
Jun 11
🎛️🧠 How can control systems learn to make optimal decisions on their own—balancing theoretical guarantees with real-world performance in everything from microgrids to smart home energy management?
📘 𝙄𝙩𝙚𝙧𝙖𝙩𝙞𝙫𝙚 𝘼𝙙𝙖𝙥𝙩𝙞𝙫𝙚 𝘿𝙮𝙣𝙖𝙢𝙞𝙘 𝙋𝙧𝙤𝙜𝙧𝙖𝙢𝙢𝙞𝙣𝙜 𝙛𝙤𝙧 𝙎𝙚𝙡𝙛-𝙇𝙚𝙖𝙧𝙣𝙞𝙣𝙜 𝙊𝙥𝙩𝙞𝙢𝙖𝙡 𝘾𝙤𝙣𝙩𝙧𝙤𝙡 by Qinglai Wei, Ruizhuo Song, and Hongyang Li introduces iterative adaptive dynamic programming (IADP) theory from a control systems perspective—presenting both advanced theoretical analyses and the most recent practical applications.
Volume 2 of the Series on Deep Learning Neural Networks, this monograph highlights real-world demonstrations in residential energy systems, showing the strong performance of iterative ADP methods.
🔎 Why this book is essential reading:
📖 1. Principles of Adaptive Dynamic Programming
🧱 Foundational principles of adaptive dynamic programming
🎯 Self-learning optimal control under uncertainty
🔬 Setting the stage for iterative refinement
🔁 2. Discrete-Time Iterative Methods
📊 Discrete-time local value iterative ADP
✅ Admissibility and termination analysis
🔄 Discrete-time local policy iteration ADP
⏱️ 3. Continuous-Time and Game-Theoretic Extensions
🕒 Continuous-time time-varying policy iteration
♟️ ADP for discrete-time zero-sum games
🎮 Model-free optimal control for unknown nonlinear multi-player non-zero-sum games
🤝 4. Distributed and Fault-Tolerant Control
🌐 Continuous-time distributed policy iteration for multi-controller nonlinear systems
🛡️ Data-based fault-tolerant control via distributed policy iteration
🔗 Coordination across multi-controller architectures
🏠 5. Smart Energy and Real-World Applications
🔋 Dual iterative Q-learning for optimal battery management in residential environments
⚡ Mixed iterative ADP for optimal battery energy control in microgrids
🏡 Error-tolerant ADP for renewable home energy scheduling and actor-critic learning in smart home energy management
🌐 Explore the book here: worldscientific.com/worldsci…
💡 Ideal for researchers, professionals, academics, and undergraduate and graduate students in control engineering—as well as practitioners working at the intersection of optimal control, reinforcement learning, and energy management.
👉 Quote 𝐖𝐒𝐓𝐖𝐓𝐑𝟑𝟎 at checkout to enjoy 𝟑𝟎% off your purchase now!
#AdaptiveDynamicProgramming #IterativeADP #SelfLearningControl #OptimalControl #PolicyIteration #ValueIteration #ZeroSumGames #NonZeroSumGames #ActorCriticLearning #QLearning #ModelFreeControl #DistributedControl #FaultTolerantControl #BatteryManagement #MicrogridControl #SmartHomeEnergyManagement #ReinforcementLearningControl #NonlinearSystems

4
261

Mar 24
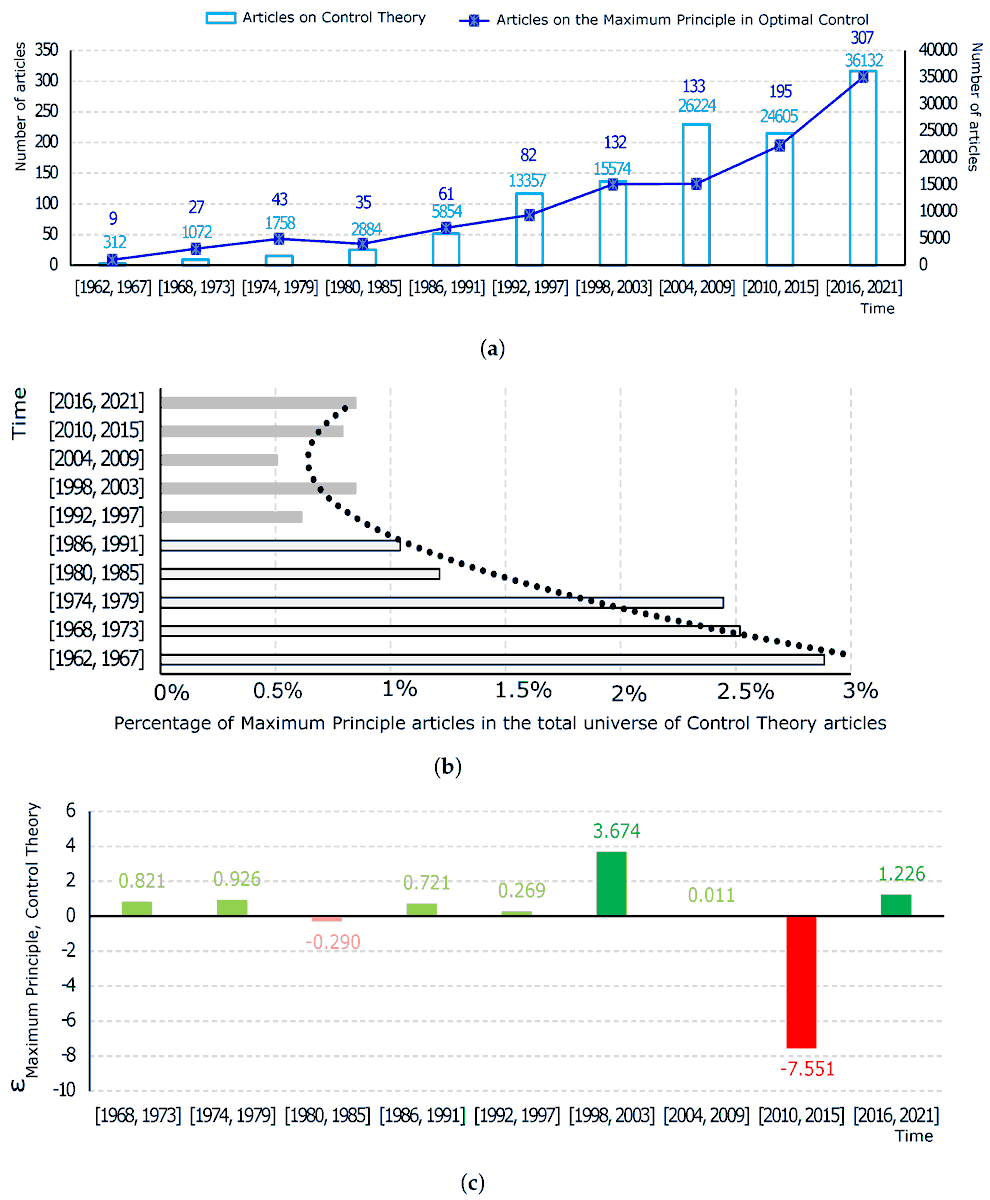
Sixty Years of the Maximum Principle in #OptimalControl: Historical Roots and Content Classification
✏️ Roman Chertovskih et al.
🔗 brnw.ch/21x0Zs2
Viewed: 6303; Cited: 8
#mdpisymmetry #bibliometricanalysis
@UPorto
@ComSciMath_Mdpi
2
35

Jan 24
In 1996, James Sethian showed a remarkably clean idea. You can get shortest routes through a messy world by letting a wave expand once. No trial paths. No scanning beams. Just one growing front.
You compute an arrival time field T(x,y). At each point, T means how long the front needs to reach that point. The rule is ‖∇T‖ = 1/F. If the medium is fast, meaning F is large, the front moves quickly and T grows slowly. If the medium is slow, meaning F is small, the front moves slowly and T grows quickly. Obstacles act like F is near zero, so the front cannot pass through and instead wraps around.
Then you get the path without searching. Once T exists, you pick any start point and follow xdot proportional to minus grad T. You slide downhill on the time landscape and trace a fastest route back to the source.
This is the Hamilton Jacobi and optimal control view that Tsitsiklis (1995) made precise. Compute the value or arrival time function first, and the optimal trajectories follow from it.
#FastMarching #EikonalEquation #HamiltonJacobi #OptimalControl #ShortestPath #ComputationalGeometry
19
86
1,046
203,256

Jan 19
Check out our latest work, "Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning for Agile Flight," published in the IEEE Transactions on Robotics, where we reconcile #OptimalControl and #ReinforcementLearning, achieving the same super-human performance, but with superior generalizability, as our previous model-free deep RL! Code released!
PDF: arxiv.org/pdf/2306.09852
Code: github.com/uzh-rpg/acmpc_pub…
Full Video: youtube.com/watch?v=_qekrF4E…
Model-free #ReinforcementLearning (RL) is known for its strong task performance and flexibility in optimizing general reward formulations. On the other hand, #ModelPredictiveControl (MPC) provides robustness, constraint handling, and powerful online replanning capabilities. In this work, we extend our previous AC-MPC paper (Romero, ICRA'24) by taking a deeper look at how both approaches can be unified. We introduce and extend Actor-Critic Model Predictive Control (AC-MPC), a framework that embeds a differentiable MPC inside an Actor-Critic RL architecture. This integration allows the MPC-based actor to perform short-term predictive optimization, while the critic facilitates long-horizon learning and exploration. We conduct a comprehensive study that highlights AC-MPC’s key advantages:
- Better out-of-distribution generalization, both against unknown disturbances and changes in the quadrotor dynamics
- Improved sample efficiency
- A novel empirical analysis uncovering a relationship between the critic’s value function and the MPC cost function, providing deeper insight into their interplay. We validate our method in simulation and the real world on a quadcopter flying at superhuman speeds of up to 21 m/s, matching state-of-the-art model-free RL performance, and retaining the predictive structure of MPC for more reliable out-of-distribution behavior.
Reference:
Actor-Critic Model Predictive Control: Differentiable Optimization meets Reinforcement Learning for Agile Flight
IEEE Transactions on Robotics (T-RO), 2025
PDF: arxiv.org/pdf/2306.09852
Full Video: youtube.com/watch?v=_qekrF4E…
Code: github.com/uzh-rpg/acmpc_pub…
Kudos to @roaguiangel, @EliJalbout, @realyunlong!
@UZH_en @UZH_Science @UZHspacehub @AUTOASSESS_EU @ERC_Research @UZH_ai
3
64
419
27,000

26 Oct 2025
This video demonstrates the neural network solution to the Ramsey–Cass–Koopmans model. Each frame represents an epoch of the optimization process.
Code:
colab.research.google.com/dr…
#OptimalControl #DeepLearning

In addition to traditional methods, using PINN, we can solve the Ramsey ODE model too. How do you compare Ridgeless Kernel to PINN?
3
26
181
26,842

16 Sep 2025
"Integrating Reinforcement Learning and Model Predictive Control for Mixed-Logical Dynamical Systems," by Caio Fabio Oliveira da Silva, Azita Dabiri, and Bart De Schutter
Pub Date: 21 August 2025
Link: ieeexplore.ieee.org/document…
#reinforcementlearning #hybridsystems #optimalcontrol

1
3
167

8 Sep 2025
#Article
📜 A Non-Linear Offset-Free Model Predictive Control Design Approach
by Haoran Zhang and Emmanuel Prempain
mdpi.com/2076-0825/13/8/322
@uniofleicester
@MDPIEngineering
#nonlinearmodelpredictivecontrol #optimalcontrol #integralcontrol #realtimecontrol #watertankprocess

2
60

24 Aug 2025
🔥 Read our Paper
📚 Inducing Optimality in Prescribed Performance Control for Uncertain Euler–Lagrange Systems
🔗 mdpi.com/2076-3417/13/21/119…
👨🔬 by Christos Vlachos et al.
#adaptivedynamicprogramming #optimalcontrol
1
3
81

15 Aug 2025
#NextatBIRS-@CMO_oaxaca Mathematical Analysis of Adversarial Machine Learning, August 17- 22, 2025 birs.ca/event/25w5469
#DataScience #PDE #Calculus #OptimalControl #Optimization #MachineLearning
2
6
324

30 Jul 2025
Super excited to have LQRax featured at Google Developers Blog! Try it on Google Colab: github.com/MaxMSun/lqrax
Model-based control is still essential in the era of large models, but it must evolve to support robot learning:
- To translate discrete decisions to the continuous dynamics of robots.
- To enable online learning using the robot’s onboard resources.
- To automate closed-loop data generation for robot learning.
Not only do we need new control algorithms to support robot learning, but also the right software infrastructure. @Google's #JAX provides a great platform for this mission.
I recently had the pleasure of chatting with Srikanth Kilaru at Google about my journey with JAX and my JAX-enabled control package—LQRax—for efficient robot learning.
Read more about our conversation in this article below.
#AI #Robotics #RobotLearning #OptimalControl #EmbodiedAI
29 Jul 2025

Learn how JAX enables efficient optimal control and simulation. Roboticist @max_msun shares how JAX bridges the gap between model-based control and deep learning, and the robotics ecosystem ↓
developers.googleblog.com/en…
9
287
20 Jun 2025
#NextatBIRS Efficient and Reliable Deep Learning Methods and their Scientific Applications, June 22 - 27, 2025 birs.ca/event/25w5382
#MachineLearning #Calculus #OptimalControl #Optimization #NumericalAnalysis #AI
@NSF-MPS #DMSFunded @Innovation_AB @NSERC_CRSNG @CRSNG_NSERC
1
2
643

9 May 2025
モデル予測制御を用いた卓球ロボット
飛んでくるボールの速度と軌道を素早く推定し、ボールに様々な回転をかけて狙った場所に打ち返す
arxiv.org/html/2505.01617v1
#RobotArm #MPC #HighSpeedPrecision #OptimalControl #algorithm #TableTennis #PingPong #MIT
6
22
2,358

8 Apr 2025
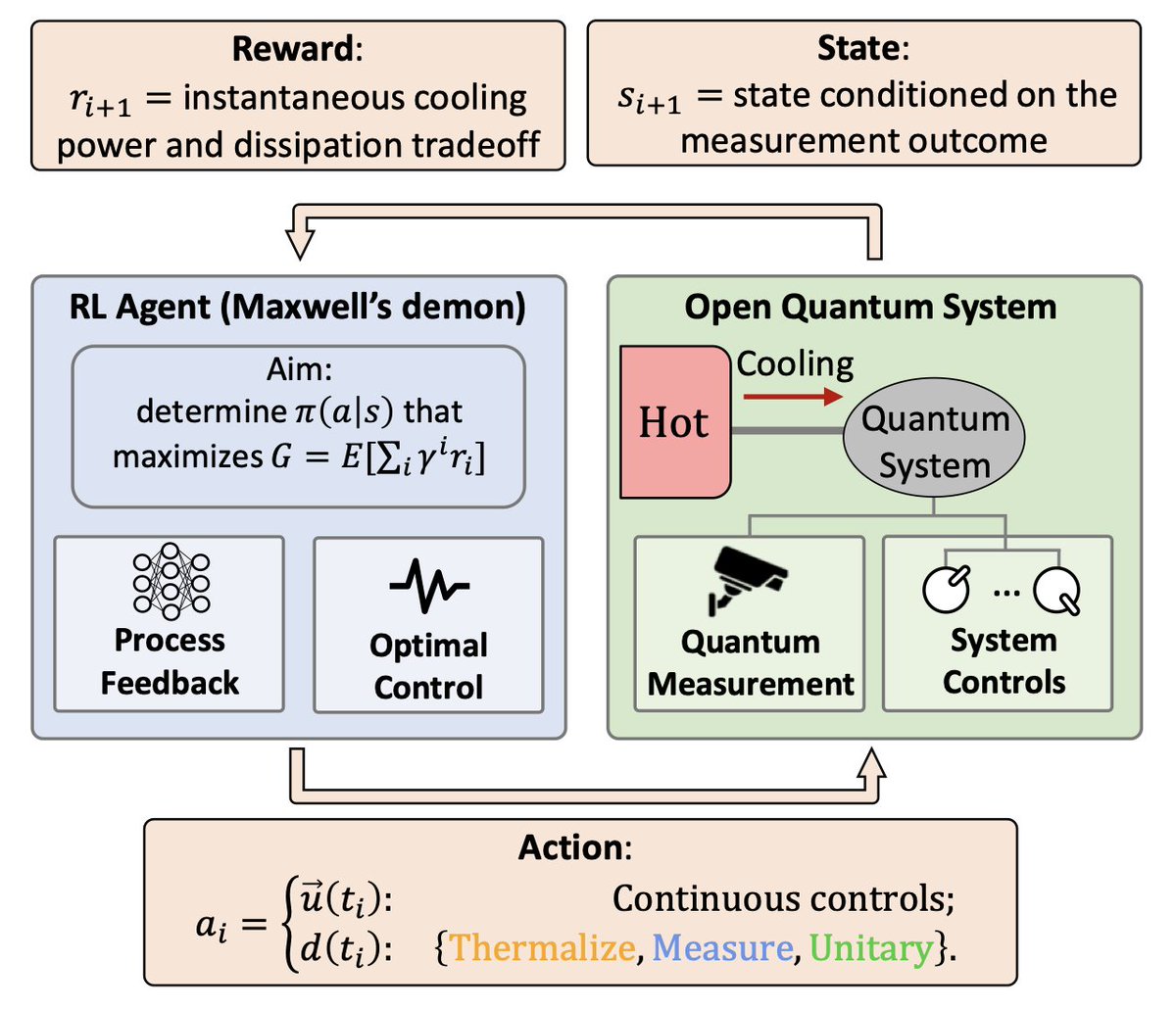
Artificially intelligent Maxwell's demon for optimal control of open quantum systems
lnkd.in/d2Xx8Jfg
A reinforcement learning agent in #machinelearning is interpreted literally as a thermodynamic agent reminiscent of a Maxwell's demon for the optimal control of open quantum systems.
In detail, #feedback control of open quantum systems is of fundamental importance for practical applications in various contexts, ranging from quantum computation to quantum error correction and quantum metrology. Its use in the context of thermodynamics further enables the study of the interplay between information and energy. However, deriving optimal feedback control strategies is highly challenging, as it involves the #optimalcontrol of #openquantumsystems, the stochastic nature of quantum measurement, and the inclusion of policies that maximize a long-term time- and trajectory-averaged goal.
In this work, we employ a #reinforcementlearning approach to automate and capture the role of a quantum #Maxwell's demon: the agent takes the literal role of discovering optimal feedback control strategies in qubit-based systems that maximize a trade-off between measurement-powered cooling and measurement efficiency. Considering weak or projective quantum measurements, we explore different regimes based on the ordering between the thermalization, the measurement, and the unitary feedback timescales, finding different and highly non-intuitive, yet #interpretable, strategies.
In the #thermalization-dominated regime, we find strategies with elaborate finite-time thermalization protocols conditioned on measurement outcomes. In the measurement-dominated regime, we find that optimal strategies involve adaptively measuring different qubit observables reflecting the acquired information, and repeating multiple weak measurements until the quantum state is 'sufficiently pure', leading to random walks in state space. Finally, we study the case when all timescales are comparable, finding new feedback control strategies that considerably outperform more intuitive ones. We discuss a two-qubit example where we explore the role of #entanglement and conclude discussing the scaling of our results to #quantummanybodysystems.
Warm thanks to Paolo Andrea Erdman, Robert Czupryniak, Bibek Bhandari, Andrew Jordan, @FrankNoeBerlin, and Giacomo Guarnieri for this wonderful collaboration at the interface of #artificialintelligence and #quantumthermodynamics.
1
13
72
2,822

1 Apr 2025
The April issue of SIAM News is now available! In this special issue on #ComputationalScience and #engineering, Sebastian Reich focuses on one aspect of the #DigitalTwin paradigm: the synergy between #DataAssimilation and #OptimalControl. Check it out! siam.org/publications/siam-n…

ALT A diagram illustrating the relationship between a physical twin and digital twin, which involves a predictive/generative model, data assimilation, and control.
3
7
667

14 Mar 2025
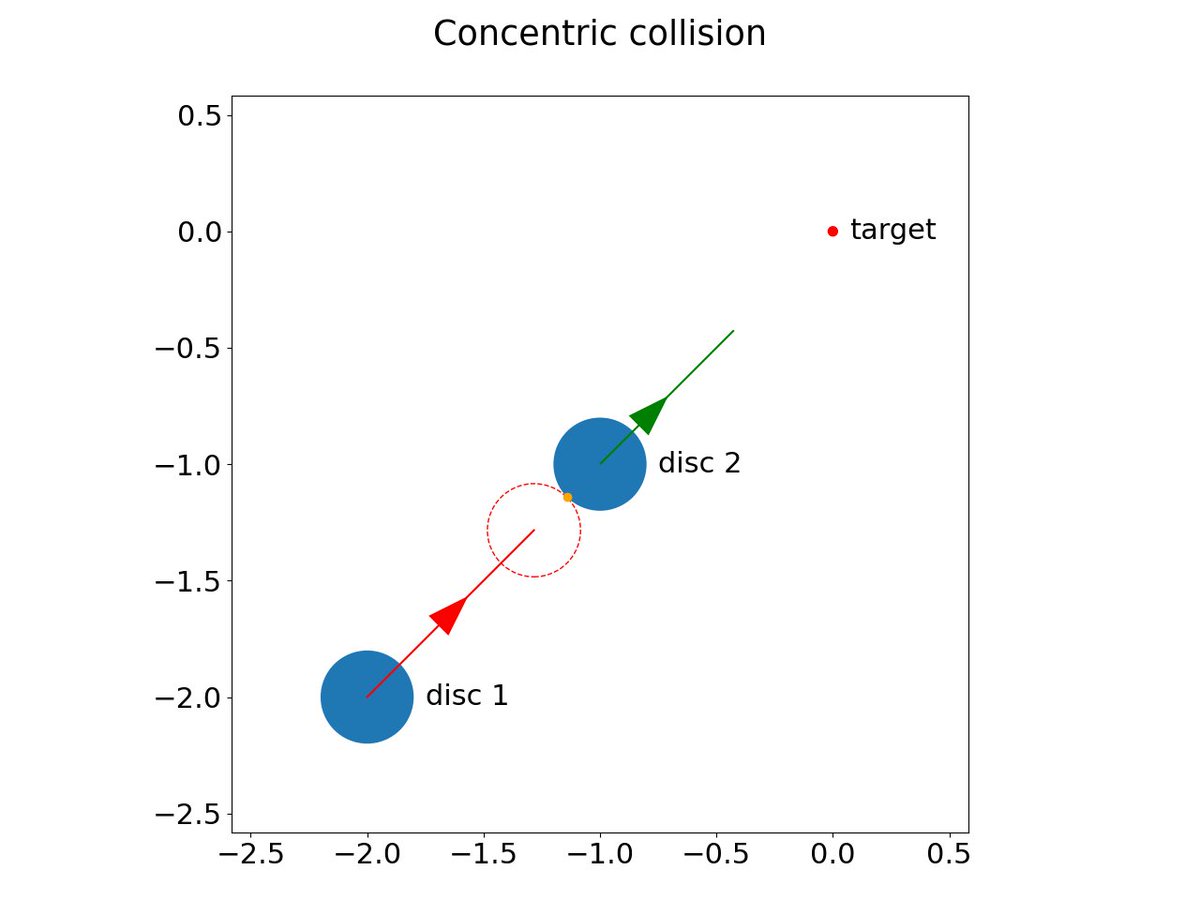
[1/4] A project from a while ago is out: we design a new algorithm based on hybrid minimum principle for optimal control in rigid-body dynamics with collisions doi.org/10.1016/j.cnsns.2025… #OptimalControl #HybridSystems #PhysicsSimulation #ReinforcementLearning
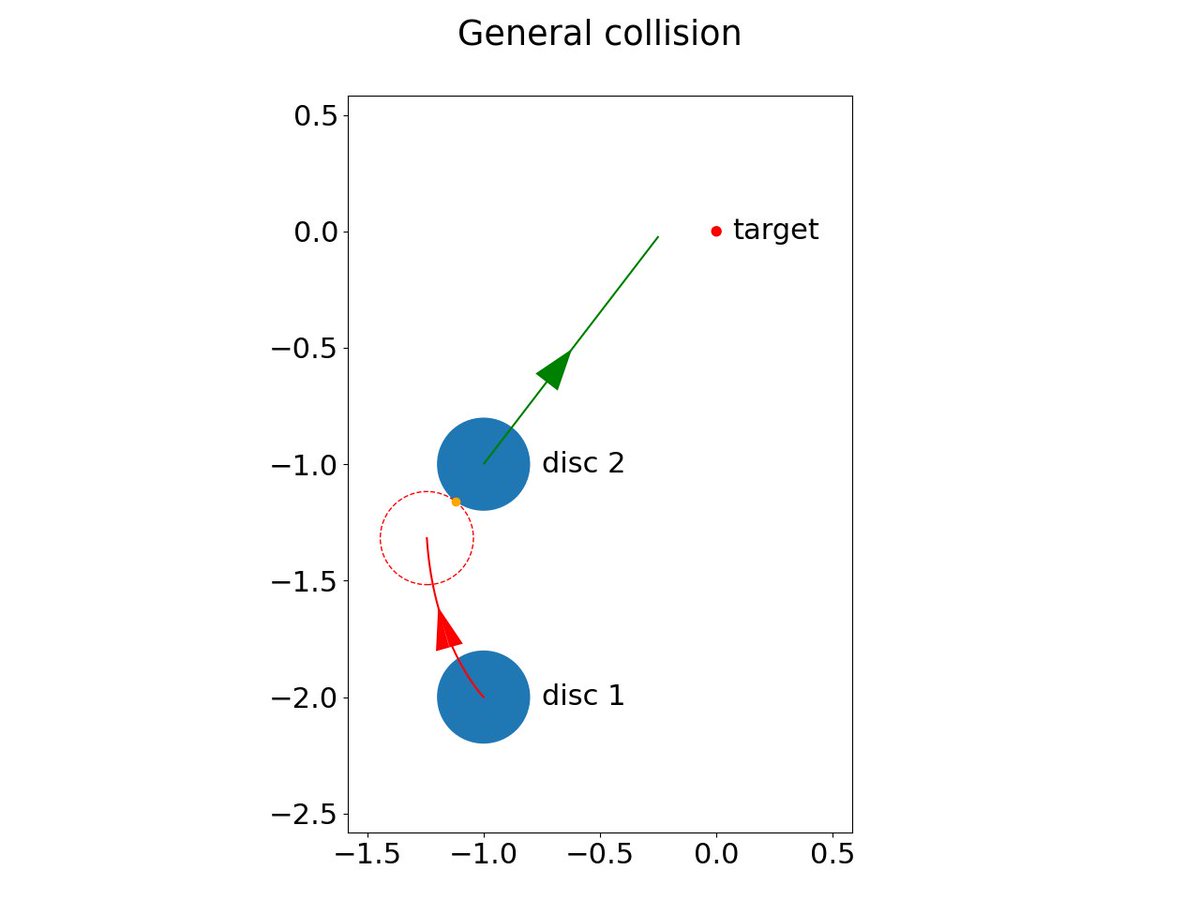
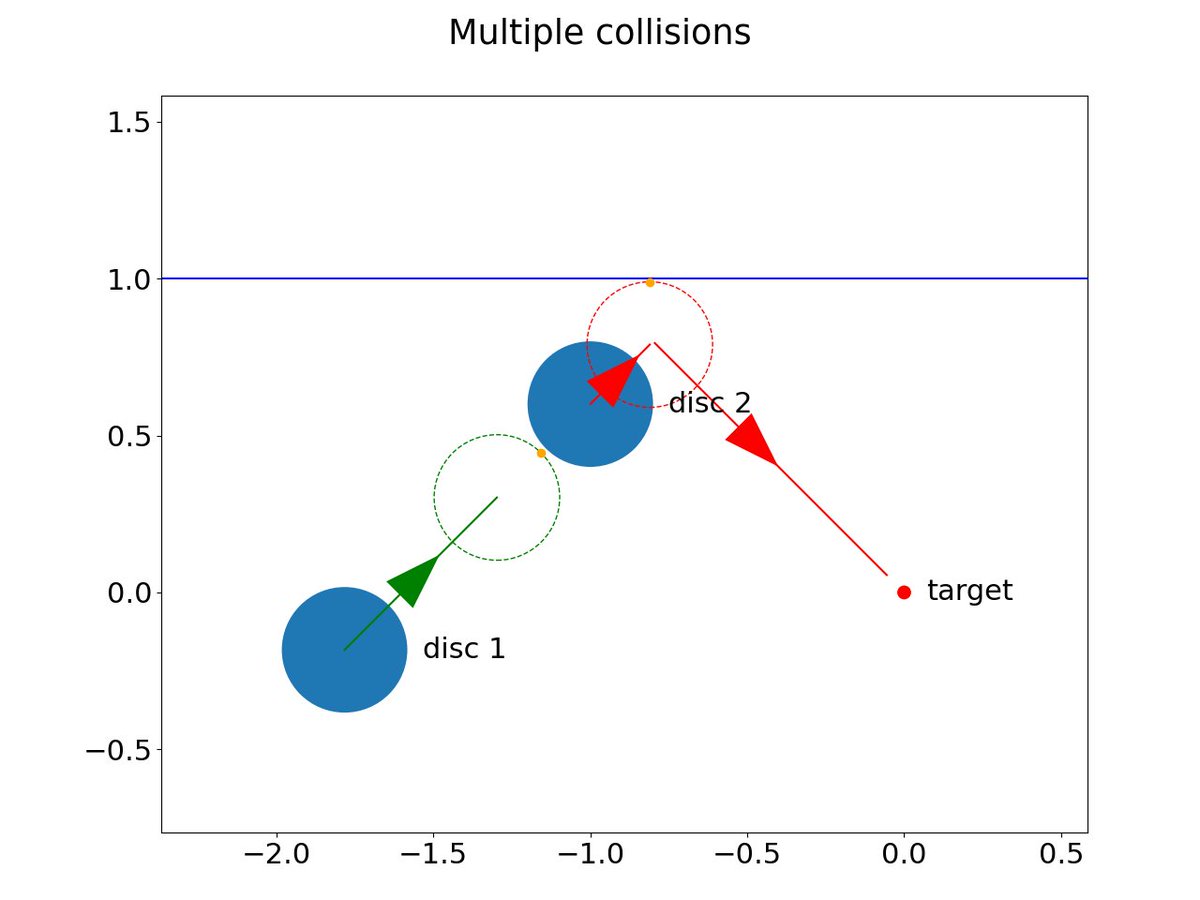
1
3
281

12 Feb 2025
📍Let us warmly welcome Prof. Taekyun Kim as the new member of our ADECP's Editorial Board.👏
Prof. Taekyun Kim
Kwangwoon University
South Korea
Interests: #numbertheory, #optimalcontrol, probability
ojs.acad-pub.com/index.php/A…

2
49
7 Feb 2025
#Article
📜 Novel Adaptive Magnetic Springs for Reliable Industrial Variable Stiffness Actuation
by Branimir Mrak, et al.
mdpi.com/2076-0825/12/5/191
@FlandersMake
#codesign #mechanismdesign #optimalcontrol #industryapplications #parallelelasticactuators #variablestiffness
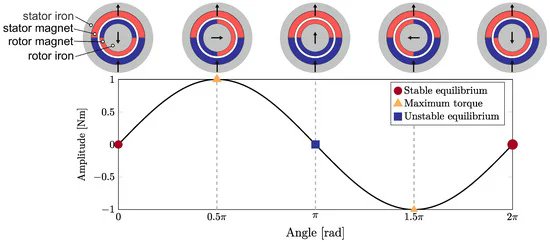
1
23

9 Jan 2025
Discover advanced strategies for optimal control in this insightful session with Rajeev Voleti. Learn how JuliaSimControl, #ModelingToolkit, and InfiniteOpt address multi-system coordination challenges with #innovative techniques. Watch the video to explore real-world applications and groundbreaking solutions. juliahub.com/company/resourc…
#JuliaLang #OptimalControl #AutonomousSystems #JuliaLang
8
569

27 Dec 2024
Reducing Tyre Wear Emissions of Automated Articulated Vehicles through Trajectory Planning
mdpi.com/1424-8220/24/10/317…
@tudelft @KTHuniversity
#trajectoryplanning; #optimalcontrol; #articulatedvehicles
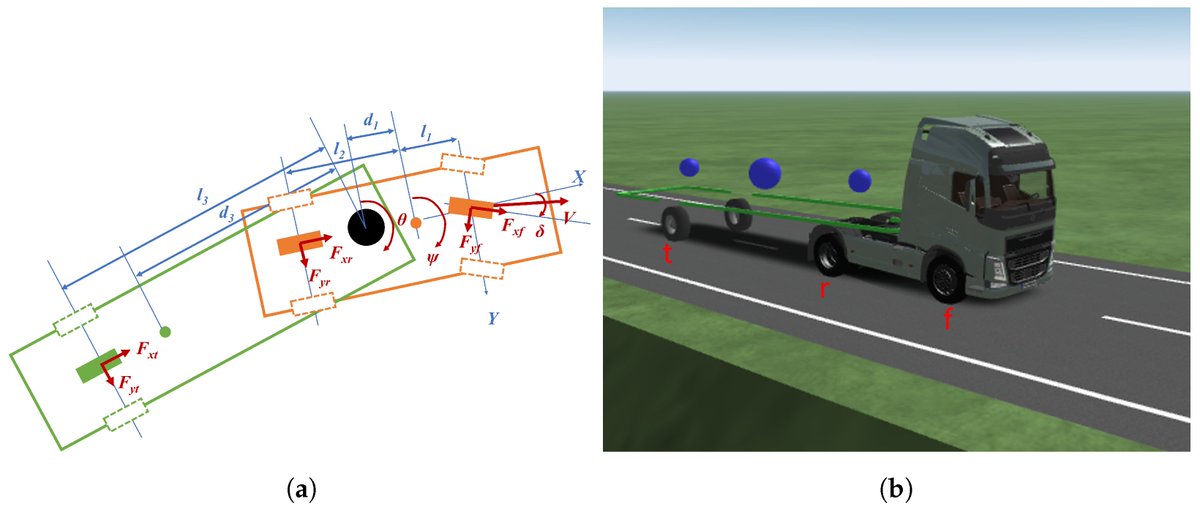
1
2
121

11 Dec 2024
Le gars quand il va réaliser que Marx, Cockshott, Cottrell, Guzman, Kantorovitch étaient des universitaires.
Il va la sortir de son gros cerveau, la planification socialiste. Team #OptimalControl
1
1
54