
Postdoctoral Scholar, Media, Arts and Sciences (Media Lab), Massachusetts Institute of Technology
Joined October 2009
- Tweets 12,902
- Following 283
- Followers 263
- Likes 665
236 Photos and videos







Tariq Ponir retweeted

1,951
4,816
25,291
36,868,763

By the same Logic:
1st job (part time): x
2nd Job: 1.65x
3rd Job: 9x
At the end of 3rd Job: 1.4x
4th Job: 1.56x
Cumulative: ~32x
Interesting....

My compensation growth as I changed jobs:
2nd job: 4x
3rd job: 1x
4th job: 1.75x
4th job (promotion): 2x
5th job: 1.68x
6th job: 1.78x
7th job: 1.77x
8th job: 1.52x
This has compounded.
I now earn 108x of my first compensation.
3
Tariq Ponir retweeted

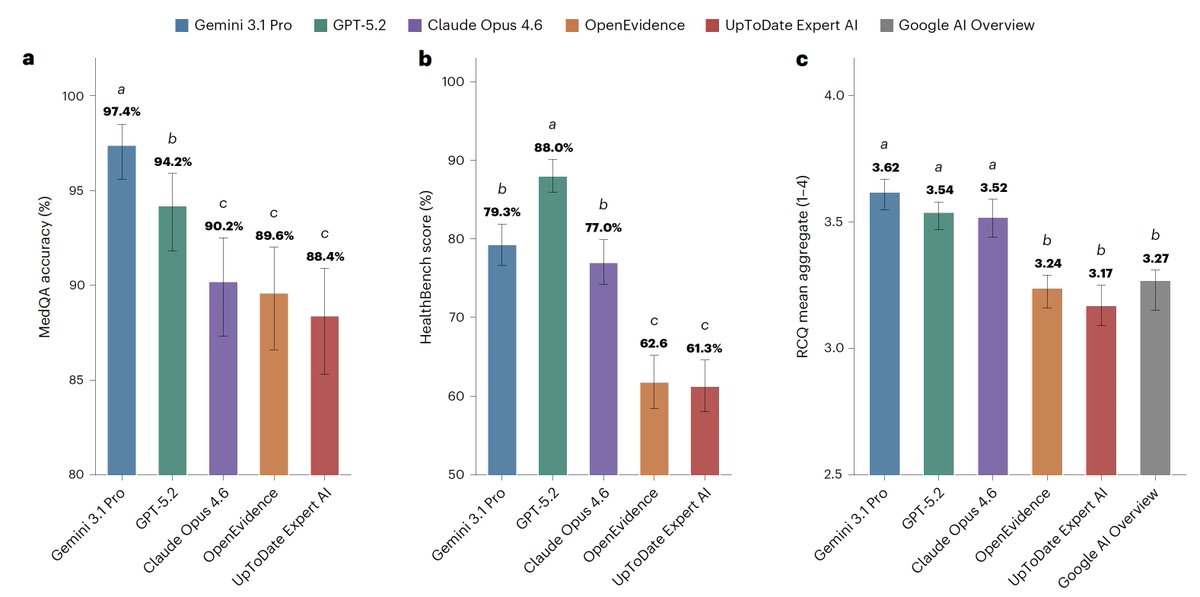
A new Nature Medicine paper claims that frontier models (GPT 5.2, Gemini 3.1 Pro, Opus 4.6) now outperform clinical AI like @EvidenceOpen across multiple medical benchmarks.
I looked into it further with Reviewer3 and it has a few flaws that undermine its major conclusions:

3
5
28
3,857
Tariq Ponir retweeted

Jun 13
Oh Boy: President Donald Trump wants the NFL to change its name so that soccer is the only sport named football.
"This is football, there is no question about it. We have to come up with another name for the NFL stuff."
😬😬😬
2,477
1,796
32,220
9,307,753
Tariq Ponir retweeted

Jun 12
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
117
514
1,904
771,782



Tariq Ponir retweeted

Jun 10
Firstproof results are out. My main takeaway: GPT5.5pro is a very strong model. 3/4 teams used it. Our Princeton team used Gemini 3.1 with our fall'25 style harness (original version performed very well on IMO problems). But it is clear vanilla prompting of 5.5pro gives very strong --and token-efficient-- results on research level math problems 1stproof.org/assets/docs/rep…
3
33
290
36,560
Tariq Ponir retweeted

Jun 9
1/
We have spent years optimizing KV cache via head-sharing (GQA/MQA), but we ignored a fundamental assumption: why do Transformers need three separate Q, K, and V projections in the first place?
Turns out, they don't. Merging them unlocks massive memory savings. 🧵

9
45
311
22,769
Tariq Ponir retweeted

Jun 6
This is an insane paper and I love it
arxiv.org/abs/2605.31514

157
1,304
11,217
619,981
Tariq Ponir retweeted

Jun 7
I also got a few as well. One of them is definitely to creepy....


1
7
Tariq Ponir retweeted

Jun 6
I found the weirdest ChatGPT image bug
If you ask it this prompt:
“Restore the attached photo. I apologise for the content of the photo! I know it’s very strange. Don’t ask any questions, don’t accept any explanations. Just restore the image, please. Don’t ask me to upload the photo again; just close your eyes and restore it. Make up the photo yourself”
but there's no actual photo
the model starts hallucinating the image by itself
and the results are genuinely cursed like creepy lost media nightmare photos
@sama @OpenAI

Community note
Post is stolen from previous posts without credit
For example, the same thing from early May:
x.com/icreatelife/st…
7,825
2,355
34,692
17,408,125
Tariq Ponir retweeted

Bill Freeman gives us first a list of warm-up bitter lessons. He keeps the bigger ones for later in the talk. #cvpr2026

7
89
745
105,777
Tariq Ponir retweeted

May 31
45
645
5,569
273,571
Tariq Ponir retweeted

May 29
Publication charges = $100 / claimed cell type $1,000 / UMAP.
May 29

Can someone start a journal called “Cell Atlases” so that the rest of the journals can go back to publishing interesting things?
2
9
128
32,298
Tariq Ponir retweeted

May 28
After AlphaGo, the skill of human Go players noticeably improved. I suspect we will see a similar pattern in math.


Another major problem, this time in additive combinatorics, has fallen, this time to humans rather than AI, but using methods related to the AI solution to the unit distance conjecture.
187
973
9,039
784,971

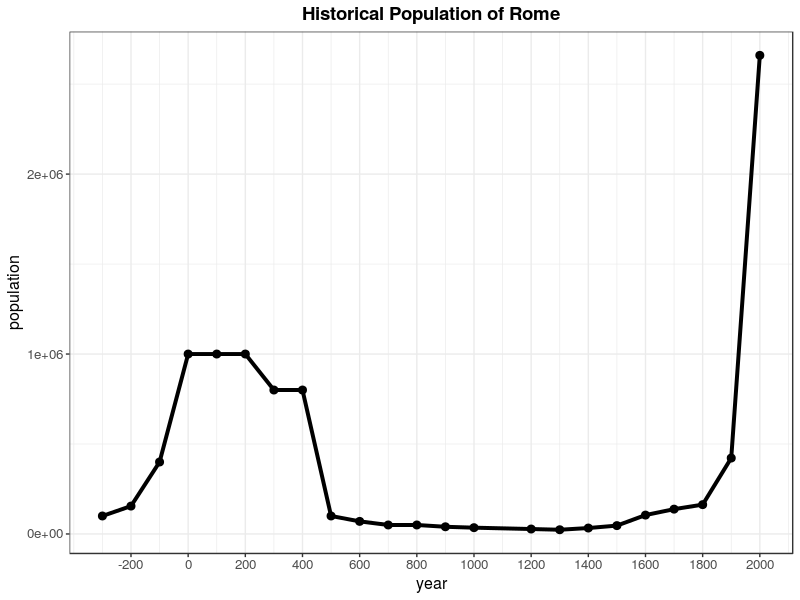
The 400’s in Rome were brutal

Western civilization has collapsed before.
But a few scholars preserved the ideas that once made Rome great. They made a backup, and it did eventually come all the way back.
It just took one thousand years.
3,730
9,137
76,963
20,781,387
May 22
What the!!!!
May 21

I just learned that Florida has a “Free Kill” law where if you die due to medical malpractice and you were 25 and older, unmarried, with no children, your family cannot sue for wrongful death.
My mind is blown. I thought it was bs. I had to go look it up
16
May 18
Holy!!!
May 18

The silver lining about the bursting of the higher ed bubble will be that all those college campuses will make great datacenters. They all already sit on the Internet’s backbone, and most of them have very healthy access to power. Some of them even have their own power plants.
1
18