
🤖🦾 @saturdayrobotic Robotics & World Model Reading Club 12 Recap: @DanielXieee (@QuantingX7410) on Reproducible Robotic Dexterity Benchmarking: From Grasp Taxonomies → Multi-Axis Evaluation → Physical AI
Dexterity remains one of robotics’ least standardized capabilities. Binary success rates and static grasp taxonomies fail to capture fluent manipulation. Progress requires reproducible benchmarks, automated evaluation, embodiment-aware hardware, and foundation models capable of generating diverse yet semantically meaningful rollouts for post-training.
📏 Human Dexterity Foundations
Occupational-therapy benchmarks provide repeatable human baselines:
• O’Connor Finger Dexterity Test: high-density pin insertion throughput.
• Purdue Pegboard Test (Tiffin, 1948): single/bimanual insertion speed & accuracy.
These measure coordination, learning curves, and fine-motor throughput under standardized protocols.
✋ Why Grasp Taxonomies Are Insufficient
The classic 33-grasp taxonomy spans Power/Intermediate/Precision grasps (diameter, sphere, disk, prismatic, tripod, lateral, pincer, hook, adduction, parallel-extension, etc.). It measures manipulation vocabulary (available poses), not fluency (dynamic coordination under spatial, temporal, contact, force, and tool constraints).
📊 GENE-26.5 Dexterity Axes
Manipulation decomposes into:
1️⃣ Spatial Precision
2️⃣ Temporal Composition
3️⃣ Contact Richness
4️⃣ Contact Coordination
5️⃣ Tool-Mediated Interaction
These dimensions better capture dexterity than task-level success alone.
🧩 DexBench (RLWRLD NVIDIA Isaac Lab Arena)
18 atomic task families across 5 domains:
Special Picking(4), In-Hand Reorientation(4), Bimanual Regrasp(7), Precision Insertion(5), Hand Fastening(5), Constrained-Axis Manipulation(5), Interface Actuation(4), Force-Regulated Wiping(2), Flowable Material Control(4), Fabric Handling(2), Cable Winding(1), Package Handling(5), Sorting/Binning(3), Bin Packing(2), Box Sealing(1), Precision Arrangement(3), Tool Use(4), Moving Object Interaction(2).
Examples:
🔧 Window-regulator assembly requires simultaneous multi-point 6D alignment across articulated linkages with failure modes including forced insertion, reversed seating, component deformation, and jig damage.
💧 Pouring benchmark: 1.5L kettle → 300ml mark. Human judges assess fill level and spillage, revealing reproducibility limits.
⚠️ Current benchmarks still rely on non-standardized kits and human evaluation.
🔄 Toward Fully Automated Evaluation
• AutoEval (Berkeley/NVIDIA): 24/7 autonomous evaluation cells, policy queues, PaliGemma-based success classifiers, ~0.99 correlation with human labels.
• FurnitureBench: standardized long-horizon furniture assembly.
• LIBERO: 130 language-conditioned lifelong-learning tasks.
• RoboCasa: large-scale household simulation with leaderboards and distributed evaluators.
✅ Recommended benchmark recipe:
• Cheap standardized physical kits (3D-printable/off-the-shelf)
• Timed throughput metrics
• Human norm curves
• Zero human evaluation
• Autonomous success detection, recovery logging, duration histograms, and multi-axis scoring
📈 Critical Measurement Gaps
Success rates should be supplemented with:
• Spatial/temporal/contact-axis scores
• Recovery efficiency
• Perturbation robustness
• Throughput under distribution shift
• Tactile & force profiles
• Sim2real gap quantification
Evaluation models themselves can overfit to task-specific visual cues, necessitating axis-aligned dexterity metrics independent of benchmark idiosyncrasies.
🤲 Embodiment Gap = Primary Bottleneck
Human demonstrations are collected with 5-finger embodiments; ~20% of tasks (e.g., phone manipulation) become infeasible with 3-finger systems. Contact-rich manipulation likely requires dense tactile arrays (~15×15–20×20).
Human-video pretraining remains difficult because robot kinematics, sensing, compliance, and dynamics differ substantially from humans. Human-like impedance/muscle-style actuation and matched sensing reduce this transfer gap.
🧠 PhysBrain
Egocentric2Embodiment extracts structured physical commonsense from egocentric human video, producing E2E-3M (3M VQA samples) with temporal consistency and evidence grounding.
Focus:
• State-change reasoning
• Object interaction modeling
• Long-horizon planning
Results:
• >20% planning gains versus other 7B-scale models.
• Strong transfer through PhysGR00T/PhysPI on SimplerEnv, LIBERO, RoboCasa, ERQA, and PhysBench.
This provides dense human-derived physical priors to complement sparse robot trajectories.
🌍 World Models & Post-Training
Oasis 3 (Decart) introduces API-accessible, promptable, multi-view, closed-loop, geometry-aware, action-conditioned world models for Physical AI.
Key insight:
Post-training quality is fundamentally limited by rollout quality. Effective RL requires pretrained VLAs/world models capable of producing diverse but semantically meaningful trajectories. Pretraining and post-training must scale together.
Long-term planning likely requires moving beyond pixel/video decoding toward abstract latent dynamics that support shortcut discovery, recovery strategies, and novel tool invention.
🧮 Planning Stack
ReAct PDDL enables verifiable symbolic planning over continuous control. Force-aware vision, muscle-like actuation, and latent action alignment (LARA) improve contact-rich and tool-mediated behaviors.
🚀 Hardware Co-Design
Origami Robotics’ 22-DoF quasi-direct-drive anthropomorphic hands with 1:1:1 mapping between glove, hand kinematics, contacts, and sensing directly attack the embodiment gap. Such systems make PhysBrain-style priors, human-video transfer, and reproducible dexterity benchmarks substantially more practical.
🎯 Scalable robotic dexterity requires the convergence of multi-axis evaluation, autonomous benchmarking, tactile-rich embodiment, physical commonsense pretraining, world-model rollouts, and human-aligned hardware-data co-design.





2
5
854
Inma Vicente Molina retweeted

Try new Solventum™ Filtek™ Easy Match Flowable Restorative featuring:
A flowable for all direct restorations, occlusal surfaces, veneers, and all procedures including injection moulding. #FEMFlow
Request your clinical sample. ms.spr.ly/6016vic5q

ALT Sample the new injectable flowable composite- Solventum\u2122 Filtek\u2122 Easy Match Flowable Restorative
1
1
3

Jun 13
It's interesting that they used terps to keep it flowable. I usually used 5-8% depending on the distillate. Any more can be harsh on the throat.
1
1
26

Jun 13
UltraScape flowpoint is a rapid-setting flowable grout designed for fast application and early trafficking – open to foot traffic in just 1 hour.
Perfect for projects where time matters but quality can’t be compromised.
🔎 instarmac.co.uk/products/ult…
#UltraScape #Flowpoint

1
6

Flowable fill is not quite concrete, but a water and soil mixture that feels like rock if hit. Once hardened, it adds protection and stability for the waterline.
Construction on the 42-inch secondary raw waterline continues. It is fully installed at Lake Pflugerville and only
1
45
Below is a summary of other project updates from the presentation. Please note, all timelines are subject to change.
To help protect the system from future damage, crews have installed flowable fill around portions of both raw waterlines, as seen in the photo of this post.
1
36

OMNNICHROMA has 2 flowable composites- OMNICHROMA Flow and OMNICHROMA Flow BULK. Where do you prefer to use each of them and why?
youtube.com/watch?v=UfaJHvEi…
1
9

The flowability is depending on alkali content of the lava. Rich alkali gives flowable lava, but poor alkali pyroclastic lava flow. The latter one is more dangerous, because high temperature lava cluster diffuses to air.
1
60

Jun 10
Restorative Workflow: Solventum™ Filtek™ Easy Match Flowable Restorative and 3M™ Filtek™ Easy Match Universal Restorative in Combination with 3M™ Scotchbond Universal Plus Adhesive and Solventum™ Filtek™ Composite Warmer
#Scotchbond #Filtek
ms.spr.ly/6014vgwmm

5
Meet Solventum™ Filtek™ Easy Match Flowable ✨ Intuitive shading, adaptive opacity & excellent polish. One flowable for all direct restorations.
Order now: redirme.com/ctjbr5
Join our free webinar with Dr. Marcin Krupinski 👉 go.solventum.com/2ju4dG
#Solventum #Solver
15
Inma Vicente Molina retweeted
Simplify your direct restorations drawer with new Solventum™ Filtek™ Easy Match Flowable Restorative:
-Covers all direct restorations, occlusal surfaces, veneers, and all procedures including injection moulding. #FEMFlow
Request your clinical sample. ms.spr.ly/6013v5v83
1
2
35

Jun 8
UltraScape flowpoint is a rapid-setting flowable grout designed for fast application and early trafficking – open to foot traffic in just 1 hour.
Perfect for projects where time matters but quality can’t be compromised.
🔎 instarmac.co.uk/products/ult…
#UltraScape #Flowpoint

10

✨ Die Flowable Injection Technique korrigiert kleine Zahnlücken, ungleichmäßige 🦷 Zahnformen oder feine Kanten ohne Abschleifen, kostengünstiger als Keramik-Veneers. 👉 Jetzt im KU64-Blog lesen: zurl.co/w22Qo
#KU64 #FlowableInjection #CompositeVeneers #ZahnarztBerlin
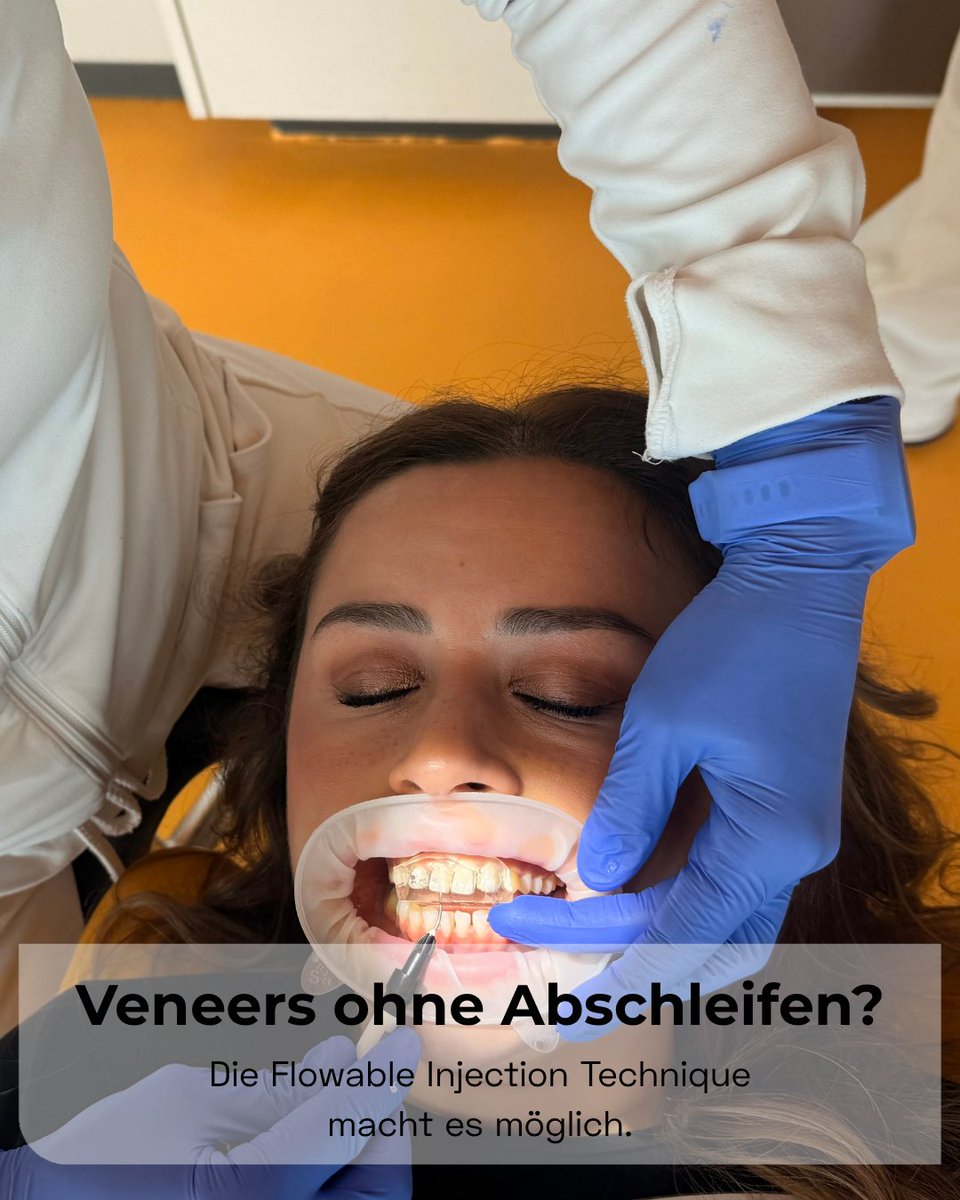
12

The Solventum™ Filtek™ Easy Match Flowable Restorative simplifies shade matching with 3 shades: Bright, Natural or Warm. Match by intuition or light cure a small button to confirm. Effective across many indications.
Contact Solventum to find out more.
Sponsored by @solventum
22

Jun 8
Innovation in der Zahnästhetik: KU64 stellt substanzschonende Flowable Injection Technique vor presseportal.de/pm/181398/62… #ots #gesundheit #news
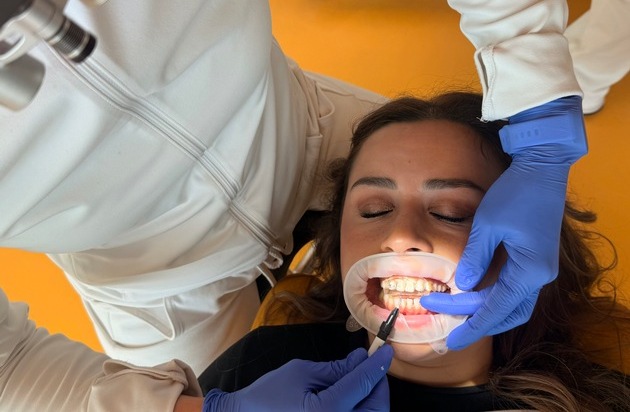
1

Innovation in der Zahnästhetik: KU64 stellt substanzschonende Flowable Injection Technique vor presseportal.de/pm/181398/62… #ots #fashion #news

3