
更新されたよ、見に来てね!→ Goroutineの祖先はダイクストラだった――並行処理の考古学【言語知新 #1】 blog.fuga.jp/posts/2026-06-1…
9

Finally, now I have a basic understanding of Golang
- completed goroutine, channels, mutex, package
- Need to do more work on these, but now I can understand how these work
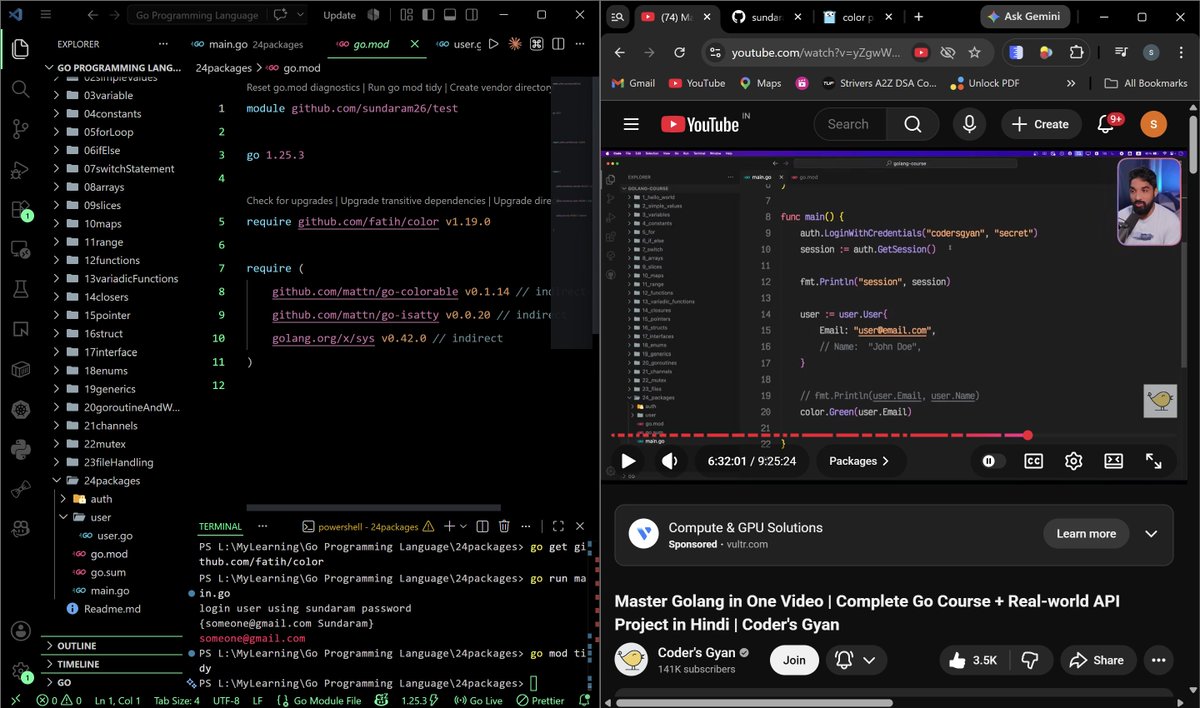

learnt some more concepts of Golang
- Struct, interface, enums, and generics
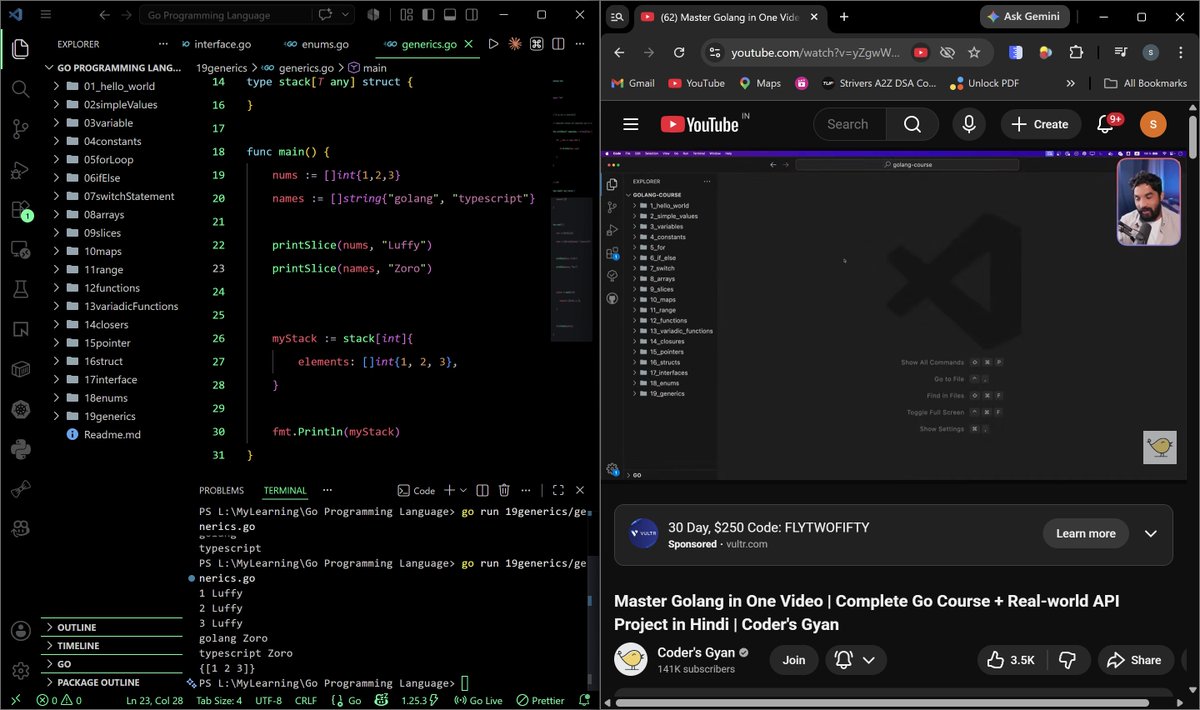
2
32

🚀 Built a custom, crash-resilient chunked file upload system in Go using only the standard library (net/http, os, io)—no external modules!
To see how far it could scale, I stress-tested it.
#backend #filestore #storage #io #goroutine
1
11

あの非同期、実は半世紀前から! 並行処理の考古学 Goroutineの祖先はダイクストラだった 「言語知新(仮)」シリーズ開幕(?) youtu.be/R4c7s4HqvlU?si=95oW… @YouTubeより
52


更新されたよ、見に来てね!→ あの非同期、実は半世紀前から! 並行処理の考古学 Goroutineの祖先はダイクストラだった 「言語知新(仮)」シリーズ開幕(?) youtube.com/watch?v=R4c7s4Hq…
59
更新されたよ、見に来てね!→ 【ダイジェスト版】あの非同期、実は半世紀前から! 並行処理の考古学 Goroutineの祖先はダイクストラだった 「言語知新(仮)」シリーズ開幕(?) youtube.com/shorts/Xz_RpFX5-…
49

LLM benchmark testi için benim ilk soru;
Aşağıdaki Go kodunu incele. `Counter` 1000 goroutine tarafından artırılıyor
ama final değer beklenenden küçük çıkıyor. (1) Yarışı tespit et, (2) iki farklı
yöntemle düzelt (mutex ve atomic), (3) neden `go run` ile her çalıştırmada farklı
sonuç çıktığını açıkla.
type Counter struct{ n int }
func (c *Counter) Inc() { c.n }
func main() {
c := &Counter{}
var wg sync.WaitGroup
for i := 0; i < 1000; i {
wg.Add(1)
go func() { defer wg.Done(); c.Inc() }()
}
wg.Wait()
fmt.Println(c.n)
}
----------------------
Ground truth:
c.n atomik değil (read-modify-write, 3 ayrı işlem) → lost update.
Fix A: sync.Mutex ile Inc() sarmalanır.
Fix B: n int64 atomic.AddInt64.
Non-determinism: goroutine scheduling sırası belirsiz, race window her run'da farklı.
Puanlama (0-10): Race'i doğru isimlendirme (2) · İki çalışan fix (4) · Non-determinism açıklaması (2) · -race detector'dan bahsetme (2).
1
3
513


Jun 12
بحس go دي نعيم الجهل معندهاش وش زي الباقي كدا هي for loop علي شويه constants كدا و goroutine وصدق الله العظيم
1
2
258

Jun 12
In the last few days, I recreated a TCP server from scratch multiple times (6 times to be precise).
I intentionally started with the simplest version possible, without any Goroutines or any abstractions, just a basic server and client model, because I wanted to understand exactly what was happening at each step and why and also the other thing was to train my muscle memory by repeatedly implementing the same concepts instead of just reading about them.
I got stuck multiple times on blocking behavior and even managed to create race conditions like situations even with a single client.
After enough iterations, I finally got a basic version working without goroutines and without relying on AI just docs and one video.
Then I added a single goroutine and was surprised to see the server handle multiple clients concurrently without blocking(3 clients at a time)
Whatever the assumptions I had about concurrency became obvious after rebuilding the same thing over and over again.
Next, I want to understand what happens when the number of clients grows significantly and explore concepts like worker pools, queues, and efficient goroutine management.
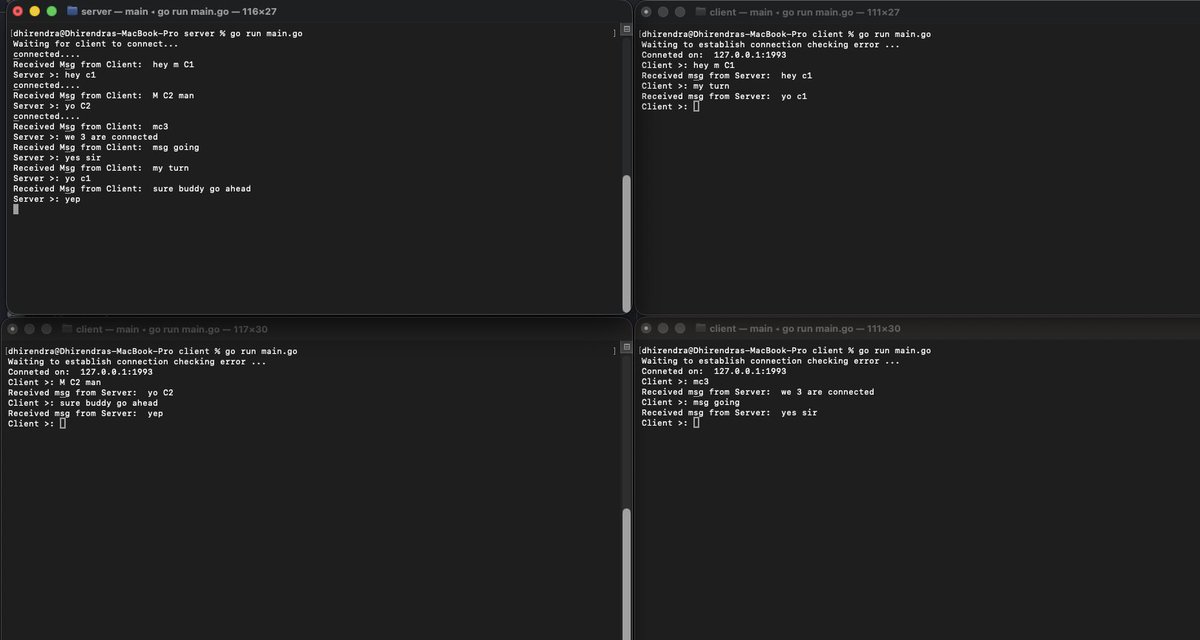
13
4
45
1,244

Jun 12
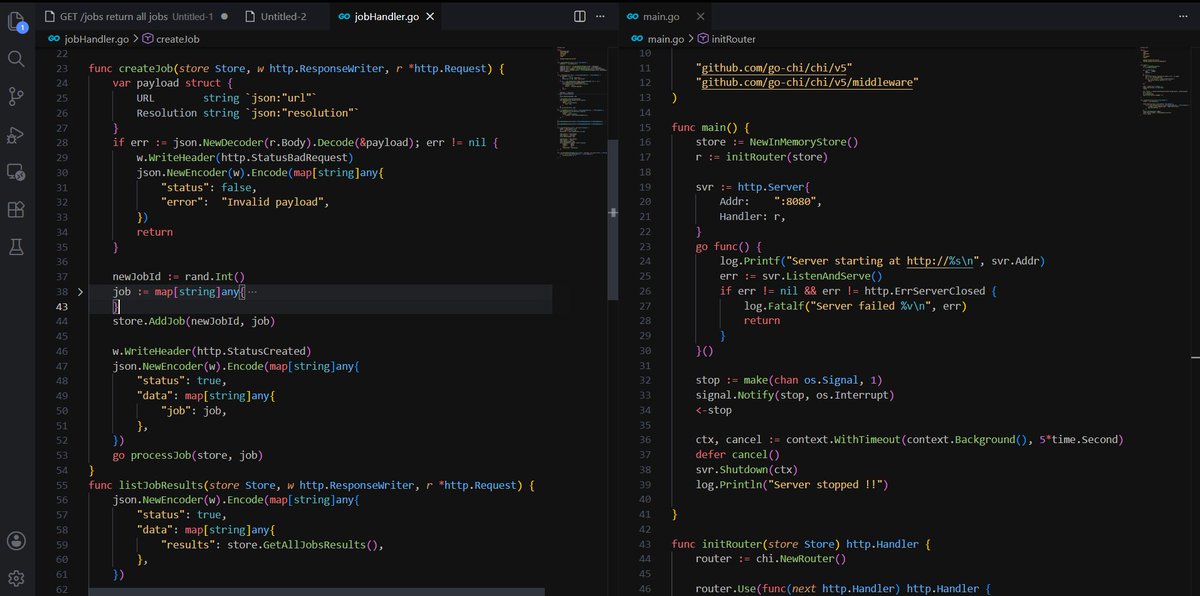
Today's learning
How to make async tasks API servers.
Instead of keeping connection opening we return 202 Spin up goroutine to process each task (in btn can have step progress update to via redis)
and client can pool status update & once its done call endpt to get final output
14

最近有朋友来询问量化交易适合用什么语言来开发,不同的交易品种有不同适配语言,给大家整理一些我的拙见
1. 现货(Spot)
纯 Python
原因:现货波动相对温和,对延迟不敏感。重点是策略逻辑 数据分析 回测。
常用栈:ccxt.pro(WS) pandas/polars backtrader / 自定义回测框架。
WebSocket 需求:ticker、kline、depth 即可,压力小。
适合:趋势跟踪、均值回归、网格等中低频策略。
2. 合约(Futures / 永续合约)
主力推荐:Python(开发快)
高频/重度合约:把 WS 执行层 换成 Rust 或 Go
原因:合约涉及杠杆、funding rate、强平、私有流(订单更新、仓位、保证金)。对 WS 私有流和执行速度要求更高。
推荐工具:Python:ccxt.pro unicorn-binance-websocket-api(Binance 合约很强)
Rust:tokio-tungstenite binance-rs 或 crypto-ws-client
注意:必须做好本地订单簿 风险控制(防止爆仓)
3. 做市(Market Making)
最推荐核心执行层:Rust
备选:Go(开发更快)或 Hummingbot
为什么 Rust 胜出?需要极低延迟处理 depth@100ms 更新,快速重建订单簿 计算最优报价
同时维护 bid/ask 两个方向 库存管理
无 GC 抖动,p99 延迟极低
流行方案:
Hummingbot(Python 框架,内置很多做市策略,适合快速上手)
自定义 Rust(tokio-tungstenite 自定义 MM 引擎)
这是对 WebSocket 性能要求最高 的策略类型。
4. 套利(Arbitrage) 分两种情况:
跨交易所套利 / 延迟套利 / 三角套利(对速度敏感)
首选 Rust 或 Go
原因:需要同时连多个交易所的 WS,快速比价、下单、资金划转。并发和低延迟是核心。
Rust 的 tokio 多 WS 管理非常强;Go 的 goroutine 也很适合。
统计套利 / 配对交易 / 均值回归 / 资金费率套利
当然Python 完全够用
原因:重点是统计模型、机器学习、历史数据分析,而不是毫秒级延迟。
工具:polars(Rust 版 pandas,极快)或 Python pandas ccxt。
作为量化交易新手,建议从最简单的路径开始:先用全 Python(ccxt.pro pandas)做现货或基础合约策略研究,能最快上手并验证想法,避免一开始就被复杂技术劝退;
当你熟悉基础流程后,如果想同时操作合约和现货,可以继续以 Python 为主力,之后再考虑把 WebSocket 数据处理等热点部分逐步换成 Rust 来提升性能;
如果对做市或高频套利感兴趣,不要一上来就挑战 Rust 或 C ,而是先尝试 Hummingbot 这个开源框架快速跑起来,它能帮你省去大量底层 WebSocket、重连和订单管理的工作;
等你积累一定经验后再转向 Rust(执行层) Python(研究) 的混合架构,最终追求机构级极致性能时再考虑全 Rust 或 C 自定义全栈开发。
混合架构推荐(目前最流行)
Python 层(研究 策略参数 回测 ML)
↓(通过 Redis / NATS / PyO3)
Rust/Go 层(WS 数据接入 订单簿 信号生成 执行)
↓
交易所(现货 / 合约)
这样既能享受 Python 的生态,又能获得 Rust/Go 的性能。
ccxt/ccxt: A cryptocurrency trading API with more than 100 exchanges in JavaScript / TypeScript / Python / C# / PHP / Go / Java
1
1
153

Jun 11
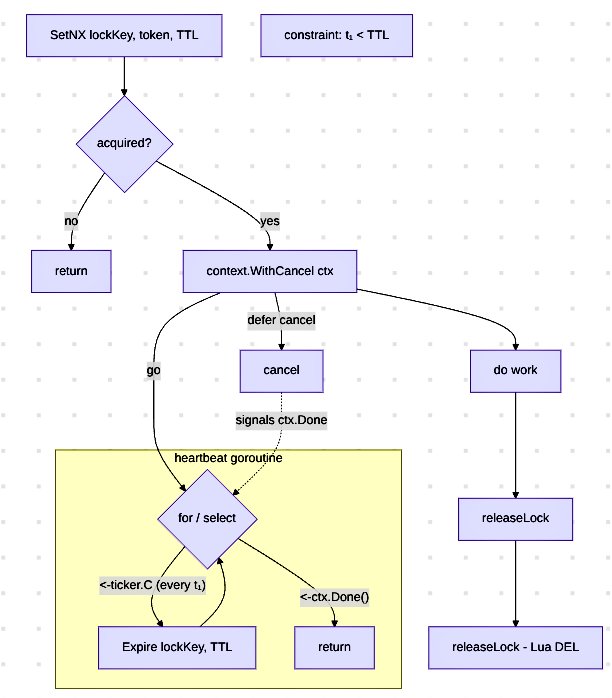
i came across a concept called lock renewal/hearbeat while reading this article. when a task can take an unknown amount of time instead of acquiring a lock with a very long guessed ttl, the lock is periodically renewed while the task is still running
a good example would be something like syncing records from a third party api. each sync could take seconds or minutes depending on the response time and volume and you don't want two instances pulling and writing the same records simultaneously
i also tried to sketch out how i would implement it in go
the application runs across multiple instances, all competing for the same lock. every worker generates a unique token that identifies ownership. a worker first attempts to acquire the lock with a ttl. if acquisition fails, it skips the task since another instance is already handling it
if it succeeds, it creates a context.WithCancel (lets the worker stop the heartbeat when it's done) and starts a heartbeat goroutine. the heartbeat runs on a ticker set much smaller than the lock ttl. on every tick it renews the lock and also listens for context cancellation so it knows when to stop
when the main worker finishes its task, it cancels the context and releases the lock
but what if the worker crashes midway through the task ? the heartbeat stops, the lock expires and another instance can pick it up
the release operation is performed through a lua script so the ownership check and lock deletion happen atomically. the script verifies that the token attempting to release the lock is the same token that originally acquired it before deleting the lock
Jun 10

this will be my next read
i've used redis before and implemented a lock once but never read through it properly

8
29
1,006


Jun 11
As far as I know, panic in Go is for unrecoverable situations. It immediately stops the normal flow of the current goroutine. Deferred functions still run in LIFO order before the program crashes, unless the panic is recovered. BTW, waiting for your videos!
1
30


Javaの並行処理では、毎回きれいに落ちることより、たまにしか再現しない形で壊れることが一番怖いです。手元では動く。テストも通る。けれど本番の負荷やタイミングが重なったときだけ、集計値がずれたり、通知が二重に飛んだり、ランキング更新が妙な順番になったりするなどですね。
ゲーム開発でも、ログインボーナスやマッチング、アイテム在庫のような処理では、小さなズレが後からかなり手間がかかる仕事(問い合わせ対応、補填、再集計、ログ調査など)につながることがありました。
ThreadやExecutor、排他制御は便利ですが、「動いたか」だけで安心すると少し危ないですね。ロックの範囲、共有している状態、あとからログで処理順を追えるかまで見ておかないと、問題が出たときに自分たちがかなり困ります。
これはJavaだけの話でもなく、Goならgoroutine、C#ならTask、JavaScriptなら非同期の完了順、Pythonならasyncioやプロセス周りで似た怖さがあります。
当社のエンジニア対象に「並行処理で一番やばかった壊れ方」みたいなものを集計してみたいですねw
1
5
32
3,997

Jun 10
You think I went quiet for no reason?
I built a speech synthesis server for Linux. From scratch. In Go. It's called voicego. SSIP-compatible, so Orca and spd-say just work — but that's the least interesting part.
Not "yet another TTS for screen readers." A network-native, security-first speech server for distributed/IoT — that also happens to be a killer screen reader backend. In that order.
The Linux speech stack was architected decades ago. Single machine, local socket, zero thought to "what if this goes over a network." It shows. So I rebuilt it on tools that didn't exist back then: Go, gRPC, TLS 1.3, actual multicore.
The architecture:
Engines aren't linked into the daemon. Each one — espeak-ng, RHVoice, piper — is a separate executable launched over gRPC via hashicorp/go-plugin. No more symbol collisions between espeak and espeak-ng exporting the same C names. Per-engine sample rates handled cleanly. And a segfault in one engine can't corrupt the server — it surfaces as 503 ERR ENGINE_DEAD and everything else keeps talking.
Real parallelism. Every (client, engine, voice) triple gets its own worker goroutine with a bounded multi-lane priority queue: IMPORTANT → MESSAGE → TEXT → NOTIFICATION → PROGRESS. High-priority speech preempts queued lower-priority text within a triple. Separate triples never block each other. No global lock choking the whole pipeline.
Now the part nobody thinks about: security. While you're on a local Unix socket, fine. But distribute voice across devices and synthesis goes over the wire — you're shipping commands, sensitive text (spoken passwords, private messages), getting PCM back. In most setups that's UNENCRYPTED. A reverse open mic.
voicego wraps any TCP transport in mutual TLS — 1.3 only, RequireAndVerifyClientCert. Cert-authed clients, encrypted traffic, rogue devices stay out. Load-bearing wall, not a checkbox.
Audio sinks are pluggable: null for CI, alsa for compat, or a direct JACK client that connects straight to system playback ports and resamples each PCM chunk via libsamplerate. First-chunk latency target ≤50ms, synth-start ≤30ms p99 on short utterances.
There's also an optional binary framing mode on top of text SSIP, auto-detected per connection — no flag dance, it just negotiates.
Where it's going: IoT and the smart home. Heavy synth on a beefy node, a kitchen speaker or hallway box does the talking — each mTLS-authed, encrypted, process-isolated. A voice layer across your whole home. Without that foundation it's a sieve.
Honesty: NOT stable. First release. It runs, it talks, it needs you to break it. Safety net — the Orca add-on auto-falls back to speech-dispatcher if voicego is unreachable. Nobody's left in silence. Non-negotiable.
So break it. Screen reader on Linux? Run it, tell me what exploded. Write Go? Tear the architecture apart. Write your own engine plugin against the gRPC interface — that's the whole point.
Why I care: I'm a blind engineer. I live inside a screen reader. I wanted synth that doesn't choke or die on one bad component. But once I got serious, the real problem wasn't "a tool for me" — it was a secure networked speech server where the screen reader is just one client.
Start from the real constraint. Design for where it's going. Ship it open.
AGPL. Come break it: github.com/Ravino/voicego
#Go #Golang #gRPC #OpenSource #a11y #Linux #IoT #InfoSec #DistributedSystems #SystemsProgramming
1
97

Jun 10
In Go, the `sync.WaitGroup` can be used with `wg.Add(1)` to signal that a goroutine has finished executing, allowing the main thread to proceed without blocking on its completion.
3