
Computer Science на самом деле занимаются очень многие. Проблема в том, что все просты вещи давно сделаны, а сложные редко находят приложение. Но те же блокчейны строятся на односторонних функциях. Солверы так вообще — мат модели для сложных индустриальных задач очень востребованы. В России, кстати, сейчас большой спрос на это дело: мало того, что все затягивают пояса и оптимизируют, так ещё Cplex и Gurobi больше нельзя купить — теперь надо крутиться.
Но помимо сложных вещей выстреливают и простые: Brian Ford взял заброшенную модель для парсинга из 70-х, понял что к чему, сделал её апгрейд удобным для людей и заметил, что линейный алгоритм из 70-х который был заброшен из-за нехватки памяти сейчас прекрасно работает — и вот вам Parsing Expression Grammars. С нейронными сетями история похожая: пинали их долго, с полвека уж точно, а в начале 10-х и мощностей стало хватать и допинать получилось. Я думаю, что следующим выстрелит логическое программирование на базе Prolog :)
1
12
716

Apr 20
🧠 Types of Data Analysis & How It’s Done
1️⃣ Descriptive Analysis — “What Happened?”
Purpose: Summarize and visualize data
How it’s done:
- Summarize data
- Calculate averages and totals
- Create reports and dashboards
Tools: Excel, Tableau, Google Data Studio
2️⃣ Diagnostic Analysis — “Why Did It Happen?”
Purpose: Identify causes and patterns
How it’s done:
- Identify trends and anomalies
- Drill down to root causes
- Perform correlation analysis
Tools: SQL, Power BI, Splunk
3️⃣ Predictive Analysis — “What Could Happen?”
Purpose: Forecast future outcomes
How it’s done:
- Build forecasting models
- Use machine learning algorithms
- Predict future trends
Tools: Python, R, SAS
4️⃣ Prescriptive Analysis — “What Should We Do?”
Purpose: Recommend actions and optimize decisions
How it’s done:
- Recommend best actions
- Optimize processes
- Run simulations and scenario testing
Tools: Gurobi, IBM CPLEX, Alteryx

1
2
48






Apr 7
🚨 BREAKING: Purdue built an AI system that automatically fact-checks scientific papers, and used it to dismantle a quantum computing breakthrough claim.
Analysts with zero quantum expertise fed the paper in.
The AI found undisclosed conflicts of interest, cherry-picked data, and a fraudulent baseline comparison.
The "breakthrough" was a product launch dressed as science.
A quantum startup called Kipu Quantum published a paper claiming their algorithm achieves "runtime quantum advantage" over classical computers on IBM's 156-qubit quantum processor.
The abstract claimed speedups of "several orders of magnitude."
Purdue's AutoVerifier read the paper, pulled 10 more papers, traced financial records, and built a knowledge graph connecting every claim to every piece of evidence.
Here is what it found.
The data didn't support the abstract.
The methods section used appropriate hedging "best-performing instance," "can potentially."
The abstract dropped every qualifier.
The "several orders of magnitude" projection had zero supporting analysis in the body text.
AutoVerifier flagged this as a structural pattern of strategic overclaiming: cautious methods, assertive framing.
The "80x speedup" was one cherry-picked outlier. Median speedup was 5–7x.
CPLEX the classical baseline was benchmarked on a single CPU thread.
When tested against stronger classical solvers, the quantum advantage disappeared entirely.
Zero independent papers corroborated the claim. All 4 supporting papers shared at least 4 of 6 authors with the original.
A D-Wave rebuttal replaced the quantum processor with a trivial classical algorithm.
Same solution quality. The quantum component contributed nothing detectable.
The paper never asked this question.
AutoVerifier found the rebuttal through citation-chain retrieval.
The conflicts of interest never disclosed in the paper:
→ All six authors employed by Kipu Quantum
→ CEO Enrique Solano holds an equity stake
→ BF-DCQO is Kipu's commercial product sold as "Iskay Quantum Optimizer" on IBM's marketplace
→ Product launched March 2025 the "breakthrough" paper followed two months later
→ IBM provides the hardware, owns the classical baseline, hosts the commercial product, and co-authors the benchmark no independent link in the chain
The company then quietly retracted its own claim.
> May 2025: "runtime quantum advantage."
> October 2025: "hybrid sequential quantum computing."
> March 2026: classical solvers "reach or surpass" the hybrid workflow.
The retraction came from the authors themselves.
AutoVerifier's final verdict:
→ Runtime advantage: Likely Hallucination high semantic entropy, only 1 of 3 independent models agreed
→ QPU execution: Confirmed
→ Technology maturity: TRL 4–5
→ Keystone properties for credible quantum advantage: 0 out of 5 met
The analysts had no quantum expertise.
They fed in one paper.
The system did the rest.

10
23
83
5,764

"양자가 전력 그리드까지?"
인플렉션($INFQ) 공부를 하다가 우연히 흥미로운 프로젝트를 발견했습니다.
미국 에너지부(DoE) 산하 ARPA-E가 주관하는 에너지 그리드 최적화 프로젝트에 Infleqtion이 참여하고 있습니다.
프로젝트 이름은 ENCODE — Enhancing Neutral-atom Computers for Optimizing Delivery of Energy의 약자입니다. $620만 규모이고, ARPA-E 역사상 최초의 양자컴퓨팅 전력망 프로젝트입니다.
배경을 먼저 이해하면 왜 이게 흥미로운지 알 수 있습니다.
지금 전력망 운영자들은 전기를 어디서 얼마나 생산해서 어디로 보낼지를 최적화하는 소프트웨어를 씁니다. 그런데 AI 데이터센터 전력 수요 폭증, 태양광·풍력 같은 불규칙한 재생에너지 증가로 전력망이 너무 복잡해졌습니다. 기존 소프트웨어(Gurobi, CPLEX 같은 산업 표준 툴 등)는 문제가 너무 커지면 정확한 답 대신 근사값을 씁니다. 근사값을 쓰면 발전 비용이 올라갑니다.
Infleqtion은 여기에 양자컴퓨터를 투입해서 기존 소프트웨어가 못 찾던 진짜 최적해를 찾겠다는 목표를 갖고 있습니다.
흥미로운 건 참여 기관 구성입니다. Argonne 국립연구소, 국립재생에너지연구소(NLR)와 함께, 시카고에 실제 전기를 공급하는 전력회사 ComEd(Exelon 산하)가 파트너로 들어와 있습니다. 단순 연구가 아니라 실제 전력망에 적용하는 걸 처음부터 염두에 두고 설계된 프로젝트입니다.
기술적으로도 재미있는 포인트가 있습니다. 전력망 최적화를 위한 컴퓨터가 기존 슈퍼컴퓨터보다 전기를 훨씬 덜 먹는다는 점입니다. Infleqtion의 중성자 원자 기반 양자컴퓨터는 킬로와트 수준의 전력으로 작동하는데, 슈퍼컴퓨터는 메가와트가 필요합니다. 전력망 효율화를 위한 컴퓨터가 전력 효율적이라는 아이러니하지만 중요한 특성도 재밌는 포인트입니다.
마침 오늘(4월 7일)부터 3일간 샌디에이고에서 ARPA-E 에너지 이노베이션 서밋이 열립니다. Infleqtion이 이 자리에서 ENCODE 프로젝트 진행 상황을 발표할 예정입니다. 내일(4월 8일)에는 2025년 연간 실적과 2026년 매출 가이던스 발표도 예정되어 있어, 이틀 연속으로 주목할 만한 이벤트가 이어집니다.
인플렉션 종목 추천이 아니며 정보 전달 목적으로 작성하였습니다. 개인적으로는 아직 인플렉션에 대해 스터디 단계입니다.
1
11
1,237


#Generative #AI and #optimization in 2026 : #Bob @IBM , #CPLEX and the comeback of #ORMS
linkedin.com/pulse/generativ…
@KirkDBorne @vardi @syvaniem @joerg_wende @hh_wandsbek @INFORMS @Inria @marchand_de_cig #watsonx
2
93

Mar 13
記事を投稿しました! IBM Bob + CPLEX で タオル製造の最適化-予算内で収益率を最大化しつつ廃棄を最小化- on #Qiita qiita.com/Asuka_Saito/items/…
2
73

/
📣データ活用、進んでいますか?🧐
データ分析・活用のセミナーを開催!
\
ㅤ
データは極めて大きな価値がある一方で、分析して活用するにはハードルが高くなりがちですよね…😢
ㅤ
「データ分析や最適化に取り組みたいが、専門的なプログラミングスキルがない」
「複雑な業務ルールや条件を、システムにどう設定すればいいかわからない」
ㅤ
この度、上記のようなお悩みをお持ちの方に向けて、課題を解決するためのオンラインセミナーを開催します🔥
ㅤ
<セミナー概要>
タイトル:
データ活用を、一部の専門家から現場の手に。IBM Bobで加速するDX内製化の最適解
~SPSSとCPLEXを全社で使い倒し、意思決定のスピードを最大化する~
ㅤ
日時:2026年4月16日(木) 12:00~13:00
場所:オンライン開催
参加費:無料
お申込みURL:nic-channel.v2.nex-pro.com/c…
ㅤ
本セミナーでは、IBMのビジネス向け生成AI開発支援ツール「IBM Bob」を活用し、
SPSS Modelerによるデータ分析や、CPLEXによる数理最適化のハードルを劇的に下げる手法をご紹介します👏
ㅤ
<このような方におすすめです>
・データ分析や最適化計算の内製化・効率化を目指す方
・Pythonなどのコーディングスキルに不安があるが、高度な分析を行いたい方
・現場の業務課題を素早くシステム化・アプリ化したいDX推進担当者
ㅤ
高度なITスキルに依存せず、ビジネス現場主導でデータ活用を推進したいDX担当者様必見の内容になっています👀
データ活用をより身近で、簡単なものに。
皆様のご参加を心よりお待ちしています🫶
ㅤ
#セミナー #データ分析 #データ活用
#プログラミング #数理最適化 #システム
#業務効率化 #DX #IT技術
#NTTインテグレーション #NIC #NTTグループ
#プレスリリース #IT企業
3
242

Feb 21
過去の最適化結果から得られた知見を基に、初期解の提示や制約の絞り込みを行うことで、GurobiやCPLEXといった既存ソルバーの処理を効率化
youtu.be/oaq82bjoVJM

6
830


Feb 9
نرم افزار
IBM ILOG CPLEX Optimization Studio v22.1.2
رسید
ibm.com/products/ilog-cplex-…
1
4
539
#Very #simple #CPLEX #CPOptimizer incremental solves in #OPL github.com/AlexFleischerPari… and #python #docplex github.com/AlexFleischerPari… #ORMS #watsonx #AI @IBM @IBMwatsonx @INFORMS @vardi @KirkDBorne
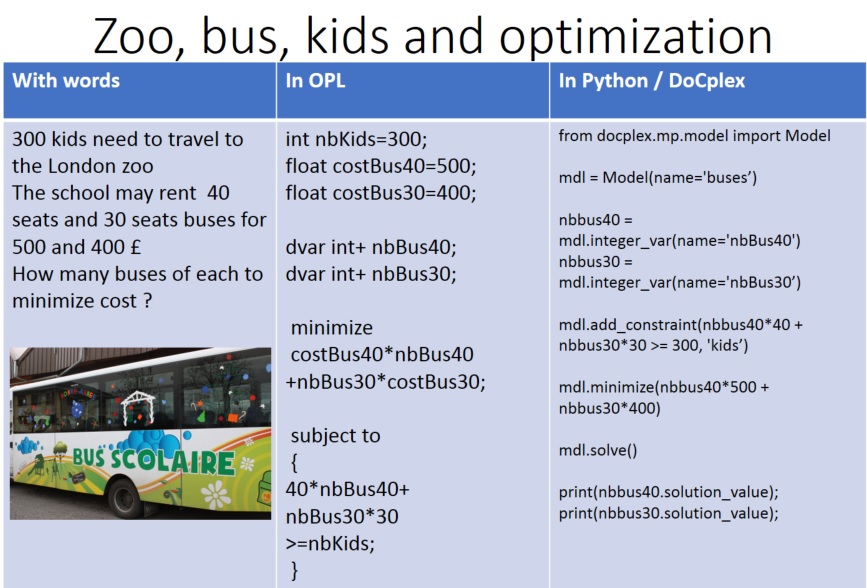
2
55

Jan 24
Solvers (CPLEX, Gurobi) are still underrated tech although it already runs so much of the worlds scheduling/planning
3
110

Jan 23
This reminds me of similar thought we had when we saw that people using CPLEX were making a shitload of money. In one case, the cost of the project (hundred of k euros) was repaid every single minute!
We almost never found a way to get revenue sharing in place, be at ILOG, or at IBM. One issue is how to measure that revenue. A second issue is that if we pushed for it, then people would move to inferior but capable enough alternatives. The cost of using our premium quality would be too high.
This is to say that I highly doubt this OpenAI initiative will fly any time soon.

1
1
16
2,480
Jan 22
SWE is more than prototyping. I hope yo know that.
I worked on production code in the past (cplex), and I know it is way more demanding than what I do now.
1
4
151
Jan 5
emacs or jupyter lab, depending on the project.
I am biased because my projects are small, usually code for a kaggle competition.
If I had to work on a significiant code base, like CPLEX, I'd probably use vs code now.
1
3
209

21 Dec 2025
@T_Gamard c quoi ce bordel ? Cplex il a mal fait l’optimisation demande un remboursement.
19 Dec 2025

À peine 20% des TGV complets pour le premier week-end: il reste encore beaucoup de places dans les trains pour les vacances de Noël (mais pas tous)
l.bfmtv.com/mK88

1
3
728



11 Dec 2025
量子コンピュータが創薬の実務に本格的に足を踏み入れた瞬間がやってきました。
公開された論文「Practical protein-pocket hydration-site prediction for drug discovery on a quantum computer」は、
現行のノイジー中規模量子(NISQ)ハードウェアだけで、FDA承認済みの医薬品が実際に結合しているタンパク質の結合ポケット内において、実験で観測された水和部位(晶水)の位置を85~92 %という極めて高い精度で予測することに世界で初めて成功したことを報告しています。
この研究では、古典的な最先端溶媒理論である3D-RISMを用いてタンパク質周囲の連続的な水密度分布を計算した後、その密度ピークを0.5 Å間隔の3次元グリッド上に離散化し、「各グリッドに水分子を配置するか否か」を0/1のバイナリ変数として表現しました。さらに、水分子同士の立体障害や相互作用をペアワイズの罰則項として取り込み、全体を二次無制約二進最適化問題(QUBO)に変換するという、極めて洗練された定式化を行っています。
こうして作られたQUBOは、Q-CTRLが開発したエラー抑制技術Fire Opalを搭載した変分量子ソルバーによってIBMのHeronプロセッサ(最大156量子ビット)上で実際に実行され、最大123量子ビット規模の実機実験において、古典的なWaterMap、分子動力学シミュレーション、Hydraprot、Watgenといった既存の最良手法と同等かそれを超える精度で水和部位を再現しました。
特に注目すべきは、古典的な正確ソルバー(CPLEX)やシミュレーテッドアニーリングが解を見つけられなくなる100量子ビットを超える大規模インスタンスにおいて、量子ソルバーが明らかに優れた解(エネルギー的に低い配置)を発見した点です。
これは、生物学的に意味のあるタスクにおける量子優位性(quantum advantage)の、極めて初期ながら確かな証拠と言えます。
この手法は、単なる概念実証にとどまらず、以下の創薬ワークフローに今すぐ組み込むことが可能です。
- 仮想スクリーニング前の水和マップ自動生成
- ドッキング計算の初期水分子配置テンプレート
- 相対結合自由エネルギー計算(FEP)の水和項補正
- 水を介したリガンド設計(water-bridging scaffold)の迅速探索
論文ではさらに、量子ビット数が300~500に達する2026~2027年頃には古典手法を完全に凌駕し、1000量子ビット級の初期誤り訂正マシンが出現する2028~2029年頃には「実用的な量子優位性(practical quantum advantage)」が達成されると明確なスケーラビリティ分析を示しています。
量子コンピュータが「遠い将来の夢」ではなく、「今日から使える創薬ツール」になったことを、誰でも再現可能な実機実験で証明した、まさに歴史的な一報です。
10 Dec 2025

#compchem #quantumcomputing I’m thrilled to share this new preprint: "Practical protein-pocket hydration-site prediction for drug discovery on a quantum computer".
👉Check it out: arxiv.org/abs/2512.08390
Demonstrating the practical utility of Noisy Intermediate-Scale Quantum (NISQ) hardware for recurrent tasks in Computer-Aided Drug Discovery is of paramount importance. We tackle this challenge by performing three-dimensional protein pockets hydration-site prediction on a quantum computer. Formulating the water placement problem as a Quadratic Unconstrained Binary Optimization (QUBO), we use a hybrid approach coupling a classical three-dimensional reference-interaction site model (3D-RISM) to an efficient quantum optimization solver, to run various hardware experiments up to 123 qubits. Matching the precision of classical approaches, our results reproduced experimental predictions on real-life protein-ligand complexes. Furthermore, through a detailed resource estimation analysis, we show that accuracy can be systematically improved with increasing number of qubits, indicating that full quantum utility is in reach. Finally, we provide evidence that advantageous situations could be found for systems where classical optimization struggles to provide optimal solutions. The method has potential for assisting simulations of protein-ligand complexes for drug lead optimization and setup of docking calculations.
Great collaboration with @loco_daniele (@qubit_pharma ), Kisa Barkemeyer and Andre R. R. Carvalho (@qctrlHQ). We thank the IBM quantum network @IBMResearch for providing time on the Heron quantum processing units.

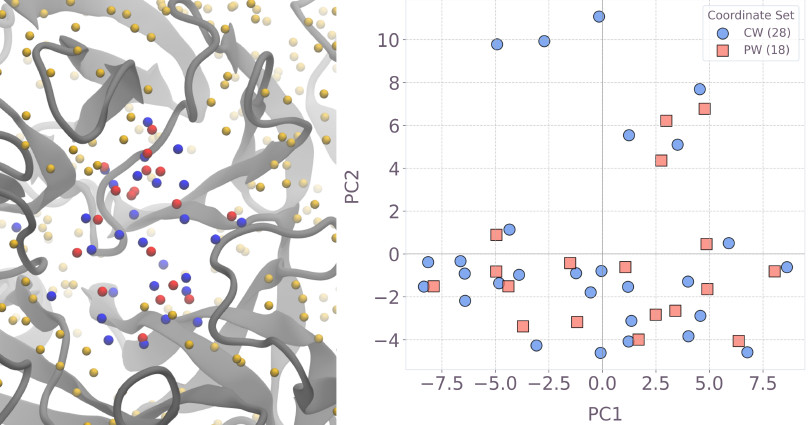
2
108