


3 Jun 2025
Fine-tuning is dead, right?
Wrong. This research shows it still beats prompting by 10%.
If we’re asking if fine-tuning is still worth it for better LLM outputs, the clear answer this paper shows is 𝗬𝗘𝗦 - especially for structured outputs and domain-specific tasks.
Paper: arxiv.org/abs/2505.24189v1
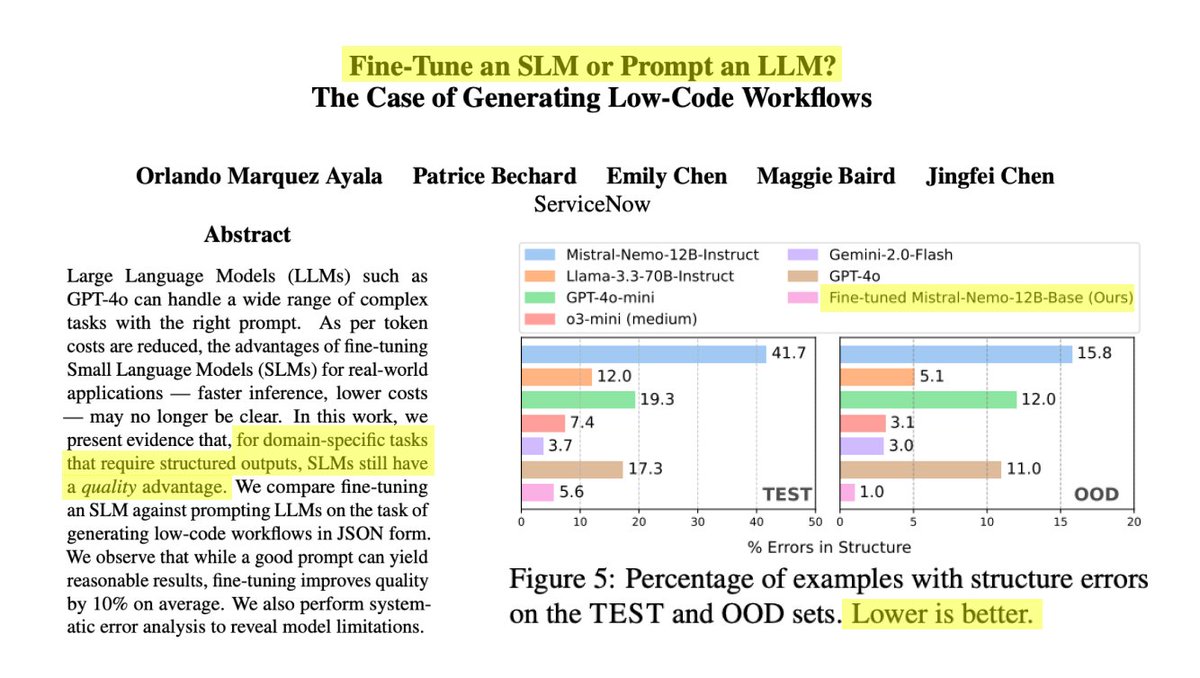
The researchers compared fine-tuning Small Language Models (SLMs) against prompting Large Language Models (LLMs) for generating low-code workflows in JSON format. The results? Fine-tuning improved quality by 𝟭𝟬% 𝗼𝗻 𝗮𝘃𝗲𝗿𝗮𝗴𝗲.
Here's why this matters:
1️⃣ 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 𝗼𝘂𝘁𝗽𝘂𝘁𝘀 𝗯𝗲𝗻𝗲𝗳𝗶𝘁 𝗺𝗼𝗿𝗲 𝗳𝗿𝗼𝗺 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴
While general tasks like summarization work well with prompting, domain-specific tasks requiring standardized outputs still see significant gains from fine-tuning.
2️⃣ 𝗘𝘃𝗲𝗻 𝗮𝘀 𝘁𝗼𝗸𝗲𝗻 𝗰𝗼𝘀𝘁𝘀 𝗱𝗲𝗰𝗿𝗲𝗮𝘀𝗲, 𝗾𝘂𝗮𝗹𝗶𝘁𝘆 𝗴𝗮𝗽𝘀 𝗿𝗲𝗺𝗮𝗶𝗻
The advantages of fine-tuning SLMs (faster inference, lower costs) might seem less important as LLM costs drop, but the quality advantage persists.
3️⃣ 𝗥𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗲𝗻𝘁𝗲𝗿𝗽𝗿𝗶𝘀𝗲 𝗮𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀 𝘀𝗵𝗼𝘄 𝘁𝗵𝗲 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲
The researchers built "Flow Generation," an application that translates text requirements into low-code workflows, and showed that fine-tuning was necessary to achieve the desired quality in the results.
4️⃣ 𝗘𝗿𝗿𝗼𝗿 𝗮𝗻𝗮𝗹𝘆𝘀𝗶𝘀 𝗿𝗲𝘃𝗲𝗮𝗹𝗲𝗱 𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰 𝘀𝘁𝗿𝗲𝗻𝗴𝘁𝗵𝘀
The fine-tuned SLM significantly outperformed LLMs on enterprise-specific features, with a FlowSim score 12.16% higher than GPT-4o in certain areas.
There’s a growing assumption that simply prompting the latest LLMs is always the best approach. But this paper shows that for applications requiring consistent, structured outputs, fine-tuning is still better.
The key takeaway? 𝗖𝗵𝗼𝗼𝘀𝗲 𝘆𝗼𝘂𝗿 𝗮𝗽𝗽𝗿𝗼𝗮𝗰𝗵 𝗯𝗮𝘀𝗲𝗱 𝗼𝗻 𝘆𝗼𝘂𝗿 𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰 𝗻𝗲𝗲𝗱𝘀. If you need standardized, structured outputs in a domain-specific context, fine-tuning may still be your best bet... for now.
2
2
17
965

28 May 2025
📊 We benchmarked top VLMs (GPT-4o, Claude, Gemini) vs. open-weight models (Qwen, LLaMA, Pixtral).
📈 Finetuned open models outperform proprietary ones:
Qwen2.5-VL-7B → FlowSim: 0.614
GPT-4o → FlowSim: 0.786
𝐐𝐰𝐞𝐧𝟐.𝟓-𝐕𝐋-𝟕𝐁 (𝐟𝐢𝐧𝐞𝐭𝐮𝐧𝐞𝐝) → 𝐅𝐥𝐨𝐰𝐒𝐢𝐦: 𝟎.𝟗𝟓𝟕

1
2
149

16 Jan 2025
all the secrets of aerodynamics are locked behind a professional license of solidworks flowsim
1
23
2,170


7 May 2024
🧪👩💻Today in #ISMRM2024, #Singapore, research from @VHIO shines!
Anna Voronova, PhD student under the guidance of @fragrussu, presented FlowSim, a simulator that enables the estimation of #microvascular properties in #cancer, opening the door for new biomarkers in tumours (#0586)

1
4
409

7 May 2024
Great presentation at #ismrm 2024 in Singapore by @VHIO @radiomicsVHIO 's Anna Voronova -- her new FlowSim simulator enables the estimation of #microvascular properties in #cancer, and may enable the computation of new biomarkers in tumours. Well done Anna!!

2
8
643

7 May 2024
A simulator of diffusion MRI signals arising from micro-vasculature perfusion?? Anna Voronova will explain everything with the poster "FlowSim: A Blood Flow Simulator For Histology-Informed Diffusion MRI Micro-Vasculature Mapping In Cancer", at Validation & Simulation, 14.30.
1
1
5
251

2 Feb 2024
Matlab and Simulink for control sims, Solidworks Flowsim for CFD - lots of validation runs were also done by kind folks with access to Ansys Fluent so I have an idea of how close my numbers are to a more industry-standard CFD program.
1
9
358
11 Dec 2023
Each sim is between 300,000 and 600,000 cells with at least 40k directly contacting solids. Solidworks FlowSim doesn't have tons of options for localized mesh density but so far with a little patience the results are alright.
2
249

28 Dec 2021
Houdini FlowSim Fashion
Frontpiece for a dress.
#3Dprinting #fashion #exploration #houdini #sidefx #analog #fabrication
2
3
32

5 May 2019
I am now waiting every sunday evening for the WE flowsim results :). It is like GoT but without the sex, the deads, the politics, etc.. but with nice CGI and better lightings ;p
1

23 Oct 2018
Tool Tip FlowSim - Now you can calculate the fluid flow only for a sector instead of the entire model & significantly reduce the analysis time. Use 'Axial Periodicity' feature available starting SOLIDWORKS Flow Simulation 2018 onward ^OA #SOLIDWORKS #FlowSimulation
2
2




11 Jan 2017
With great power comes great responsibility. With great experience come great products #CAESAR #SmartEOR #FlowSim bit.ly/2ihvi2r
1
3
3 Aug 2016
Come by booth 6207 at #ATCE2016 to check exciting new features in our software #CAESAR #SmartEOR #FlowSim #Galaxy4D #Transients #PetroTrak
1
1