
Joined June 2008
- Tweets 13,831
- Following 637
- Followers 2,907
- Likes 4,509
10,843 Photos and videos











Pinned Tweet

7 Aug 2025
“This Is Not How Mathematicians Are Trained”
数学家不是这样训练的
1, "Solving the forward problem (positive time) and the inverse problem (negative time) together has always been a desire of mathematicians, but they’ve never known where to begin. Neural networks, however, tackle this problem naturally" (将正时间的正问题与负时间的反问题同时求解,一直是数学家的梦想,但他们始终不知道从何入手。而神经网络却能自然地处理这个问题)
2. “Variables, coefficients, even coordinates, are changing. Everything is in flux. This is not how mathematicians are trained. It would be impossible for mathematicians to come up with such a design” (变量、系数,甚至坐标都在变化,一切都处于变动之中。数学家不是这样的训练。这样的设计,不可能出自数学家之手)
3. “Mathematicians tread carefully around composite functions with more than two layers, wary of the many pitfalls, yet neural networks solve them effortlessly, almost nonchalantly.” (数学家在处理超过两层的复合函数时格外谨慎,警惕其中诸多陷阱, 而神经网络却几乎漫不经心地轻松应对)
4. “Neural networks have stacked covers, mathematically speaking, whereas the Numerical Manifold Method typically uses only 3 to 4. In contrast, neural networks stack hundreds or even thousands of such covers. I never imagined anyone would take it that far”. (神经网络在数学上拥有堆叠的覆盖层,而数值流形通常只有三到四层覆盖。相比之下,神经网络则堆叠了上百乃至上千层。我从未想过有人会将其推进到这种程度).
That was what Gen-Hua Shi (石根华) told me after returning from a two-week vacation in early June 2024..
see rest of the story, click the link
open.substack.com/pub/deepma…


3
4
30
8,672
Title: Preserving Plasticity in Continual Learning via Dynamical Isometry
Authors: Andries Rosseau, Robert Müller (@deepqlearning), Ann Nowé
From the Deep Manifold view, dynamical isometry helps preserve plasticity, but it is not the source of plasticity. The deeper source comes from high-order nonlinear data forcing stacked piecewise manifolds to form ring / torus-like stationary structures.
These coupled stationary structures create elastic directions where weak perturbations can move the solution without destroying previously learned geometry.
In this sense, layer-wise isometry is an important preservation mechanism, while Deep Manifold places plasticity inside a broader geometric picture: node-cover reorientation, accumulated curvature, interconnected toroidal geometry, and eventual manifold rigidity.
#DeepManifoldInterpretation

📄 Paper 6/6
Preserving Plasticity in Continual Learning via Dynamical Isometry
Rosseau A, Müller R, Nowe A.
Accepted at ICML 2026 Main Track
ICML: icml.cc/virtual/2026/poster/…
@deepqlearning
15
I like the CIF framing, but from a Deep Manifold perspective I would call it the product-facing projection of a deeper Model CAP constraint: Coverage, Accuracy, and Performance.
“Cheap” and “Fast” are both expressions of performance, while “Intelligent” mixes two different things: how much of the learning space the model covers, and how accurately it stabilizes around useful local fixed points.
A larger model or more test-time compute can improve coverage and accuracy, but usually increases active inference cost and latency. Hardware can move the frontier, but it does not remove the underlying constraint.
The real breakthrough will come from learning efficiency: better architecture, better manifold cover, better routing, and smaller active inference regions, so the system preserves intelligence while reducing the computation needed to reach a stable answer.
#DeepManifoldInterpretation
16h

here's the "CIF theorem" for AI models
Cheap, Intelligent, Fast - no model holds top tier performance on all 3 dimensions
why?
we have a few ways to increase intelligence:
1. more training data
2. larger model size
3. test time compute
1 has pretty much been exhausted
2 & 3 will both increase inference cost and latency, so this is the primary constraint
now.. can we hold one dimension static and improve on another? yes - through specialized inference hardware, we can reduce latency without losing intelligence. that is the "fast mode" that we're starting to see, but better hardware is more expensive so "fast mode" makes cost go up in both codex and claude
is there truly no way to improve all 3 axis at the same time? there is! we can do so by improving learning algorithm and model architecture
that will be one of the most interesting things to watch in the next couple of years. whoever can create a breakthrough on this front and maintain a moat, might just become the winner that takes it all

2
3
139
Title: From AGI to ASI
Affiliations: Mainly Google DeepMind
I would be cautious with the word superintelligence unless it is tied to a measurable evaluation matrix. “Super” sounds intuitive, but without specifying the task domain, baseline population, resource budget, autonomy level, reliability threshold, latency, cost, and time horizon, it becomes an ill-posed problem.
People may appear to discuss the same ASI question while actually using different boundary conditions. It is like saying “super vehicle”: do we mean fastest, safest, strongest, cheapest, longest range, or best under battlefield conditions? Each definition leads to a different answer.
From the Deep Manifold perspective, intelligence is not a free-floating label; it is a boundary-conditioned fixed-point problem. Without boundary conditions, there is no unique convergence path, no stable fixed point, and therefore no well-defined object called “superintelligence.”
Deep Manifold Part 2 emphasizes that boundary conditions provide iterative direction and shape convergence in neural systems
**Well-posed problem** (opposite of ill-posed)
en.wikipedia.org/wiki/Well-p…
#DeepManifoldInterpretation
Jun 12

Beautiful paper from Google DeepMind.
Explains the pathways from AGI to ASI, and why that jump could happen through several routes.
The authors frame the AGI-to-ASI transition around 4 technical pathways:
- continued scaling of compute, model size, data, and test-time inference;
- algorithmic paradigm shifts beyond today’s transformer-based foundation-model stack;
- recursive self-improvement, where AI accelerates AI R&D and improves future systems; and
- multi-agent collective intelligence, where large populations of specialized agents coordinate into a superhuman group agent.
Scaling may work for a while, but it could hit limits in data, compute, energy, or weaker returns from making systems larger.
Recursive improvement is the most uncertain path, because AI could speed up AI research, but that loop may also slow if hard research problems need real-world testing, scarce hardware, or new ideas.
Multi-agent collectives may be the most underappreciated path, because a society of competent digital workers could outperform a brilliant individual model through specialization, speed, and coordination.
The big point is that ASI may not arrive as 1 sudden event, but as a chain of faster changes as AI helps create better AI and stronger scientific tools.
----
Link – arxiv. org/abs/2606.12683
Title: "From AGI to ASI"

8
467
Jun 12
Title: A Bitter Lesson for Data Filtering
Authors : Christopher Mohri , John Duchi, Tatsunori Hashimoto (@tatsu_hashimoto)
Filtering helps when the model lacks enough capacity to separate manifold regions. But when the model is large enough, unfiltered data supplies weak stochastic perturbations across a broader manifold. These perturbations can activate more intrinsic pathways, stabilize more fixed-point basins, and improve generalization.
The “bitter lesson” here is not only scale beats curation; it is that over-curation may remove the very perturbations needed for fixed-point construction in high-order nonlinear data.
One caution: this should not be overstated as “all data is good.” The paper itself says harmful conditional shifts can still damage the model, for example systematically false statements that look like normal high-quality text.
Deep Manifold would say the same: useful perturbation nudges the manifold; adversarial or wrong conditional structure can anchor the wrong fixed point.
** Dataualism **
x.com/BetaTomorrow/status/20…
#DeepManifoldInterpretation
Jun 12

Wow, this is interesting..
@Stanford researchers put a common assumption to the test: large models need only “high-quality” filtered training data.
What if the best filter is no filter at all?
They compared full Common Crawl data with heavily filtered versions of it and got surprising results:
1. Filtering can help with small compute budgets, because models can't learn from everything well.
2. However, as models get larger and train longer, the full, unfiltered dataset becomes the winner.
Large models handle messy data better than expected – low-quality text, irrelevant text, or some “junk” data are not a big deal; these models can tolerate them.
And they can even extract useful signal from data that looks poor.
These facts transform general rules:
→ Filtering helps when compute is limited. But when compute is very large, removing too much data may throw away useful information.
This also connects with the concept of "bitter lesson": at large scale, simple scaling often beats clever human design.
But the final choice depends on your constraints and preferences – would you rather increase compute costs or put more resources and time into filtering?
Interesting to see your answers 👀

1
13
73
8,701
Jun 12
Title: DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation, arXiv: 2506.14202v3.
Makoto Shing and Takuya Akiba (@iwiwi) , Sakana AI; Masanori Koyama, The University of Tokyo.
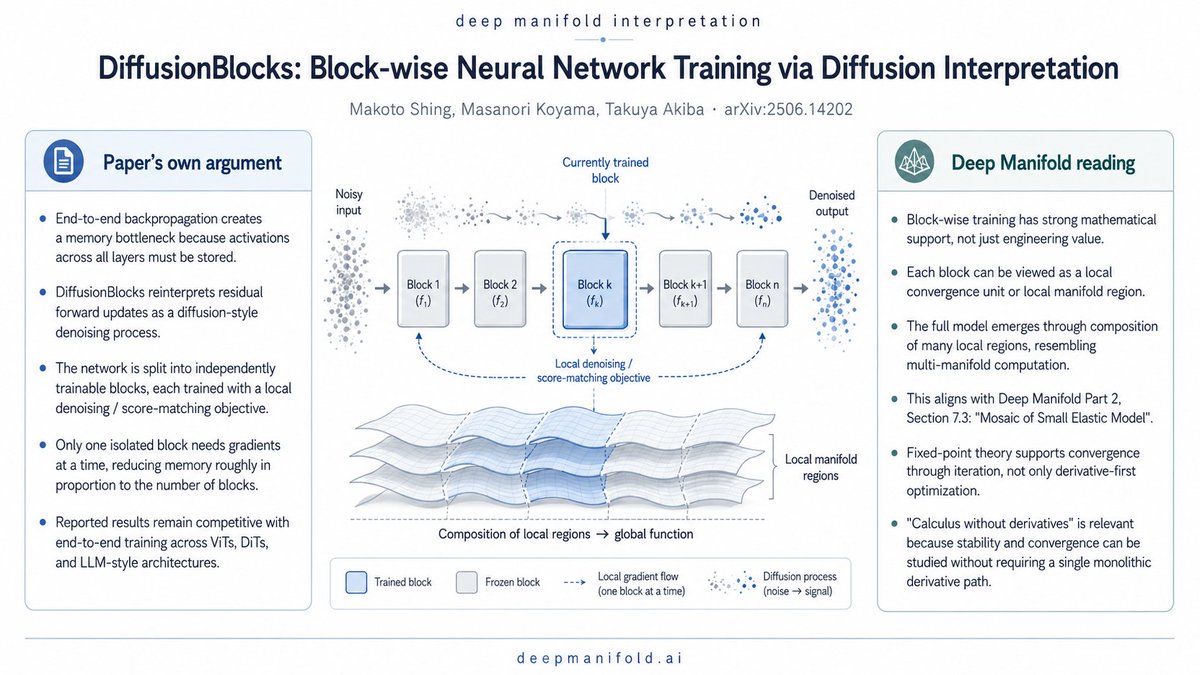
This work is more than memory reduction.
Block-wise training has strong mathematical support. A deep network does not have to be viewed only as one monolithic end-to-end object. It can also be understood as an iterative system, where each block acts as a local convergence unit and the full model emerges through the composition of many locally trained blocks.
From a Deep Manifold view, this resembles multi-manifold computation: each block learns a local manifold region, with its own local boundary condition and convergence pathway. The whole network then becomes a stacked pathway across these local manifolds, rather than a single global smooth object.
This connects directly to Deep Manifold Part 2: Neural Network Mathematics, Section 7.3, “Mosaic of Small Elastic Model.” The future of scalable AI may not be one ever-larger rigid model, but many local elastic models or blocks, each capturing a manageable piece of high-order nonlinear data.
The key mathematical point is fixed point theory: convergence is fundamentally about iteration, not necessarily classical derivatives. That is why the tradition of “calculus without derivatives” is relevant here. Stability, convergence, and solution construction can be studied beyond derivative-first end-to-end optimization.
This paper may be an early engineering signal toward block-wise, multi-manifold AI systems.
#DeepManifoldInterpretation
May 28

DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
arxiv.org/abs/2506.14202
2
4
51
2,915
Jun 11
Paper: MiniMax Sparse Attention from MiniMax
MiniMax Sparse Attention is important because it makes attention visible as a relational/compositional operator, not just token mixing. This is where the category-theory connection enters: neural networks learn relations among tokens, blocks, heads, and contexts more than isolated data objects. In this paper, the Index Branch learns which relationships are worth computing by selecting key/value blocks for each GQA group, and the Main Branch computes exact attention only over that selected relational support. Their two-stage design — indexer first, attention second — is very close to object-relation separation in category-theory intuition.
The paper also partially exposes the “high school math mistake” in standard learnable attention. Q/K measure relational similarity, while V carries content through that measured relation; these are different mathematical roles. Treating Q/K/V as just parallel learnable projections hides the distinction between relation measurement and value transport. MiniMax does not fully solve this, but its Index Branch is explicitly relational: it learns a sparse cover over the long-context manifold, while the Main Branch performs local/blockwise integration over that cover. Its warmup, KL alignment, and detach are therefore manifold-stabilization mechanisms, not just engineering tricks.
** Single Token Geometry 07: Attention 单标几何 07:注意力 **
x.com/BetaTomorrow/status/20…
#DeepManifoldInterpretation
Jun 11

Hey everyone — our high-performance MSA kernel library is now open-source. The M3 weights are expected to drop this Friday. Thanks for waiting!
Github: github.com/MiniMax-AI/MSA
Paper:github.com/MiniMax-AI/MSA/bl…

2
30
1,424
Jun 11
1. Complexity is Rooted in High-Order Nonlinearity and Discontinuity
True computational complexity does not come from high dimensionality alone; it arises when a system exhibits high-order nonlinearity and discontinuous boundaries (such as sudden fractures or sharp data shifts). When an environment is strictly linear, optimization is straightforward, but the moment you introduce highly nonlinear dynamics, finding the best solution (the global minimum) becomes an NP-hard problem.
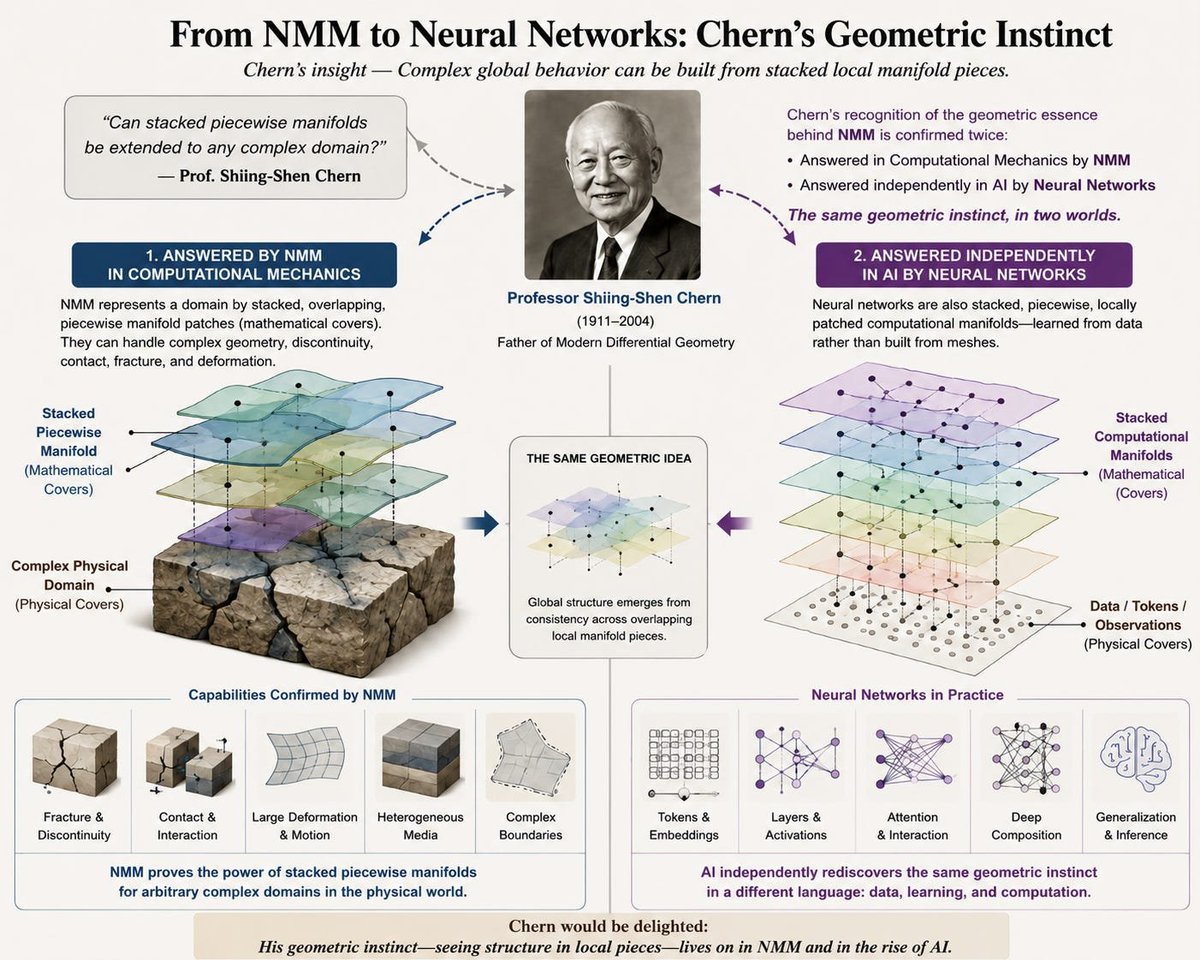
2. NMM Solves This via Functional Decomposition and Stacked Manifolds
Traditional methods (like FEM) hit a wall because they try to chop up physical space into a rigid grid, but the Numerical Manifold Method (NMM, Gen-Hua Shi) elegantly decouples the math from the physical space. NMM tackles high-order nonlinearities by decomposing the function that describes the system across independent, overlapping mathematical "covers". This stacked manifold approach allows NMM to model extreme discontinuities and complex behaviors without being bottlenecked by the need to constantly remesh physical geometry.
3. Neural Networks Unknowingly Adopted This Architecture, Unlocking Their Power
Deep learning has achieved such incredible success because it accidentally stumbled into this exact mathematical framework. By unknowingly adopting the mechanics of stacked manifolds, neural networks avoid the impossible task of navigating tangled data directly. Instead, the network decomposes incredibly complex, highly nonlinear target functions into a series of stacked, localized functional approximations (using layers and neurons). By decomposing the function rather than the space, neural networks escape the rigid geometry trap, allowing them to stretch, fold, and adapt to almost infinite complexity.
Professor Shiing-Shen Chern, widely regarded as the father of modern differential geometry, served as one of the three members of the Shi PhD dissertation committee (UC Berkeley), providing academic validation for the mathematical framework of numerical manifold method and laying the foundation for the subsequent development of the theory. Chern’s only question was: 'Can stacked piecewise manifolds be extended to any complex domain? He would have been delighted to see the progress in neural networks, as their geometry can be understood as stacked piecewise manifolds.
Jun 1

Avi Wigderson is the only person in history to have won both a Turing Award (computer science) and Abel Prize (math). I interviewed him all about his field. We discussed:
• His intuition on a proof of P vs NP
• Why we use SAT solvers for most NP problems
• Zero knowledge proofs and their impact
• Quantum computation and implications
• Math and computer science's relationship
Where to watch:
• YouTube: youtu.be/5GUcvSAJcJw
• Spotify: open.spotify.com/episode/4JZ…
• Apple Podcasts: podcasts.apple.com/us/podcas…
• Transcript: developing.dev/p/turing-awar…
Thank you to this episode's sponsors for supporting my work:
• WorkOS: makes your app Enterprise Ready with easy to use APIs to add SSO, SCIM, RBAC, and more in just a few lines of code, check them out at workos.com/
Timestamps:
00:00 - Intro
01:08 - P vs NP
14:51 - What if you relaxed correctness
25:38 - Why NP complete problems are equivalent
30:33 - Space vs time complexity
43:06 - Why people use SAT solvers
45:53 - Randomness is a resource
55:48 - Randomness depends on computational power
01:21:20 - Zero knowledge proofs and their significance
01:38:30 - Quantum computation and why it matters
01:56:24 - Math vs computer science
02:08:16 - Major breakthroughs and his experience
02:12:31 - Advice for his younger self
02:14:48 - Outro
1
6
54
2,578
Jun 11
Recursive’s result is very meaningful as automated bounded research, especially for engineering-like AI optimization. But it should not be confused with broad automated scientific discovery. In bounded AI training tasks, the metric can act as a usable boundary functional.
In broad science, we often do not yet know the boundary functional. We are trying to infer the law, the variables, the geometry, and the reward at the same time. That makes the problem not just another optimization loop, but a higher-order inverse problem with an uncertain target.
#DeepManifoldInterpretation

450
Jun 10
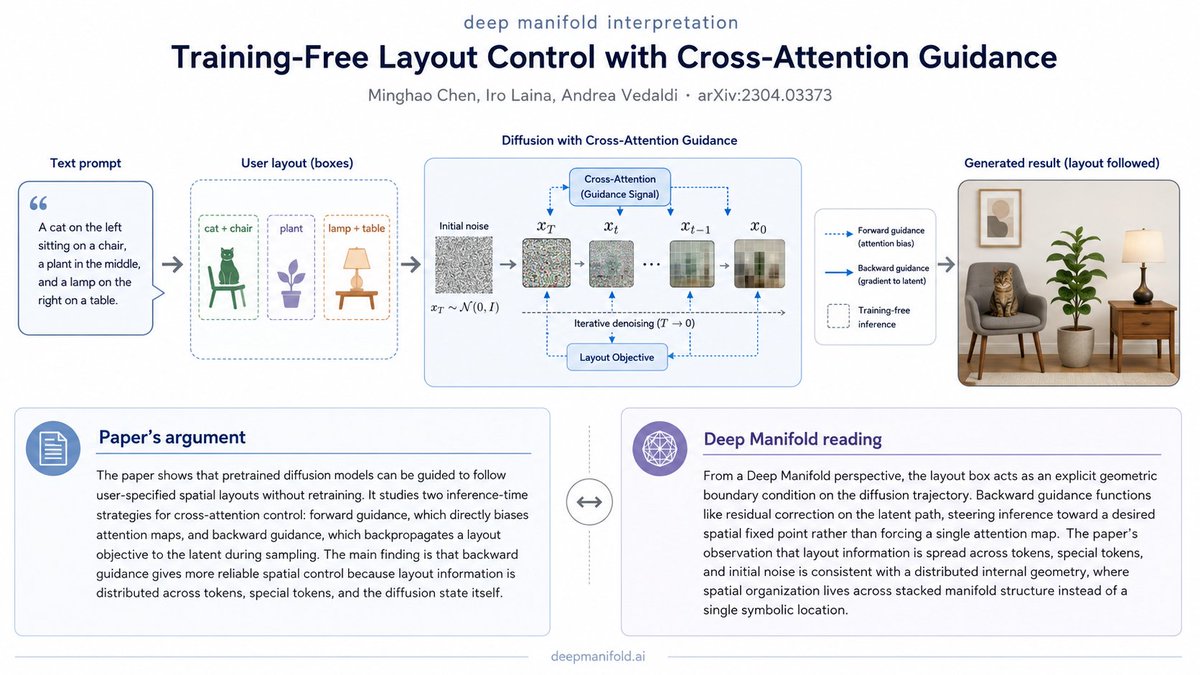
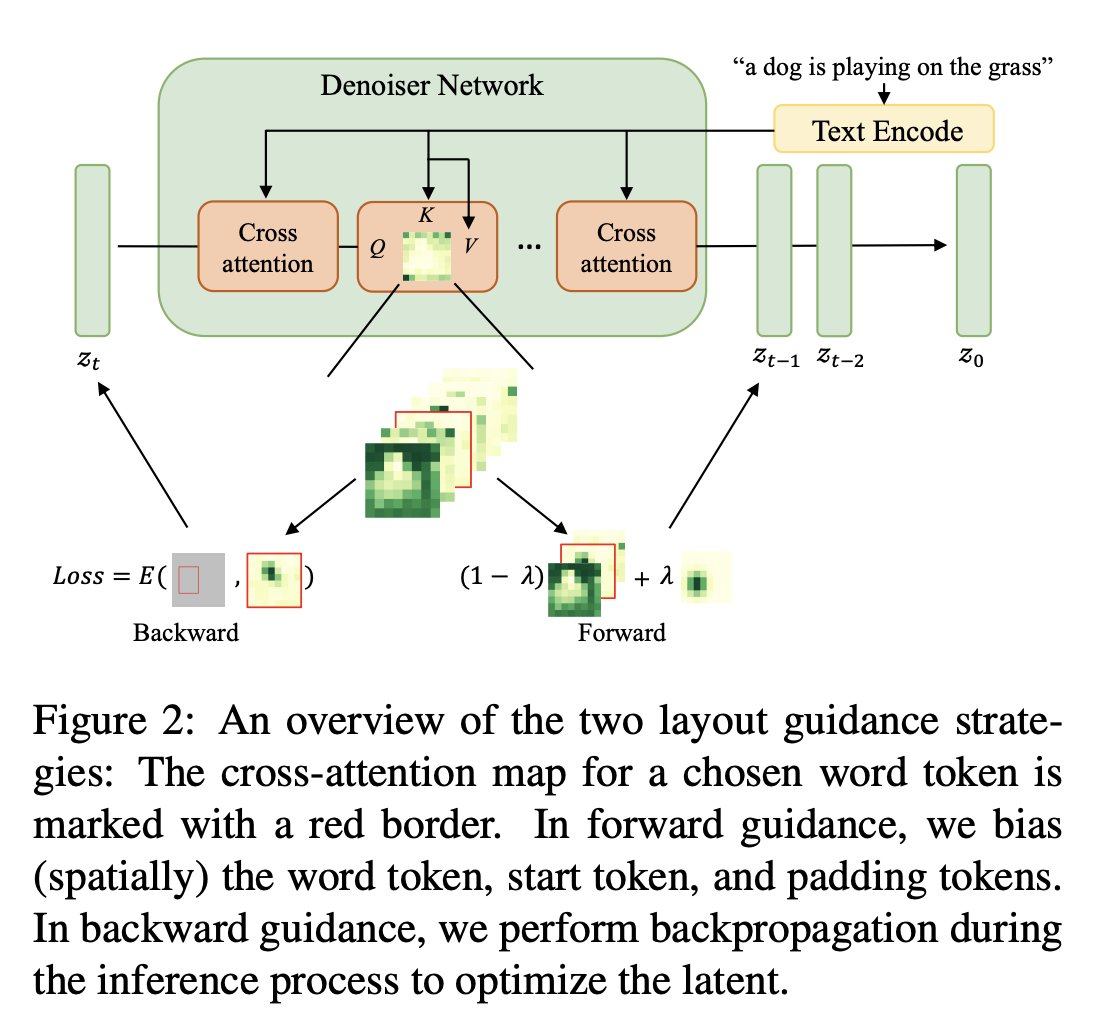
From a Deep Manifold lens, Training-Free Layout Control with Cross-Attention Guidance shows that layout in diffusion models is not controlled by text semantics alone, but by inference-time boundary conditions imposed on the model’s stochastic trajectory.
The paper’s main result is that bounding boxes can guide pretrained diffusion models without retraining by shaping cross-attention, especially through backward guidance that updates the latent state rather than forcing one token map directly.
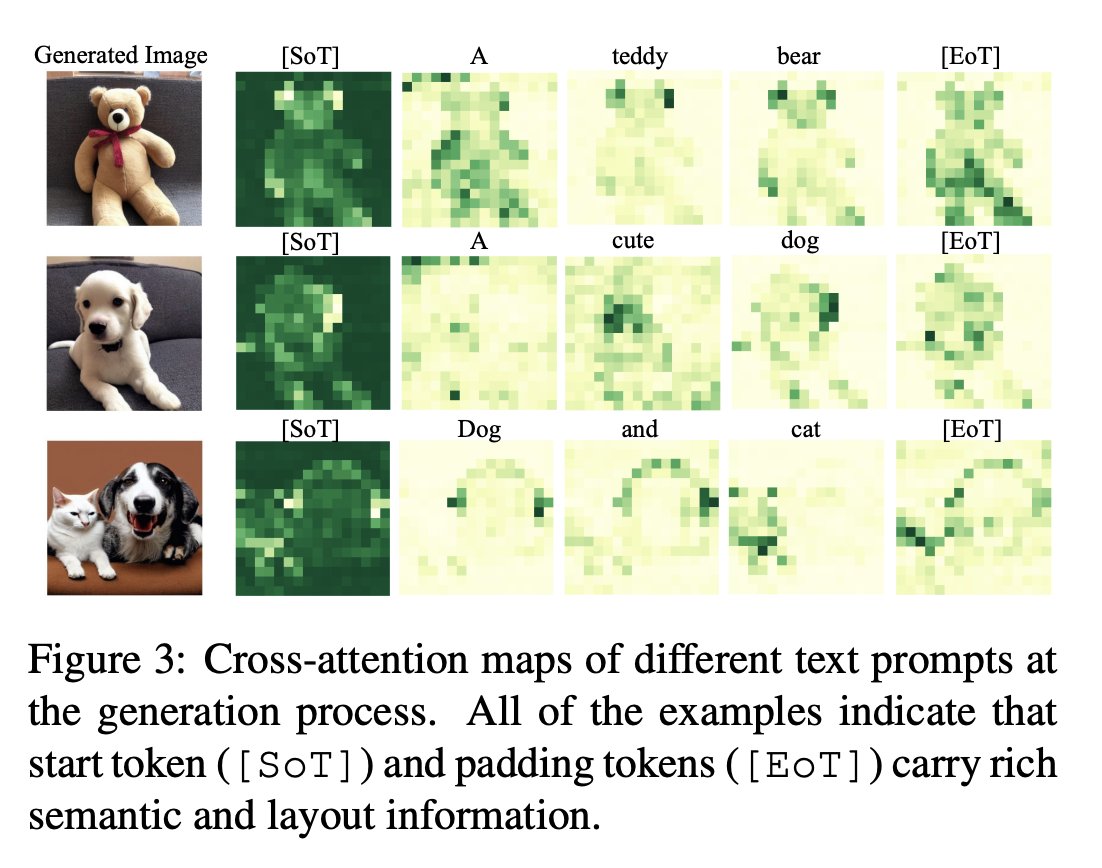
This matters because the authors find layout information is distributed across object tokens, special tokens, and even initial noise, meaning spatial structure lives across the model’s stacked internal geometry rather than in a single symbolic label.
In Deep Manifold terms, the box acts as a geometric boundary condition, backward guidance acts as residual correction, and the diffusion process is steered toward a desired spatial fixed point already latent in the pretrained manifold.
#DeepManifoldInterpretation

[CV] Training-Free Layout Control with Cross-Attention Guidance
M Chen, I Laina, A Vedaldi [University of Oxford] (2023)
arxiv.org/abs/2304.03373


1
400
Jun 10
Paper: Topological Neural Operators
Authors: Lennart Bastian(@lennart_bastian), Tolga Birdal(@tolga_birdal), Samuel Leventhal and Mustafa Hajij (@HajijMustafa)
From a Deep Manifold view, Topological Neural Operators is valuable because it shows that operator learning improves when geometry is not treated as an afterthought.
The paper’s own argument is that TNOs lift neural operators from point-only domains into cell complexes, where vertices, edges, faces, and volumes each carry the physical quantities that naturally belong there.
Our reading is separate: this is a strong example of geometry pre-structuring admissible computation before learning begins. It reduces the burden on the neural network by fixing part of the topological information flow, while leaving the feature transformation learnable.
The limitation is equally important: the topology is still mostly prescribed, so TNO is best understood as geometry-guided neural operator learning, not yet a full boundary-conditioned Deep Manifold system where the manifold itself is dynamically constructed, deformed, and stabilized through fixed-point iteration.
#DeepManifoldInterpretation
15
112
4,076
Jun 10
Paper: Do Transformers Need Three Projections? Systematic Study of QKV Variants
This paper gives empirical support to a Deep Manifold suspicion: standard Q/K/V attention may over-separate roles that are not intrinsically separate inside a propertyless neural representation.
Q must remain distinct because it defines directional relational probing, but K and V can often share the same learned manifold cover.
In other words, attention may need a separate relational operator, not three fully independent projections. The “mistake” is not that QKV fails, but that the field treated its tripartite projection as mathematically necessary rather than as an inherited architectural convention.
**The High School Math Mistake**
x.com/BetaTomorrow/status/20…
#DeepManifoldInterpretation

Jun 9

1/
We have spent years optimizing KV cache via head-sharing (GQA/MQA), but we ignored a fundamental assumption: why do Transformers need three separate Q, K, and V projections in the first place?
Turns out, they don't. Merging them unlocks massive memory savings. 🧵

2
19
1,154
Jun 10
Paper: Specialization of softmax attention heads: insights from the high-dimensional single-location model
One interesting point this paper highlights is that attention-head specialization is not automatically beneficial.
Since attention heads are trainable relational measures, early heads may capture the strongest similarity structure, while later heads are left to learn weaker, noisier, or redundant relations.
In standard softmax attention, these less useful heads are not naturally turned off, so they may continue contributing variance rather than meaningful structure.
This makes head specialization a subtle fixed-point process: useful heads stabilize around meaningful relational pathways, while weaker heads may remain active without adding much value.
#DeepManifoldInterpretation
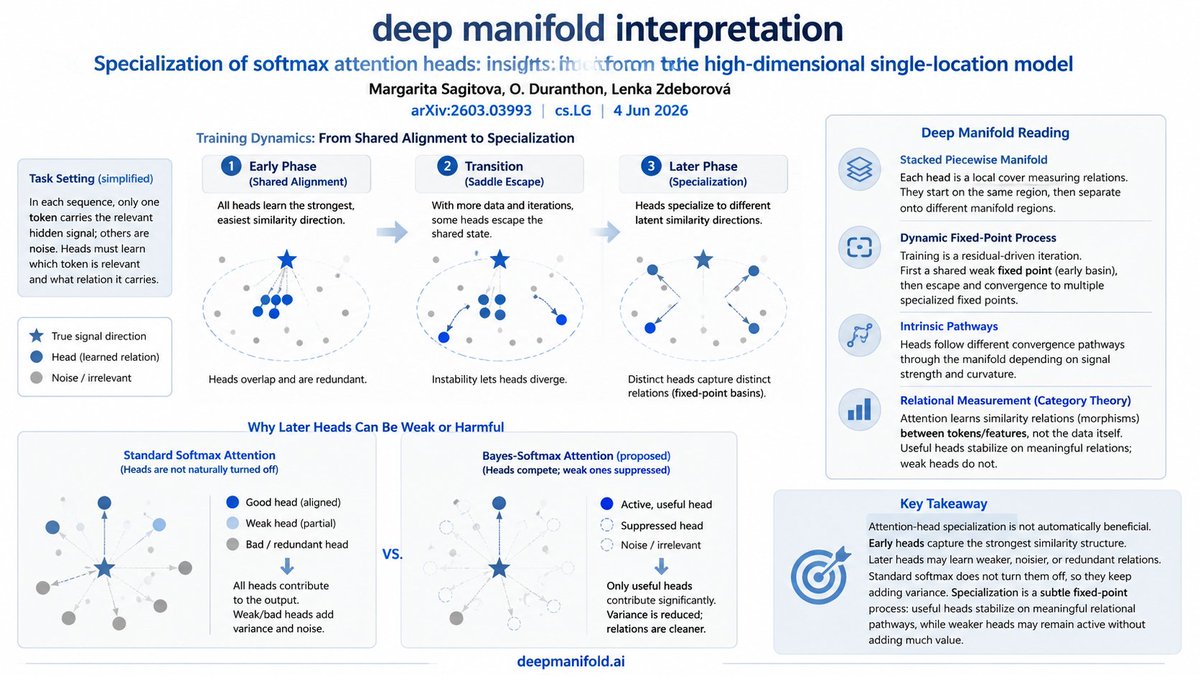

Transformer training often proceeds through sudden changes: new capabilities appear, attention heads specialize, many heads remain redundant.
We build a solvable model explaining staged head specialization through symmetry breaking and signal structure. arxiv.org/abs/2603.03993
4
26
1,592
Jun 9
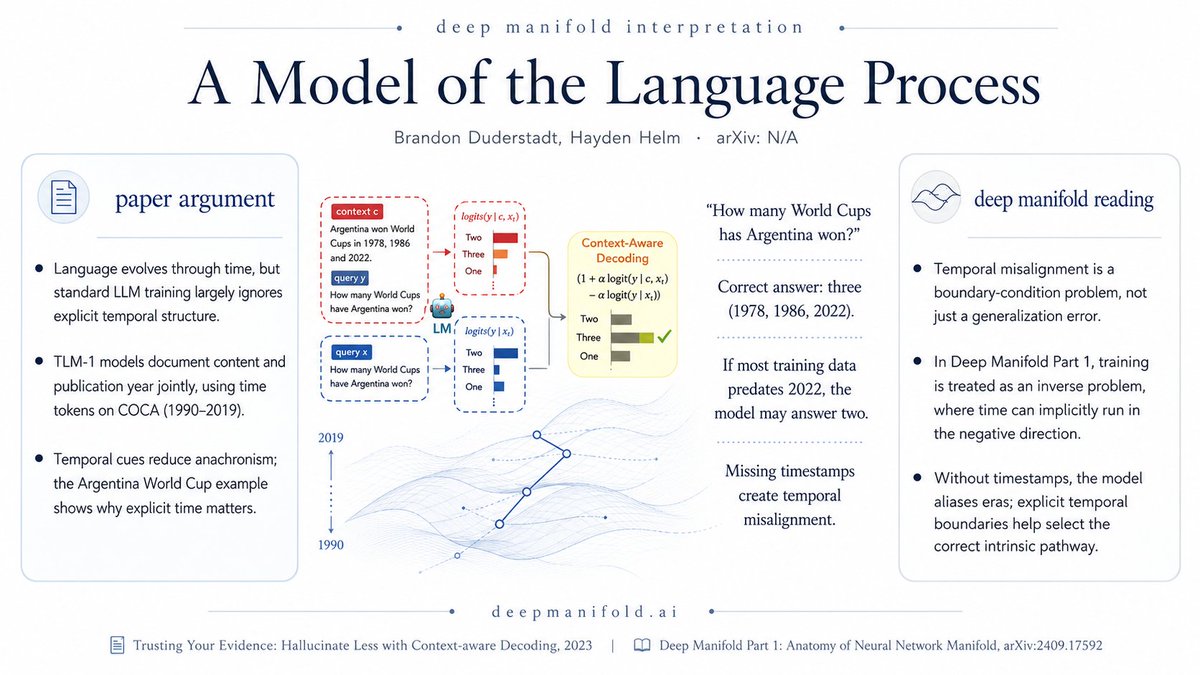
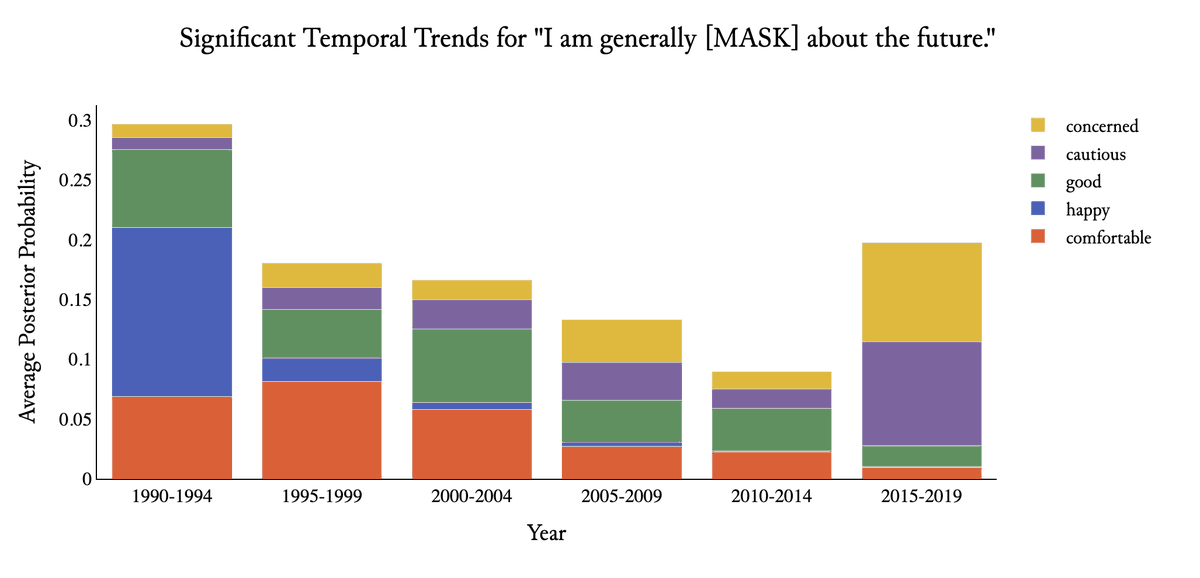
This paper (A Model of the Language Process) exposes a major oversight in today’s AI community: LLMs largely lack explicit temporal elements, even though language and knowledge evolve through time.
One example from "Trusting your evidence: Hallucinate less with context-aware decoding, 2023", The Argentina World Cup example shows the problem clearly: without a strong timestamp, a model trained mostly before 2022 may answer “two” instead of “three,” not because it failed to generalize, but because it converged to the wrong temporal context.
From the Deep Manifold perspective, this is a missing boundary-condition problem: as argued in Deep Manifold Part 1: Anatomy of Neural Network Manifold, 2024 (Section 3.1) neural-network training is an inverse problem, and inverse problems may inherently involve negative time. Without explicit temporal boundary conditions, the model aliases different eras and selects the wrong intrinsic pathway; adding time restores orientation to the learned manifold.
#DeepManifoldInterpretation

today, we're releasing the first public research report from calcifer computing: A Model of the Language Process.
as of yesterday, it has been accepted to the @aclmeeting 2026 Main Conference. You can read the report as an interactive blog post here: calcifercomputing.com/report…
1
2
18
1,442