
Jun 11
Small sample size can lead to unreliable research results.
Choosing the right sample size improves accuracy, statistical power, and confidence in your findings.
#Biostatistics #ClinicalResearch #SampleSize #ResearchSupport #StatsCure

ALT Small Sample Size Can Affect Your Research. Educational infographic highlighting the importance of choosing the right sample size for accurate and reliable research outcomes. The graphic features statistical charts, data analysis visuals, and research support services including Sample Size Calculation, Statistical Data Analysis, Study Design Guidance, SPSS, R & SAS Support, and Research Methodology Assistance. Designed by StatsCure Network for researchers, healthcare professionals, and academic institutions.
29

you can end up looking like a total whale or goat over a small live mtt sample.
if we somehow found a way to play this out for an actual relevant samplesize (and very low/no rake) i'd certainly put money on the online players.
1
15
1,402




En dansker havde med 73% sandsynlighed brugt "læner" sig tilbage.
Det er ét af argumenterne min algoritme kom frem til.
"Sætter sig tilbage" af en AIlingvistificering af en (ophav)->Eng->DA formulering hentet fra en database.
Samplesize er ikke stort nok til læner/sætter kan..
1
3
88

#statstab #535 The Benefits Of Reporting Critical Effect Size Values
Thoughts: You ran a study w/o a power analysis? Report the lowest value your test could have detected at 80% power and 5% alpha.
#poweranalysis #effectsize #samplesize #posthoc
osf.io/preprints/psyarxiv/7q…
1
2
129



May 5
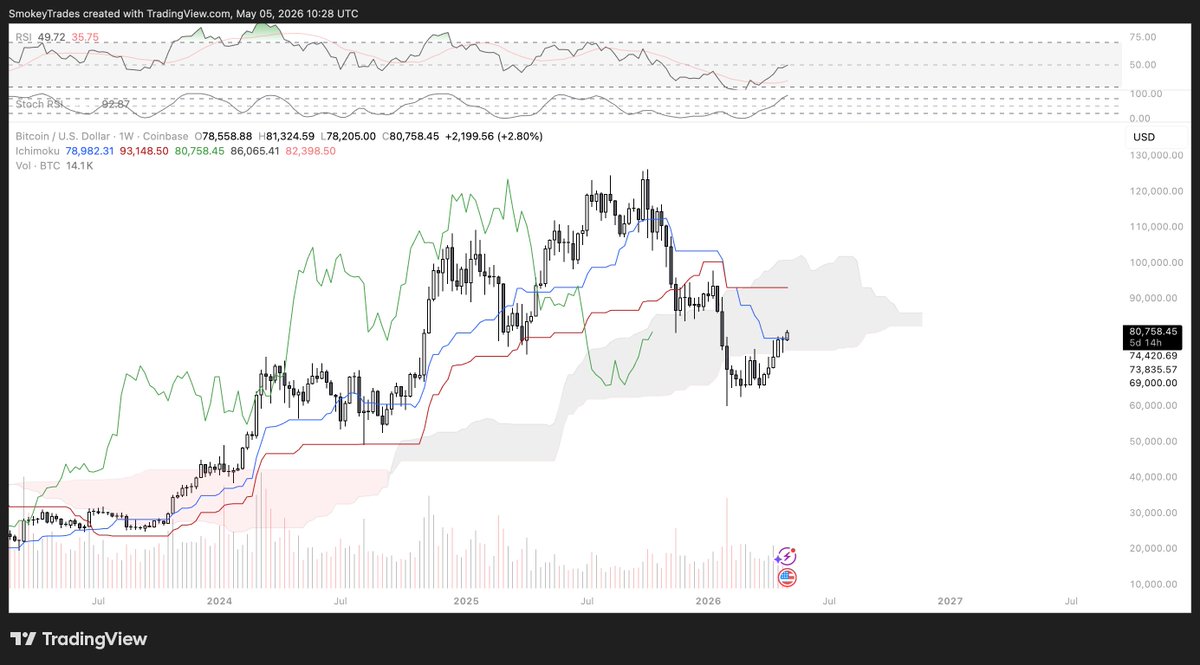
There's not been a single time in Bitcoin history where a weekly reclaim of the Cloud Bottom hasn't led to a fully completed Edge-to-Edge
Samplesize isn't huge but just something to look out for
4
5
62
8,299

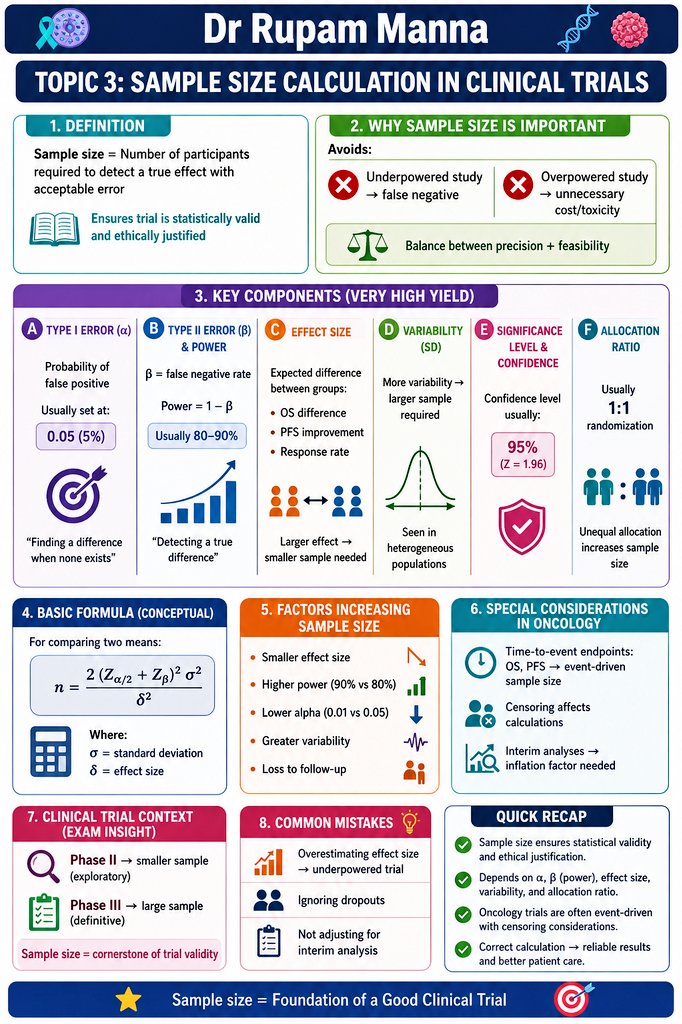
📌 High-Yield Biostatistics Every Oncologist & Resident Must Master
TOPIC : Sample Size Calculation in Clinical Trials
Complete visual masterclass in one frame:
✅ Definition & why sample size = foundation of every good trial
✅ Key components (α, β/power, effect size, variability, allocation ratio)
✅ Conceptual formula factors that increase sample size
✅ Oncology-specific pearls (OS/PFS event-driven endpoints, censoring, interim analysis)
✅ Phase II vs III common mistakes to avoid
“Sample size ensures statistical validity and ethical justification.”
Save it. Share it. Use it in trial design, paper reading & viva/exams.
Dr Rupam Manna
@DrRupamOncology
#ClinicalTrials #SampleSize #Biostatistics #Oncology #MedEd #OncoViva #VivaPrep #ClinicalResearch
1
18
56
2,901

Apr 20
Joar aber ist halt auch wirklich ne sehr kleine samplesize, Hein hat ja nur 2 Spiele gemacht. Und hatte jetzt, abgesehen von den 2, ne ganze Saison keine Spielpraxis. Also schon Risiko
1
3
268

Zwei spiele als samplesize, wo man bei einem 70 Minuten in Überzahl war, sind mir dafür eigentlich deutlich zu wenig. Lasst ihn die Saison doch zu Ende bringen, dann hat man zumindest 7 Spiele auf die man blicken kann. Das jetzt festzuzerren wäre aus meiner Sicht unnötig früh
1
55
909


"oohohooo the best people in these sports are vegan therefore vegan make you STRONG!" erm... This #samplesize is far too #small to make #inference with a #highlevelofconfidence
1
2
59

Apr 5
Boah, kann ich mir eigentlich schwer vorstellen. Dafür sind 13 Profieinsätze eine zu kleine Samplesize. Sein Talent ist unbestritten, aber so viel Geld auf den Tisch zu legen wäre schon auch ein Gamble. Was nicht heißt dass irgendein verrückter englischer Club es nicht doch tut.
5
246


Mar 30
How many participants do you actually need for your study?
This is one of the most important questions in statistics because your sample size determines both the reliability of your results and the overall costs.
❌ If your sample is too small, real effects may not be detected, even if they truly exist. This can lead to incorrect conclusions.
❌ If your sample is too large, you may spend more time, money, and effort than necessary.
Power analysis helps you find the right balance between reliable results and efficient use of resources.
The visualization below shows how the required sample size varies with the effect size. When the effect size is small, a large number of participants are needed to detect it reliably. As the effect size increases, the required sample size decreases. This highlights a fundamental principle of study design. Small effects require large samples, while large effects can be detected with fewer participants.
I recently released a new module in the Statistics Globe Hub that explains how to perform sample size calculation using power analysis. The module includes a video lecture, practical examples, and exercises to help you apply the method step by step in R.
Not a Statistics Globe Hub member yet? The Hub is an ongoing learning program where I release a new module every week on topics related to statistics, data science, AI, R, and Python.
Join the Hub now to get immediate access to the Statistical Power module and all other modules released this month.
More information about the Statistics Globe Hub: statisticsglobe.com/hub
#Statistics #DataScience #PowerAnalysis #SampleSize #RStats
7
24
1,289

Mar 27
Asian weather Markets are not in my Timezone @Polymarket.
So i just track the Forecasts there, try to build a model for every City and Open Orders then.
My samplesize is very low but Singapore and Shanghai look very promising. Anyway i wanted a Forecast from Yesterday for today:
1
4
248
Mar 26
Many statistical studies fail to detect real effects simply because the analysis does not have enough power.
Statistical power measures the probability that a statistical test correctly detects a true effect instead of missing it.
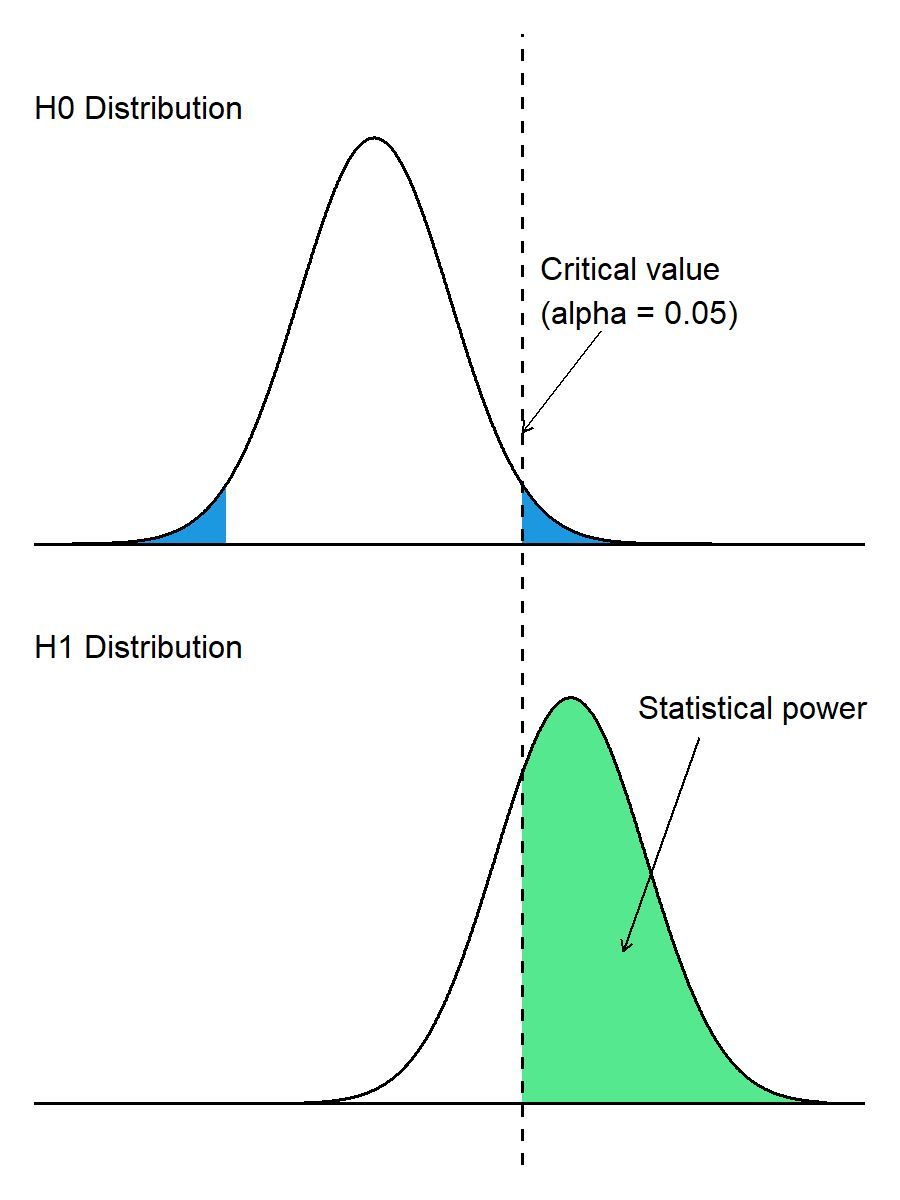
The graphic below illustrates this idea using two distributions:
🔹 H0 distribution: the distribution of the test statistic when no real effect exists.
🔹 H1 distribution: the distribution of the test statistic when a real effect is present.
The blue regions represent the significance level (α). These are the rejection regions under the null hypothesis.
The green region shows the statistical power. It represents the probability that the test statistic falls into the rejection region when the alternative hypothesis is true.
A commonly recommended target in many studies is a power of 0.8 to 0.9, meaning there is an 80–90% chance of detecting a real effect.
The good news is that you can use power analysis to determine the required sample size for your study before collecting data. Power analysis combines assumptions about the expected effect size, the significance level, and the desired power to estimate how many observations are needed so that your study has a reasonable chance of detecting a real effect if it exists.
In R, power analysis can be performed using the pwr package, while in Python similar calculations can be done with the statsmodels library.
In the latest Statistics Globe Hub module, I explain how to perform sample size calculation using power analysis. The module includes a video lecture, practical examples, and exercises that show how to implement the method in R.
The Statistics Globe Hub is a weekly learning program where I publish new modules on statistics, data science, AI, R, and Python.
By joining now, you will get immediate access to the Statistical Power module and all other modules released this month.
More information: statisticsglobe.com/hub
#statistics #datascience #statisticalpower #poweranalysis #samplesize #rstats #statisticsglobehub
2
26
127
4,163