
YMIN Military Capacitors: Wide temp & high voltage resistant, direct import replacement, cut costs & supply chain risks
ymin.cn/news/ymin-military-g…
#YMINElectronics #MilitaryManufacturing #SolidCapacitors #SupplyChainSecurity #ComponentSelection

1

Why Metal Oxide Film Resistors May Be Your Circuit’s Best Friend
When it comes to choosing the right resistor, "standard" isn't always enough.
While metal film resistors are great for precision, Metal Oxide Film Resistors are the heavy-lifters of the component world.
Based on our latest guide, here is why you should consider them for your next industrial or power-related design:
* High-Temperature Stability: Unlike carbon or metal film, metal oxide resistors can operate at much higher temperatures (up to 300°C!) without drifting or failing.
* Surge & Overload Endurance: They are built to handle momentary power "spikes" and surges during startup—making them far more robust than their metal film counterparts.
* Safety First (Flameproof): Most are finished with a silicone-based, non-flammable coating. If they do fail under extreme overload, they do so safely.
* Long-term Reliability: Since the material is already an oxide, it is chemically stable and doesn't degrade or oxidize further over time.
Where should you use them?
While metal film is king for audio and precision, Metal Oxide is the go-to for:
✅ Power Supplies
✅ Industrial Applications
✅ Surge Protection
Despite the fact that metal oxide film resistors may not be nearly as common as metal film ones, they still have a great number of areas where they excel.
#electroniccomponents #CircuitDesign #HardwareDesign #Resistors #electronicsengineering #ElectronicsNotes #ComponentSelection

3
3
25
1,556

Jan 21
Würth Elektronik expands its online range with a Product Navigator tool that helps developers quickly find the right electronic and electromechanical components by application and topology.
More info at: international.electronica-az…
#WurthElektronik #ProductNavigator #ComponentSelection #ElectronicsDesign
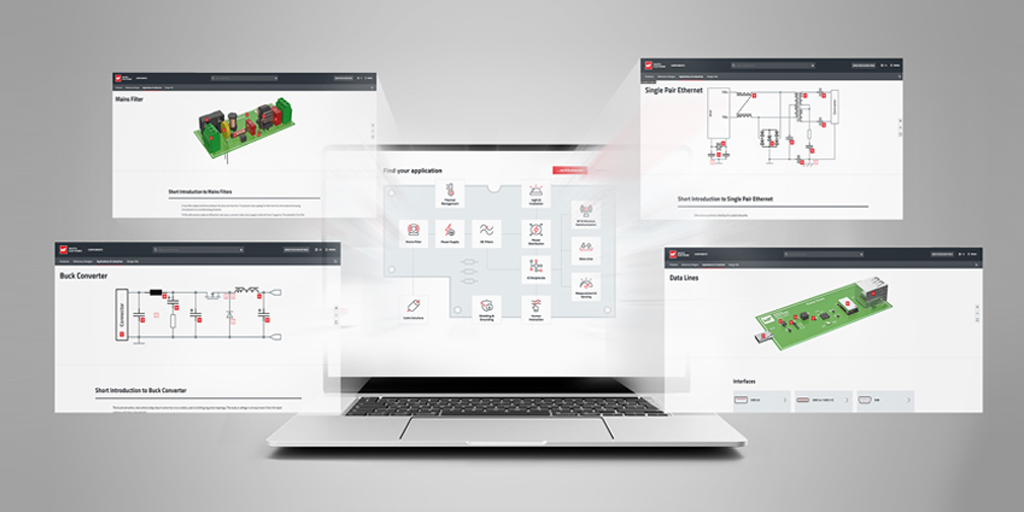
10

@we_online introduces its expanded Product Navigator, enabling faster component selection by application, topology, and tested data. #WurthElektronik #ElectronicsDesign #ComponentSelection #REDEXPERT
electronicsmedia.info/2026/0…
5

We provide reliable, AEC-Q qualified components for your automotive designs.
#AutomotiveElectronics #TVSdiode #CircuitProtection #Diode #AutomotiveLighting #Engineering #ElectricalEngineering #ComponentSelection #PCBA #Reliability #AECQ #LEDLighting #ElectronicsManufacturer

1
5

25 Sep 2025
Looking to elevate your PCB designs? Check out our latest blog on Optimizing Component Selection and Layout for PCB Design!
📍 Learn expert tips on:
🔧 Choosing the right components for functionality & reliability
📐 Perfecting PCB layouts for signal integrity & thermal management
🔥 Advanced reflow temperature monitoring for flawless soldering
Whether you're prototyping or mass-producing, Makerfabs ensures your design stands out in performance and durability. 🌟
👉makerfabs.com/blog/post/opti…
#PCBDesign #ElectronicsEngineering #ComponentSelection #PCBLayOut #SMTAssembly #Makerfabs #ElectronicsManufacturing #TechDesign #Prototyping #ReflowSoldering #ManufacturingSolutions #EngineeringExcellence #IoT

1
167

19 May 2025
🔍 𝐁𝐆𝐀 𝐯𝐬. 𝐋𝐆𝐀
Choosing between Ball Grid Array (BGA) and Land Grid Array (LGA) affects your board’s density, serviceability, and thermal performance.
📚 Learn more details:👉 pcbmay.com/bga-vs-lga/
#PCBMay #PCBDesign #BGA #LGA #PCBAssembly #PCBA #ComponentSelection




27

12 May 2025
If I were building an on-prem supercomputer-style setup for training and running the latest LLMs in a bunker-style, no-external-dependency, sovereign mode (think: digital citadel prepper mode), here’s the stack I’d commandeer—balanced for raw performance, redundancy, and futureproofing.
⸻
1. Hardware Stack – Data Center in a Box
Compute
•Chassis: 4U rackmount server chassis with redundant hot-swap fans and PSU
•Motherboard: Supermicro or ASUS ESC series with multi-socket support
•CPU: Dual AMD EPYC 9654 or Intel Xeon Max – 96–128 cores total, PCIe Gen 5 support
•RAM: 1–2TB ECC DDR5 RAM – needed for large model training stability
GPU
•Primary: 4–8x NVIDIA H100s (PCIe or SXM depending on budget and power availability)
•Alternative: AMD MI300X if you’re committed to open tooling (ROCm stack)
•Each H100 = 80GB HBM3 and ~700W, so plan for airflow and power
•NVLink Bridge: For GPU-GPU communication bandwidth if you’re going multi-GPU training
Storage
•Fast scratch space: 16TB of PCIe Gen 4/5 NVMe SSDs in RAID 0 (for model shuffling)
•Long-term storage: 100–500TB in ZFS RAID-Z2 NAS (data checkpoints backups)
•Backup: LTO tape system or off-grid cold backup
Networking
•Switch: Mellanox 100G Infiniband or Ethernet for GPU cluster networking
•NICs: Dual-port 100G NICs in each node for model parallelism or cluster distribution
•Airgap Firewall: Full isolation with a hardened, no-default-route gateway
⸻
2. Power Cooling
•Power: 30kW–60kW UPS with generator fallback
•Cooling: Liquid cooling or custom airflow chambers (air-cooled GPUs will throttle)
•Monitoring: Open-source Prometheus/Grafana dashboards for thermal and load monitoring
⸻
3. Software Stack – Isolation Mode AI Ops
OS Core
•OS: Ubuntu Server LTS or Rocky Linux (minimal install)
•Kernel: Real-time tuned Linux kernel for training stability
•Containerization: Docker or Podman with NVIDIA container runtime
•Orchestration: Local Kubernetes (k3s or microk8s) or just systemd for simplicity
Model Training Stack
•Frameworks: PyTorch DeepSpeed HuggingFace Transformers
•Libraries:
•NVIDIA CUDA cuDNN or ROCm (if AMD)
•Bitsandbytes or QLoRA for quantized training
•Checkpointing: HuggingFace Hub in “offline” mode or Git-annex
•Optimization:
•FSDP (Fully Sharded Data Parallel)
•Zero Redundancy Optimizer (ZeRO)
•Mixed precision (FP16/bfloat16)
Local Models
•Preload: LLaMA 3, Mistral, Phi-3, and Mixtral variants
•Train: fine-tune your own on custom data via PEFT or QLoRA
UI API
•Ollama, Text Generation WebUI, or LM Studio for local inference
•Optional: local ChatGPT-like front-end via Open WebUI or similar
⸻
4. Bonus Isolation Features
•Faraday Cage or EMF-protected server room
•Manual patch updates: using sneakernet (USB signed by trusted source)
•Air-gapped tools: Local DNS, time server (via GPS), and Git mirrors
⸻
TL;DR Build List Summary
ComponentSelection
CPUDual AMD EPYC 9654
GPU8x NVIDIA H100 (or AMD MI300X)
RAM1-2TB ECC DDR5
Storage16TB NVMe 100TB ZFS
Power30kW UPS generator
CoolingLiquid preferred
OSUbuntu LTS / Rocky Linux
FrameworksPyTorch, DeepSpeed, Transformers
Airgap SetupFully isolated with offline mirrors
⸻
Would you like this turned into a visual rack layout or build schematic PDF?
1
1
465

8 May 2025
The selection of machinery components, from gears and bearings to motors and sensors, directly impacts the overall functionality and reliability of machines. #ComponentSelection #MachinePerformance
1
1

8 May 2025
The selection of machinery components, from gears and bearings to motors and sensors, directly impacts the overall functionality and reliability of machines. #ComponentSelection #MachinePerformance
1
3
4 May 2025
Machine failure prevention is also about selecting the right components for the application, ensuring that each part is suited for the intended load, temperature, and environmental conditions. #ComponentSelection #ApplicationFit
1
7
4 May 2025
Machine failure prevention is also about selecting the right components for the application, ensuring that each part is suited for the intended load, temperature, and environmental conditions. #ComponentSelection #ApplicationFit
1
9
3 May 2025
Investing in advanced materials and components during the design phase can help reduce future repair costs and improve the longevity of machines, resulting in lower lifecycle costs. #ComponentSelection #LongLifespan
1
3
3 May 2025
Investing in advanced materials and components during the design phase can help reduce future repair costs and improve the longevity of machines, resulting in lower lifecycle costs. #ComponentSelection #LongLifespan
1
2
29 Apr 2025
🔍 𝐐𝐅𝐏 𝐯𝐬. 𝐐𝐅𝐍
Picking the right #ICpackage can impact your board’s size, thermal performance, and assembly.
📚 Read our full guide👉 pcbmay.com/qfp-vs-qfn/
#PCBMay #PCBDesign #QFP #QFN #SurfaceMount #PCBA #ComponentSelection #SMT




9

26 Apr 2025
👂What Does Your Project Need?
A. Mini servo drives
B. High-efficiency PV systems
C. 5G base station power
D. Heavy-duty power tools
#PowerElectronics #ComponentSelection
💬 Comment: What's your toughest MOSFET challenge?
See full specs at: [link]
medium.com/@VBsemiMOSFET/vbs…

1
41

15 Apr 2025
💡Automotive Supply Chain Insights: Fastener Selection Guide for Electrical Systems of EVs
linkedin.com/pulse/automotiv…
#EVFasteners #ElectricalSystems #ComponentSelection #EngineeringInsights #AutomotiveManufacturing #EVComponents #highstrengthfasteners #ZhejiangZhongruiAutoParts

9 Apr 2025

Our OEM and aftermarket parts, including custom-engineered high-strength bolts, brackets, pins, and springs, contribute to enhanced automotive efficiency and quality.
zjzrqc.com/
zrqiche@163.com
#FastenerSolutions #OEMParts #automotive #ZhejiangZhongruiAutoParts




1
42

16 Oct 2024
• Watch out for tolerance. A 100Ω resistor with a 5% tolerance can range from 95Ω to 105Ω. #ComponentSelection
1
16 Oct 2024
• Choosing the right diode: Consider voltage ratings, forward current, and response speed. #ComponentSelection
1
1

13 Aug 2024
We offer best-in-class services for #circuitboarddesign and manufacture including #hardware #study, #analysis, #design, #componentselection, #BoM #optimization, and #schematicdiagram capture.
For more information, visit- embien.com/electronic-circui…

1
2
28