
Jun 10
Starting a new project in PyTorch: a Plant Disease Classification model using transfer learning with EfficientNet-B0 and Grad-CAM for visual explanations.
I know I'll struggle a lot while implementing it, but that's what progress is all about. Let's see how this goes.
2
13


Jun 10
کرنل convnextv2 7x7 بود ui رو بهتر تشخیص میداد.
efficientNet 3x3
سریعتر بود و به سخت افزار پایینتری نیاز داشت
در اخر هردو تقریبا یک نتیجه رو دادند با اون تعداد.
1
3
140
Jun 10
برای موبایل معمولا روی چیزهایی مثل
ConvNeXt یا EfficientNet
ترین میکنن، من همه رو هی اماحان کردم، نتیجه مناسب نداد با اون تعداد.
بدک نبود اما بدرد نرم افزار جدی نمیخورد.
1
6
209

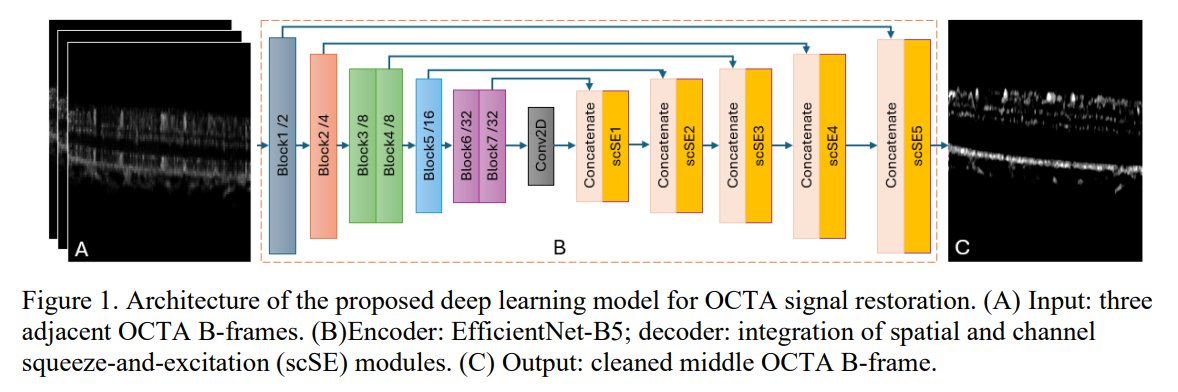
3/25 𝗧𝗵𝗿𝗲𝗲-𝗗𝗶𝗺𝗲𝗻𝘀𝗶𝗼𝗻𝗮𝗹 𝗥𝗲𝘁𝗶𝗻𝗮𝗹 𝗠𝗶𝗰𝗿𝗼𝘃𝗮𝘀𝗰𝘂𝗹𝗮𝘁𝘂𝗿𝗲 𝗥𝗲𝘀𝘁𝗼𝗿𝗮𝘁𝗶𝗼𝗻 𝗶𝗻 𝗢𝗖𝗧 𝗔𝗻𝗴𝗶𝗼𝗴𝗿𝗮𝗽𝗵𝘆
This paper proposes a deep learning algorithm, utilizing an EfficientNet-B5 encoder and a decoder with squeeze-and-excitation modules, to restore capillary anatomical vasculature from single OCTA volumes, addressing imaging artifacts and neglecting 3D architecture. The model significantly (p < 0.001) improved image quality (PSNR 26.16±1.26 vs. 22.23±0.78; SSIM 0.91±0.02 vs. 0.72±0.03) and microvascular fidelity by at least 3.8% (2D) and 51.2% (3D) compared to original scans.
#OCTA #DeepLearning #ImageRestoration #RetinalImaging #MedicalImaging
Paper Link: arxiv.org/abs/2606.05375

1
100

Jun 8
🚀🔥 AI Learning Series - Day 10 🔥🚀
Convolutional Neural Networks (CNNs) & Computer Vision
Yesterday we learned Neural Networks.
Today we discover how AI actually “sees” images like humans do.
Normal Neural Nets fail on images (too many pixels, lose spatial info).
CNNs solve this — the backbone of face recognition, self-driving cars, medical imaging & more.
How CNN Works (Core Concepts)
Convolution Layer → Small filters (3×3) slide over image & detect edges, textures, shapes.
ReLU → Adds non-linearity.
Pooling Layer → Shrinks image, keeps important features, reduces computation.
Fully Connected Layer → Final classification.
Flow: Image → Conv → ReLU → Pool → Conv → ReLU → Pool → Flatten → Output (Cat / Dog)
Popular CNN Architectures
Model
Year
Key Feature
Famous For
LeNet-5
1998
First CNN
Digit recognition
AlexNet
2012
ReLU Dropout
ImageNet breakthrough
ResNet
2015
Skip connections
152 layers
EfficientNet
2019
Best efficiency
Modern standard
Simple CNN Code (PyTorch - Copy-Paste Ready)
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(64*7*7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 64*7*7)
x = F.relu(self.fc1(x))
return self.fc2(x)
model = SimpleCNN()
print(model)
Today’s Challenge 🔥
Open Google Colab.
Train this CNN on MNIST (handwritten digits).
Then try CIFAR-10 (color images) and compare with plain Neural Net.
Experiment: Add more conv layers, change filters, add Dropout.
Truth Bomb:
Master CNNs and you can build image classifiers, object detectors (YOLO), face unlock systems, and medical diagnosis tools. This is where practical AI power begins. 💪
Save this thread. Practice today.
Day 11 tomorrow: RNNs, LSTMs & Sequence Data (Text & Time Series)
#AISeries #Day10 #CNN #ComputerVision #DeepLearning #LearnAI #AIForBeginners #ArtificialIntelligence #MachineLearning

88


我觉得统计学是个非常好的专业。
在AI时代,每个人都应该先急赤白脸地从手搓linear regression学起,啃SVM啃三个月,认真研究hidden markov model,认真学习lasso,再把各种clustering、decision tree、蒙特卡洛都学一遍,
然后进入原始neural network时代,先从古典神经网络、玻尔兹曼机、back propagation看起,花个一两年,从CNN、RNN、LSTM这些模型开始啃,然后学resnet和EfficientNet,啃一啃GAN,学一学早期transformer和BERT系列模型,
再花一两年时间,把reinforcement learning学明白,把convex optimization这个大方向看懂,再从caffe、tensorflow、pytorch这种早年大框架开始研究,
再花几年的功夫,认真研究研究GPT-1、GPT-2、GPT-3,跟着开源的方法训练一个,再去看看vllm这些inferecen框架,
最后你一个统计方向的傻王八蛋终于沿着stats路线彻底学成了,可以和硅谷和北京高中小孩坐一桌,开始研究AI Agent了。
64
41
328
81,609

May 26
With auto research available has anyone tried to discover maybe more versions of EfficientNet for ImageNet?
I feel we should be doing more aggressive NAS now that we have tools that can automate them and improve but all I see is LLMs being used for everything
6
759

May 22
A ResNet-50 with 94% accuracy on ImageNet?
Fooled by changing fewer than 0.3% of an image's pixels.
An EfficientNet-B5 with 83.6% top-1 accuracy?
Misclassifies a tabby cat as a fire truck — with a perturbation invisible to any human.
This is adversarial vulnerability. It's in every AI model in production.
Perturb finds it before attackers do. → perturbai.io/whitepaper
2
37

May 21
🚨 One operator. Two subnets. The work itself shows where $TAO is heading, most are sleeping.
Koyuki Nakamori @knakamor ran ML at Headspace, led AI at the Avalanche Foundation, was Head of AI at the Opentensor Foundation. She could be anywhere in AI. She is co-founding two subnets on Bittensor.
On a @VenturaLabs podcast, she made two points that every subnet founder should be paying attention to:
“You have to have something that people can get their hands on.”
And:
“The power of miners.”
One side is product.
The other side is incentive design.
She knows.
Perturb SN26 @perturbaix adversarial robustness as a network. A decentralized GAN where miners compete to find the smallest pixel change that fools a production AI model. Every attack is LLM-verified. Phase 1 is live on EfficientNet-B5. The EU AI Act now mandates robustness testing on high-risk AI (healthcare, autonomous vehicles, critical infrastructure) with fines up to 6% of global revenue. Market is $1.43B today, projected $11.6B by 2033. Zero competing subnets in this category. End-state vision: on-chain robustness certificates regulators can audit.
Vocence SN78 @vocence_bt decentralized voice AI. Miners compete against Alibaba's Qwen 3.6 27B baseline across nine dimensions: tone, accent, naturalness, emotion, content correctness. Goal is state-of-the-art voice quality this quarter. Live product at vocence.ai/studio. Bigger thesis: voice becomes the front door to AI, not text. ElevenLabs is the centralized target.
The possible connection of the two Subnets:
Perturb could generate the exact adversarial data Vocence needs to harden voice models on dialect, accent, and language edge cases that frontier models constently fumble. Vocence could become a natural downstream that feeds audio data back into Perturb's perturbation pipeline. Two subnets, one operator, two-way data flywheel thats possible. This is what subnet-to-subnet composability could look like in practice. An operational loop.
This is the part of Bittensor almost nobody is pricing in, but they will. The talent migration. The ecosystem keeps pulling builders who could be anywhere in AI and they are choosing decentralized rails.
That is the part many miss.
@knakamor @perturbaix @vocence_bt
$TAO
DYOR.
And shout out to @taodaily_io for constant content a must follow 👌
taodaily.io/koyuki-nakamoris…
Link for the amazing work done by @VenturaLabs and the podcast link: youtu.be/InVd4uvHHYg?si=NXHW…


May 13

⚠️ There is a problem hiding inside every AI model deployed in the world right now. $TAO's Perturb SN26 just went live on mainnet. Making it one of the most important subnets on the network.
Your AI model scores 94% accuracy in testing. Looks great. Ships to production. Then someone changes fewer than 0.3% of the pixels in an image a change invisible to any human eye and that same model misclassifies completely. Confidently. Catastrophically.
This is called an adversarial attack.
Medical imaging models used for cancer detection can be fooled this way. Autonomous vehicle systems can be made to ignore a stop sign. Fraud detection systems can be made to approve fraudulent transactions. Facial recognition controlling physical access to secure buildings can be bypassed.
The scariest part? Most organizations shipping AI products have never tested for this. Not because they don't care. Because the tooling to do it at scale simply didn't exist.
Until now.
Think of it like a security testing firm except instead of one team of experts working on your model for 6 weeks and charging $200,000, you have a global network of miners competing around the clock to find every possible vulnerability.
Validators present a challenge: here's an image of a tabby cat. Fool the AI model into thinking it's something else but do it with the smallest possible change to the image. A change so small no human would notice.
Miners compete to find that attack. The one who fools the model with the least visible change, and does it fastest, wins. The winning technique earns $TAO emissions.
Every single attack is verified by an LLM semantic checker so a valid attack genuinely fools the model on a meaningful label, not just a technical integer class mismatch. The verification is tight.
What makes this extraordinary is the compounding property.
Every day miners compete, the network gets better at finding attacks. The dataset of adversarial examples grows. The techniques improve. No centralized security firm has this.
They charge you $200K, write a report, and leave. Perturb gets stronger every single day permanently.
The market is real and it's accelerating fast.
The EU AI Act classifies AI systems in healthcare, autonomous vehicles, critical infrastructure, and hiring as high-risk requiring mandatory robustness testing before deployment. Non-compliance fines go up to 30 million euros or 6% of global revenue. That's not a soft guideline. That's a compliance requirement with teeth.
Enterprise procurement teams are already demanding adversarial robustness certificates before signing AI vendor contracts. A Perturb certificate can unblock deals worth orders of magnitude more than the subscription cost. This is a $1.43 billion market growing at 26.1% annually projected to hit $11.6 billion by 2033.
And there are zero competing subnets in this category on Bittensor. Zero.
The roadmap is real and well-staged. • Phase 1 launches with EfficientNet-B5 a production-grade image classifier that's hard enough to attack that basic methods fail, but accessible enough that any serious miner can participate with an RTX 3080.
• Phase 2 adds architecture diversity CNNs, Transformers, hybrid models.
• Phase 3 expands into LLM text attacks. Phase 5 targets vision models with over 1 billion parameters.
Perturb’s real prize isn’t testing.
It wants the winning attack systems to become on-chain robustness certificates cryptographically immutable, regulator-auditable, and impossible to forge. Something no vendor’s self-reported compliance document can ever match.
Take a problem the centralized world handles poorly expensive, static adversarial testing run it as an open competition, pay the best solutions, and let the network compound.
The team is building in public. Sigurd is active in Discord and they’re looking for design partners right now to help build the dashboard. If you want to shape this, the door is open.
perturbai.io
$TAO
DYOR

5
10
49
4,356

May 13
⚠️ There is a problem hiding inside every AI model deployed in the world right now. $TAO's Perturb SN26 just went live on mainnet. Making it one of the most important subnets on the network.
Your AI model scores 94% accuracy in testing. Looks great. Ships to production. Then someone changes fewer than 0.3% of the pixels in an image a change invisible to any human eye and that same model misclassifies completely. Confidently. Catastrophically.
This is called an adversarial attack.
Medical imaging models used for cancer detection can be fooled this way. Autonomous vehicle systems can be made to ignore a stop sign. Fraud detection systems can be made to approve fraudulent transactions. Facial recognition controlling physical access to secure buildings can be bypassed.
The scariest part? Most organizations shipping AI products have never tested for this. Not because they don't care. Because the tooling to do it at scale simply didn't exist.
Until now.
Think of it like a security testing firm except instead of one team of experts working on your model for 6 weeks and charging $200,000, you have a global network of miners competing around the clock to find every possible vulnerability.
Validators present a challenge: here's an image of a tabby cat. Fool the AI model into thinking it's something else but do it with the smallest possible change to the image. A change so small no human would notice.
Miners compete to find that attack. The one who fools the model with the least visible change, and does it fastest, wins. The winning technique earns $TAO emissions.
Every single attack is verified by an LLM semantic checker so a valid attack genuinely fools the model on a meaningful label, not just a technical integer class mismatch. The verification is tight.
What makes this extraordinary is the compounding property.
Every day miners compete, the network gets better at finding attacks. The dataset of adversarial examples grows. The techniques improve. No centralized security firm has this.
They charge you $200K, write a report, and leave. Perturb gets stronger every single day permanently.
The market is real and it's accelerating fast.
The EU AI Act classifies AI systems in healthcare, autonomous vehicles, critical infrastructure, and hiring as high-risk requiring mandatory robustness testing before deployment. Non-compliance fines go up to 30 million euros or 6% of global revenue. That's not a soft guideline. That's a compliance requirement with teeth.
Enterprise procurement teams are already demanding adversarial robustness certificates before signing AI vendor contracts. A Perturb certificate can unblock deals worth orders of magnitude more than the subscription cost. This is a $1.43 billion market growing at 26.1% annually projected to hit $11.6 billion by 2033.
And there are zero competing subnets in this category on Bittensor. Zero.
The roadmap is real and well-staged. • Phase 1 launches with EfficientNet-B5 a production-grade image classifier that's hard enough to attack that basic methods fail, but accessible enough that any serious miner can participate with an RTX 3080.
• Phase 2 adds architecture diversity CNNs, Transformers, hybrid models.
• Phase 3 expands into LLM text attacks. Phase 5 targets vision models with over 1 billion parameters.
Perturb’s real prize isn’t testing.
It wants the winning attack systems to become on-chain robustness certificates cryptographically immutable, regulator-auditable, and impossible to forge. Something no vendor’s self-reported compliance document can ever match.
Take a problem the centralized world handles poorly expensive, static adversarial testing run it as an open competition, pay the best solutions, and let the network compound.
The team is building in public. Sigurd is active in Discord and they’re looking for design partners right now to help build the dashboard. If you want to shape this, the door is open.
perturbai.io
$TAO
DYOR
2
11
57
5,525

EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
By Mingxing Tan & Quoc V. Le
EfficientNet:
لم تكن مجرد تحسين بسيط في نماذج الرؤية الحاسوبية، بل أعادت التفكير بالكامل في طريقة توسيع الشبكات العصبية.
قبلها، كان الباحثون يكبرون النماذج بشكل غير متوازن:
زيادة العمق، أو العرض، أو دقة الصور فقط.
لكن ذلك كان يستهلك موارد ضخمة دون أفضل كفاءة ممكنة.
الورقة قدمت مفهوم Compound Scaling، والذي يعتمد على موازنة:
• عمق النموذج
• عرض الشبكة
• دقة الصورة
بطريقة مدروسة رياضيًا.
النتيجة كانت نماذج تحقق:
دقة أعلى، كفاءة أفضل، وعدد بارامترات أقل مع استهلاك حوسبي أقل.
ولهذا أصبحت EfficientNet من أكثر الأوراق تأثيرًا في عالم الرؤية الحاسوبية، خاصة في تطبيقات التصنيف، الأجهزة الذكية، وEdge AI.
ورقة غيّرت مفهوم Scaling بالكامل في عالم CNNs.
#الرؤية_الحاسوبية #البحث_العلمي
1
2
182

May 8
@tanmingxing's EfficientNet work on balancing CNN depth, width, and resolution is excellent and applicable to LLMs ?
I'm somewhat skeptical of "orthogonalizing" though. We need a clear sense of direction (a convergence point or fixed point) before orthogonalizing anything. In neural nets, that fixed point keeps moving anyway.
Still, it's very well-crafted research and absolutely worth our attention and effort, or discussion/debate.
May 8

Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
3
393


May 7
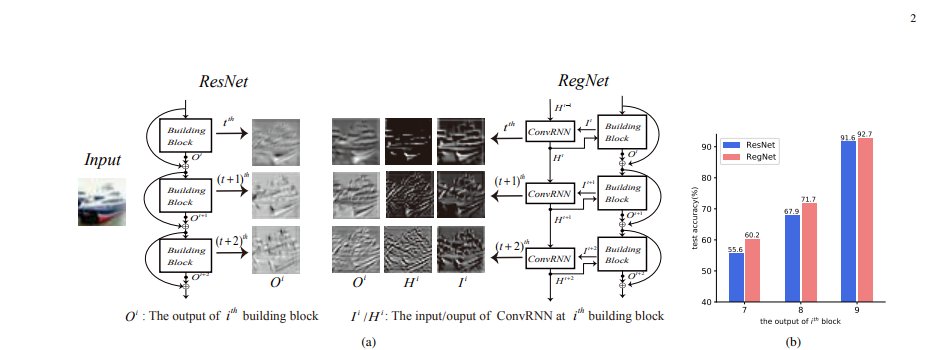
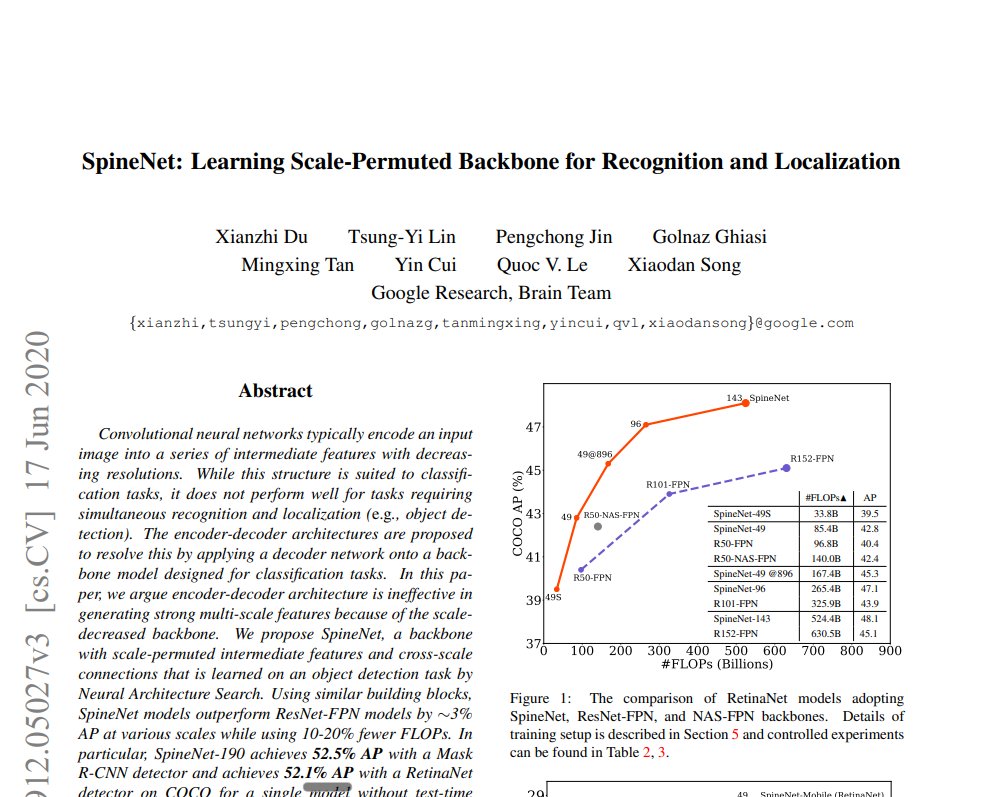
If you are into computer vision and you want to read some really good papers which have some tweaked architectures and not the normal Alexnet, Resnet, EfficientNet and stuff, I would recommend reading these 4 non-general papers:
-Res2Net
-SpineNet
-OverLoCK
-RegNet
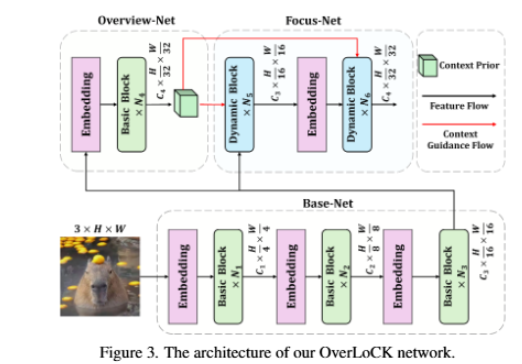
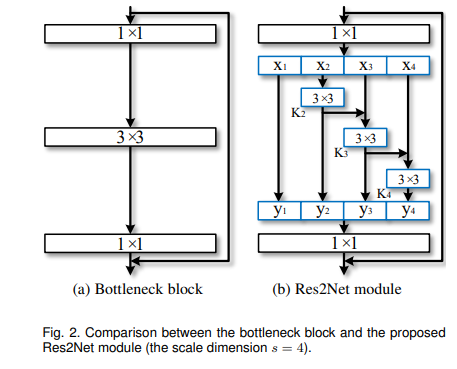
6
25
195
7,687

Apr 28
Things I have covered in the deep learning
Perceptron & Feedforward Neural Networks
Backpropagation
Activation Functions
Loss Functions
Weight Initialization
Gradient Descent Variants
Regularization (Dropout, L1, L2)
Batch Normalization
Layer Normalization
Convolutional Neural Networks (CNNs)
Residual Networks (ResNet)
DenseNet
EfficientNet
Recurrent Neural Networks (RNNs)
LSTM
GRU
Sequence-to-Sequence Models
Attention Mechanism
Self-Attention
Transformers
Positional Encoding
Encoder–Decoder Architectures
Embeddings (Word2Vec, GloVe, Contextual)
Transfer Learning
Fine-Tuning
Topics I'm planning to cover
Representation Learning
Autoencoders
Variational Autoencoders (VAE)
Generative Adversarial Networks (GANs)
Diffusion Models
Any other suggestions?
4
21
533

Apr 28
CPU, GPU, NPU and TPU - The Real Differences for AI/ML
CPU (Central Processing Unit)
The classic processor in every computer. CPUs can run any software, including AI models, but are slower for deep learning due to fewer parallel cores.
Best for:
- Traditional machine learning (scikit-learn, XGBoost)
- Running small models or prototypes
- General-purpose tasks and light inference
GPU (Graphics Processing Unit)
GPUs are built for parallel processing. They are the backbone of modern deep learning, perfect for training and inference of models like CNNs, RNNs, and transformers (GPT, BERT, ResNet).
Best for:
- Training and running large deep learning models
- Supported by all major AI libraries
- Flexible for many AI workloads
NPU (Neural Processing Unit)
NPUs are specialised chips designed only for neural network operations, often embedded in smartphones and IoT devices. They run efficient models for vision, speech, and edge AI.
Best for:
- On-device, real-time AI (face unlock, language translation)
- Battery-friendly AI in mobile and IoT
- Lightweight, efficient models
TPU (Tensor Processing Unit)
TPUs are Google’s custom AI accelerators, tuned for TensorFlow and massive neural networks. Ideal for training and deploying large models at cloud scale.
Best for:
- Scalable deep learning in Google Cloud
- Training and inference for big models (BERT, GPT-2, EfficientNet)
- High-speed tensor calculations
Which AI models run on each?
CPU: Any model, but best for classical ML, prototyping, and small-scale inference
GPU: All deep learning models (CNNs, RNNs, transformers)
NPU: Optimised mobile and edge models (MobileNet, tiny BERT)
TPU: Large-scale neural networks in TensorFlow
Note DPUs (Data Processing Units):
DPUs don’t run AI models directly, but they play a key role in modern AI infrastructure. They accelerate data movement, networking, and storage, freeing up CPUs and GPUs for computation making large-scale AI systems faster and more efficient.

2
6
140

Apr 24
Meet EfficientNet-B0, a game-changer in computer vision. This lightweight model delivers top-tier image classification while being incredibly efficient. It's a go-to choice for developers who need accuracy without massive computational costs.
1
3
670