DevOps Tool of the Week: AirLLM 🛠️
You don't need a powerful GPU to run large models locally.
AirLLM is an open-source tool that lets you run large models on a single GPU without needing the whole model in VRAM at once.
It splits the model into layers and loads one layer at a time during inference.
Here is what it does 👇
- Initially, AirLLM pulls the full model, splits it into per-layer shards, and saves on local disk.
- When you send a query, it loads the model into VRAM one layer at a time.
- It loads Layer 1 from disk into GPU VRAM, processes it, then clears VRAM and calls the next layer.
- It repeats this for every layer, and once all layers are processed, it returns the response to your query.
With this, even a 4GB GPU can run a 70B model.
𝗦𝘁𝗮𝗿𝘁 𝗛𝗲𝗿𝗲: github.com/lyogavin/airllm
#LLM #MLOps #devopstools

1
10
55
2,108

Jun 7
Dockhand Docker v1.0.32 enhances self-hosted container operations with refined views, better log handling, and improved Git stack deployments.
#dockermanagement #containeroperations #devopstools #selfhosted
2

Jun 7
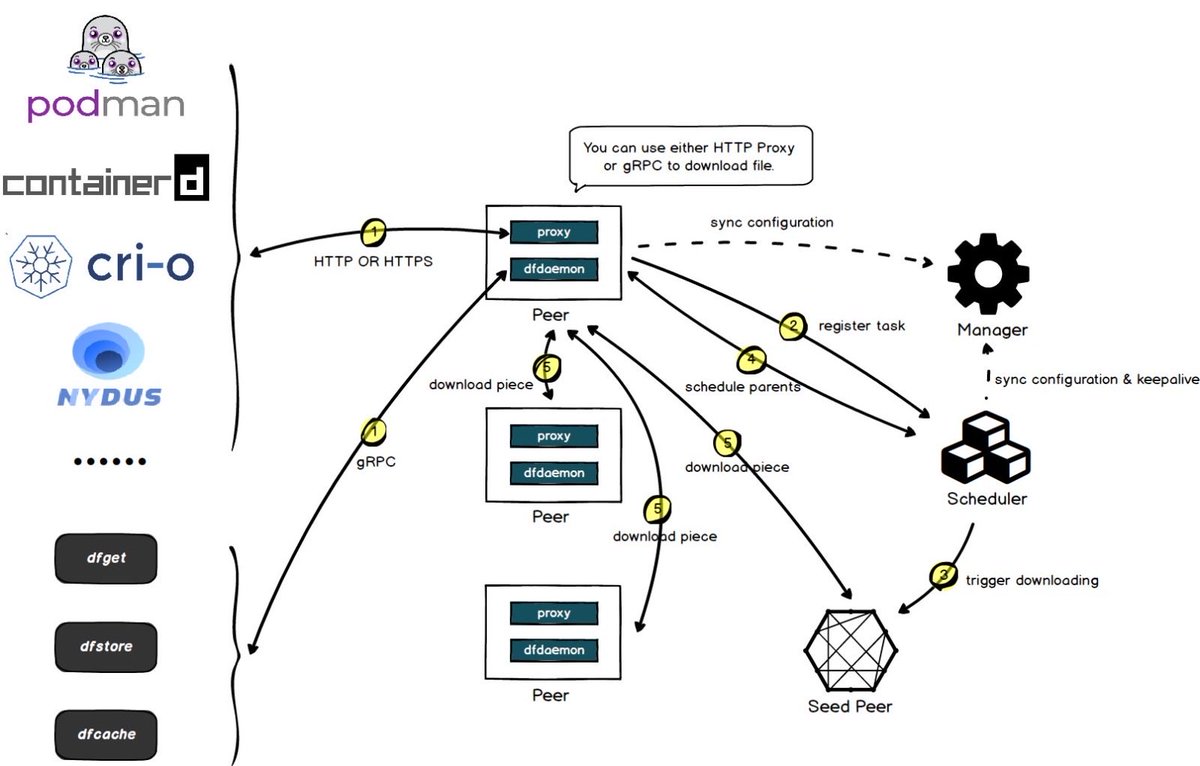
DevOps Tool of the Week: Dragonfly 🛠️
Pulling a 130 GB model to 200 GPU nodes generates 26 TB of traffic.
But what if nodes pulled from each other instead of the source?
That is where Dragonfly helps. It is an open-source peer-to-peer file distribution system.
The initial downloading node becomes a local cache. The model hub is hit once, and the rest of the cluster pulls from each other.
Here is what it does 👇
- Supports direct model downloads from Hugging Face and ModelScope.
- Split files and start sharing peer-to-peer before the first download finishes.
- Reduce origin bandwidth from 26 TB to ~130 GB across 200 nodes.
- Supports private repos with token authentication.
- Deploys on Kubernetes as a DaemonSet.
👉𝗚𝗶𝘁𝗵𝘂𝗯 𝗥𝗲𝗽𝗼: github.com/dragonflyoss/drag…
#devopstools #devops
4
24
1,035

May 31
Types of IAC
- Configuration management (Ansible, Puppet, Slatstack)
- Server Templating (Docker, Packet, Vagrant)
- Provisioning tool (Terraform, Clout formation)
Any other tools you know?
By Kodekloud
#devopstools
#iac #infrastructure
#engineer #docker #kubernetes #kodekloud

2
47
Apr 26
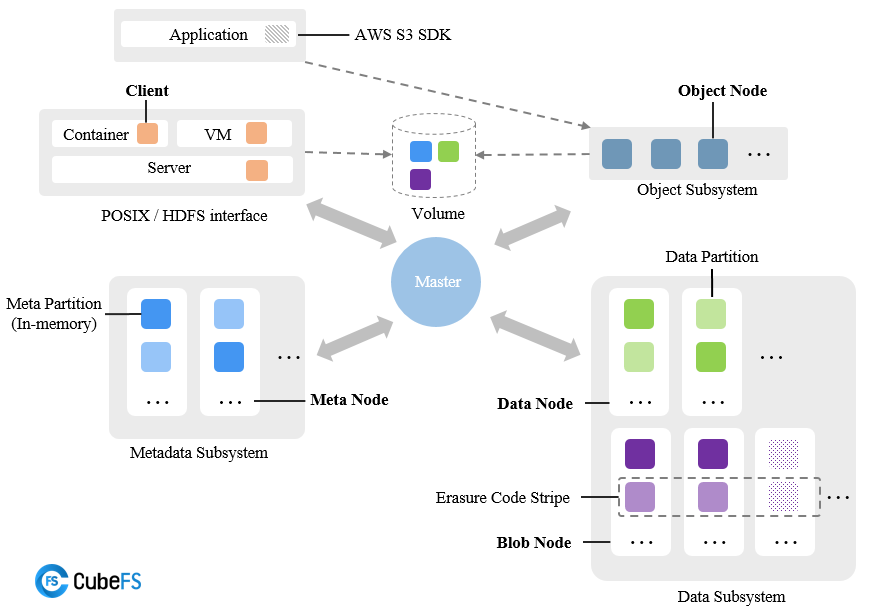
Handling millions of files is where most distributed storage systems start slowing down.
As file count grows, finding them quickly becomes the real problem.
Most systems keep a single index of where all files are stored.
When thousands of requests hit that index at once, everything slows down.
CubeFS handles this differently.
It splits the file index across multiple servers.
So instead of one server handling all requests, the work is spread out.
That's why it stays fast even when many applications read millions of files at the same time.
If you're working with AI training data or processing large datasets, this design matters.
Github : github.com/cubefs/cubefs
#devopstools #devops
12
53
2,017

🚨 On-call shouldn’t feel like chaos. So why does it?
Read More 👉 resources.callgoose.com/blog…
#OnCallManagement #IncidentManagement #DevOps #SRE #ITOperations #Automation #ITAutomation #Alerting #IncidentResponse #DevOpsTools #CloudOps #SiteReliability #Monitoring #CallgooseSQIBS

3
5
50

Apr 19
Today's lessons were on:
✅ Why NFTs use IPFS (Interplanetary File System) for storing metadata and assets off-chain due to high costs of storing on-chain.
❌ Couldn't get IPFS app compatible with my MacOS.🥲
✅ Built a Foundry Script to track NFT deployment via DevOpsTools.👨🏾💻
1
7
147
Apr 5
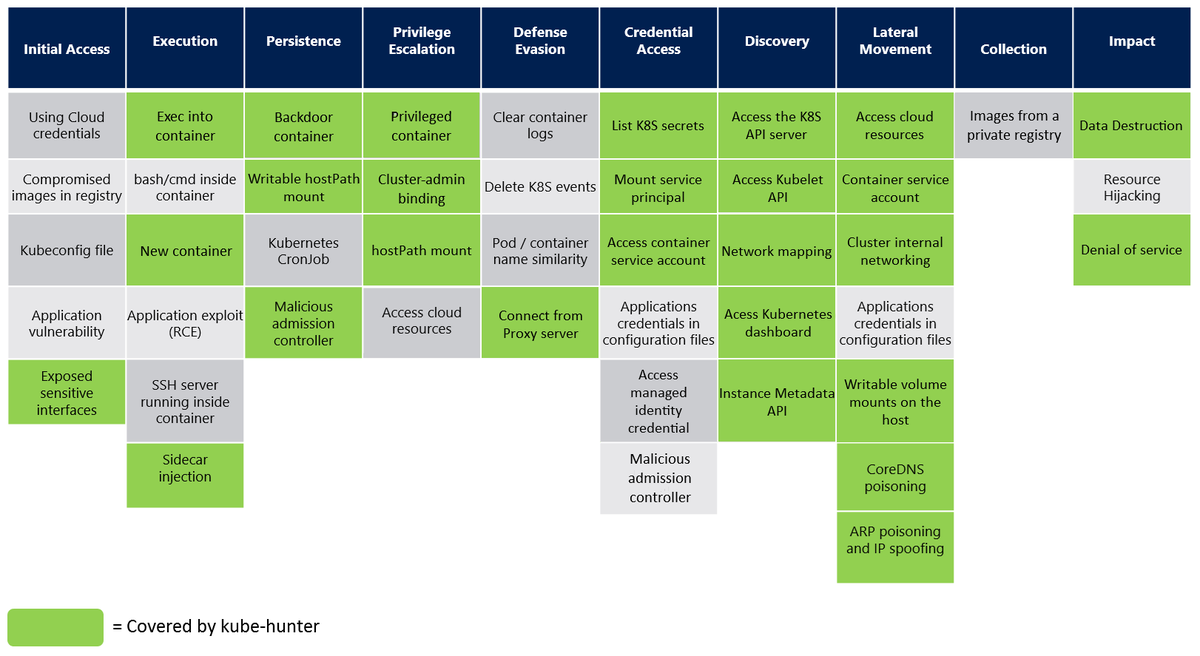
Kube-bench checks compliance.
Kube hunter checks if you are actually secure.
Kubernetes clusters can accidentally expose things like the API server, etcd, or weak RBAC permissions without teams realizing it.
Kube-hunter helps find these issues by acting like a real attacker and probing your cluster for weaknesses.
Instead of just reviewing configs, it actively tests what an attacker could actually access or exploit.
It can run:
- Externally (like an outsider),
- Inside the cluster (as a pod), or
- Scan the network to discover exposed services.
This makes it useful for catching real risks like open dashboards, public API endpoints, or insecure etcd access.
Tools like kube-bench and Trivy mostly check configurations and known vulnerabilities.
Kube-hunter is different because it simulates real attack paths, not just compliance checks.
That’s why teams often use it in pre-production to catch practical security gaps before going live.
𝗚𝗶𝘁𝗵𝘂𝗯: github.com/aquasecurity/kube…
#devops #devopstools
13
38
1,527

Apr 5
✨ Game-changer:
Scrum vs Kanban
Everything you need to know 👇
🔗 kubaik.github.io/scrum-vs-ka…
#Cybersecurity #GreenTech #AgileMethodologies #MachineLearning #DevOpsTools
2
10
Apr 1
📊 Blue/Green Deploy in 2026: What changed?
New comprehensive guide covering:
✨ Core concepts
🔧 Practical examples
⚡ Performance tips
🎯 Best practices
Dive in 👇
🔗 kubaik.github.io/bluegreen-d…
#AI #DevOpsTools #DigitalNomad #DeployWithEase #software
3
11
Mar 29
Adding AI agents in Kubernetes is complicated.
But have a solution now. For example,
Your team uses Claude and GitHub Copilot, and these tools need access to Jira, GitHub, and your Kubernetes cluster to do real work.
So every action from AI goes through MCP servers.
Now the problem starts when there is no control.
- Anyone can access anything
- Credentials may get exposed, and
- You won’t know what the AI actually did.
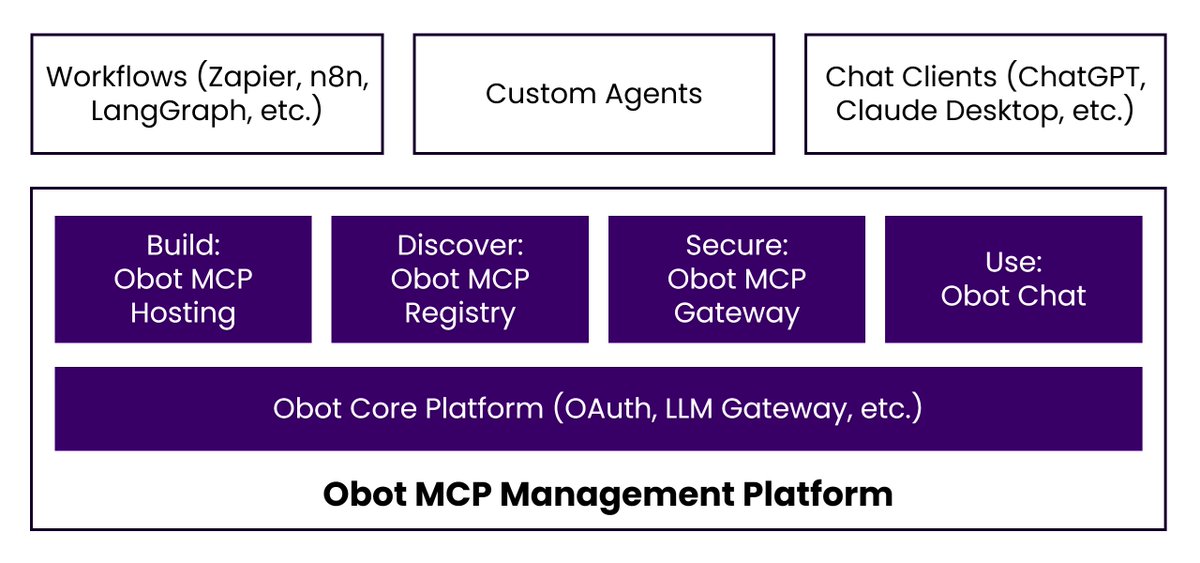
Obot is a the actual solution for this
Obot sits in between and acts like a control layer inside your Kubernetes cluster.
Every AI request passes through it, and policies decide who can access what.
It also logs every action, so you have full visibility of what happened.
In simple terms, Obot works like a security guard for your AI tools.
GitHub: github.com/obot-platform/obo…
#devops #devopstools
1
9
536

Mar 24
📖 New Post on RackNerd: ✅ Exploring Prometheus and Grafana: A Guide for Server Monitoring 💻🌐 Learn more: blog.racknerd.com/exploring-…
🛒 ORDER VPS HOSTING: racknerd.com/kvm-vps
#RackNerd #Prometheus #Grafana #ServerMonitoring #DevOpsTools #VPSHosting #InfrastructureMonitor

2
182
Mar 22
Developers often deploy apps like NGINX on Kubernetes
But they must write many YAML files such as,
Deployments, Services, Ingress, and ConfigMaps.
Managing all of this can be complex.
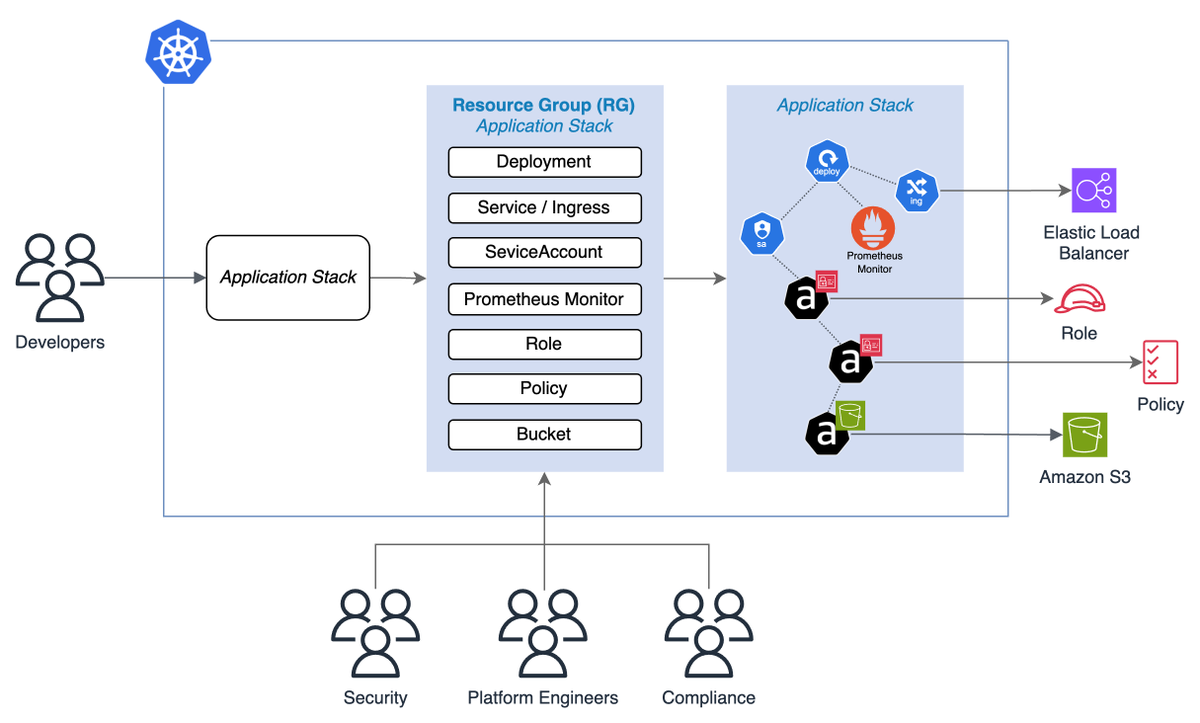
KRO (Kubernetes Resource Orchestrator) solves this by using reusable templates called ResourceGroups.
Developers only provide simple inputs like app name, replicas, or image tag, and KRO automatically creates all the required Kubernetes resources.
Here's how it works:
- You create a ResourceGroup definition that bundles multiple Kubernetes resources together.
- KRO's controller watches for these instances and automatically provisions all underlying resources in the correct order.
- It handles dependencies between resources, ensuring everything is created in the right sequence.
Unlike Helm or Kustomize, KRO works directly at the Kubernetes API level, making it easier to manage resources and integrate with GitOps workflows.
𝗚𝗶𝘁𝗵𝘂𝗯 𝗥𝗲𝗽𝗼: github.com/kubernetes-sigs/k…
#devopstools #devops
2
23
106
5,038
Mar 11
🚀 Level up your Test Smarter game
New comprehensive guide covering:
✨ Core concepts
🔧 Practical examples
⚡ Performance tips
🎯 Best practices
Dive in 👇
🔗 kubaik.github.io/test-smarte…
#TestAutomation #TypeScript #Microservices #Backend #DevOpsTools
12
1
94
Feb 22
Running Kubernetes and VMs in separate environments?
That is twice the complexity you do not need.
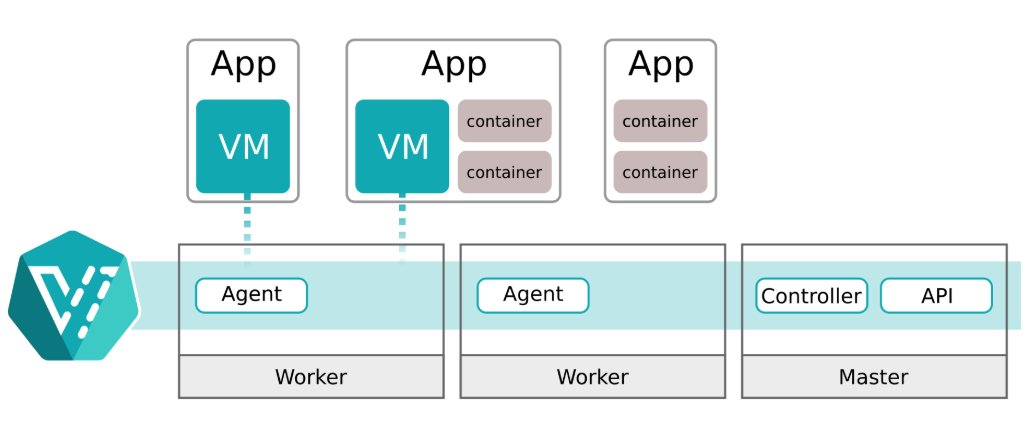
KubeVirt solves this by letting you run virtual machines directly inside Kubernetes as if they were just another workload.
Most organizations cannot migrate everything to containers overnight.
Some applications are too complex or not suited to run as containers.
But maintaining dual infrastructure is expensive and difficult.
KubeVirt lets Kubernetes manage virtual machines as native resources using CRDs, and it runs each VM inside a pod powered by QEMU/KVM.
You get all the Kubernetes benefits, such as scheduling, scaling, networking, and storage integration.
KubeVirt is quickly gaining real-world traction, with organizations like CERN and Killercoda already using it in production.
𝗚𝗶𝘁𝗵𝘂𝗯 𝗟𝗶𝗻𝗸: github.com/kubevirt/kubevirt
#devops #devopstools
1
9
61
1,838

Feb 5
The #ProgressChef platform has changed a lot over the years and this blog does a good job of explaining how the Chef solution is designed to be approachable while still meeting enterprise automation needs.
👉 prgress.co/3NRPhtf
#DevOpsTools #InfrastructureAutomation

ALT Progress Chef Has Evolved! It's more approachable with YAML/JSON support and more! READ BLOG
2
224
Jan 31
Ever faced this during a Kubernetes incident?
Which Service is routing traffic to this crashing Pod, and
What will break if we touch it?
Now assume this happens across multiple clusters.
That is a real Kubernetes problem.
During incidents, Kubernetes gives you data, not context.
What you do is switch between contexts, check dashboards, and YAMLs, manually tracing
Ingress → Service → Deployment → Pod, under pressure.
The problem is not missing data.
The problem is missing relationship visibility.
This is where Karpor helps you.
It builds a resource graph across clusters and shows dependencies, blast radius, and misconfigurations in a single view.
It indexes cluster resources, maps their relationships (labels, selectors, ownerRefs), and exposes them as a searchable graph, not raw YAML.
That is why it is powerful during outages and postmortems.
𝗧𝗼𝗼𝗹: karpor.kusionstack.io/
Quick question 👇
What slows you down more during incidents?
#devopstools #devops
4
4
39
2,266

DevOps Quiz Time: Can you spot the right tools? 🤔
Modern DevOps relies on powerful tools for automation, monitoring, and continuous delivery.
This quiz puts your DevOps fundamentals and tool knowledge to the test—perfect for engineers, tech leaders, and digital innovators ⚙️📈🔥
Think you know the answer? Reply with your choice and join the conversation.
At BSIT Software Services, we enable high-performance DevOps ecosystems that accelerate growth and innovation.
#BSIT #BSITSoftware #BSITSoftwareServices #DevOpsTools #CloudOps #SoftwareEngineering

4
11
16 Dec 2025
Large Language Models (LLMs) are very popular now.
And many people are building AI apps using them, but
How do you make sure your users always get good, and reliable answers from these models?
For example,
You built an application using gpt-4o mini and released it to users.
After a few days, you notice:
- The responses are getting slower
- The cost is going up
- The answers are becoming less accurate
In situations like this,
you can use a tool called 𝗛𝗲𝗹𝗶𝗰𝗼𝗻𝗲 to monitor and understand how your LLM is behaving so you can quickly find what’s going wrong.
Helicone gives you a single visual dashboard where you can see:
- Number of requests
- Cost
- Errors
- Latency (how long responses take), etc.
So how does Helicone do this?
When you integrate Helicone, you change the base URL of your LLM to Helicone’s gateway URL.
In simple terms, Helicone sits in the middle as a proxy between your application and the LLM.
All the requests from your app pass through the Helicone gateway first.
This allows Helicone to track both the requests and the responses from the LLM.
𝗧𝗼𝗼𝗹: helicone.ai/
#devopstools #devops

4
19
1,487
13 Dec 2025
Many teams struggle when they have to manage many Kubernetes clusters.
Here is the painful part
You may want to run one app (or many apps) across different clusters. This could be for lower latency, edge use cases, or multi-cloud safety.
You may also have separate clusters for dev, stage, and prod.
If you want to deploy something like a Prometheus stack to every cluster, you often need to switch kubeconfig contexts and deploy it one cluster at a time.
This is slow, boring, and easy to mess up.
The CNCF sandbox project Clusternet solves this.
It helps in treating many clusters like “one” environment (or at least manage them centrally).
It cuts down duplicate work, keeps configs the same everywhere, and makes rollouts easier.
Clusternet can work with:
- normal Kubernetes clusters
- managed clusters
- on-prem clusters behind firewall
- edge clusters
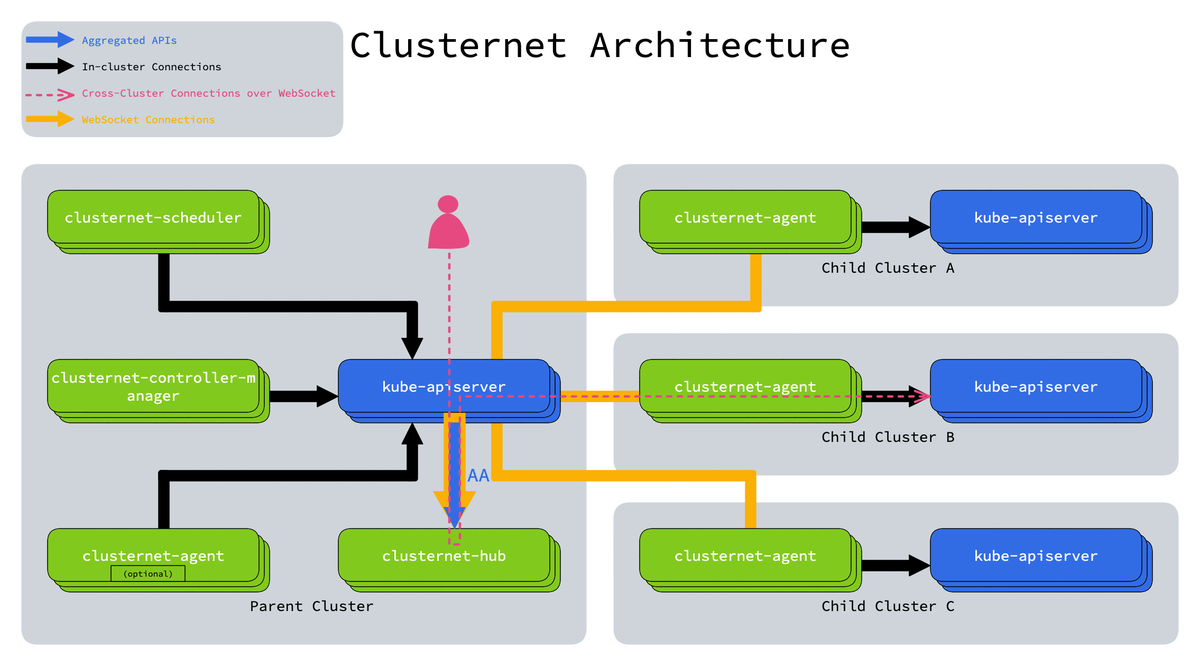
Here is how it works at the backend.
- Each child cluster connects to a central “hub” by running an agent. The agent sends health, version, and status info.
- A websocket connection over TCP links the child agents to the hub. This gives two-way communication so the hub can push updates or read status.
- The hub exposes “shadow APIs.” When you create resources there, they act like templates. They are not applied to the hub itself but to the child clusters.
- Network tunnels can be set up so the hub can reach clusters behind firewalls or inside private networks as if they were local.
𝗖𝗹𝘂𝘀𝘁𝗲𝗿𝗻𝗲𝘁 𝗚𝗶𝘁𝗛𝘂𝗯 𝗥𝗲𝗽𝗼: github.com/clusternet/cluste…
#devopstools #devops
14
81
3,193