
emibonnie and their ability to nonchalantly say things that is interpretable in different ways will always be comedic
EMIBONNIE MOONSHADOW BLOOM
#BBFanFest2026D2
46m

twitter.com/manbodemi_/statu…
EMIBONNIE DANDELION NIGHT
#BBFanFest2026D2
🧡: I actually feel the exact same way as you, Phi(Namtan).
🗣️: (Screaming)
NT: Feel the same as me? In what way...? Honestly, I have no idea, but since the fans are screaming, I'm just going to play along with the joke and pass it over to you.
🧡: I mean, I feel just as excited as you, but with less pressure! I feel like I’ve been here for days now. I’m starting to get used to the stage, the runway, and I'm walking with much more power. I’m not as cautious as yesterday, now my walks actually have some sound to them.
💜: Ah, how?
🧡: Like, I can walk down the stairs without being as scared as yesterday. Yesterday, I was still like, "Oh no, am I gonna fall?" But today, I feel way more ready. And whatever mistakes I made yesterday, I'm here to fix them all for everyone today!
11
63
1,608

Me parece que sí nadie se quiere mojar que los manden a todos para la casa y traigan a otros, están ahí para tomar decisiones, no para echar una cervezas viendo las pantallas... y que no me digan que eso es interpretable y que se puede entender que no hay intención... blablabla
7
Dongheon Lee retweeted

Interpretable enzyme function prediction via sparse autoencoder features of ESMC across the microbial protein universe
1. The paper proposes a “features-first” route to enzyme function prediction: instead of training a new deep model, it uses ESMC-6B’s sparse autoencoder (SAE) features as an interpretable semantic signature to predict EC numbers.
2. Key enabler: the ESMC SAE expands layer-60 hidden states into a 16,384-feature codebook with Top-K=64 sparsity, and each feature has an independently interpretable biological concept label (generated/annotated via multi-agent GPT-5), enabling mechanistic explanations alongside predictions.
3. Benchmark setup: 4,868 reviewed microbial SwissProt enzymes (Bacteria Archaea), balanced across 7 EC1 superclasses and spanning 161 EC3 subclasses; proteins are 80–700 aa and have ≥3 EC levels. Protein representations are mean-pooled SAE activations, evaluated with simple linear probes.
4. Main EC3 result (161-way classification, 80/20 split): SAE binary features (just the top-64 active concepts per protein) reach 78.9% top-1 and 88.5% top-5 accuracy, outperforming a 3-mer logistic regression baseline (57.3% top-1) and approaching BLASTp (80.5% top-1).
5. Using richer SAE information improves further: the combined binary activation weights representation reaches 85.6% top-1 and 90.5% top-5, exceeding BLASTp top-1 by 6.4% in this benchmark.
6. Practical advantage over homology transfer: BLASTp returns no hit for 12.6% of test proteins, while SAE features yield predictions for 100% of queries; for the BLASTp no-hit subset, SAE binary still achieves 62.1% top-5 accuracy.
7. “Dark-matter regime” analysis: test proteins are binned by maximum 3-mer Jaccard similarity to training data; in the lowest-similarity bin (<0.20, containing 61% of the test set), SAE top-5 accuracy is 0.656 vs 0.438 for the 3-mer baseline, showing robustness when sequence similarity is minimal.
8. Generalization to unseen enzyme classes: leave-one-EC3-class-out evaluation (60 populous EC3 subclasses held out) trains only an EC1 classifier and tests whether it recovers the correct EC1 superclass for a completely unseen EC3 class; SAE binary achieves 47.7% EC1 recovery (3.3× random; vs 26.6% for sequence features).
9. Interpretability check: the most discriminative SAE features align with known enzymology—e.g., hydrolases linked to α/β-hydrolase catalytic triad/nucleophilic elbow geometry; oxidoreductases to Rossmann NAD(P)H-binding motifs; transferases to P-loop/Walker A phosphate-binding patterns; translocases to multi-helix transmembrane bundle concepts—supporting mechanistic plausibility of the learned “concept” features.
10. Atlas-scale survey: scanning 7.7M ESM Atlas cluster representatives, the authors identify 169,859 “dark enzyme-like” candidates (uncharacterized clusters with enzyme-suggestive Pfam keywords) spanning major microbial phyla, positioning SAE-based signatures as a scalable prioritization tool for experimental enzyme discovery.
💻Code: github.com/YueHuLab/esmc-sae…
📜Paper: arxiv.org/abs/2606.12209
#ProteinLanguageModels #EnzymeDiscovery #ECNumber #Interpretability #SparseAutoencoders #Microbiome #Metagenomics #ComputationalBiology #ESMC #ESMAtlas

6
34
2,287
Dimitra Maoutsa retweeted

Jun 12
New paper: We learn an interpretable phase portrait of physical dynamics directly from movies of a system.
arxiv.org/abs/2604.24662
Led by Michael Martini, Eslam Abdelaleem, and @PaarthGulati . We do this by a new method we call Dynamical Symmetric Information Bottleneck (DySIB), which compresses pasts and futures of a data stream into a latent space, maximizing the mutual information between the past and the future latents, and preserving the physical structure of the problem (time-translation invariance and differential, small changes between nearby time points).
One will see similarities between DySIB and JEPA-like approaches to world models. Yet, our goal is not world models, but learning and interpreting the underlying physics from data. For this, we argue that physics of the system must be learned in the latent space (e.g., Newton's 2nd law predicts dynamics of latent variables, motion of the center of mass, but not of the ambient data, images of the object on a CCD camera). The Information Bottleneck framing allows us to explicitly control the quality of the representation vs its complexity, so that we can generate a family of models with different complexity and prediction quality. That said, we deemphasize prediction metrics as a measure of success: in physics, understanding and prediction are related, but are not the same (Ptolemaic epicycles predicted well, but were a poor model of physics). Instead, for this work, we focus on interpretability -- and I am particularly proud that DySIB extracted an obviously correct phase portrait of a simple physical system we worked on, which can be interpreted by anyone with an introductory physics course under their belt.
1
15
88
6,870

AI Research Intern – Lexsi Labs
Commitment: Full-time internship (6 months; potential extension or full-time offer)
Start Date: Rolling
About Lexsi Labs
Lexsi Labs is one of the leading frontier labs focusing on building aligned, interpretable and safe Superintelligence. Most of the work involves on creating new methodologies for efficient alignment, interpretability lead-strategies and tabular foundational model research. Our mission is to create AI tools that empower researchers, engineers, and organizations to unlock AI's full potential while maintaining transparency and safety.
Our team thrives on a shared passion for cutting-edge innovation, collaboration, and a relentless drive for excellence. At Lexsi.ai, everyone contributes hands-on to our mission in a flat organizational structure that values curiosity, initiative, and exceptional performance.
As a research intern at Lexsi.ai, you will be uniquely positioned in our team to work on very large-scale industry problems and push forward the frontiers of AI technologies. You will become a part of the unique atmosphere where startup culture meets research innovation, with key outcomes of speed and reliability.
What You’ll Do
We work on multiple frontier research ideas and challenges. If you are selected, you would be working on one of these following areas. Collaborate closely with our research and engineering teams on one of the areas:
Library Development: Architect and enhance open-source Python tooling for alignment, explainability, model alginment, uncertainty quantification, robustness, and machine unlearning
Explainability & Trust: Improve and find new observations using our and other SOTA XAI techniques (DLB, LRP, SHAP, Grad-CAM, Backtrace) across text, image, and tabular modalities to understand and present new model interpretability.
Mechanistic Interpretability: Probe internal model representations and circuits—using activation patching, feature visualization, and related methods—to diagnose failure modes and emergent behaviors.
Uncertainty & Risk: Develop, implement, and benchmark uncertainty estimation methods (Bayesian approaches, ensembles, test-time augmentation) alongside robustness metrics for foundation models.
Tabular Foundational Models (Orion): Work with our leading Tabular Foundational Model team to improve and launch new tabular foundational model architectures and work on our leading opesource library TabTune.
Reinforcement Learning: Explore new ideas and algorithm around RL and our new RL fine-tuning library.
Research Contributions: Author and maintain experiment code, run systematic studies, and co-author whitepapers or conference submissions.
General Required Qualifications
Strong Python expertise: writing clean, modular, and testable code.
Theoretical foundations: deep understanding of machine learning and deep learning principles with hands-on experience with PyTorch.
Transformer architectures & fundamentals: comprehensive knowledge of attention mechanisms, positional encodings, tokenization and training objectives in BERT, GPT, LLaMA, T5, MOE, Mamba, etc.
Version control & CI/CD: Git workflows, packaging, documentation, and collaborative development practices.
Collaborative mindset: excellent communication, peer code reviews, and agile teamwork.
Preferred Domain Expertise (Any one of these is good) :
Explainability: applied experience with XAI methods such as DLB, SHAP, LIME, IG, LRP, DL-Bactrace or Grad-CAM.
Mechanistic interpretability: familiarity with circuit analysis, activation patching, and feature visualization for neural network introspection.
Uncertainty estimation: hands-on with Bayesian techniques, ensembles, or test-time augmentation.
Quantization & pruning: applying model compression to optimize size, latency, and memory footprint.
LLM Alignment techniques: crafting and evaluating few-shot, zero-shot, and chain-of-thought prompts; experience with RLHF workflows, reward modeling, and human-in-the-loop fine-tuning.
Tabular Foundational Models: Should have used or improved TFMs like Orion, TabPFN, TabICL etc
Post-training adaptation & fine-tuning: practical work with full-model fine-tuning and parameter-efficient methods (LoRA, adapters), instruction tuning, knowledge distillation, and domain-specialization.
Additional Experience (Nice-to-Have)
Publications: contributions to CVPR, ICLR, ICML, KDD, WWW, WACV, NeurIPS, ACL, NAACL, EMNLP, IJCAI or equivalent research experience.
Open-source contributions: prior work on AI/ML libraries or tooling.
Domain exposure: risk-sensitive applications in finance, healthcare, or similar fields.
Performance optimization: familiarity with large-scale training infrastructures.
What We Offer
Real-world impact: address high-stakes AI challenges in regulated industries.
Compute resources: access to GPUs, cloud credits, and proprietary models.
Competitive stipend: with potential for full-time conversion.
Authorship opportunities: co-authorship on papers, technical reports, and conference submissions.
apply:app.screenloop.com/careers/a…
1
58
Chidambara .ML. retweeted

New multicenter 🇪🇸 study: interpretable #MachineLearning models improve survival prediction in extremely preterm infants and outperform CRIB I/II using only birth variables
Thanks to Paula Sol and Paula Petrone for leading this outstanding work. 👏
... sciencedirect.com/science/ar…

1
2
7
369

Zapatero hizo lo mismo que Aznar y González, eso de asesoría y similares, tan interpretable a nivel judicial como plazca.
20

An interpretable radiomics–machine learning model for early risk stratification of invasive ... - Nature nature.com/articles/s41598-0… #MachineLearning
5

No le ha salido muy allá y como lo ha dejado interpretable pues ahí estamos al acecho para la puñalada, esto es tuiter, despellejing zone, en mi caso tirando de humor mejor que de malicia.
1
1
10

Si molts no teniu ni idea de qui és català i qui no, tenim mala peça al teler. Illa, us agradi o no, és català. Illa no és castellà. La catalanitat no és un concurs de fidelitat a Catalunya, és una condició cientificament objectiva. No és quelcom interpretable
11
10
41
829
Belinda Li retweeted

Do you want to conduct interpretability research from first principles?
The Standard Interpretable Model is finally here:
A user-aware general theory of interpretable machine learning to deductively design interpretable methods
arxiv.org/abs/2606.12289

1
10
102
10,053
Keunwoo Choi retweeted
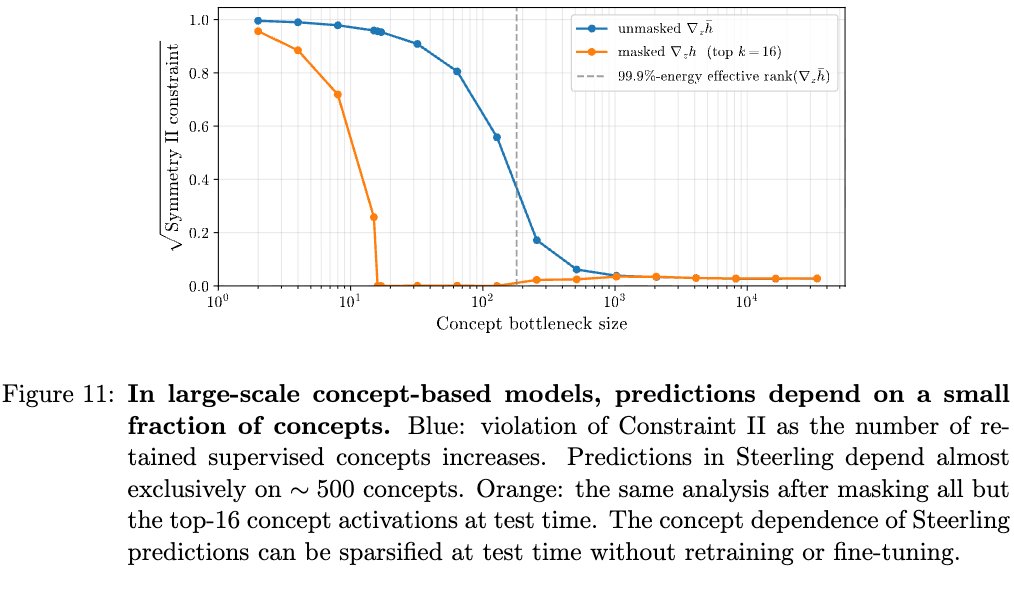
We validated the interpretability of Steerling8B, the first large scale interpretable model by @guidelabsai
We empirically measured how Steerling8B could satisfy the prediction-concept dependency symmetry by construction
2
1
4
1,220

The Standard Interpretable Model: A general theory of interpretable machine learning to deductively design interpretable methods using Lagrangian mechanics
Pietro Barbiero, Giovanni De Felice, Mateo Espinosa Zarlenga, …
arxiv.org/abs/2606.12289 [𝚌𝚜.𝙻𝙶 𝚌𝚜.𝙰𝙸 𝚌𝚜.𝙽𝙴]
4
166
Ajitesh Shukla retweeted

Doshi-Velez & Kim (Towards a rigorous science of interpretable ML) were doing definitional and 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 𝐫𝐢𝐠𝐨𝐫. Their paper has almost no math.
rather, it's a taxonomy (application-grounded, human-grounded, functionally-grounded evaluation) plus an argument that interpretability is not one thing and is fundamentally task- and human-dependent. It was a "stop being sloppy about what we're measuring" intervention. It tells you how to judge a method, not how to build one.
Standard Interpretable Model or SIM (Barbiero et al, 2026) is going for 𝐠𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐫𝐢𝐠𝐨𝐫. It's not just asking for cleaner evaluation, it's proposing a template that takes premises (e.g. user subjectivity) in and derives symmetries, constraints, losses, and architectures out.


Do you want to conduct interpretability research from first principles?
The Standard Interpretable Model is finally here:
A user-aware general theory of interpretable machine learning to deductively design interpretable methods
arxiv.org/abs/2606.12289
1
3
39
3,886