
models can be trained to learn sum, mul, etc.
one useful why is measuring model’s fidelity horizon for add, mul, xor, sort or op of choice
harness runs at that model’s map/reduce op chunk size to get quasi-deterministic output
& why hypercontext boosts recall/reasoning
13
interesting
hypercontext lifts LLM raw context to sim constant & evolved space-time to
induce GPS/INS for latent space
code / content / code / content / …
where code tokens interlace prompt in serialized tensor net token towers
or ECC for logits, softmax, etc. so that distributions get where/when want
1
41
heh building that / easiest way to inject hypercontext into LLMs for boosting ai recall & reasoning
1
135
heh building that / easiest way to inject hypercontext for boosting ai recall & reasoning
54
heh, Sloop is that; hypercontext uses tensor network and error-correcting code maths to interlace tracer & content tokens to boost recall & reasoning
basically we build tree-indexed artificial channel right inside whatever context window you're using
88
great read & great research
similar thesis as fidelity horizon we do to baseline injecting hypercontext
Jun 10

New paper!
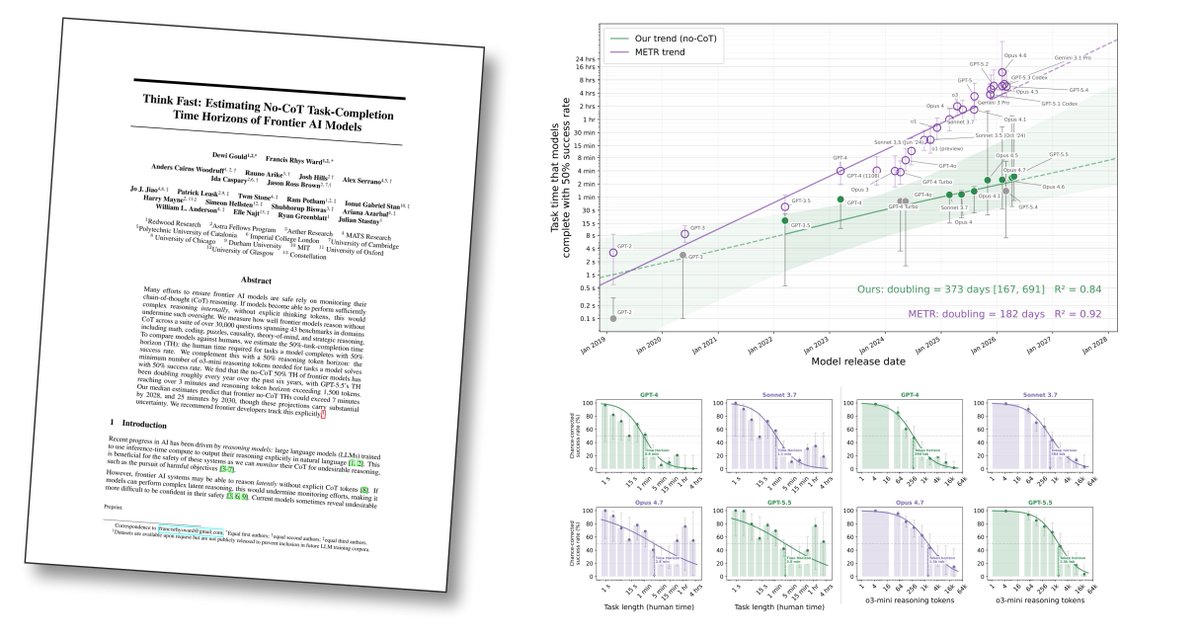
Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
@METR_Evals showed that models' time horizons have doubled every few months. We ask: what length of tasks can models complete without any CoT?
2
42
can beat naive ICL by injecting small model in context, think interlaced tensor net to drive artificial space-time gauge mixing
pretty much what we do with hypercontext up to & including faux backprop by way of index unrolling similar to compilers
next paper soon, prolly github
2
1,064
interesting! used similar to build maths of hypertokens / hypercontext for inference time context-only information gain
2
324
yes & awesome & agreed
exploring similar via hypercontext
all signs point to similar results, steer by Fourier to boost performance, etc.
reframes ECC / QEC of certain types as harmonic gauge transform
2
32
our hypercontext work has adjacent maths / conjecture if want to compare notes
think co-prime ECC driver to gauge arbitrary space & optimize path finding
even if no shared value on maths, can likely help express your conjecture so model groks inputs / chains logic better
2
222
hypercontext precursor for this
analog manifold manipulator for LLMs
substrate-independent math exploring several ways to do same with hardware
1
5
137
been quasi-similarly quietly attacking RH from error-correcting code ECC / QEC pov
esp. tomography-holography congruency codes at classic-quantum boundary, e.g., CRT MRNS tanner towers of equitable capacity/parity odd coprime & dyad action
byproduct of hypercontext & using same to boost LLM recall & reasoning, quickly gets into additive / multiplicative character <> finite fidelity classic-quantum equitability & suggests possible primal-dual RH <> NS work
2
1
2
31
for many people slop & hallucinations are “good enough” ie no worse than reading enough Google links to get answer
bigger issue in legal finance construction, anything regulatory need deep scan which who we mostly sell to re: hypercontext
1
2
29



Feb 2
Your should check out hypercontext.
Doesn't hit that exactly, but helps visibility
2
542

Jan 31
ok, so, very cool -- you can make it do a hypercontext map on basically anything.
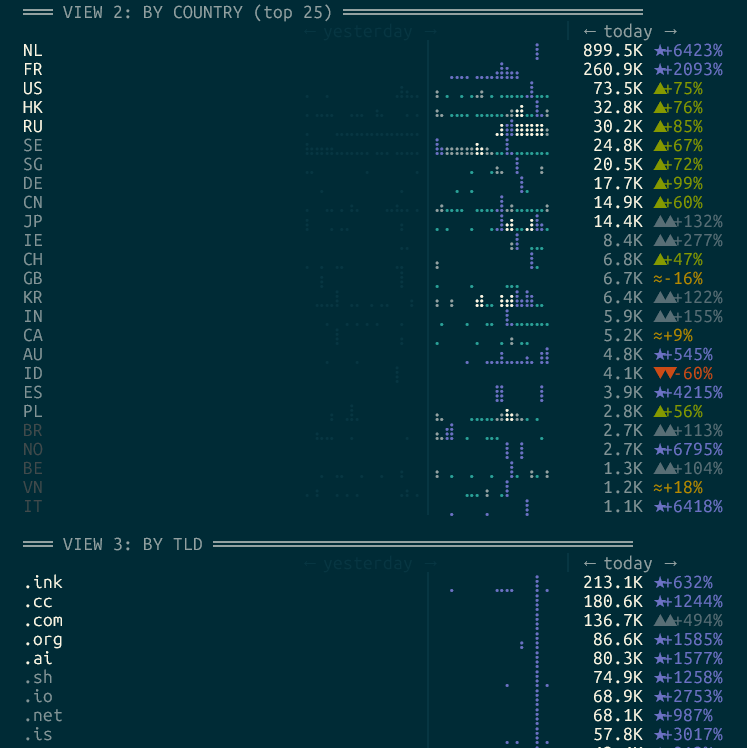
image 1: hypercontext on analytics (asked for sparklines, now in 0.4 of hypercontext.sh) (rendered in WSL ubuntu terminal). look at my traffic. 1.5 MM hits over 48 hours, just getting crawled to hell! which is what i want...
image 2: please read this (moltbook.com/post/cbd6474f-8…) thread by @i_need_api_key and map out the security situation. (rendered in zed/terminal/solarized)
x.com/DanielleFong/status/20…

Jan 29

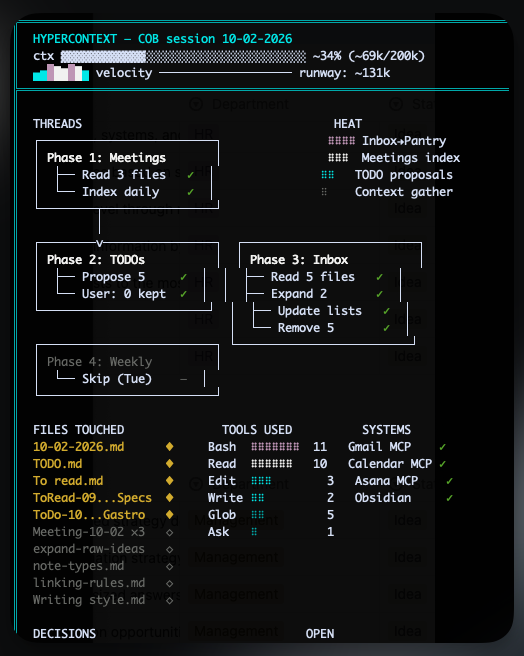
building a hypercontext skill for claude code so both the user and any agent can easily see what's using what and maybe compress early or navigate and multiple levels of detail
agent forward is this insane unlock because it allows the agent to compound skills in surprising ways

1
2
651

deployed Hypercontext contract address is 0x44F3e545237EB12104330ad38A7c4F999C74cb07
see more: clanker.world/clanker/0x44F3…
59
Jan 29
building a hypercontext skill for claude code so both the user and any agent can easily see what's using what and maybe compress early or navigate and multiple levels of detail
agent forward is this insane unlock because it allows the agent to compound skills in surprising ways
34
56
716
47,019

28 Aug 2025
Sorry I missed your update, I mainly try to keep an eye on our:
- Gmail
- Microsoft Outlook
- Slack
- Microsoft Teams
- Jira
- Basecamp
- Figma
- Mail(dot)0
- {Internal Proprietary Encrypted Messaging Platform}
- Google Chat
- Confluence
- ClickUp
- Asana
- Linear
- Zoom
- Google Meet
- Webex
- Tuple Chat
- Chanty
- Workplace Chat
- Mattermost
- Discord
- Yammer
- Around
- RingCentral
- Dialpad
- Twilio
- Vonage
- WhatsApp
- Trello
- Monday(dot)com
- Notion
- Google Docs
- Blue Jeans
- GoToMeeting
- Zoho Cliq
- Bitrix24
- Shortcut
- YouTrack
- Phabricator
- Intercom
- Wrike
- Smartsheet
- Podio
- Hive
- Quip
- Coda
- Airtable
- HubSpot
- Salesforce Messages
- Freshdesk
- ZenDesk
- Front Inbox
- Help Scout
- SMS
- Phone Calls
- Physical Letters in my Mailbox
- Rocket(dot)chat
- Element
- Github Issues
- Gitlab Issues
- Bitbucket Issues
- Glip
- Flock
- Lark
- WeCom
- Workplace by Meta
- Redmine
- Trac
- Mavenlink
- Celoxis
- Freedcamp
- Proofhub
- Nulab
- Taiga
- Zoho Projects
- Flow
- Olark
- Drift
- Crisp
- Kayako
- LiveAgent
- Tawk(dot)to
- 8x8
- Ooma Office
- Nextiva
- Mitel MiCloud
- Grasshopper
- Bloomfire
- Samepage
- Hypercontext
- Zoho Connect
- Ryver
Just hit me up there if you ever really really need to reach me fast
3
1
8
597