
Jun 11
🎛️🧠 How can control systems learn to make optimal decisions on their own—balancing theoretical guarantees with real-world performance in everything from microgrids to smart home energy management?
📘 𝙄𝙩𝙚𝙧𝙖𝙩𝙞𝙫𝙚 𝘼𝙙𝙖𝙥𝙩𝙞𝙫𝙚 𝘿𝙮𝙣𝙖𝙢𝙞𝙘 𝙋𝙧𝙤𝙜𝙧𝙖𝙢𝙢𝙞𝙣𝙜 𝙛𝙤𝙧 𝙎𝙚𝙡𝙛-𝙇𝙚𝙖𝙧𝙣𝙞𝙣𝙜 𝙊𝙥𝙩𝙞𝙢𝙖𝙡 𝘾𝙤𝙣𝙩𝙧𝙤𝙡 by Qinglai Wei, Ruizhuo Song, and Hongyang Li introduces iterative adaptive dynamic programming (IADP) theory from a control systems perspective—presenting both advanced theoretical analyses and the most recent practical applications.
Volume 2 of the Series on Deep Learning Neural Networks, this monograph highlights real-world demonstrations in residential energy systems, showing the strong performance of iterative ADP methods.
🔎 Why this book is essential reading:
📖 1. Principles of Adaptive Dynamic Programming
🧱 Foundational principles of adaptive dynamic programming
🎯 Self-learning optimal control under uncertainty
🔬 Setting the stage for iterative refinement
🔁 2. Discrete-Time Iterative Methods
📊 Discrete-time local value iterative ADP
✅ Admissibility and termination analysis
🔄 Discrete-time local policy iteration ADP
⏱️ 3. Continuous-Time and Game-Theoretic Extensions
🕒 Continuous-time time-varying policy iteration
♟️ ADP for discrete-time zero-sum games
🎮 Model-free optimal control for unknown nonlinear multi-player non-zero-sum games
🤝 4. Distributed and Fault-Tolerant Control
🌐 Continuous-time distributed policy iteration for multi-controller nonlinear systems
🛡️ Data-based fault-tolerant control via distributed policy iteration
🔗 Coordination across multi-controller architectures
🏠 5. Smart Energy and Real-World Applications
🔋 Dual iterative Q-learning for optimal battery management in residential environments
⚡ Mixed iterative ADP for optimal battery energy control in microgrids
🏡 Error-tolerant ADP for renewable home energy scheduling and actor-critic learning in smart home energy management
🌐 Explore the book here: worldscientific.com/worldsci…
💡 Ideal for researchers, professionals, academics, and undergraduate and graduate students in control engineering—as well as practitioners working at the intersection of optimal control, reinforcement learning, and energy management.
👉 Quote 𝐖𝐒𝐓𝐖𝐓𝐑𝟑𝟎 at checkout to enjoy 𝟑𝟎% off your purchase now!
#AdaptiveDynamicProgramming #IterativeADP #SelfLearningControl #OptimalControl #PolicyIteration #ValueIteration #ZeroSumGames #NonZeroSumGames #ActorCriticLearning #QLearning #ModelFreeControl #DistributedControl #FaultTolerantControl #BatteryManagement #MicrogridControl #SmartHomeEnergyManagement #ReinforcementLearningControl #NonlinearSystems

4
276

May 19
LLM inference is now ~90% of the lifecycle energy of a deployed model. Training is no longer the bill. Serving is. A new paper from Colorado State @HPE_labs (arXiv:2605.13496, 13 May 2026) reframes the problem.
Don't optimize sustainability as a weighted sum. Schedule it as a game.
MARLIN. Four RL agents — TTFT, carbon, water, cost — each own one metric and run SAC FiLM HER in parallel. Phase 1: every agent proposes its best plan over the next 15-min epoch. Phase 2: a weighted-resource game Γ blends them. Capital Cⱼ buys influence. Utility Qⱼ ranks long-term value. Veto threshold δⱼ stops any agent from being silently traded away.
Numbers vs 8 SOTA baselines (Helix, Splitwise, NSGA-II, PerLLM, SLIT, QLearning, DDQN, ActorCritic):
• −18% TTFT
• −33% carbon emissions
• −43% water usage
• −11% energy cost
• Pareto hypervolume 100% vs ≤68% for next-best RL framework
Why it lands in production. MARLIN is a meta-scheduler above K8s / vLLM — it doesn't touch the model or the serving kernel, only routes requests across geo-distributed datacenters. Five presets (Balanced 4 single-metric variants) let you change posture per epoch with no retraining.
For tech leaders: routing across DCs has a 30–40% sustainability delta that no kernel optimization can match. And capital-as-audit-trail turns "why did carbon spike?" into a named agent with a measurable record.
cc @dejanm @ColoradoStateU @CSUEngineering
Paper: arxiv.org/abs/2605.13496

1
3
148

Apr 21
【訓練 AI 玩平衡桿】
看到 AI 可以自動平衡桿子,阿空一直都很想試試
這集來嘗試看看~
其實加物理旋轉加一些阻尼,成效會好很多,
但還是想直接試試,所以成果就比較難收斂 (っ °Д °;)っ
youtu.be/N3eiyPXZSX0
#AI #強化學習 #QLearning #深度學習 #TensorFlowJS
3
123

Apr 13
This is my partial success to balance a double pendulum by Qlearning on a 1 bit action to move left or right by epsilon
16 Mar 2025

Did a little neural qlearning in a single html file and tiny neuralnet. No experience replay. Learns by gradient of squared error of the qlearning equation considering 3 game states, here, actionA(here), actionB(here), qscore estimates of each. Balances double cartpole a little
1
1
7
3,367


Jan 21
🧠 Q-Learning y Redes Neuronales aplicadas al trading
👉 youtu.be/8Ugi_FRV_VU
⚠️Advertencia: El trading conlleva alto riesgo de pérdida de capital. La información es solo informativa.
#qlearning #redesneuronales #tradingconia #chatgpttrading #iafinanciera #tradingeducativo

1
2
18

Continuous Learning has been solved!
grok.com/share/bGVnYWN5LWNvc…
#AI #AGI #ContinuousLearning #QLearning
1
4
557
4 Nov 2025
reinforcement such as qlearning, occurs in human language when we talk about goals and subgoals, do this and when u get into it u will have to do that and so on. I think LLMs learned it from language and a qlearning algorithm occurs in the weights even if it does not in the code
5
228

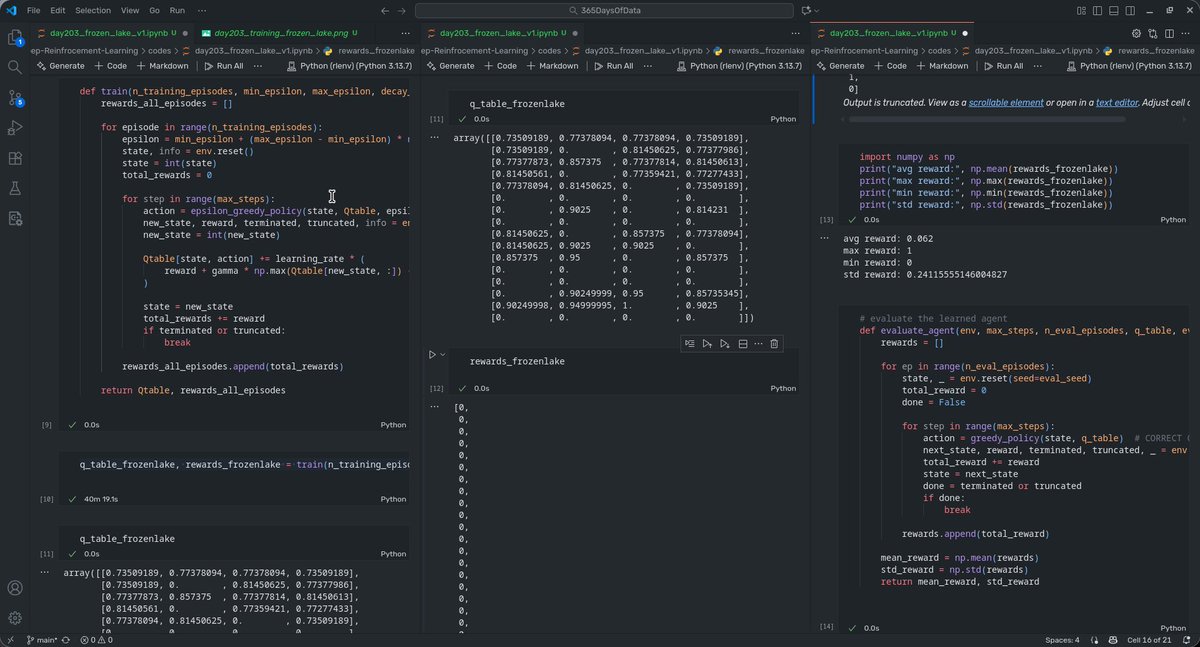
ML grind day 203/365🎯
(deep RL)
> implemented qlearning from scratch
> trained an agent in frozen lake environment
> evaluated but always reach the goal (unusual, will debug tomorrow)



ML grind day 202/365🎯
(deep RL)
> dug into monte carlo & TD, when to use what
> tried writing intuition of the algo [q-learning]
> explored onpolicy vs offpolicy
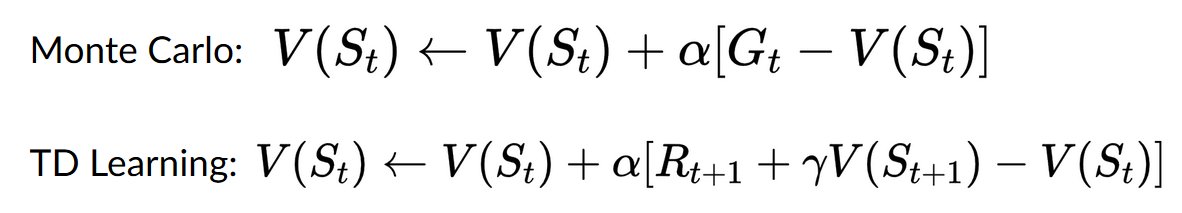


19
556

20 Oct 2025
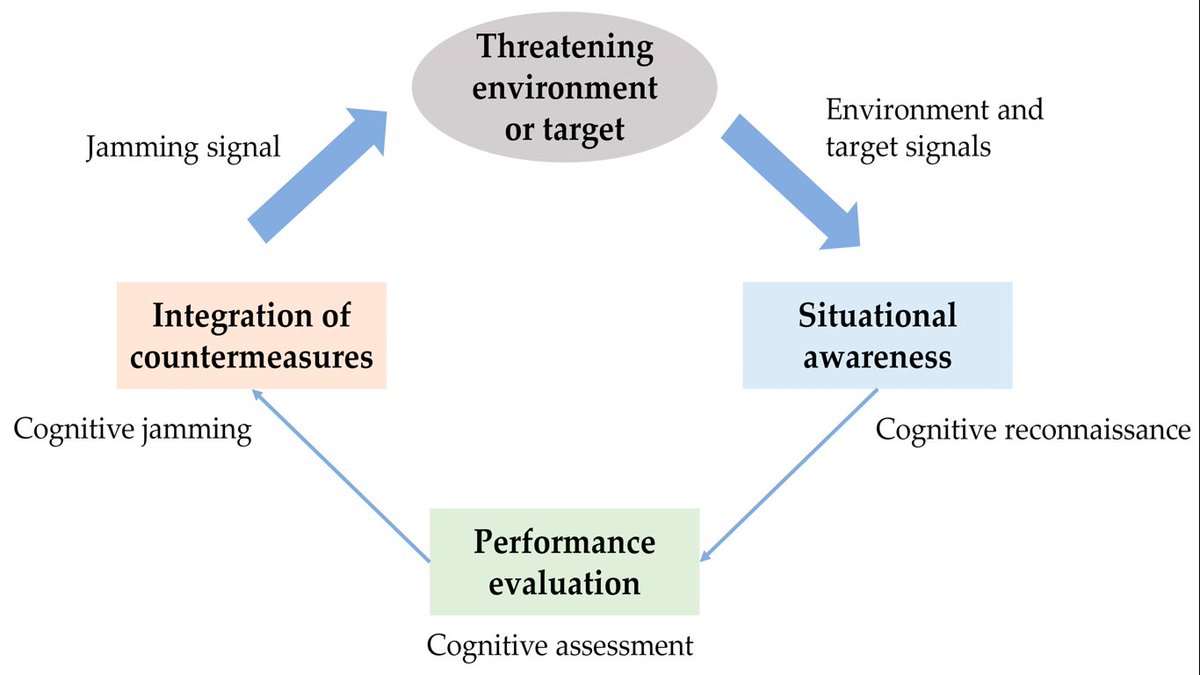
👉👉 Efficient #Jamming Policy #Generation Method Based on Multi-Timescale Ensemble #QLearning
✍️ Jialong Qian et al.
🔗 brnw.ch/21wWLK0
1
2
314

29 Sep 2025
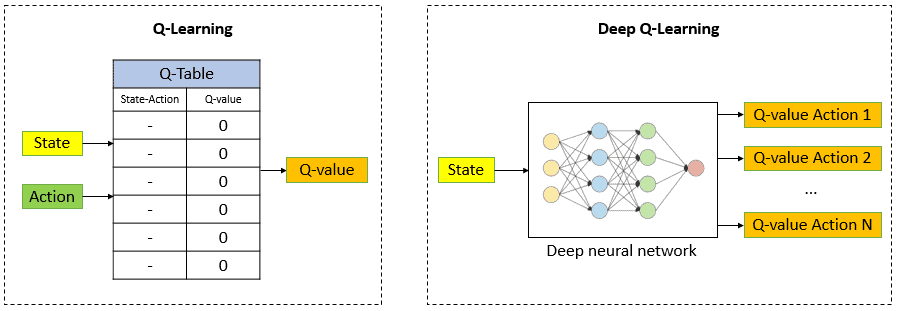
Day 2/30:
> learned about Q-learning and how it helps agents learn optimal actions
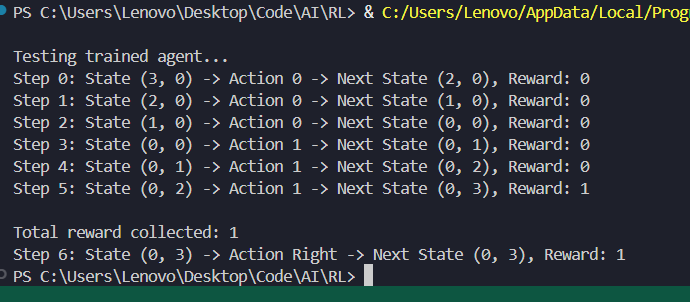
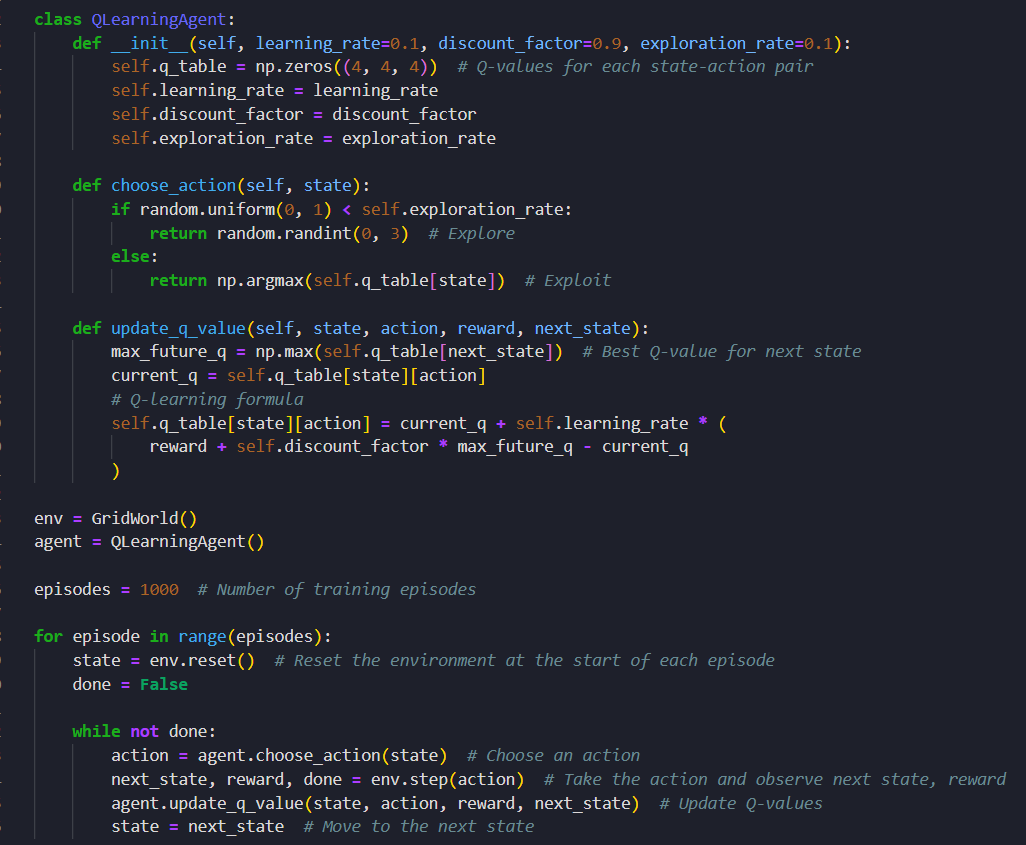
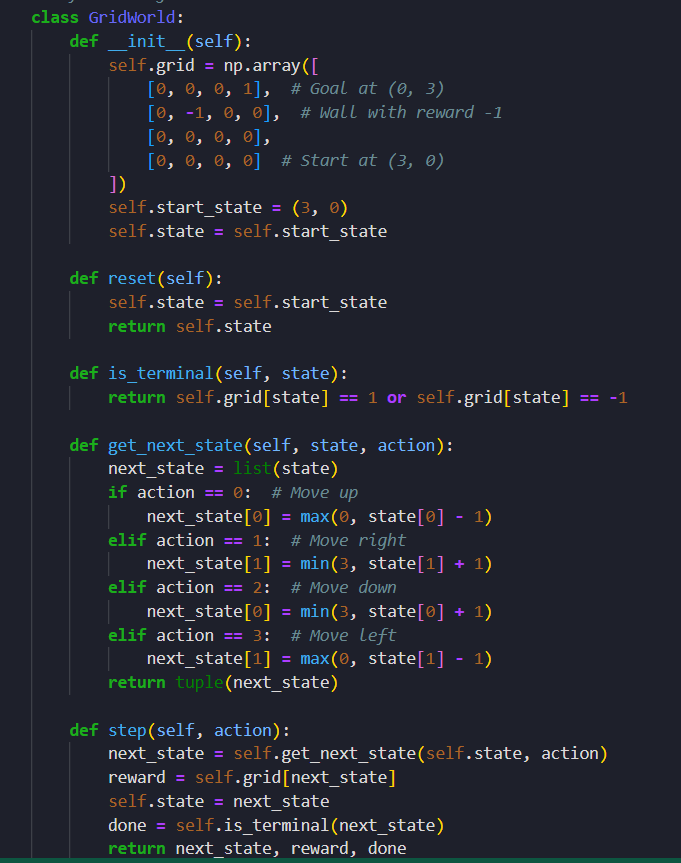
> implemented an agent using Q-learning to solve a GridWorld environment
> trained the agent over 1000 epochs and tested it.
#LearningUtsav2025 #FestivalOfLearning #LUD2 #QLearning
@learning_utsav
11
160

24 Sep 2025
An early surprising result going back to the qlearning atari paper from deepmind is knowledge transfer is very resilient. For example, if you train a net to play Breakout, that net is a much better starting point to learn Pitfall than a random one.
4
1,127

23 Sep 2025
The simplest qlearning goal is to reach higher places, since u can measure height continuously. They might have to stack things up and stand on it, which would take planning.
1
13
22 Sep 2025
hook in some neural-qlearning and make them goal directed minds
1
1
194
22 Sep 2025
I made this small html file that does neural-qlearning. It runs in CPU (no GPU), no experience-replay, and only 2 actions (left vs right). It barely works. Time to turn theory into practice as Ive got a 3d isosurface based game world to bring to life.
16 Mar 2025
Did a little neural qlearning in a single html file and tiny neuralnet. No experience replay. Learns by gradient of squared error of the qlearning equation considering 3 game states, here, actionA(here), actionB(here), qscore estimates of each. Balances double cartpole a little
93

25 Jun 2025
i'm training a model to learn a simple arcade game I built called 'Catch'.
It uses QLearning to figure out how to move the paddle and prevent the ball from hitting the ground
...fascinating to see the model autonomously learn the optimal strategy
v early sneak peak....embarrassing.
15 May 2025

Don't know who wants to hear this, but I'm very happy! 🥳
Remember Google's Genie paper where they learned end-to-end interactive worlds purely from game videos?
Well, I recreated my own tiny version of it for Atari Breakout!
5
165

5 Jun 2025
Wrote a blogpost on qlearning algorithm.
If you want to get started with rl, q-learning is a good place to start.
link in replies
1
3
154

3 Jun 2025
it’s a reinaman gradient SGD with Qlearning
i work on it as i go along
it’s all for the WuBu Nesting Playground
tryna “play with my balls”
github.com/waefrebeorn/bytro…
wubu-sphere-visual.replit.ap…
2
2
17
24 Mar 2025
I still believe neural-qlearning would solve this. And I'll say even further, that this specific game could be live qlearned in a browser, where a particular action in the game commits to playing the game for which "the only winning move is not to play" youtube.com/watch?v=MpmGXeAt…
3
3
303