1649 bps ✅
- NG Net Inc $45.5b 139% ⤴️🟢 margin 55.8% 1247 bps ✅
- Net Inc $58.3b 211% ⤴️🟢 margin 71.5% 2885 bps ✅
- OCF $50.3b 84% ⤴️🟢 margin 61.7% -53 bps ↘️🔴
- FCF $48.6b 86% ⤴️🟢 margin 59.5% 10 bps ✅
Compute & Networking
- Rev $74.6b 88% ⤴️🟢
- Data Center Rev $60b 77% ⤴️🟢
- Data Center Networking Rev $15b 200% ⤴️🟢
- EBIT $53.3b 142% ⤴️🟢 margin 71.5% 1584 bps ✅
Graphics
- Rev $7.1b 58% ↗️🟢
- EBIT $2.9b 79% ⤴️🟢 margin 41.6% 496 bps ↘️🔴
Revenue by Geography
- US $63.8b 148% ⤴️🟢
- Taiwan $12b 57% ↗️🟢
- China $4.6b -53% ↘️🔴
- Other $1.3b 21% ↗️🟢
Revenue by Segment (new reporting)
- Data Centre $75.2b 92% ⤴️🟢
- Data Centre (Hyperscale) $37.9b 115% ⤴️🟢
- Data Centre (Al Clouds, Industrial, and Enterprise - ACIE) $37.4b 74% ⤴️🟢
- Edge Computing $6.4b 29% ↗️🟢
2Q27 Mgmt Guide
- Rev $91b 95% ⤴️🟢
- GP $68.2b 101% ⤴️🟢 margin 74.9% 248 bps ✅
- EBIT $59.7b 110% ⤴️🟢 margin 65.6% 472 bps ✅
1 | Exceptional quarter 85% and 20% QoQ.
We delivered an exceptional quarter with revenue, operating income and free cash flow exceeding our prior records. Total revenue of $82 billion was up 85% year-over-year and 20% sequentially. This marked our third consecutive quarter of year-over-year acceleration and the 14th straight quarter of sequential growth, a significant feat given the sheer size and complexity of our manufacturing operations. The $13.5 billion sequential revenue increase was also a record.
2 | Driven by data center which grew 92% and 21% QOQ, driven by Blackwell GB300 demand.
Data center revenue of $75 billion was up 92% YoY and 21% QoQ, driven by sustained strength in our Blackwell architecture and demand for GB300 NVL72 was particularly strong with Frontier motto builders and hyperscalers each having cumulatively deployed hundreds and thousands of Blackwell GPUs, marking the fastest product ramp in our company's history. Grace Blackwell is the fastest training system as well as the lowest token generation cost at Inference.
3 | Networking revenue was 3X with strength in Spectrum-X Ethernet, which is now the largest, and Infiniband grew 4X.
Spectrum-X, our end-to-end Ethernet platform purpose-built for AI is now larger than all Ethernet network peers combined. InfiniBand has also had a very strong quarter, growing more than 4x YoY, driven by deployments of our next-generation XDR technology. For your models, data center computing revenue of $60 billion was up 77% YoY while data center networking revenue of $15 billion, nearly tripled YoY.
4 | Transiting from the previous Compute and Graphics Segment report in a new one with Data Center, data center and ACIE, and edge computing, because the customers and applications are different.
transition to a new reporting framework that better reflects our current and future growth drivers. We have 2 market platforms, data center and edge computing. Within data center, we will report 2 submarkets hyperscale and ACIE, which incorporates AI clouds, industrial and enterprise. Hyperscale will include revenue from the public cloud and the world's largest consumer Internet companies, while ACIE addresses our growth opportunities in diverse AI purpose-built data centers and AI factories across industries and countries. Edge computing highlights devices for agent and physical AI, including PCs, gaming consoles, workstations, AI RAN base stations, robotics, and automotive.
on the segmentation and the description of the business. We wanted you to understand our business better. AI is very diverse and computing is diverse. They're diverse in several ways. . The first thing, of course, is AI includes languages and depending on the different industries…The second thing is the applications are diverse.
5 | New reporting also helps to understand the business better, because every segment has different stacks, different OS, and operates differently. NVIDIA also goes to market with them differently. Hyperscale is the easiest because it's just five to six of them, and the rest with over 250,000.
So that's the reason why we broke it all apart this way. It's the simplest way of understanding our business. Each one of them have different stacks in a lot of ways. They have different operating systems. They operate in a different way.
We go to market very differently in each one of them. The easiest go-to market, of course, is the hyperscaler because they're only 5 or 6 of them. But the rest of the industry represents a couple of 250,000 companies around the world. That go-to-market is very complex, very diverse. Your understanding of AI has to be extremely diverse.
6 | AI Cloud revenue more than 3X, Sovereign revenue grew strongly at 85%.
Moving back to our data center results. Hyperscale revenue of $38 billion was approximately 50% of data center revenue and increased 12% QoQ. ACIE revenue was $37 billion and grew 31% QoQ, including AI cloud revenue that more than tripled YoY. Our customers have enabled rapid stand-up of AI compute capacity. The number of partners exceeding 10 megawatts has nearly doubled in just 1 year, now surpassing 80 sites. Sovereign revenue increased more than 80% YoY. NVIDIA AI infrastructure is now deployed across nearly 40 countries, representing $50 trillion in GDP. As evident to our Q1 results, our customer base is diverse and growing.
7 | H100s and A100s pricing continue to stay strong. Customers are generating profitable revenue beyond the depreciable life of their GPUs.
The price of renting a H-100 has risen 20% year-to-date, while A100 cloud pricing is up nearly 15%. Benefiting from the versatility of our platform and continuous performance enhancements enhanced by our software stack, customers are generating profitable revenue beyond the depreciable life of their GPUs. The vast and trusted marketplace for NVIDIA compute is a critical foundation on which billions and AI infrastructure spending is being financed by the ecosystem.
8 | The two primary drivers behind the accelerating build-out of AI infrastructure shift to recommender systems and content understanding with GPU-based accelerated computing and the growing adoption of AI products and services as it moves to reasoning and agentic.
There are 2 primary drivers behind the accelerating build-out of AI infrastructure. First, from search and advertising to recommender systems and content understanding. The largest hyperscale workloads continue to transition from CPU to GPU-based accelerating computing. Second, the adoption of products and services native to AI is inflecting. Since the advent of ChatGPT, we have witnessed mainstream AI transition from one-shot inference to reasoning and to now agent AI is no longer a nice to have. AI is now a necessity for enhancing productivity across all industries and roles.
9 | Analysts are now forecasting hyperscale capex to exceed $1T in 2027. With agentic AI, AI infrastructure spending is on track to reach $3 to $4T annually by the end of 2030.
With analysts now forecasting hyperscale CapEx to exceed $1 trillion in 2027 and Agentic-AI beginning to proliferate all industries AI infrastructure spending is on track to reach $3 billion to $4 trillion annually by the end of this decade. Our Blackwell architecture is everywhere, adopted and deployed by every major hyperscaler, every cloud provider and every major model maker.
10 | NVIDIA supports all major frontier AI labs with the addition of Anthropic.
First, NVIDIA is the only platform that runs every Frontier AI model. With the addition of Anthropic to our existing partners, OpenAI, X-AI, Meta MSL, Gemini and many others, our share of Frontier AI is growing.
We will support the company's growth trajectory through AWS, Azure, [ Core ], Space-X AI and more. Now with the addition of Anthoropic-2, OpenAI, Gemini, [ SpaceXXAI ], Meta, MSL, Microsoft AI, TML, Reflection, Complexity, Cursor, and other major frontier labs already building on NVIDIA.
11 | The stronger share of revenues from Anthropic would definitely help to boost NVIDIA’s growing share of hyperscaler CapEx, with significant capacity to come online in 2026-27.
And so if you look at the segmentation and the size of each, you could see that, in fact, we're growing share in the hyperscalers because we now have much bigger support from Anthropic, a new partner of ours, and we're helping them expand their capacity greatly in the coming years. And then the second very few companies have exposure into the second category because of the platform solution that we have.
And so the amount of capacity that we're going to bring online for Anthropic this year and next year is going to be quite significant, very significant. And so we're growing -- and our coverage of Anthropic has been largely 0 until just recently.
12 | NVIDIA delivers the industry's lowest token cost, the highest token throughput, and the highest ROI. NVIDIA compute is not just the highest performance but the most economic and financeable.
With our extreme codesign approach, we deliver the industry's lowest token cost, the highest token throughput and the highest ROI. [ MLPerf ] inference results are in. And once again, we swept every benchmark as Blackwell Ultra delivered the highest throughput across the broad set of models and deployment scenarios. Full stack innovations drove the 2.7x increase in throughput and a 60% reduction in the cost per token on GB300 compared to just 6 months ago.
NVIDIA compute is not just the highest performance AI infrastructure. It is the most economic and financeable. Customers do not buy GPUs. They build AI factories and the right economic metric is not the purchase price of the GPU. It is the life top cost of an AI factory producing intelligence, tokens per dollar, uptime, utilization, time to production, software durability and asset light. NVIDIA excels at all of them.
13 | Agentic AI and RI presents growth opportunities for CPUs and for the new arm-based Vera CPUs to dominate with a $200bn TAM. NVIDIA now has visibility to nearly $20 billion in total CPU revenue for 2026, and it's set up to be the world's largest CPU supplier.
Agentic-AI and reinforcement learning represents new growth opportunities for CPUs. Building on the success of our Grace CPU, Vera is arriving just in time to meet this inflection. Built on custom arm [indiscernible] and codesigned end-to-end with Rubin GPUs and NVLink, Vera will deliver up to 1.5x faster performance per core, 2x performance per watt and 4x density per rack compared to x86-based alternatives.
Vera CPU opens a brand-new $200bn TAM for NVIDIA a market we have never addressed before. And every major hyperscale and system maker is partnering with us to get it deployed. We have visibility to nearly $20 billion in total CPU revenue this year, setting us up to become the world's leading CPU supplier.
14 | Vera Rubin production shipments are slated to commence in H2, starting in Q3.
Our annual product patients, a pace that is unmatched remains a key pillar supporting our market position. We are on track to commence production shipments of Vera Rubin in the second half of this year starting in Q3 by integrating 7 purpose-built chips across 5 accelerated racks, Vera Rubin will deliver up to 35x higher inference throughput and up to 10x greater AI factory revenue compared with Blackwell.
15 | Thinking happens on GPUs, but orchestration is on CPUs. Expects more C-CPUs to be used, and Vera, which is an agentic CPU, is well-positioned to dominate.
All of the thinking happens on GPUs, all of the orchestration essentially runs on CPUs. And the subagents when they're spun off, they -- when they're thinking they use GPUs.
With respect to CPUs, an agent is essentially what people call a harness. And so the harness runs on the CPU. And the tool runs on CPUs.
So we're going to need a lot more CPUs, and Vera was designed to be an agentic CPU. The CPUs of the past were designed to have many cores so that it could be easily rentable. People rent at cores. Well, agents don't rent cores. They just want the work to be done fast.
The economics of the past was dollars per core. That's the economics of cloud computing of the past. The economics of the AI of the future is tokens per dollar or dollars per token. And so what we need to do in the future is to generate tokens, process tokens as fast as possible, and that's what Vera does incredibly well. So we're expecting to be very successful with Vera.
16 | NVIDIA is growing its share in inference very quickly.
Well, we are growing share in inference, and we're growing share in inference very, very quickly. And the reason for that is this year, the number of frontier model companies grew. And so there's Cursor and [ Complexity ] and there's some new model companies, TML and Reflection and the list goes on. And so the number of frontier model companies has grown, and we added Anthropic to our partnership this year. They're expanding incredibly fast.
is that we're gaining share in inference…Remember, so far, everything that I've just explained in the inference question is really focused on hyperscale. Remember, there's a whole second category of AI data centers that we serve almost uniquely.
17 | LPX It's designed for low latency and high token rate, and because its throughput is low, its model size capacity is low due to its ability to absorb lesser context. Sees the product as being niche and will only be bought by customers who have different types of token services. Well, today might be less than 20%, excited that this could be much higher.
The LPX is designed for low latency and high token rate. But its throughput is low, its throughput is low. It's model size capacity is low. And it's context processing, its ability to absorb a lot of context, for example, for software coding, for agentic workloads, its ability to absorb a great deal of context is lower. And so the -- so the challenge is simply, and I've explained before that the use case for LPX is not broad.
It's intended for somebody who has a fairly large portfolio of different types of token services. And for the high token rate, maybe these services are quite premium and the number of customers is not significant, but the token rate is very high. And so that remains exactly consistent with what I've said before, and I still expect that. And so -- so I expect that LPX and other SRAM-based decode focused -- high token rate generated focused accelerators will always be -- would be a niche product for some time to come.
And I think whether it's 20% or 10% just depends on where we are in the development of AI. I think today, it's a lot less than 20%. Some day, these premium tokens could be 20% and we're ready to work with service providers to enable this capability. I'm excited about it.
18 | NVIDIA's chips are well positioned for AI native clouds because they take care of all of the design and manufacturing and allow them to focus on renting out the most rentable, best performing chips to their customers that are the easiest to finance.
First of all, you're correct that AI native clouds -- AI native clouds don't build chips, don't design their own chips, and they don't want to -- they can't really assemble unrelated parts together into an AI factory. And their time -- their patients, their tolerance for time to first token is extremely low and their need for an architecture that has a great deal of offtake so that it runs every model as customers from everywhere is incredibly high. And so that's the reason why NVIDIA's architecture is so perfect for them. We offer every component and whatever we don't offer our ecosystem of partners offer it, and it's all fully integrated. It all works together.
The number of customers that could rent it from an AI native is incredibly high. Basically, every single AI builder, every AI native startup around the world. SaaS companies, enterprise companies, industrial companies. And so our computing -- our architecture is the most rentable of any computing platform in the world. So it's the most performing. It's the easiest to put together. It's the most rentable, has the best TCO and it's the easiest to finance. And so all of those properties are quite unique to the needs of AI native.
19 | While edge computing is growing slower than data center, optimistic about physical AI, and it continues to gain momentum with TTM revenue of $9bn.
Our edge computing market platform generated $6.4 billion, up 10% QoQ and 29% YoY. Robust Blackwell workstation demand was a strong contributor to the growth while consumer demand fell modestly due to higher memory and system prices. Our physical AI continues to gain momentum, exceeding $9 billion in revenue over the last 12 months. Our partnership with Uber will power the Robotaxi fleet across nearly 30 cities and 4 continents by 2028.
And then, of course, physical AI. NVIDIA is practically the only company serving physical AI today. And we've been working on physical AI for a long time. And so that is also growing.
20 | NVIDIA now plans to return around 50% of free cash flow to shareholders, through dividend or share buybacks.
We plan to review our dividend on a regular basis as we continue to scale our business. We are also announcing an $80 billion share repurchase authorization, which is in addition to the $39 billion remaining on our current plan. As we indicated at GTC, we plan to return roughly 50% of free cash flow to shareholders this year.
21 | Expects the value pyramid to eventually invert in the longer term as it moves from the semiconductor and infrastructure to the application layer
If you look at that segment, it started growing after the AI ecosystem developed in the hyperscale. Hyperscale developed AI first for a lot of reasons. They have great computer science. They have excellent data center capability. And they also focus largely on consumer applications, which, if not perfect, is not the end of the world.
It enhances the service so long as it enhances the service. And so for many of the other applications, industrial applications, enterprise applications, until the AI is very capable and thus really productive work and does it safely, and it could do it in a way that can actually generate impact in income, it doesn't really get used. And so you expect the second category to develop slower than hyperscale, and you could see that in the numbers.
However, long term, if you look at industrial and enterprise, clearly, that's where future economics is going to be because it represents some $50 trillion, $80 trillion of the world's economy. And so -- and it's going to be larger than that because of AI. And so I expect the second category to be larger over time, both in the near term over the next several years, I think it's a foregone conclusion, both are going to grow incredibly fast I expect the second category to still grow faster, but both are going to grow incredibly fast.
22 | Continue to expect sequential growth driven primarily by the data center, and they have full confidence in $1T of Blackwell and Rubin revenue from 2025 to 2027.
We expect sequential growth to be driven primarily by data center. We are continuing to work vigorously on our supply chain ecosystem to address the incredible demand we see ahead of us, giving us full confidence in the $1 trillion in Blackwell and Rubin revenue we foresee from 2025 through calendar 2027.
23 | Think they should be growing faster than hyperscale capex, because compute is revenue and profit, and if they don't have compute, they have neither.
So first of all, we should be growing faster than hyperscale CapEx. And the reason for that is illustrated by the segmentation that I just described. Our data center business has 2 large parts. And so if you look at the first part, it's hyperscalers. That's the hyperscale CapEx that you were just talking about. And there are $1 trillion this year. I -- very expectation is going to grow from here for fundamentally good reasons. This is the way computing is going to work in the future. And if they don't have the compute, they won't have the revenues. It is very clear, compute is revenues, compute is profit. And so the world is changing. Software didn't use SaaS, it didn't use as much compute, but AI requires a tremendous amount of compute.
➡️ Final Takeaways on NVIDIA $NVDA:
NVIDIA continues to ride the long-term AI structural tailwind by being one of the key innovators and suppliers of AI architecture, supporting strong visibility through multi-year capex. Led by the visionary leadership of Jensen Huang, NVIDIA dominates with a strong, unified, and backward-compatible architecture; software CUDA; a growing networking moat; and the ability to keep innovating faster than its competitors at a faster cadence and at an ever-larger scale. Seeing strong demand in Grace Blackwell and Rubins. Particularly excited about the rapid growth in networking and CPUs, which is extremely complementary to their GPUs.



4
14
62
3,137

May 18
Thinking about how OAI has codesigned the codex harness and the model, I can only imagine they have put a lot of effort into optimizing 5.6 for /goal
Making it infer your intent better and making it more creative to overcome plateaus
2
246

May 17
nowadays seems like the model codesigned agent harness is the product
1
10
965


May 13
$IONQ
150 to 250 logical qubits. By 2028. Issued from Oak Ridge.
The DOE Office of Science just published an RFI under the internal title "Quantum Supercomputer Request for Information." Full official label: "Scientifically Relevant Fault-Tolerant Quantum Computing Systems." Notice ID 892431-26-RFI-0001. Deadline: June 9. Open to all bidders, no set-aside.
Before getting to the targets, read the vocabulary.
Direct citations from the document:
→ "computing capabilities for science and national security"
→ "in concert with High-Performance Computing and Artificial Intelligence"
→ "uniquely suited, optimized, or codesigned for DOE's science mission, as opposed to generic quantum computation"
→ "unit costs for smaller, fully functional quantum computing modules"
→ "activities that may not already be on a vendor's plan of record"
→ "time-to-solution or total cost of ownership"
That last phrase is the title of IonQ's 2026 commercial campaign. Rolls-Royce, Einride, LG Electronics, KISTI Korea all packaged under "Time to Solution." The DOE's procurement language and IonQ's commercial language have merged.
The 2028 targets:
→ 150–250 logical qubits
→ Universal instruction set
→ 10⁵ hard operations (T / Toffoli)
→ 10⁻⁸ logical error rate per operation
Mid-2030s scale-up in the same document: O(10⁹) hard gates on 1000 logical qubits, applied to chemistry, materials, plasma physics, high energy physics.
The HPC Quantum AI triptych the RFI emphasizes also sits at the heart of the Genesis Mission, launched by the DOE and White House OSTP on January 16 $293M for AI × science breakthroughs. This RFI is the fault-tolerant leg of that mission moving from policy to procurement design.
Three weeks before this RFI, IonQ published the Walking Cat blueprint on arXiv (2604.19481): 2,514 physical qubits for hundreds of logical ones, every hardware component already demonstrated in the labs. Modular by design exactly the architecture the RFI invites to be priced "in smaller, fully functional quantum computing modules."
IonQ's own 2028 target, in the annual report signed by De Masi two weeks ago: 8,000 logical qubits and 200,000 physical qubits. 32x the upper end of the DOE ask. Backed by a 99.99% two-qubit gate fidelity the world record needed to approach the 10⁻⁸ logical error rate the RFI requires.
The contracting office sits at PO BOX E, Oak Ridge, TN 37831:
→ IonQ has been an industry partner of the Oak Ridge QSC Phase II program ($125M, 2025–2030) from day one.
→ The Discovery supercomputer lands at Oak Ridge in 2028 the same year as the RFI target.
→ IonQ's Director of Quantum Applications, Martin Suchara, joined from Argonne National Lab where he co-founded DOE Q-NEXT, one of the five DOE National QIS Centers under the same Office of Science that just issued this RFI.
The RFI asks for modules. Beyond DOE, IonQ is also the only commercial winner of DARPA HARQ the federal quantum interconnect program that makes those modules talk to each other. On April 14, AFRL demonstrated entanglement between two commercial IonQ systems, validating the modular interconnect any scaled FTQC will require.
The RFI also encourages respondents to "use external expertise to complement their core capabilities" exactly the ecosystem IonQ has been building all year with NVIDIA, the Dell Federal cohort, and the National Lab complex.
And it asks each respondent how their system is "uniquely suited" to DOE's mission, "as opposed to generic quantum computation." That language is not accidental.
An RFI is not a contract. But this one reads like the procurement design phase for a machine someone has already specified out loud.
The DOE asked the market a question yesterday. Three weeks ago, IonQ had already published the answer from the same campus where IonQ already works.
🔗 sam.gov/workspace/contract/o…
$IONQ #IonQ #Quantum #DOE

5
12
94
27,876

May 13
Bill Gates’ job…..
CoDesigned by James Cutler. Gates Residence Medina, Washington, overlooking Lake Washington.

2
1
12
2,083