
May 15
📢 #highlycited paper
📚 Slim-YOLO: An Improved Sugarcane Tail Tip #RecognitionAlgorithm Based on #YOLO11n for Complex Field Environments
🔗 mdpi.com/2076-3417/15/8/4286
👨🔬 by Chunming Wen et al.
🏫 Guangxi University for Nationalities/Guangxi Zhuang Autonomous Region Intelligent Visual Collaborative Robot Engineering Research Center/Guangxi University Engineering Research Center for Multimodal Information Intelligent Sensing Processing and Application/State Key Laboratory for Conservation and Utilization of Subtropical Agro-Bioresources
#complexenvironment #featureextraction

1
2
109
Apr 13
📢 #highlycited paper
📚 Multi-View Jujube Tree Trunks Stereo Reconstruction Based on UAV #RemoteSensing Imaging Acquisition System
🔗 mdpi.com/2076-3417/14/4/1364
👨🔬 by Shunkang Ling et al.
🏫 Shihezi University/Xi'an Jiaotong University
#3Dreconstruction #featureextraction

1
3
70
Mar 27
📢 #highlycited paper
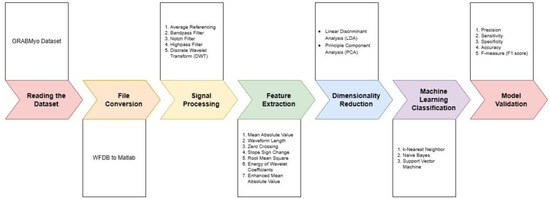
📚 #MachineLearning-Based #FeatureExtraction and Classification of #EMGSignals for #IntuitiveProstheticControl
🔗 mdpi.com/2076-3417/14/13/578…
👨🔬 by Chiang Liang Kok et al.
🏫 University of Newcastle/Singapore Institute of Technology/Singapore University of Social Sciences
#signalprocessing
4
2
43

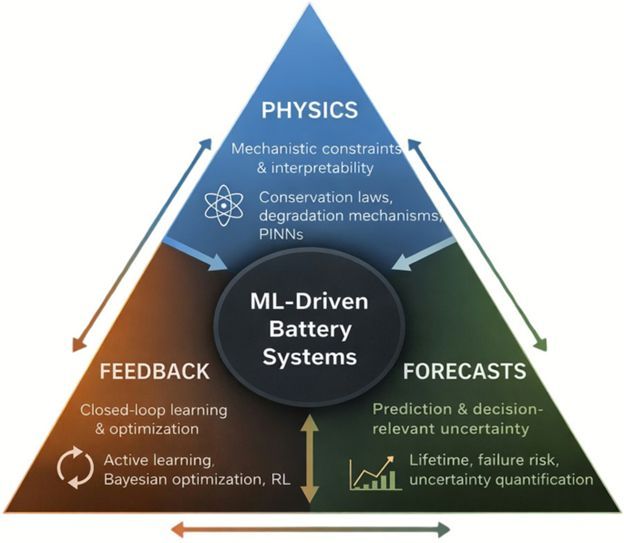
This #OpenAccess #MRSEnergyJournal special issue article consolidates a decade of progress in #ML-driven #battery innovation, from early-cycle #FeatureExtraction to #operandoImageAnalysis and #PhysicsInformedModeling.
1
4
295

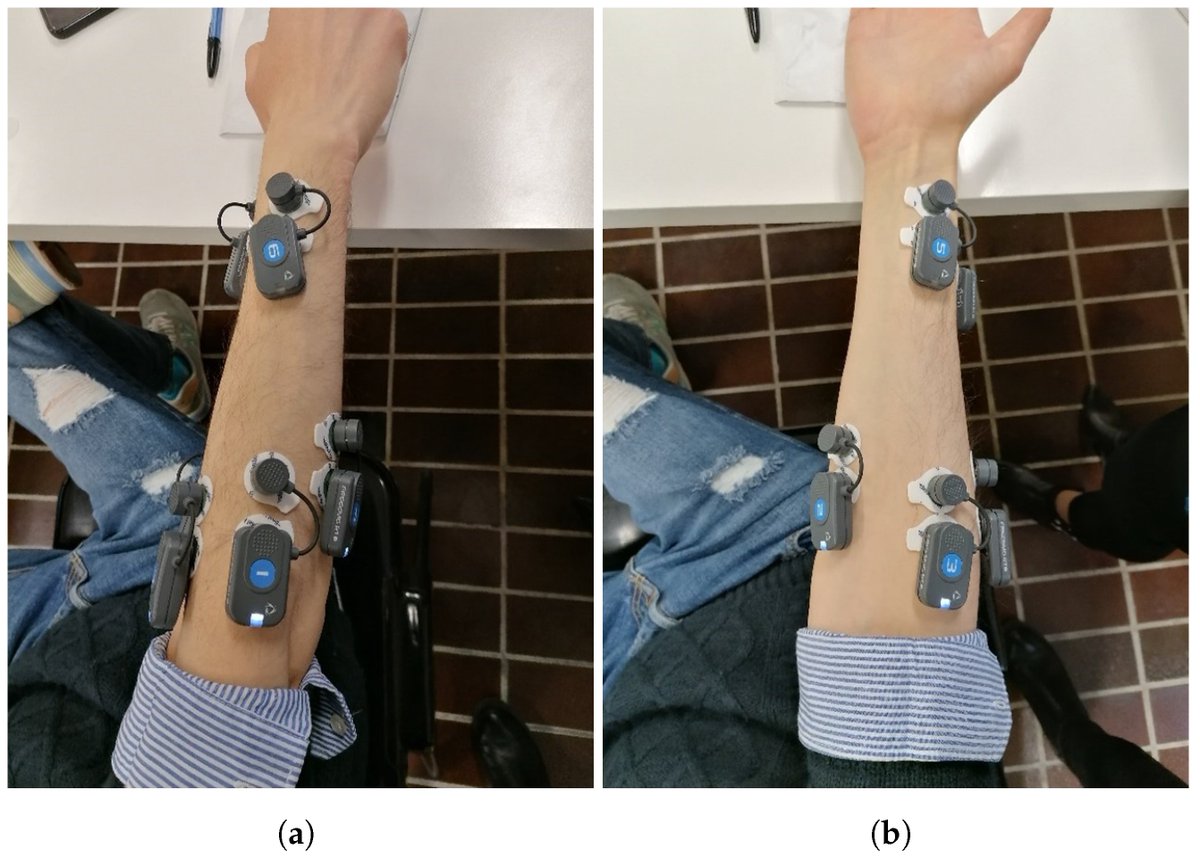
💥Highly recommended publication: "Intelligent Human–Computer Interaction: Combined Wrist and Forearm Myoelectric Signals for Handwriting Recognition"
🔗 shorturl.at/cki2r
🏫 @UnivPoliMarche @UnivRoma3
📌#EMG #handwriting #patternrecognition #featureextraction
4
62

3 Dec 2025
ffmpegのblurdetectでブラーフレームを除去して3DGS学習してみた。処理フローまとめると
1. OSMO360の全フレームのブラー値計算
2. 30フレーム中ブラー値が最小なフレームを採用
3. 12視点切り出し
4. Comap FeatureExtraction&Matching
5. GLOMAP reconstruction
6. PostShot 3DGS train
ぶっちゃけそんなに差は無い(悲報)
左:ブラー除去有、右:ブラー除去無


10
645

1 Dec 2025
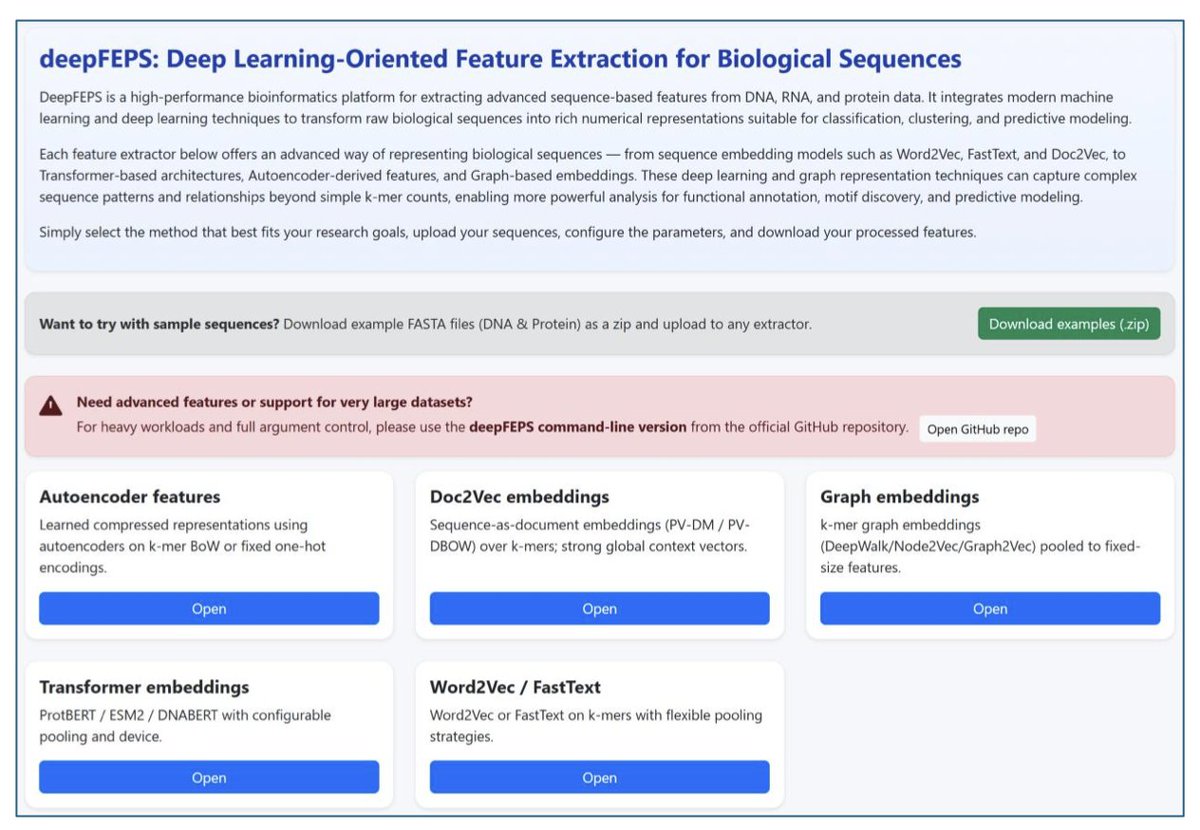
DeepFEPS: Deep Learning-Oriented Feature Extraction for Biological Sequences
1. DeepFEPS is a groundbreaking toolkit that unifies advanced feature extraction methods for biological sequences into a single platform, making it easier for researchers to transform raw DNA, RNA, and protein sequences into numerical representations suitable for machine learning and deep learning. This integration significantly reduces the preprocessing overhead and enhances reproducibility.
2. The toolkit incorporates five families of modern feature extractors: k-mer embeddings (Word2Vec, FastText), document-level embeddings (Doc2Vec), transformer-based encoders (DNABERT, ProtBERT, ESM2), autoencoder-derived latent features, and graph-based embeddings. Each method captures different aspects of sequence information, providing a comprehensive toolkit for diverse bioinformatics tasks.
3. DeepFEPS offers both web-based and command-line interfaces, catering to users with varying computational backgrounds. The web server is ideal for exploratory analyses, while the command-line interface supports large-scale processing and integration into institutional workflows. This dual accessibility ensures flexibility and scalability.
4. One of the most innovative aspects of DeepFEPS is its automated quality-control reports, which include sequence counts, dimensionality, sparsity, variance distributions, class balance, and diagnostic visualizations. These reports help users quickly assess data quality and make informed decisions about preprocessing steps.
5. The inclusion of transformer-based encoders marks a significant advancement, as these models leverage self-attention to capture long-range dependencies in sequences. This capability is crucial for tasks like protein structure prediction and regulatory element identification, where context and sequence relationships are key.
6. DeepFEPS is designed to be extensible, allowing for the integration of emerging models and methods in the future. This forward-thinking approach ensures that the toolkit remains relevant as the field of bioinformatics continues to evolve rapidly.
7. The toolkit is freely available as an open-source project, with both a web server and a GitHub repository for the command-line version. This accessibility ensures that researchers worldwide can benefit from the latest advancements in sequence feature extraction without barriers.
📜Paper: arxiv.org/abs/2511.22821
#Bioinformatics #DeepLearning #FeatureExtraction #BiologicalSequences #Toolkit #OpenSource
1
4
939
1 Dec 2025
GLOMAPの別例、紅葉した大山寺3DGSです。
[OSMO360 -> 799images -> 12視点reframe -> COLMAP FeatureExtraction&Matching -> GLOMAP]
3DGSの仕上がりはCOLMAPのreconstructionと同等と思います。GLOMAPはCPU処理でも十分早いので、COLMAPをマルチGPUで高速化した方が効果大きいと思います。
あと、GLOMAPのreconstuction後のpoint cloudの色情報を抜き出す処理がシングルスレッド処理のようでそこも大幅改善が見込めると思います。
#大山寺 #丹沢 #登山 #GLOMAP
30 Nov 2025

Global SfMのGLOMAP試してみたよ。V1.2.0からColmap camera rigサポートしてて、問題なくSfMできてた。
GLOMAPのカバー範囲はreconstruction部分だけで、Feature MatchingまではColmapで処理する必要あり。比較計測してないけどIncremental SfMより10倍以上早いのはその通りな感じです。Feature MatchingまではマルチGPUでリニアにスケールできるので、最後にGLOMAPでさらに高速化はありだと思う。
1
9
121
10,558

25 Oct 2025
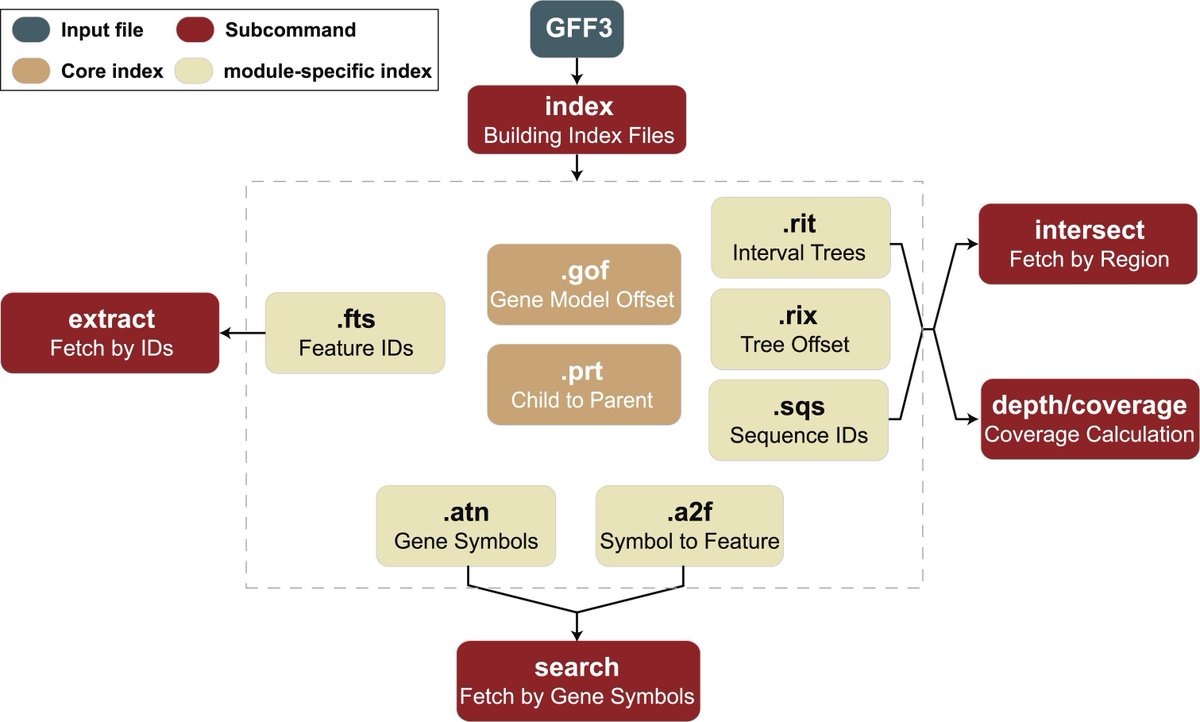
GFFx: A Rust-based suite of utilities for ultra-fast genomic feature extraction. #GFF #GenomicFeatures #FeatureExtraction #Rust @GigaScience
academic.oup.com/gigascience…
1
10
49
2,511
22 Aug 2025
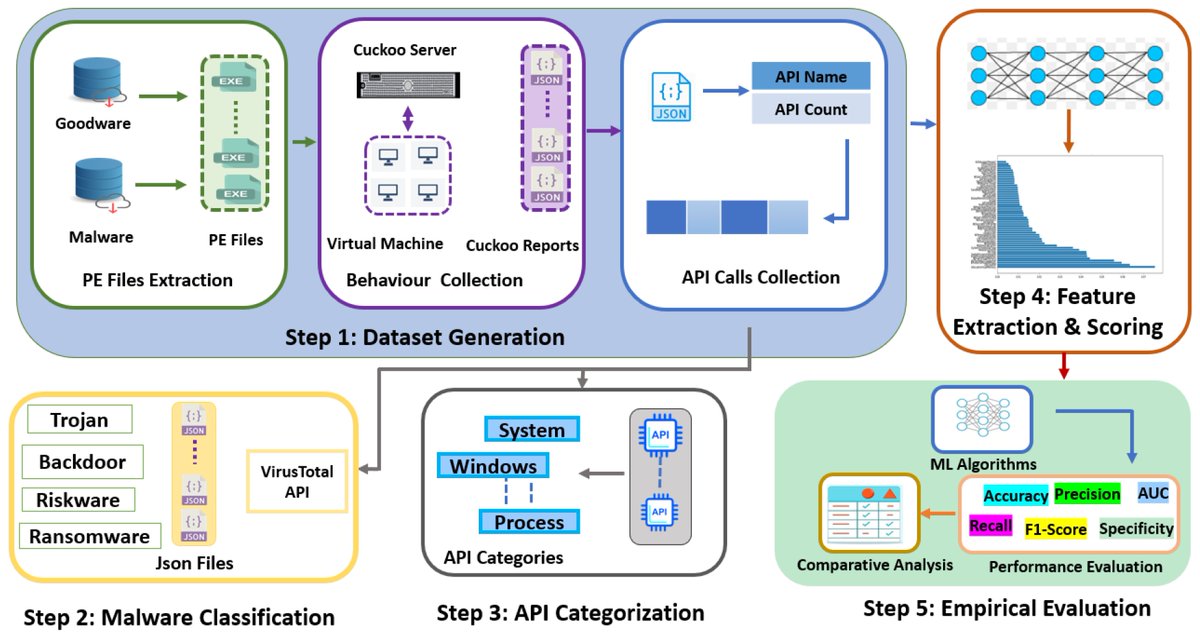
🔥 Read our Highly Cited Paper
📚 Dynamic #Malware Classification and API Categorisation of Windows Portable Executable Files Using #MachineLearning
🔗 mdpi.com/2076-3417/14/3/1015
👨🔬 by Mrs. Durre Zehra Syeda and Dr. Mamoona Naveed Asghar
🏫 University of Galway
#featureextraction
1
2
69

11 Aug 2025
@CHESS_EU #event
#SP2I at #ares2025 @ARES_Conference 2025
Lukas Malina presented research on "Optimizing #IoT #Attack #Detection in Edge AI: A Comparison of Lightweight Machine Learning Models and Feature Reduction Techniques”
--
#IoT, #EdgeAI, #AttackDetection, #MachineLearning, #Optimization, #FeatureSelection, #FeatureExtraction
More at: link.springer.com/chapter/10…

4
86
5 Aug 2025
🔥 Read our Highly Cited Paper
📚 Multi-View Jujube Tree Trunks Stereo Reconstruction Based on #UAV #RemoteSensing Imaging Acquisition System
🔗 mdpi.com/2076-3417/14/4/1364
👨🔬 Shunkang Ling et al.
🏫 @ShiheziUniv / Xi'an Jiaotong University
#3Dreconstruction #deeplearning #multiviewstereo #featureextraction

2
58
28 Jul 2025
🔥 Read our Paper
📚 PhotoMatch: An Open-Source Tool for Multi-View and Multi-Modal Feature-Based Image Matching
🔗 mdpi.com/2076-3417/13/9/5467
👨🔬 by Esteban Ruiz de Oña,Inés Barbero-García, Diego Gonzalez-Aguilera, Fabio Remondino, Pablo Rodríguez-Gonzálvez and David Hernández-López
@usal
#photogrammetry #featureextraction #handcraftedmethods

2
199
15 Jul 2025
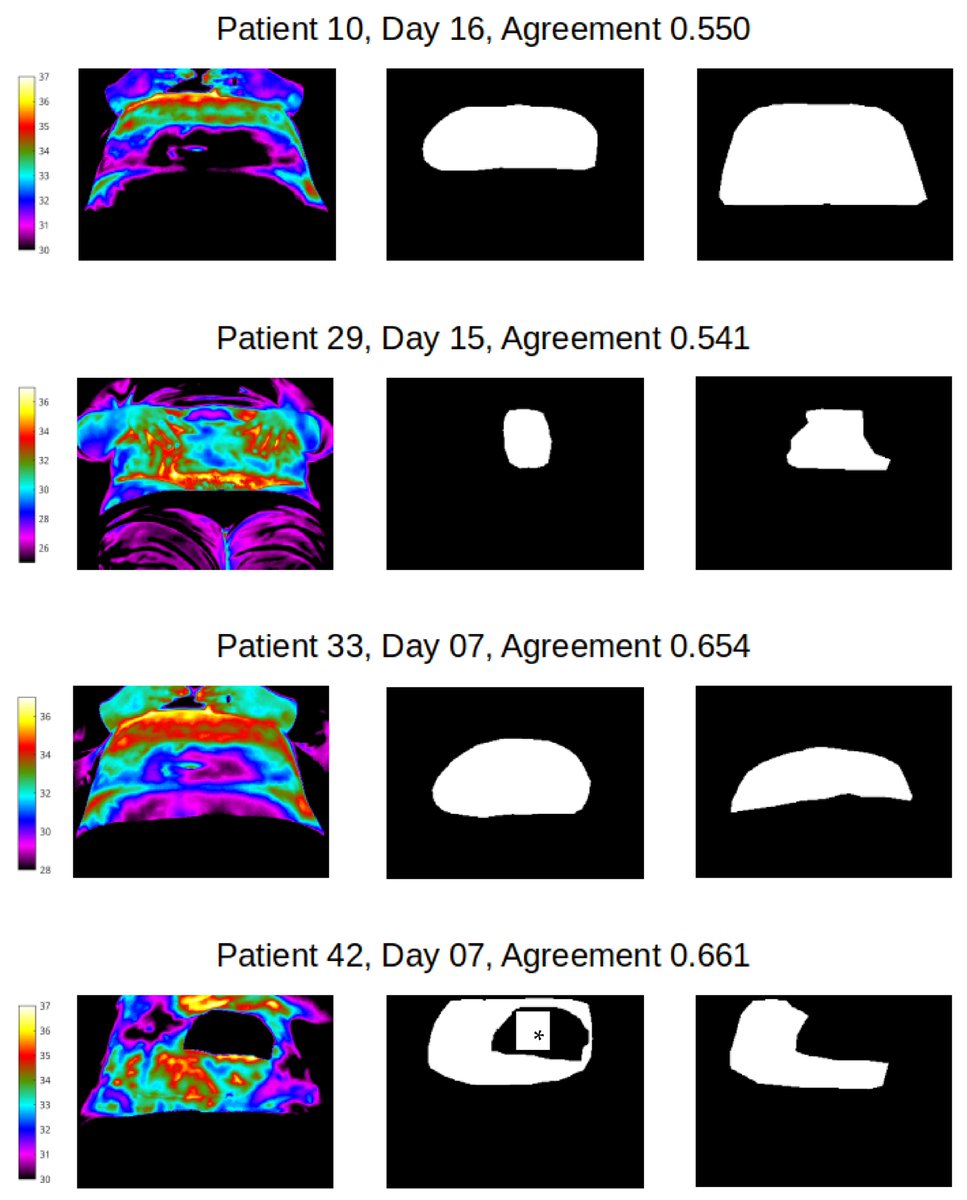
🔥 Read our Paper
📚 #Segmentation Agreement and AI-Based #FeatureExtraction of Cutaneous #InfraredImages of the Obese Abdomen after #CaesareanSection: Results from a Single Training Session
🔗 mdpi.com/2076-3417/13/6/3992
👨🔬 by Charmaine Childs, Harriet Nwaizu, Oana Voloaca and Alex Shenfield
🏫 @sheffhallamuni
#Infraredthermography #machinelearning
3
62

29 May 2025
Click-event sound detection in automotive industry using machine/deep learning
Applied Soft Computing
sciencedirect.com/science/ar…
researchgate.net/publication…
#ann #ai #ml #audio #dl #soundrecognition #featureextraction #supervisedlearning
2
3
170
6 May 2025
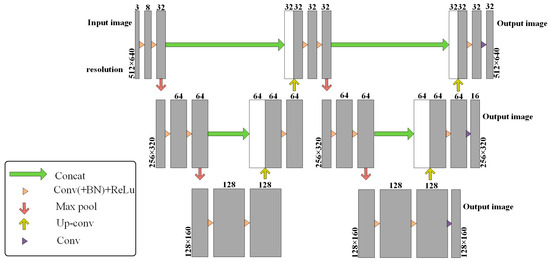
🔥 Read our Paper
📚 Multi-View Jujube Tree Trunks Stereo Reconstruction Based on UAV Remote Sensing Imaging Acquisition System
🔗 mdpi.com/2076-3417/14/4/1364
👨🔬 by Shunkang Ling,Jingbin Li,Longpeng Ding andNianyi Wang.
🏫 Shihezi University
#3Dreconstruction #deeplearning #multiviewstereo #remotesensing #featureextraction
1
2
88

18 Mar 2025
#MyOAarticle #GTIPapers Check out the Journal paper: "Enhanced Nighttime Vehicle Detection for On-board Processing” recently published in IEEE Access! doi.org/10.1109/ACCESS.2025.… @La_UPM @telecoupm #Lighting #VehicleDetection #FeatureExtraction #Detectors #Accuracy #YOLO #UrbanAreas

3
5
108
11 Mar 2025
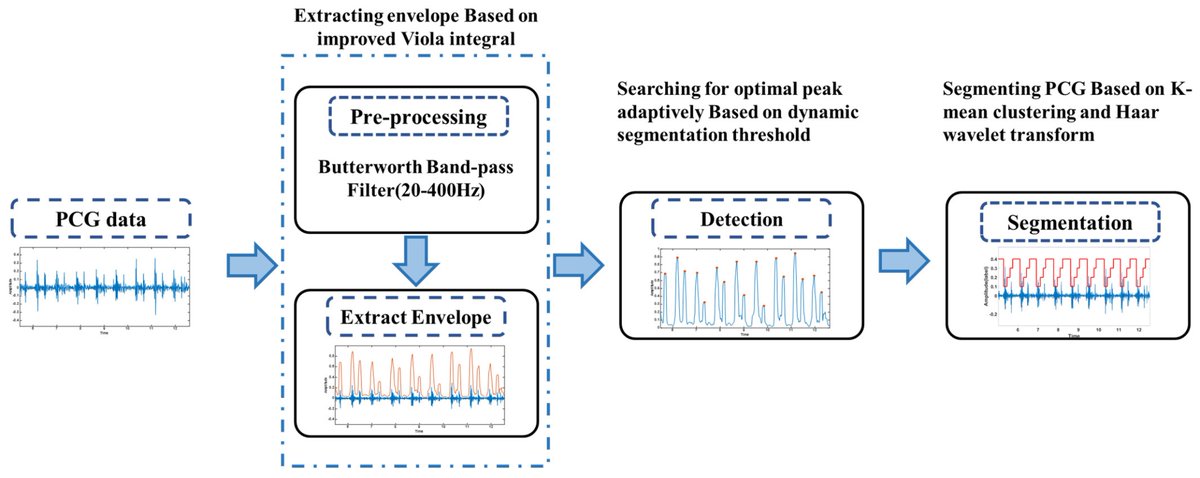
🔥 Read our Paper
📚 Optimal Heart Sound Segmentation Algorithm Based on K-Mean Clustering and Wavelet Transform
🔗 mdpi.com/2076-3417/13/2/1170
👨🔬 by Dr. Xingchen Xu et al.
🏫 @UCAS1978
#cardiovasculardisease #featureextraction
2
69
6 Feb 2025
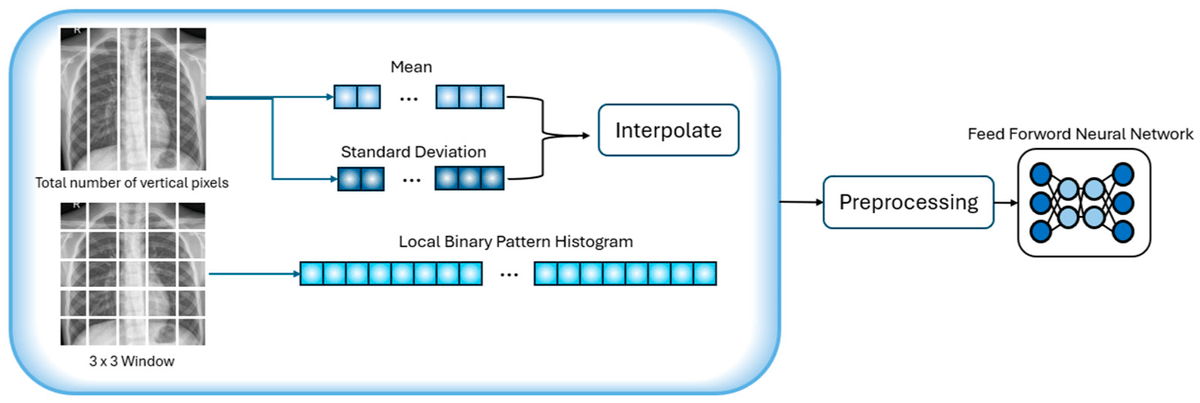
🔥 Read our Paper
📚 An Efficient One-Dimensional Texture Representation Approach for Lung Disease Diagnosis
🔗 mdpi.com/2076-3417/14/22/106…
👨🔬 by Abrar Alabdulwahab et al.
#imageprocessing #featureextraction
1
38

13 Jan 2025
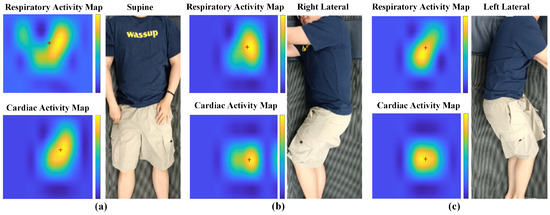
Smart Sleep Monitoring: Sparse Sensor-Based Spatiotemporal CNN for Sleep Posture Detection
mdpi.com/1424-8220/24/15/483…
#posturedetection #featureextraction
1
92