
Learning update 🚀
• Built MongoDB analytics endpoint ($graphLookup, $facet)
• Added change streams for daily snapshots ⚡
• Optimized queries (indexing explain stats)
• Built dashboard (Cursor AI Figma MCP)
• Gave AI mock interview
• Read The Power of Subconscious Mind
2
3
121

Apr 7
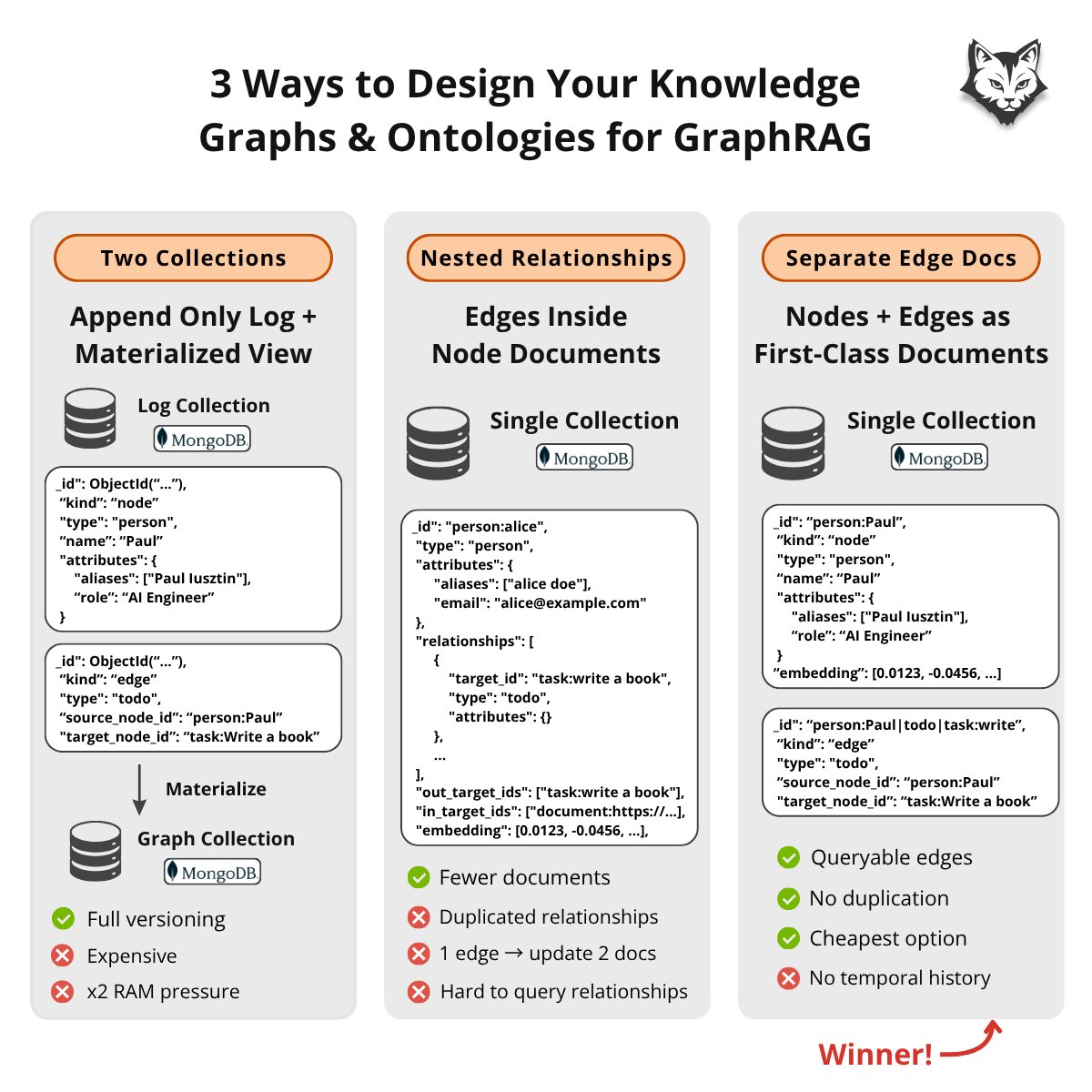
There are 3 ways to model your ontologies for GraphRAG:
(And your decision can make or break your system)
So I assessed the tradeoffs while designing the ontology data model for an OpenClaw-style assistant on @MongoDB
Here’s what I found:
1/ Append-only log materialized view (evolving ontology)
Two collections:
Log: {log_id, type: "Person", name: "Paul", attr: {"role": "founder"}}
Graph: aggregated node per entity/edge
Pros:
• Full ontology versioning over time
• Replayability and auditability of extracted knowledge
• Flexible snapshots (2023 vs 2025) for analytics
Cons:
• Duplicate data indexes
• Vector text indexes competing for RAM (~2–4x)
• Costly aggregation cycles
Powerful… but expensive to scale.
2/ One collection (ontology embedded in nodes)
Edges inside nodes (LangChain’s default @MongoDB GraphRAG).
Example: {_id: "person:Paul", out: [{to: "task:write", type: "TODO"}]}
Pros:
• Fewer documents
• Simple ontology data model mapping
Cons:
• Duplicated relationships
• 1 edge update → 2 docs
• Fragile writes, hard rollbacks
• Hard to query relationships directly
Works on a small scale…
But breaks as your ontology grows.
3/ One collection (ontology as nodes edges)
Edges become first-class docs:
Node: {_id: "person:Paul"}
Edge: {source: "person:Paul", type: "TODO", target: "task:write"}
Pros:
• Explicit, enforceable ontology
• Edges are queryable updatable
• No duplication
• Simpler writes recovery
• Native $graphLookup support
• Works natively with $graphLookup
Cons:
•No temporal history
Most practical for production GraphRAG.
@MongoDB makes implementing ontology-driven knowledge graphs in a single system straightforward:
• $graphLookup → graph traversal in one query (no JOIN recursion hell)
• Built-in vector text search alongside graph queries
• Easy horizontal scaling via sharding (AWS/GCP, multi-region)
Takeaway:
GraphRAG looks like a retrieval problem.
It’s an ontology data modeling problem first.
Because your schema defines:
• Performance
• Cost (especially RAM)
• Reliability
• Retrieval quality
P.S. What data model are you using (or would you use) for your Knowledge Graph?
1
6
171
Mar 20
LangChain gave me a knowledge graph in 10 minutes.
But I couldn't use it in production. Here's why...
I started with LangChain’s MongoDBGraphStore.
A few minutes later, I had a working knowledge graph stored in @MongoDB
@MongoDB acts as the unified memory layer for my assistant because it supports:
• Text search
• Vector search (Voyage embeddings reranking)
• Graph traversal using $graphLookup
At first glance, everything looked fine.
Then I inspected the data model.
From just 5 documents, the LLM produced:
• 17 node types
• 34 relationship types
Including variations like:
• part_of
• Part Of
• part of
3 relationship types for the same concept.
This was just one of many inconsistencies.
It also didn’t support embeddings or vector indexes.
And relationships were stored as arrays in entity documents.
Which meant:
• Detecting duplicate edges was nearly impossible
• Updating relationships required rewriting the entity
• Tracing each chunk’s source document wasn’t possible due to limited metadata
• Versioning evolving entities wasn’t possible
The problem was the data model.
Most GraphRAG tutorials jump straight to:
• Entity extraction
• Embeddings
• Retrieval pipelines
…but skip the ontology.
Without an ontology, LLM extraction is unconstrained.
Models invent new entities, relationships, and naming across documents.
So instead, I designed the ontology first.
This system uses 6 node types and 8 edge types with strict constraints.
Example: PERSON → TASK uses the TODO edge.
If the model outputs: PERSON → TASK with EXPERIENCED
…it gets rejected.
Because EXPERIENCED must be: PERSON → EPISODE.
Once the ontology exists, extraction becomes predictable.
Two strategies handle it:
1/ LLM extraction
Entities:
• Person
• Task
• Episode
• Preference
Relationships:
• TODO
• EXPERIENCED
• RELATED_TO
2/ Deterministic extraction
Structural nodes and edges:
• Document
• Chunk
Relationships:
• MENTIONS
• PART_OF
• NEXT
These come directly from the ingestion pipeline.
The storage layer becomes:
• documents → raw content
• knowledge_graph_log → immutable observations
• knowledge_graph → materialized graph built with @MongoDB aggregation
This enables:
• Scalable duplicate detection and normalization
• Ontology-based extraction (so costs don’t explode)
• Metadata control for retrieval
• Unified graph vector search
Embeddings are computed after materialization, so vectors represent the full entity.
Without control over the data model, GraphRAG breaks down quickly.
Out-of-the-box extractors look impressive in demos…
…but they produce noisy graphs and systems that cannot run in production.
LangChain is great for prototypes.
But production GraphRAG usually requires building ingestion and retrieval pipelines.
Takeaway:
GraphRAG looks like a retrieval problem.
But most of the time, it’s a data modeling problem.
P.S. Do you treat GraphRAG as a retrieval problem or a data modeling problem?
2
1
2
133
Mar 3
Palantir built a $400B empire on ontology-first AI systems long before LLMs.
And yet today, most GraphRAG tutorials skip the ontology entirely.
There’s a massive problem with how GraphRAG is being taught.
Most tutorials jump straight to:
• Embeddings
• Vector search
• Extracting entities and relationships
• Fancy retrieval pipelines
But they skip the most important step…
The data model.
If you let an LLM “extract entities and relationships” freely, it will:
• Invent new entity types per document
• Create vague edge types
• Duplicate the same entity under slightly different names
At 10 documents, it looks fine.
At 100, it’s messy.
At 1,000 , it’s unusable.
Better prompting won't fix this... You need an ontology.
Hot take: Ontologies are what make GraphRAG scalable.
This is how we modeled GraphRAG for our Digital Twin / Second Brain style personal assistant using @MongoDB as the memory layer.
Before writing a single extraction prompt, we defined:
• 6 node types
• 8 edge types
Small enough to stay consistent.
Specific enough to be useful.
The ontology became a contract.
The LLM can only extract what we define.
The query layer knows exactly what to expect.
Without an ontology, the LLM extracts hundreds or thousands of triples per document.
With an ontology, you extract only what matters to your business problem.
This means:
• Fewer triples
• Higher-quality triples (signal > noise)
• Only storing data you care about
• Faster and cheaper ingestion
Once the task is tightly scoped, you can use cheaper APIs like Gemini Flash Lite or even fine-tuned small language models scoped to your ontology.
Ontology smaller models = economically scalable GraphRAG.
But not everything goes through the LLM...
LLM-powered extraction:
• Person
• Task
• Episode
• Preference
Metadata-driven:
• Document
• Chunk
You already know titles, URIs, authors, ordering, references.
Don’t pay an LLM to rediscover metadata.
That reduces cost, latency, hallucination surface, and lets you use cheaper models safely.
From there, the storage pattern is straightforward (especially in @MongoDB):
Raw documents land in one collection.
Extracted observations are logged immutably.
A materialized graph view is rebuilt via aggregation.
Because the schema is strict, the query becomes predictable:
1. Text search
2. $vectorSearch
3. Reciprocal Rank Fusion (RRF)
4. $graphLookup with bounded expansion
The data model enables the query.
tl;dr:
GraphRAG is a schema design problem.
Yes, LLMs are powerful.
But without an ontology, they generate structured noise.
Design the ontology first.
Everything else follows.
P.S. Did you define your ontology before writing extraction code or after your graph started breaking?
2
5
224
Feb 24
Here’s the ingestion architecture we used to build a Digital Twin agent:
(Steal it to build your own)
Most teams obsess over vector search and graph traversal.
Very few design the memory pipeline correctly.
These are the steps that matter...
1–2/ Raw Data → Data Warehouse
All sources land in one raw_documents collection in @MongoDB (Atlas or self-hosted).
Emails keep headers.
Notion keeps metadata.
PDFs stay semi-structured.
Each document stores:
• source_type
• source_uri
• timestamps
• raw content
This is your durable ingestion layer.
3/ Clean Chunk
Strip HTML. Extract headers. Normalize. Chunk.
Email: “Arthur, attached is the GraphRAG survey. Coffee Friday?”
Extract:
• from: Felix
• to: Arthur
• date
• cleaned body
Update in place with atomic $set.
4/ Extract Graph Triples
Structured following our ontology (LLM):
(Arthur) → CONNECTED_TO → (Felix)
(Arthur) → HAS → (Task: Coffee Friday)
Semi-structured using metadata:
(email_doc) → CONNECTED_TO → (graphrag_paper)
The ontology constrains node edge types.
This prevents graph drift.
5/ Entity Resolution
Merge “Arthur” with existing “Arthur Iusztin”.
Match on:
• full_name
• aliases
• fuzzy search
Memory quality > memory quantity.
6/ Embeddings
Generate vectors for:
• Document chunks
• Tasks / Preferences chunks
Store them directly on each node.
7/ Knowledge Graph Objects
Each node becomes a document in kg_nodes:
• Properties
• Edges array
• Vector field
That’s your graph.
8/ Immutable Memory
All state changes are appended to a separate kg_events collection in @MongoDB.
Never overwrite.
Append events such as:
• NodeCreated
• RelationshipAdded
• PreferenceUpdated
June → “Prefers Java”
September → “Prefers Python”
Both stored.
This ensures versioning.
Latest state built via:
$sort → $group → $last
If extraction was wrong, invalidate the event.
9/ Hybrid Retrieval
At query time:
1. $vectorSearch finds entry points
2. $graphLookup expands 1–3 hops
3. Text search catches exact matches
Single aggregation pipeline.
Bounded traversal.
10/ Query-Time Knowledge Graph
The graph is a projection built from immutable logs.
Traversal depth is explicit (maxDepth: 3).
tl;dr: GraphRAG needs controlled expansion.
11–12/ Agent Layer
Expose two tools:
Write Memory → append events
Search Memory → hybrid retrieval
The agent reads and writes to the same memory layer.
That’s Agentic GraphRAG.
The core idea:
GraphRAG is a memory architecture problem.
If ingestion is structured, retrieval becomes predictable.
For this architecture, we use @MongoDB (Atlas or self-hosted) as a unified memory layer.
Documents, vectors, traversal, and event logs live in the same system.
P.S. Where does your RAG/GraphRAG ingestion pipeline break first?
1
1
2
204

Jan 10
"MongoDB にはグラフ構造を扱うための $graphLookup というクエリがあります"←そーなんだ。 developers.cyberagent.co.jp/…
11
1,115

27 Dec 2025
JSモノリスからTSマイクロサービス移行を振返り。DDDで理想状態を設計しドメイン理解を深化、Redis依存を見直しキャッシュ削減、$graphLookupでツリー取得を最適化しP95レイテンシ1/4に改善した知見を共有 / 大規模サービスのマイクロサービス移行を SRE 視点で振り返ってみる
developers.cyberagent.co.jp/…
3
118

30 May 2025
It's Connect By or With Recursive in SQL databases, or $graphLookup in MongoDB - a new use case for the indexing tutorial
dev.to/mongodb/graphlookup-c…
5
24
1,569

20 May 2023
Unlock new possibilities for your #MongoDB applications by mastering $graphLookup operator.
Here is how:

1
1
2
165
16 May 2023
Take your #MongoDB queries a notch higher. Check out the $graphLookup operator! The aggregation pipeline stage enables you to perform complex graph traversals, calculate node distance, and more. Make your queries simpler and unlock new possibilities. #advancedqueries

1
2
83

9 Sep 2022
Alguém já teve problema em usar o $graphLookup e o $lookup no com mongoose e Node.js?
Estou apanhando para puxar documentos pais e filhos de uma mesma coleção
cc: @sseraphini
1
1

7 Mar 2022
Today I found someone telling me we can do DFS and BFS things in @MongoDB ....!
Sweet shocks I get after assuming the whole industry is gone to shit 😂😂
P.S we both are trying to complete my Neural Network using #MongoDB now..!❤️
$graphLookup aggregations ❤️
6

3 Mar 2022
#100DaysOfCode D-12 $graphLookup was the Chapter I ended on today in MongoDBU. I also failed the linkedIn JS quiz, only by a question so, I'm rusty/that's ok. It's tough getting back into this but I am enjoying being back to it. Join me here mongodb.com/community/forums… learn2 grow
2

27 Dec 2021
➡️ "Attention si tu utilise du NoSQL tu ne pourras plus faire de jointure".
Ah bon ? 🤔
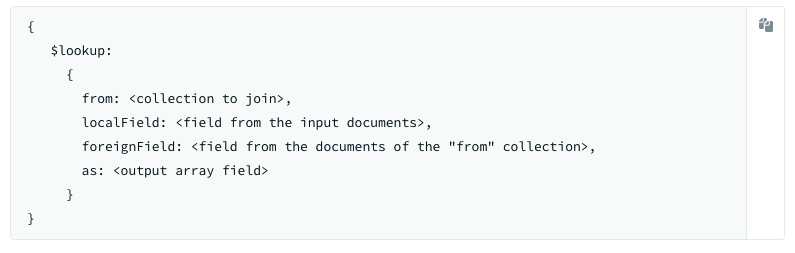
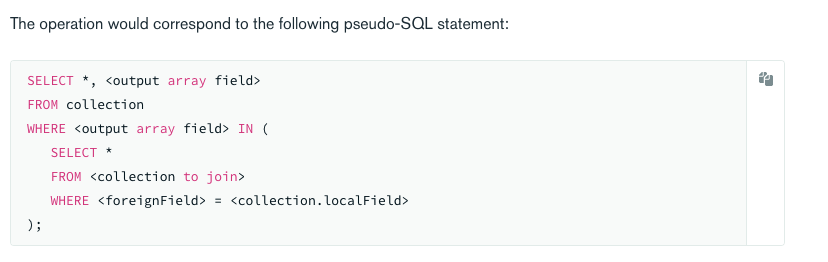
Bien sûr que c'est possible, avec MongoDB il suffit d'utiliser le stage $lookup ( ou $graphLookup si plus spécifique ). Et c'est plus lisible qu'en SQL, je trouve. 👌
2
1
3

With MongoDB 5.1, Aggregation Pipeline stages $lookup and $graphLookup can now work against sharded clusters, allowing users to combine and traverse related data across shards. 📈✨
Learn more ↓ bit.ly/301ZsT8
2
17



29 Apr 2021
// 子階層取り出し
query = [
{
$match: { title: "CTO" }
},
{
$graphLookup: {
from: "parent_reference",
startWith: "$_id",
connectFromField: "_id",
connectToField: "reports_to",
as: "member"
}
},
{
$unwind: "$member"
}
]
1
1

29 Jan 2021
Learned today the graphLookup stage in MongoDB, I think so far it's the one that I'm having the most issues with 🤷🏻♀️... How much time did it take you to get familiar with $graphLookup?
#100DaysOfCode
2


23 Jul 2020
Pro tip:
If you having n^2 or more time complexity. Look for optimization via database.
Aggregate queries, graphLookup and more.
1